
- 1使用CRNN-CTC-CenterLoss进行高效文字识别
- 2usage: conda-script.py [-h] [-v] [--no-plugins] [-V] COMMAND ... conda-script.py: error: argument CO_usage: conda-script.py [-h] [--no-plugins] [-v] co
- 3C#开源跨平台机器学习框架ML.NET----二元分类情绪分析
- 4C++可变参数模板_c++ 可变参数模板
- 5记Git基本使用、子模块基本使用、Git LFS等_git 添加子模块
- 6【小白视角】大数据基础实践(三)HDFS的简单基本操作_使用客户端节点执行hdfs dfs -put文件上传至hdfs很慢_hdfs基本操作实验
- 7ModbusTCP助手调试工具Modbus主站调试工具ModbusMaster支持所有Modbus设备调试_modbustcp调试工具
- 8.NET2.0程序 在.net 4.0 中运行的解决方案
- 9RNN/LSTM (一) 实践案例_rnn简单实例
- 10今年这面试难度,我给跪了……_自动化面试最有难度度项目
Redis面试题以及答案_redis基础面试
赞
踩
1. 什么是Redis?它主要用来什么的?
Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
与MySQL数据库不同的是,Redis的数据是存在内存中的。它的读写速度非常快,每秒可以处理超过10万次读写操作。因此redis被广泛应用于缓存,另外,Redis也经常用来做分布式锁。除此之外,Redis支持事务、持久化、LUA 脚本、LRU 驱动事件、多种集群方案。
2.说说Redis的基本数据结构类型
大多数小伙伴都知道,Redis有以下这五种基本类型:
- String(字符串)
- Hash(哈希)
- List(列表)
- Set(集合)
- zset(有序集合)
它还有三种特殊的数据结构类型
- Geospatial
- Hyperloglog
- Bitmap
list应用场景参考以下:
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpsh+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
3、什么是缓存穿透、缓存击穿、缓存雪崩?
在缓存系统的设计和运维中,"缓存击穿"、"缓存穿透"和"缓存雪崩"是三种常见的问题场景,它们各自描述了不同的异常情况,可能导致缓存系统的效率下降甚至崩溃。以下是对这三个概念的解释:
缓存穿透
缓存穿透是指查询一个数据库中不存在的数据,由于缓存不会记录这个不存在的数据,这导致每个此类请求都会穿过缓存并打到数据库上,造成不必要的数据库负载。如果有大量此类请求,数据库可能会遭受极大压力。
防御措施:
- 对查询的参数进行合法性校验,阻止不合法的查询请求。
- 所查询的空结果也可以缓存起来,设定一个较短的过期时间。
- 使用布隆过滤器,将所有可能存在的数据的哈希值放到一个足够大的布隆过滤器中,查询时先检查布隆过滤器,如果布隆过滤器说数据不存在,则不再继续查询数据库。
缓存击穿
缓存击穿是指热点数据(大量并发访问的数据)在缓存中失效的时候,导致所有对这个数据的访问都会直接打到数据库上,从而造成数据库压力瞬间增大。缓存击穿和缓存穿透不同,它指的是一个在缓存和数据库中都存在的热点数据。
防御措施:
- 设置热点数据永不过期。
- 使用互斥锁(Mutex)或者分布式锁。当缓存失效时,不是立马去加载数据库,而是先使用锁机制,保证同一时间只有一个请求去数据库中查询数据并加载到缓存中。
- 使用双重检测锁模式,在缓存失效的时候,所有的并发线程在访问数据库前,先获取一个锁,第一个访问的线程通过数据库加载数据,其他的线程则等待这个线程查询完毕,直接使用已经加载好的缓存数据。
缓存雪崩
缓存雪崩是指缓存中大量数据在同一时间失效,由于原有请求无法被缓存命中,所有数据都需要从数据库加载,导致数据库压力瞬间增大。这种情况可能由缓存服务器宕机或者缓存大量数据设置了相同的过期时间引起。
防御措施:
- 设置不同的数据缓存时间,使缓存失效的时间点尽量分散。
- 使用高可用的缓存架构,比如主从复制、缓存集群,保证单点故障不会导致整个缓存服务不可用。
- 对数据库访问进行限流措施,避免数据库被过多的请求压垮。
- 为缓存数据设置适当的冗余和备份策略,即使缓存服务宕机也能迅速恢复。
理解这三个问题及其防御措施对于设计和维护一个高效且健壮的缓存系统至关重要。
4.说说Redis的常用应用场景
- 缓存
- 共享Session
- 分布式锁
- 计数器应用
- 排行榜
- 消息队列
- 社交网络
- 位操作
5. Redis 的持久化机制有哪些?

RDB,就是把内存数据以快照的形式保存到磁盘上。
RDB持久化,是指在指定的时间间隔内,执行指定次数的写操作,将内存中的数据集快照写入磁盘中,它是Redis默认的持久化方式。执行完操作后,在指定目录下会生成一个dump.rdb文件,Redis 重启的时候,通过加载dump.rdb文件来恢复数据。RDB触发机制主要有以下几种:

RDB 的优点
- 适合大规模的数据恢复场景,如备份,全量复制等
RDB缺点
- 没办法做到实时持久化/秒级持久化。
- 新老版本存在RDB格式兼容问题
AOF
AOF(append only file) 持久化,采用日志的形式来记录每个写操作,追加到文件中,重启时再重新执行AOF文件中的命令来恢复数据。它主要解决数据持久化的实时性问题。默认是不开启的。
AOF的工作流程如下:
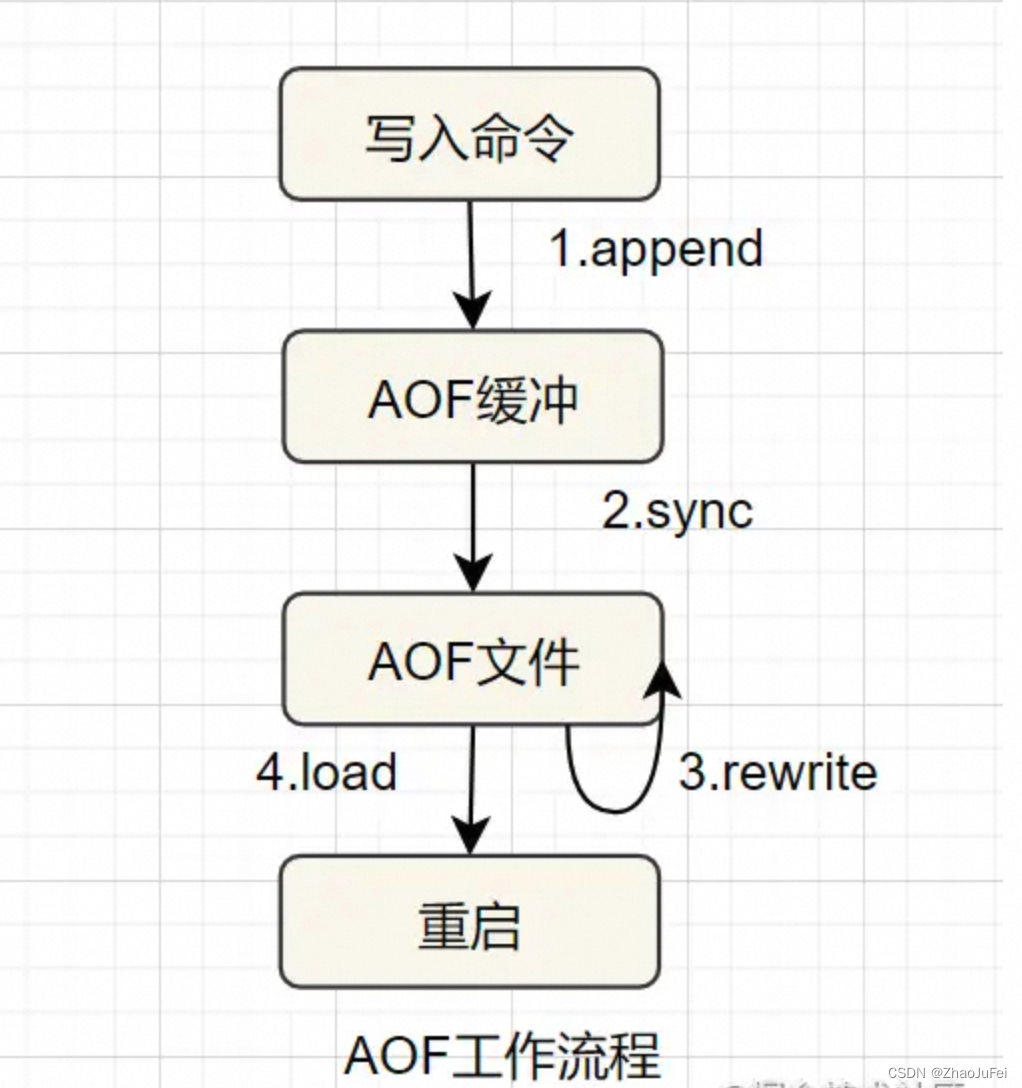
AOF的优点
- 数据的一致性和完整性更高
AOF的缺点
- AOF记录的内容越多,文件越大,数据恢复变慢。
6、Redis 实现高可用有三种部署模式:主从模式,哨兵模式,集群模式。
Redis 支持几种不同的高可用性和故障转移策略。这些模式分别为:
-
主从模式 (Master-Slave Replication): Redis 主从复制允许多个从服务器(slaves)拷贝一个主服务器(master)的数据集。在这个模式下,数据写入是由单个主服务器处理的,然后数据会被复制到一个或多个从服务器。如果主服务器出现故障,可以手动将其中一个从服务器提升为新的主服务器。不过,这个过程并不是自动的,需要管理员介入。
-
哨兵模式 (Sentinel): Redis Sentinel 是一个监控和自动故障转移系统。Sentinel 能够监控主服务器和从服务器,并在检测到主服务器不可用的情况下,自动从从服务器中选举出新的主服务器。这个过程是自动的,不需要管理员手动干预。Sentinel 可以提供更高的可用性,因为它能够在主服务器故障时自动进行故障转移。
Spring Data Redis 提供了对哨兵模式的支持,这样应用程序就不需要在发生主从切换时进行 手动干预。以下是如何在 Spring Boot 应用程序中配置 Redis 哨兵支持的一个基本示例:
- # application.yml 或 application.properties 中的配置
- spring:
- redis:
- sentinel:
- master: mymaster # 这是你在哨兵配置中设置的主节点名称
- nodes:
- - sentinel-host1:26379 # 这里的 IP 和端口是你的哨兵实例
- - sentinel-host2:26379
- - sentinel-host3:26379
- password: your-redis-password # 如果你的 Redis 设置了密码
在你的 Spring Boot 应用程序中进行了上述配置后,Spring Data Redis 会自动使用哨兵来发现当前的主节点,并且在主节点发生变化时自动更新连接。这样,即使发生故障转移,你的应用程序也可以继续与新的主节点进行通信,而无需任何手动干预。
为了完整性,请确保你添加了 Spring Boot 的 Redis Starter 依赖:
- <!-- 在你的 pom.xml 中添加 Spring Boot Redis Starter -->
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-data-redis</artifactId>
- </dependency>
使用 Spring Data Redis 和 Spring Boot 的自动配置特性,可以极大地简化哨兵模式的使用,同时确保你的应用程序能够充分应对 Redis 主节点的变化。
-
集群模式 (Cluster): Redis 集群提供了数据的自动分片(sharding)和复制。在这种模式下,数据被分散存储在多个节点上,每个节点负责维护集群数据的一部分。集群模式支持多个主节点(master nodes)和从节点(slave nodes),如果某个主节点失败,它对应的从节点可以自动升级为主节点,实现故障转移。这种模式可以提供很高的性能和良好的可伸缩性,适合大规模数据环境。
- spring:
- redis:
- cluster:
- nodes:
- - node1-host:6379
- - node2-host:6379
- - node3-host:6379
- max-redirects: 3
- password: your-redis-password # 如果你的 Redis 集群配置了密码
在这里:
spring.redis.cluster.nodes是你的 Redis 集群节点列表,节点由它们的主机名和端口组成。spring.redis.cluster.max-redirects是在集群模式下,客户端在执行命令时,因为键被重新分配到其他节点时,允许的最大重定向次数。spring.redis.password是连接到 Redis 集群节点所需的密码。
配置完成后,Spring Boot 会自动配置 Lettuce 或 Jedis 作为 Redis 客户端,以连接到你的 Redis 集群。这种方式允许你的 Spring Boot 应用程序利用 Redis 集群的所有优点,包括自动分片和高可用性。
无论是哨兵模式还是集群模式,代码级别的操作基本相同,因为 Spring Boot 的抽象层已经为我们处理了底层的细节。您只需要在配置中指定相应的模式,然后在代码中就可以使用 StringRedisTemplate 或 RedisTemplate 进行操作。
每种模式都有其优缺点,并且适用于不同的场景。在选择部署模式时,需要考虑数据的一致性要求、系统的复杂性、管理成本以及性能等因素。
7、对于哨兵模式和集群模式,如果我想在config类里自己创建RedisTemplate,该怎么做?
即使在哨兵模式和集群模式下,如果你想自定义 RedisTemplate,你仍然需要引入 spring-boot-starter-data-redis 依赖。这个 starter 会自动配置 Redis 连接工厂,无论是用于哨兵模式的 RedisSentinelConfiguration 还是集群模式的 RedisClusterConfiguration。你可以创建一个配置类,在其中定义你自己的 RedisTemplate Bean。
以下是如何自定义 RedisTemplate 的例子,分别用于哨兵模式和集群模式:
- import org.springframework.beans.factory.annotation.Autowired;
- import org.springframework.context.annotation.Bean;
- import org.springframework.context.annotation.Configuration;
- import org.springframework.data.redis.connection.RedisConnectionFactory;
- import org.springframework.data.redis.core.RedisTemplate;
- import org.springframework.data.redis.serializer.GenericToStringSerializer;
-
- @Configuration
- public class RedisSentinelConfig {
-
- @Autowired
- private RedisConnectionFactory redisConnectionFactory;
-
- @Bean
- public RedisTemplate<String, Object> redisTemplate() {
- RedisTemplate<String, Object> template = new RedisTemplate<>();
- template.setConnectionFactory(redisConnectionFactory);
- template.setValueSerializer(new GenericToStringSerializer<>(Object.class));
- return template;
- }
- }
集群模式下自定义 RedisTemplate
- import org.springframework.beans.factory.annotation.Autowired;
- import org.springframework.context.annotation.Bean;
- import org.springframework.context.annotation.Configuration;
- import org.springframework.data.redis.connection.RedisConnectionFactory;
- import org.springframework.data.redis.core.RedisTemplate;
- import org.springframework.data.redis.serializer.GenericToStringSerializer;
-
- @Configuration
- public class RedisClusterConfig {
-
- @Autowired
- private RedisConnectionFactory redisConnectionFactory;
-
- @Bean
- public RedisTemplate<String, Object> redisTemplate() {
- RedisTemplate<String, Object> template = new RedisTemplate<>();
- template.setConnectionFactory(redisConnectionFactory);
- template.setValueSerializer(new GenericToStringSerializer<>(Object.class));
- return template;
- }
- }
在这两个配置类中,我们注入了 RedisConnectionFactory,它会根据你在 application.properties 或 application.yml 中的配置自动装配。然后我们创建了一个 RedisTemplate<String, Object> Bean,并将连接工厂设置为注入的连接工厂。
在这里,GenericToStringSerializer 是一个序列化器,它可以处理你的对象序列化。当然,你可以根据你的需要选择其他序列化器,例如 Jackson2JsonRedisSerializer,JdkSerializationRedisSerializer 等。
最后,不要忘记在 application.properties 或 application.yml 中配置你的 Redis 哨兵或集群信息。
通过这种方式,你可以自定义 RedisTemplate 以满足你的特定需求,比如自定义序列化机制或启用事务支持。
8、Redisson使用哨兵模式和集群模式
Redisson 是一个高级的 Redis 客户端,它提供了丰富的功能,包括分布式数据结构和同步器,以及对哨兵模式和集群模式的支持。为了使用 Redisson 进行故障转移(failover),你需要根据你的部署环境(哨兵或集群)配置 Redisson。
以下是如何配置 Redisson 来支持哨兵模式和集群模式的示例。
哨兵模式
- 添加 Redisson 依赖到你的项目中。如果你使用 Maven,在
pom.xml文件中添加如下依赖:- <dependency>
- <groupId>org.redisson</groupId>
- <artifactId>redisson</artifactId>
- <version>最新版本</version>
- </dependency>
- 创建一个配置类来配置 Redisson 客户端:
- import org.redisson.Redisson;
- import org.redisson.api.RedissonClient;
- import org.redisson.config.Config;
- import org.redisson.config.SentinelServersConfig;
- import org.springframework.context.annotation.Bean;
- import org.springframework.context.annotation.Configuration;
- @Configuration
- public class RedissonConfig {
- @Bean(destroyMethod = "shutdown")
- public RedissonClient redissonSentinel() {
- Config config = new Config();
- SentinelServersConfig sentinelConfig = config.useSentinelServers()
- .addSentinelAddress("redis://sentinel-host1:26379", "redis://sentinel-host2:26379", "redis://sentinel-host3:26379")
- .setMasterName("mymaster")
- .setPassword("your-redis-password") // 如果设置了密码
- .setReadMode(ReadMode.SLAVE) // 可以设置读取操作使用从节点
- .setFailedSlaveCheckInterval(1000); // 检查失败从节点的时间间隔,单位是毫秒
- return Redisson.create(config);
- }
- }
集群模式
-
同样的,确保 Redisson 依赖已经添加到你的项目中。
-
创建一个配置类来配置 Redisson 客户端:
- import org.redisson.Redisson;
- import org.redisson.api.RedissonClient;
- import org.redisson.config.ClusterServersConfig;
- import org.redisson.config.Config;
- import org.springframework.context.annotation.Bean;
- import org.springframework.context.annotation.Configuration;
- @Configuration
- public class RedissonConfig {
- @Bean(destroyMethod = "shutdown")
- public RedissonClient redissonCluster() {
- Config config = new Config();
- ClusterServersConfig clusterConfig = config.useClusterServers()
- .addNodeAddress("redis://node1-host:6379", "redis://node2-host:6379", "redis://node3-host:6379")
- .setPassword("your-redis-password") // 如果设置了密码
- .setReadMode(ReadMode.SLAVE) // 可以设置读取操作使用从节点
- .setFailedSlaveCheckInterval(1000); // 检查失败从节点的时间间隔,单位是毫秒
- return Redisson.create(config);
- }
- }
请注意,在配置类中创建的 RedissonClient Bean 都使用了
destroyMethod = "shutdown",这样当 Spring 容器关闭时,Redisson 客户端会正确地关闭其连接。Failover 支持
Redisson 内置支持故障转移,它会自动处理哨兵和集群模式下的节点故障。在哨兵模式下,如果主节点故障,Redisson 会自动连接到新的主节点。在集群模式下,Redisson 能够自动重新路由到正确的节点,即使在节点故障或数据槽迁移后。
确保使用适合你部署场景的配置,并且正确地将 RedissonClient 实例注入到你需要进行 Redis 操作的类中。Redisson 提供了一系列丰富的方法和操作来与 Redis 进行交互。
9、RedisTemplate 为什么不需要加 destroyMethod?
RedisTemplate 是 Spring Data Redis 提供的一个高级抽象,它简化了与 Redis 数据库的交互。在Spring容器中,RedisTemplate 依赖于 RedisConnectionFactory 来创建与 Redis 服务器的连接。
RedisConnectionFactory 是一个更低级别的抽象,它管理着 Redis 连接的生命周期。当 Spring 应用程序上下文关闭时,Spring 容器会负责关闭所有的单例 bean,包括 RedisConnectionFactory。由于 RedisConnectionFactory 负责管理连接,它会在销毁过程中关闭并清理所有打开的 Redis 连接。
因此,RedisTemplate 本身不需要一个专门的 destroyMethod。当 RedisConnectionFactory 被销毁时,所有通过它创建的连接都会被关闭。这意味着,在大多数情况下,RedisTemplate 不需要进行特别的清理或关闭动作。
这与 RedissonClient 不同,RedissonClient 作为 Redisson 库的一部分,是一个独立的客户端实例,它管理着自己的连接池和线程。因此,需要明确地调用 shutdown 方法来释放资源,关闭所有线程并清理连接池。在 Spring 中,通过 destroyMethod 属性指定 shutdown 方法,确保在 Spring 容器关闭时,RedissonClient 实例能够正确地被销毁。
总的来说,Spring 框架提供了资源管理和清理的机制,确保了在容器关闭时资源得到释放。对于大多数 Spring 管理的 bean,无需手动指定 destroyMethod,除非这些 bean 需要特定的清理逻辑。
10、config类与start中的类
当你在自己的配置类中创建自定义的 RedisTemplate、RedisConnectionFactory 或任何其他 Bean 时,Spring Boot 的自动配置机制会尝试尊重你的定义,并且在可能的情况下避免重复创建相同类型的 Bean。
Spring Boot 通过条件注解(如 @ConditionalOnMissingBean、@ConditionalOnBean、@ConditionalOnClass 等)来控制自动配置的条件。例如,对于 RedisAutoConfiguration,Spring Boot 会检查是否已经存在一个 RedisConnectionFactory Bean。如果存在,它就不会再创建一个新的 RedisConnectionFactory。这个逻辑同样适用于 RedisTemplate 和其他的自动配置 Bean。
在你的配置类中定义的 Bean 将会“覆盖”自动配置的 Bean,前提是你定义的 Bean 名称与自动配置尝试创建的 Bean 名称相同,或者你的 Bean 类型在应用上下文中是唯一的。Spring Boot 会根据上下文中已存在的 Bean 来调整其自动配置。
例如,如果你定义了一个 RedisConnectionFactory Bean,Spring Boot 将使用你提供的这个 Bean 来配置 RedisTemplate,而不是创建一个新的连接工厂。这种方式确保了你的自定义配置会被应用,并且不会与 Spring Boot 的自动配置发生冲突。
要确保你的自定义配置覆盖了 Spring Boot 的自动配置,你可以使用 @Primary 注解在你的 Bean 上,或者确保你的 Bean 名字与自动配置中创建的 Bean 名字相匹配。@Primary 注解告诉 Spring 容器在存在多个相同类型的 Bean 时优先使用被 @Primary 注解标记的 Bean。
11. 聊聊Redis 事务机制
Redis通过MULTI、EXEC、WATCH等一组命令集合,来实现事务机制。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。
简言之,Redis事务就是顺序性、一次性、排他性的执行一个队列中的一系列命令。
Redis执行事务的流程如下:
- 开始事务(MULTI)
- 命令入队
- 执行事务(EXEC)、撤销事务(DISCARD )

