- 1医学生怎么搜题?学生党都在用的8款搜题工具来了 #其他#知识分享#笔记_九超查题
- 2c语言怎么编程机器人,移动机器人(电子球)编程(c语言)
- 3【API篇】六、Flink输出算子Sink_flink sink
- 4Python之pyc文件的生成与反编译
- 5Golang入门
- 6Xcode因为证书问题经常报的那些错_xcode 15.3 打包ipa 报错描述文件不包含证书
- 7postman使用方法
- 8推荐开源项目:SD-WebUI-StableSR - 构建高效稳定前端界面的利器
- 9精度不够,滑动时间来凑「限流算法第二把法器:滑动时间窗口算法」- 第301篇_滑动时间窗口计数
- 10Kubernate之安装(实战)_unknown flag: --admissioncontrol
伪分布式Spark集群搭建_spark伪分布式集群搭建
赞
踩
一、软件环境
| 软 件 | 版 本 | 安 装 包 |
| VMware虚拟机 | 16 | VMware-workstation-full-16.2.2-19200509.exe |
| SSH连接工具 | FinalShell | |
| Linux OS | CentOS7.5 | CentOS-7.5-x86_64-DVD-1804.iso |
| JDK | 1.8 | jdk-8u161-linux-x64.tar.gz |
| Spark | 3.2.1 | spark-3.2.1-bin-hadoop2.7.tgz |
二、实训操作步骤
技能点1:Final Shell连接虚拟机
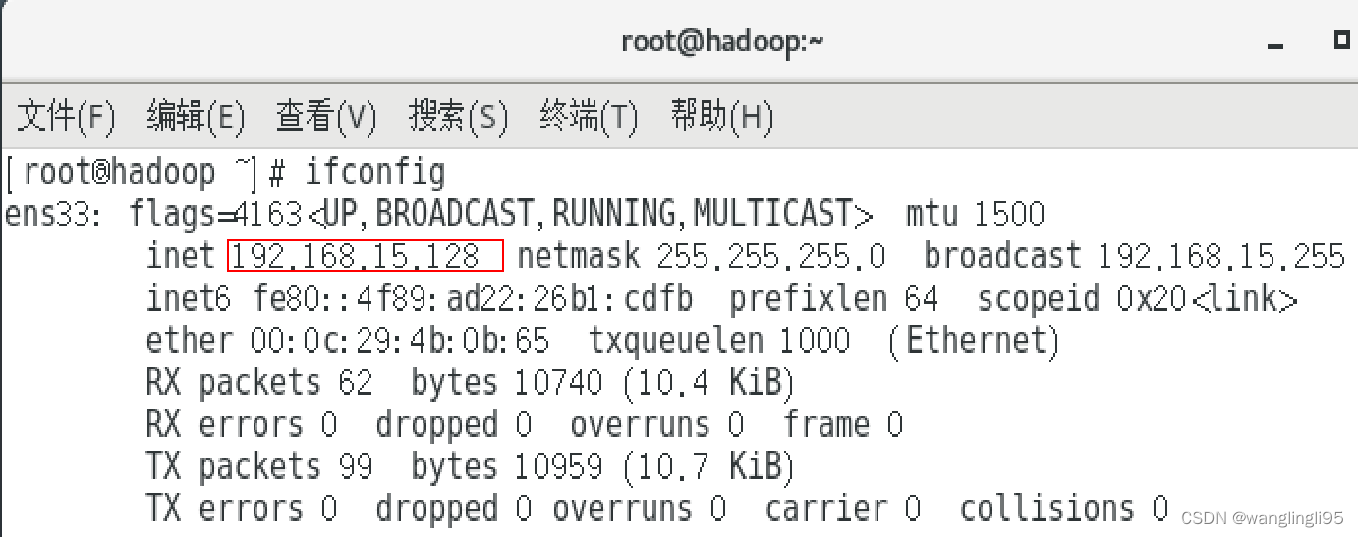
①打开虚拟机终端,输入命令ifconfig,查看虚拟机的IP地址。
②打开Final Shell,进行SSH连接虚拟机。

③设置IP地址,使用root账户和密码进行连接登录。

技能点2:上传Spark安装包并解压
①上传Spark安装包
使用FinalShell软件将HBase安装包spark-3.2.1-bin-hadoop2.7.tgz上传至虚拟机的/opt目录下。

②解压Spark安装包
使用“tar”命令将HBase解压至/usr/local目录下,具体命令如下:
tar -zxvf /opt/spark-3.2.1-bin-hadoop2.7.tgz -C /usr/local/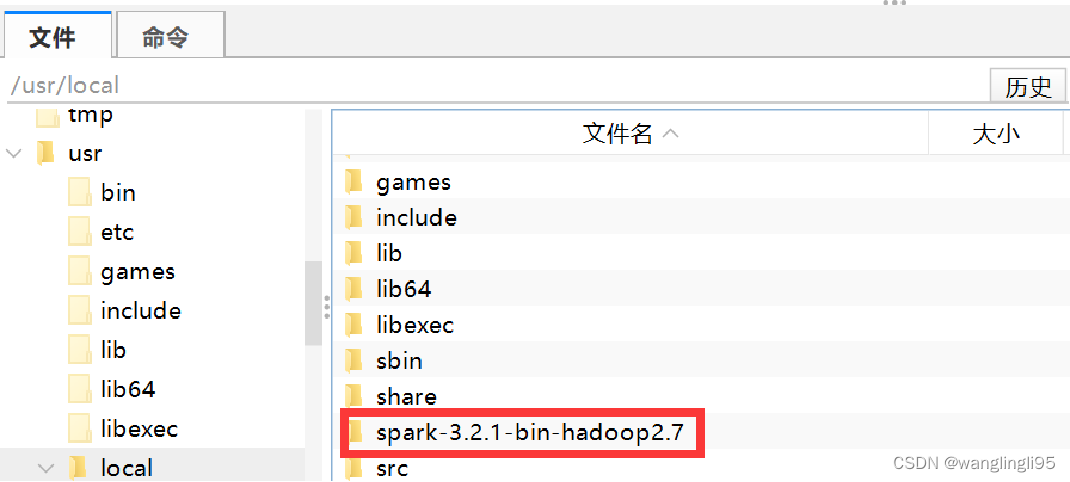
技能点3:配置spark-env.sh文件
①进入到Spark安装包的conf目录下,具体命令如下:
cd /usr/local/spark-3.2.1-bin-hadoop2.7/conf②将spark-env.sh.template复制为spark-env.sh,具体命令如下:
cp spark-env.sh.template spark-env.sh③输入“vi spark-env.sh”命令,打开文件,在文件末尾添加如下代码:
- #Jdk安装路径
-
- export JAVA_HOME=/usr/local/jdk1.8.0_161
-
- #Hadoop安装路径
-
- export HADOOP_HOME=/usr/local/hadoop-3.1.4
-
- #Hadoop配置文件的路径
-
- export HADOOP_CONF_DIR=/usr/local/hadoop-3.1.4/etc/hadoop
-
- #Spark主节点的IP地址或机器名
-
- export SPARK_MASTER_IP=hadoop
-
- #Spark本地的IP地址或机器名
-
- export SPARK_LOCAL_IP=hadoop

技能点4:启动测试Spark集群
①目录切换到sbin目录下启动集群。
- #进入到sbin目录下
- cd /usr/local/spark-3.2.1-bin-hadoop2.7/sbin
-
- #启动spark集群
-
- ./start-all.sh
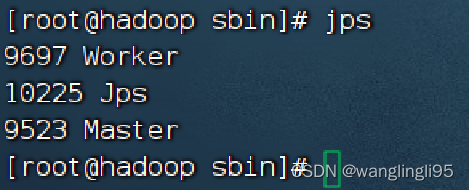
②jps查看进程。
③切换到Spark安装包的/bin目录下(cd /usr/local/spark-3.2.1-bin-hadoop2.7/bin),使用SparkPi来计算Pi的值。
- #切换到Spark安装包的/bin目录下
- cd /usr/local/spark-3.2.1-bin-hadoop2.7/bin
- #运行程序
- ./run-example SparkPi 2
![]()
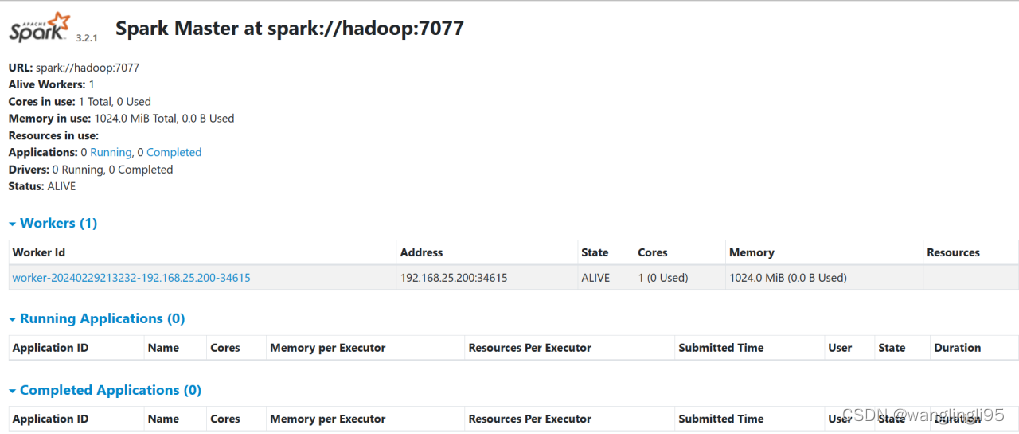
技能点5:浏览器访问Spark 页面
①关闭防火墙 输入命令“systemctl stop firewalld.service”
②打开浏览器访问Spark自带web页面 浏览器输入网址:http://192.168.15.128:8080/
③效果图如下