
- 1uboot代码分析_uboot 源码分析
- 2windows下使用ngrok让本地flask服务外网可访问_flask 发布到网上别人可以访问
- 3#if defined 宏定义常用“与”、“或”、“非”判断_ifdef判断两个宏
- 4github搭建博客_怎么搭建github
- 5总结:Prometheus长期存储方案_prometheus 存储
- 6496.下一个更大的元素
- 7分布式系统共识机制:一致性算法设计思想_分布式系统一致性设计
- 8【云计算学习教程】用户如何使用云服务产品?_云服务消费者从云服务提供商或者云服务代理商那里租赁云服务产品在合同期内和
- 9少年侠客【InsCode Stable Diffusion美图活动一期】_stable diffusion调参
- 10[论文笔记]LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
多目标优化 | NSGA-Ⅲ(上篇,附MATLAB代码)_nsga-iii什么时候
赞
踩
今天为各位讲解多目标优化算法NSGA-Ⅲ,实际上我们分别在NSGA-II多目标优化算法讲解(附MATLAB代码)、多目标优化 | 基于NSGA-II的多目标0-1背包问题求解(附matlab代码)、多目标优化 | NSGA-II进阶教程(全网首个三目标优化教程)这几篇推文中对NSGA-Ⅱ做了详细讲解。
那今天讲解的NSGA-Ⅲ实际上和NSGA-Ⅱ只是在选择机制上有区别,其他步骤完全相同。因此,需要各位先回顾一下NSGA-Ⅱ的基本步骤。
在这里,还有一个基本问题需要各位注意一下,NSGA-Ⅱ是multi-objective优化,即多目标优化,而NSGA-Ⅲ的many-objective优化,即超多目标优化。其中,multi-objective(多目标)指的是2或3个优化目标,many-objective(超多目标)指的是至少4个优化目标。
因此,NSGA-Ⅲ的优势是求解超多目标优化问题,即4个及以上的多目标优化问题。
※注:由于NSGA-Ⅲ内容较多,所以将这部分内容讲解分成两篇推文讲解。
目录
- NSGA-Ⅱ求解步骤回顾
- NSGA-Ⅲ算法设计思路
- NSGA-Ⅲ代码获取方式
- 参考文献
NSGA-Ⅱ求解步骤回顾
遗传算法GA伪代码
无论是NSGA-Ⅱ,还是NSGA-Ⅲ,它们的基础都是遗传算法GA。GA的伪代码如下:

GA的基本思路为,种群初始化→进入主循环→选择操作→交叉操作→变异操作→种群更新操作→输出全局最优解。
NSGA-Ⅱ整体伪代码
在了解了GA的基本思路后,再来看一下NSGA-Ⅱ的基本思路:

NSGA-Ⅱ与GA的一大差异在于个体的选择机制。
GA是通过轮盘赌选择或锦标赛选择等选择方式,从父代种群(种群数目为 N N N)中选择若干个个体组成子代种群,一般来说子代种群数目 N 1 N_1 N1小于父代种群数目 N N N。
而NSGA-Ⅱ先将父代种群 P t P_{t} Pt(种群数目为 N N N)与子代种群 Q t Q_{t} Qt(种群数目为 N N N)合并 R t = P t ∪ Q t R_{t}=P_{t}\cup Q_{t} Rt=Pt∪Qt(种群数目为 2 N 2N 2N),其次对合并后的种群(种群数目为 2 N 2N 2N)进行快速非支配排序 F = fast-non-dominated-sort ( R t ) \mathcal{F}=\text { fast-non-dominated-sort }\left(R_{t}\right) F= fast-non-dominated-sort (Rt),然后根据非支配排序结果以及拥挤度距离计算结果 crowding-distance-assignment ( F i ) \text { crowding-distance-assignment }\left(\mathcal{F}_{i}\right) crowding-distance-assignment (Fi),从合并种群(种群数目为 2 N 2N 2N)中选择出 N N N个个体。
NSGA-Ⅱ快速非支配排序伪代码
其中,快速非支配排序 F = fast-non-dominated-sort ( R t ) \mathcal{F}=\text { fast-non-dominated-sort }\left(R_{t}\right) F= fast-non-dominated-sort (Rt)的伪代码如下:

NSGA-Ⅱ拥挤度距离计算伪代码
拥挤度距离计算 crowding-distance-assignment ( F i ) \text { crowding-distance-assignment }\left(\mathcal{F}_{i}\right) crowding-distance-assignment (Fi)伪代码如下:
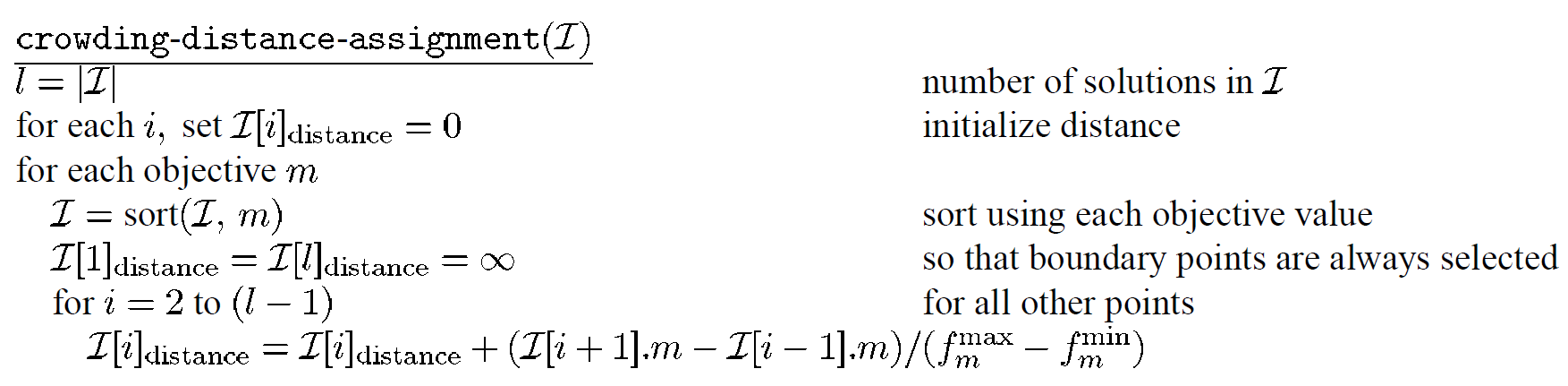
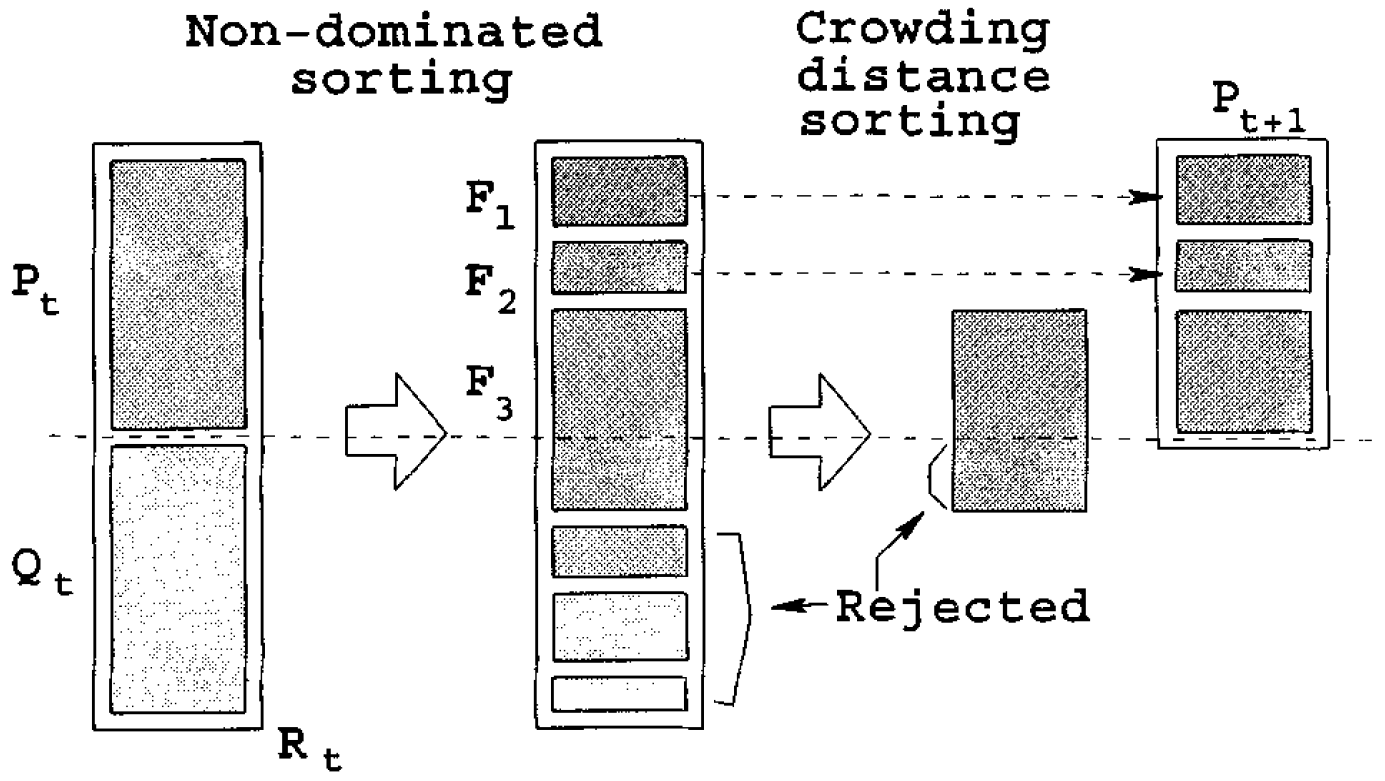
NSGA-Ⅱ示意图
NSGA-Ⅱ核心步骤示意图如下图所示:
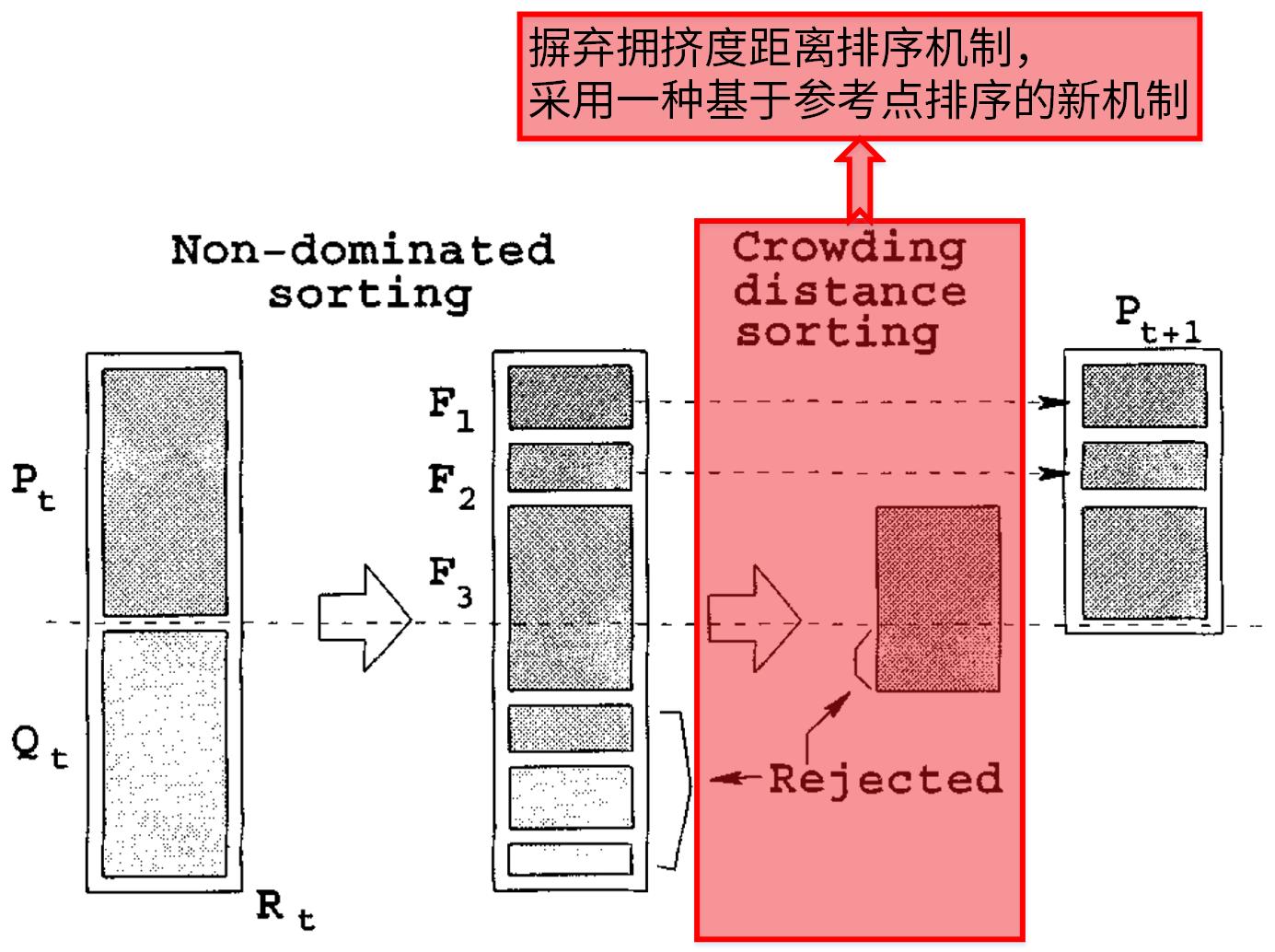
NSGA-Ⅲ算法设计思路
在回顾完NSGA-Ⅱ之后,我们开始今天的主题——NSGA-Ⅲ。实际上,在文章的开篇我们已经提到过,NSGA-Ⅲ与NSGA-Ⅱ的唯一差别在于选择机制。再严格一点,可以说是摒弃拥挤度距离排序机制,而采用一种基于参考点排序的新机制。
NSGA-Ⅲ整体伪代码
我们先给出NSGA-Ⅲ伪代码:

细心的同学已经发现,NSGA-Ⅲ的伪代码实际上和NSGA-Ⅱ的伪代码基本一致,下面我们将这两个伪代码进行对比:

左侧NSGA-Ⅲ标红的地方和右侧NSGA-Ⅱ标红的地方就是两者的差异,即两者的选择机制不同。其它步骤则完全相同。
从选择机制的伪代码行数可以看出,NSGA-Ⅲ的选择机制更为复杂,接下来则重点剖析一下NSGA-Ⅲ的选择机制。
首先需要明确一个问题,如果在进行快速非支配排序后,前 l l l层个体数目之和恰好为 N N N,那就不需要后面基于参考点排序的操作了。
因此,后续基于参考点排序是建立在一个前提之上,即前 l − 1 l-1 l−1层个体数目之和小于 N N N,前 l l l层个体数目之和大于 N N N。也就是说需要在第 l l l层个体 F l F_{l} Fl中选择出 K = N − ∣ P t + 1 ∣ K=N-\left|P_{t+1}\right| K=N−∣Pt+1∣个个体。
参考点生成方法
既然,NSGA-Ⅲ采用一种基于参考点的排序机制,那么就有3个很直接的问题:
-
这些参考点究竟是什么?
-
采用这种基于参考点的排序机制优势在哪里?
-
如何生成这些参考点?
首先回答第一个问题——这些参考点究竟是什么。
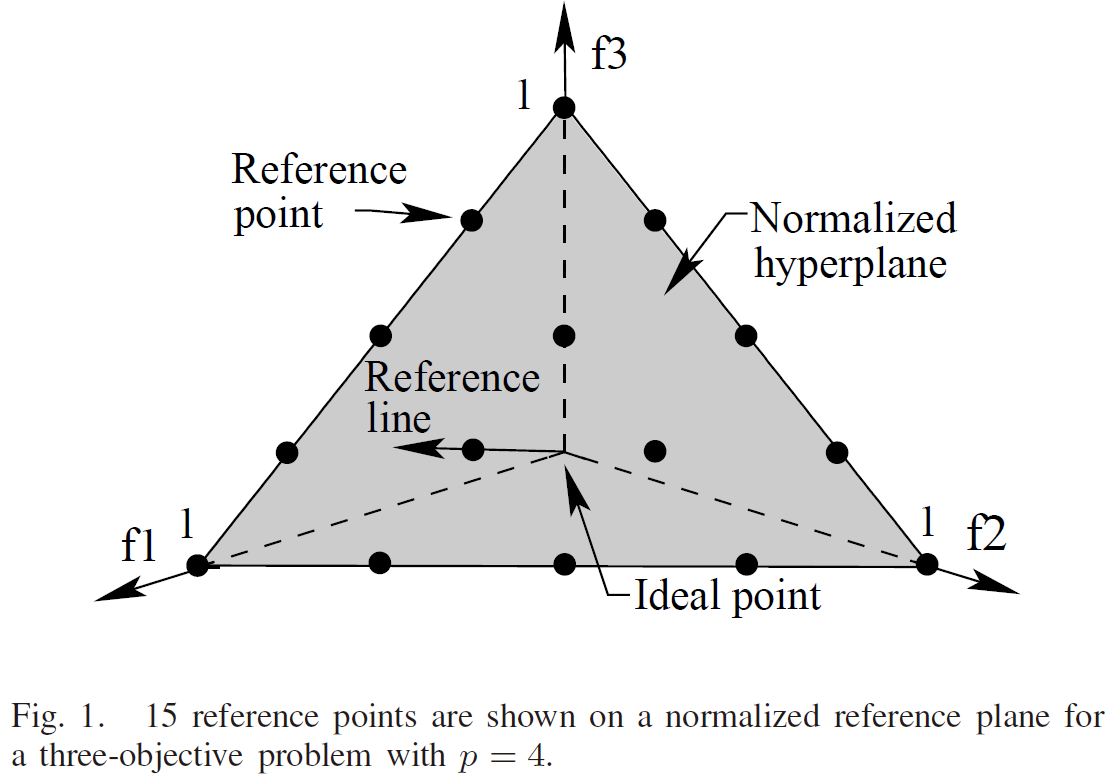
以一个三目标问题为例,这些参考点实际上等间距均匀分布在一个等边三角形平面上,其中这个等边三角形的三个顶点坐标分别为(1,0,0),(0,1,0),(0,0,1),则这些参考点的示意图如下图所示,其中下图中的15个小黑点就是参考点:
接下来回答第二个问题——采用这种基于参考点的排序机制优势在哪里。
我们都希望多目标优化最终获得的帕列托解能够尽可能均匀分布,而不是这里一堆解,那里一堆解。
因为,均匀分布的帕列托解可以为用户提供多个平衡的解决方案,这些解都保留各自的优势。而分块密集的帕列托解很明显不利于用户做决策,很明显只有这几块的解是能够支撑用户决策的,而缺少其它位置的平衡解,显示不是我们多目标优化的初衷。
因此,为了使最终获得的帕列托解能够均匀分布,NSGA-Ⅲ采用基于参考点排序的方式,在解与参考点之间建立联系,因为构造的参考点是均匀分布的,所以我们希望最终生成的帕列托解也可以保持均匀分布的这一特性。
最后回到第三个问题——如何生成这些参考点。
我们先回到第一个问题的那张图,各位要注意一点,这些参考点是等间距分布的。
示意图中的参考点是4等分分布的,这些参考点的几何生成方法如下:
- 先将3个顶点(即(1,0,0),(0,1,0),(0,0,1))进行连线,形成等边三角形。
- 在每条边上进行4等分操作,即每条边各有5个等分点,这些等分点为部分参考点。
- 将与各边平行的各对等分点连线,连线产生的交点为另一部分参考点。
- 上述交点全集即为生成的参考点。
上述参考点生成方式是以3目标为例,4目标及以上的参考点生成方法可以此类推。3目标4等分所生成的参考点示意图如下图所示。
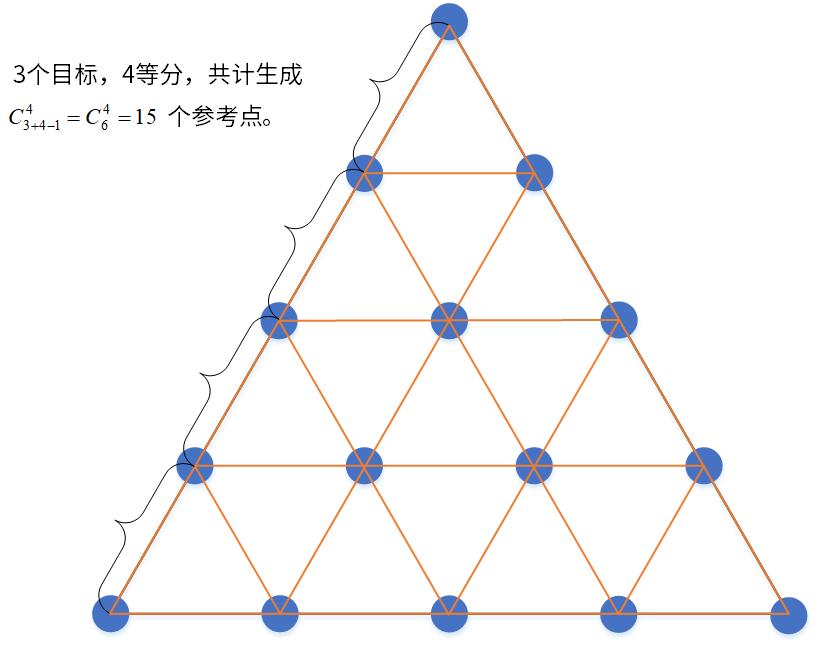
各位可以发现,如果目标数目为 M M M,等分数目为 p p p,则生成的参考点数目 H = C M + p − 1 p H=C_{M+p-1}^{p} H=CM+p−1p。
还是以上述3目标4等分为例,参考点的代数生成方法如下图所示:

4目标5等分的代数生成方法如下图所示:

参考点生成MATLAB代码如下:
function [W,N] = UniformPoint(N,M) %UniformPoint - Generate a set of uniformly distributed points on the unit %hyperplane % % [W,N] = UniformPoint(N,M) returns approximate N uniformly distributed % points with M objectives. % % Example: % [W,N] = UniformPoint(275,10) %-------------------------------------------------------------------------- % Copyright (c) 2016-2017 BIMK Group. You are free to use the PlatEMO for % research purposes. All publications which use this platform or any code % in the platform should acknowledge the use of "PlatEMO" and reference "Ye % Tian, Ran Cheng, Xingyi Zhang, and Yaochu Jin, PlatEMO: A MATLAB Platform % for Evolutionary Multi-Objective Optimization [Educational Forum], IEEE % Computational Intelligence Magazine, 2017, 12(4): 73-87". %-------------------------------------------------------------------------- H1 = 1; while nchoosek(H1+M,M-1) <= N H1 = H1 + 1; end W = nchoosek(1:H1+M-1,M-1) - repmat(0:M-2,nchoosek(H1+M-1,M-1),1) - 1; W = ([W,zeros(size(W,1),1)+H1]-[zeros(size(W,1),1),W])/H1; if H1 < M H2 = 0; while nchoosek(H1+M-1,M-1)+nchoosek(H2+M,M-1) <= N H2 = H2 + 1; end if H2 > 0 W2 = nchoosek(1:H2+M-1,M-1) - repmat(0:M-2,nchoosek(H2+M-1,M-1),1) - 1; W2 = ([W2,zeros(size(W2,1),1)+H2]-[zeros(size(W2,1),1),W2])/H2; W = [W;W2/2+1/(2*M)]; end end W = max(W,1e-6); N = size(W,1); end

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
NSGA-Ⅲ代码获取方式
https://yarpiz.com/456/ypea126-nsga3
参考文献
- Katoch S, Chauhan S S, Kumar V. A review on genetic algorithm: past, present, and future[J]. Multimedia Tools and Applications, 2021, 80: 8091-8126.
- Deb K, Pratap A, Agarwal S, et al. A fast and elitist multiobjective genetic algorithm: NSGA-II[J]. IEEE transactions on evolutionary computation, 2002, 6(2): 182-197.
- Deb K, Jain H. An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: solving problems with box constraints[J]. IEEE transactions on evolutionary computation, 2013, 18(4): 577-601.
- Tian Y, Cheng R, Zhang X, et al. PlatEMO: A MATLAB platform for evolutionary multi-objective optimization [educational forum][J]. IEEE Computational Intelligence Magazine, 2017, 12(4): 73-87.
- Mostapha Kalami Heris, NSGA-III: Non-dominated Sorting Genetic Algorithm, the Third Version — MATLAB Implementation (URL: https://yarpiz.com/456/ypea126-nsga3), Yarpiz, 2016.
- Das I, Dennis J E. Normal-boundary intersection: A new method for generating the Pareto surface in nonlinear multicriteria optimization problems[J]. SIAM journal on optimization, 1998, 8(3): 631-657.
想快速入门智能优化算法的小伙伴可以阅读我们的书籍,本书对算法的讲解详细易懂,对代码的注释也十分完备。
3.6-3.12日京东当当购书5折优惠,想要入手此书的小伙伴可可以抓紧入手哦!

京东自营购买链接:
https://item.jd.com/13422442.html
当当自营购买链接
http://product.dangdang.com/29301483.html
咱们下期再见
近期你可能错过了的好文章
新书上架 | 《MATLAB智能优化算法:从写代码到算法思想》
遗传算法(GA)求解带时间窗的车辆路径(VRPTW)问题MATLAB代码
粒子群优化算法(PSO)求解带时间窗的车辆路径问题(VRPTW)MATLAB代码
知乎 | bilibili | CSDN:随心390

