
- 1基于区块链的不动产登记电子证照应用服务系统设计方案---3.总体设计_基于区块链的可信电子证照方案设计
- 2Qt Design Studio使用场景
- 3Qt Quick QML 与 C++ 交互系列之二
- 4自然语言处理在智能客服中的实践与优化
- 5元学习Meta-Learning_元学习的情景训练
- 6一切皆是映射:AI的去中心化:区块链技术的融合
- 7macOS系统安装pycharm社区版本_pycharm社区版本下载mac
- 8火车票预售系统(JavaGUI)_网上购票系统java+gui界面
- 9快速查询的秘籍 —— B+索引的建立_索引 b+ 页中查询
- 10骨架算法(skeleton)的实现_skeleton3d函数图示
Flink 六道必考面试题总结_flink面试题
赞
踩
1.Flink如何保证Exactly-Once
-
使用checkpoint检查点,其实就是 所有任务的状态,在某个时间点的一份快照;这个时间点,应该是所有任务都恰好处理完一个相同 的输入数据的时候。
-
checkpoint的步骤:
-
flink应用在启动的时候,flink的JobManager创建CheckpointCoordinator
-
CheckpointCoordinator(检查点协调器) 周期性的向该流应用的所有source算子发送barrier(屏障)。
-
当某个source算子收到一个barrier时,便暂停数据处理过程,然后将自己的当前状态制作成快照,并保存到指定的持久化存储(hdfs)中,最后向CheckpointCoordinator报告自己快照制作情况,同时向自身所有下游算子广播该barrier,恢复数据处理
-
下游算子收到barrier之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理。
-
每个算子按照 上面这个操作 不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。
-
当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功; 否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败。
-
Flink 保证 Exactly-Once 的方式主要依赖于其 checkpoint 机制。Checkpoint 机制是 Flink 实现容错机制最核心的功能,能够根据配置周期性地基于 Stream 中各个 Operator 的状态来生成 Snapshot(快照),从而将这些状态数据定期持久化存储下来。当 Flink 程序一旦意外崩溃时,重新运行程序时可以有选择地从这些 Snapshot 进行恢复,从而修正因为故障带来的程序数据状态中断。
Checkpoint 的作用在于:
- 恢复数据一致性:在某个算子因为某些原因(如异常退出)出现故障时,Flink 可以将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性。
- 保证 Exactly-Once 语义:在 Flink 中,为了保证 Exactly-Once 语义,需要满足以下三点:
- Flink 需要开启 checkpoint;
- 数据源需要支持数据重发;
- 数据接收端需要实现幂等性写入和事务性写入。
- 通过两阶段提交协议,Flink 可以保证从数据源到数据输出的 Exactly-Once 语义。
Checkpoint 的实现步骤主要包括以下内容:
- 将 Checkpoint 标记写入日志,并记录下 Checkpoint RBA(Recovery Block Address),这个通常是当前的 RBA。
- Checkpoint 进程通知 DBWn 进程将所有 Checkpoint RBA 之前的 buffer cache 里面的脏块写入磁盘。
- 确定脏块都被写入磁盘以后,Checkpoint 进程将 Checkpoint 信息(SCN)写入/更新数据文件和控制文件中。SCN 是发出检查点命令时对应的 SCN。
在 Flink 中,Checkpoint 的过程包括以下具体步骤:
- 在每个时间间隔,如每秒或每分钟,Flink 都会触发一个 Checkpoint。这个时间间隔由用户在 Flink 配置中设定。
- Checkpoint 进程首先会收集网络上的信息,包括流量、日志、事件等。这些信息可以从多个源头获取,例如网络设备、安全设备、服务器等。收集的信息会被存储在 Checkpoint 的数据库中,以供后续的分析和处理。
- Checkpoint 进程会对收集到的信息进行分析,以确定是否存在安全威胁。分析的过程包括以下几个方面:
- 安全策略分析:检查网络上的流量是否符合安全策略,例如是否允许访问某个特定的端口或协议。
- 威胁分析:检查网络上的流量是否包含恶意的攻击行为,例如病毒、木马、DoS攻击等。
- 行为分析:检查网络上的流量是否存在异常行为,例如大量的连接请求、重复的访问等。
- Checkpoint 进程会通知 DBWn 进程将所有脏块写入磁盘。这些脏块包含了未提交事务所修改的数据。物理位置连续的页会放在一起集中写入,以提高写入性能。新分配的缓存块不会被写入。
- 所有脏块都写入磁盘后,Checkpoint 进程会将所有的脏页都标记为“clean”。
- 最后,Checkpoint 进程会将结束的 Checkpoint 标记写入日志,并将 Log Block 写入持久化存储。这样,当 Flink 系统出现故障时,可以通过 Checkpoint 恢复数据的一致性。
2.Flink的双流Join分为哪几类
-
分为window join和interval join两种
-
window join:将两条实时流中元素分配到同一个时间窗口中完成Join
-
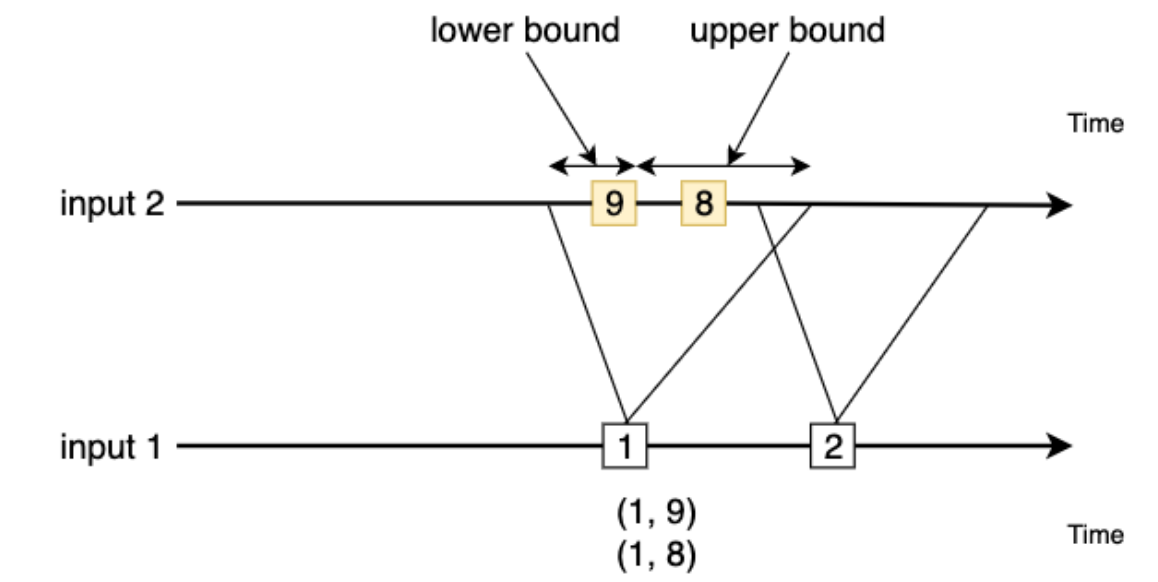
interval join:根据右流相对左流偏移的时间区间(interval)作为关联窗口,在偏移区间窗口中完成join操作
-
window join


间隔联结(Interval Join)

3.Flink是如何处理反压的
-
反压就是指下游数据的处理速度跟不上上游数据的生产速度,Flink处理反压的流程如下:
- 每个TaskManager维护共享Network BufferPool(Task共享内存池),初始化时向Off-heap Memory中申请内存。
- 每个Task创建自身的Local BufferPool(Task本地内存池),并和Network BufferPool交换内存。
- 上游Record Writer向 Local BufferPool申请buffer(内存)写数据。如果Local BufferPool没有足够内存则向Network BufferPool申请,使用完之后将申请的内存返回Pool。
- Netty Buffer拷贝buffer并经过Socket Buffer发送到网络,后续下游端按照相似机制处理。
- 当下游申请buffer失败时,表示当前节点内存不够,则逐层发送反压信号给上游,上游慢慢停止数据发送,直到下游再次恢复。
什么是反压(backpressure)
反压通常是从某个节点传导至数据源并降低数据源(比如 Kafka consumer)的摄入速率。反压意味着数据管道中某个节点成为瓶颈,处理速率跟不上上游发送数据的速率,而需要对上游进行限速。
反压的影响
反压并不会直接影响作业的可用性,它表明作业处于亚健康的状态,有潜在的性能瓶颈并可能导致更大的数据处理延迟。反压对Flink 作业的影响:
checkpoint时长:checkpoint barrier跟随普通数据流动,如果数据处理被阻塞,使得checkpoint barrier流经整个数据管道的时长变长,导致checkpoint 总体时间变长。
state大小:为保证Exactly-Once准确一次,对于有两个以上输入管道的 Operator,checkpoint barrier需要对齐,即接受到较快的输入管道的barrier后,它后面数据会被缓存起来但不处理,直到较慢的输入管道的barrier也到达。这些被缓存的数据会被放到state 里面,导致checkpoint变大。
checkpoint是保证准确一次的关键,checkpoint时间变长有可能导致checkpoint超时失败,而state大小可能拖慢checkpoint甚至导致OOM。
Flink的反压
1.5 版本之前是采用 TCP 流控机制,而没有采用feedback机制
TCP报文段首部有16位窗口字段,当接收方收到发送方的数据后,ACK响应报文中就将自身缓冲区的剩余大小设置到放入16位窗口字段。该窗口字段值是随网络传输的情况变化的,窗口越大,网络吞吐量越高。TCP 利用滑动窗口限制流量:
TCP 利用滑动窗口实现网络流控
4.Flink的watermark如何理解
简单来说,它就是一种特殊的时间戳,作用就是为了让事件时间慢一点,等迟到的数据都到了,才触发窗口计算。我举个例子说一下为什么会出现watermark?
比如现在开了一个5秒的窗口,但是2秒的数据在5秒数据之后到来,那么5秒的数据来了,是否要关闭窗口呢?可想而知,关了的话,2秒的数据就丢失了,如果不关的话,我们应该等多久呢?所以需要有一个机制来保证一个特定的时间后,关闭窗口,这个机制就是watermark
从设备生成实时流事件,到Flink的source,再到多个oparator处理数据,过程中会受到网络延迟、背压等多种因素影响造成数据乱序。在进行窗口处理时,不可能无限期的等待延迟数据到达,当到达特定watermark时,认为在watermark之前的数据已经全部达到(即使后面还有延迟的数据), 可以触发窗口计算,这个机制就是 Watermark(水位线),具体如下图所示。
水位线可以用于平衡延迟和结果的完整性,它控制着执行某些计算需要等待的时间。这个时间是预估的,现实中不存在完美的水位线,因为总会存在延迟的记录。现实处理中,需要我们足够了解从数据生成到数据源的整个过程,来估算延迟的上线,才能更好的设置水位线。
如果水位线设置的过于宽松,好处是计算时能保证近可能多的数据被收集到,但由于此时的水位线远落后于处理记录的时间戳,导致产生的数据结果延迟较大。
如果设置的水位线过于紧迫,数据结果的时效性当然会更好,但由于水位线大于部分记录的时间戳,数据的完整性就会打折扣。
所以,水位线的设置需要更多的去了解数据,并在数据时效性和完整性上有一个权衡。
5.Flink的窗口机制分为哪几类
-
分为Time Window、Count Window和Session Window三种
-
时间窗口根据时间对数据进行划分,分为Tumbling Time Window和Sliding Time Window,其中滚动时间窗口会将数据流切分成不重叠的窗口,每一个事件只能属于一个窗口;滚动时间窗口中的一条数据可以对应多个窗口
-
计数窗口根据元素个数对数据进行划分,分为Tumbling Count Window和Sliding Count Window
-
会话窗口根据会话来对数据进行划分,简单来说,就是数据来了之后就开启一个会话窗口,如果接下来还有数据陆续到来,那么就一直保持会话;如果一段时间一直没收到数据,那就认为会话超时失效,窗口自动关闭
-
6.Flink是如何处理迟到数据的
-
watermark设置延迟时间
-
window的allowedLateness方法,可以设置窗口允许处理迟到数据的时间
-
window的sideOutputLateData方法,可以将迟到的数据写入侧输出流

