
- 1SQLI-labs-第二十五关和第二十五a关
- 2PCIe扫盲——PCI总线中的Reflected-Wave Signaling_pci spec规定了每个pci总线上最多可以连接多达32个pci设备
- 3最近收集的9000个英语单词_英语单词9000个
- 4PostgreSQL 数据库实现公网远程连接_postgresql 远程连接
- 5vscode推送gitee方法
- 6雨云游戏云VPS搭建MCSM面板和我的世界(MC)Paper服务器教程_mcsmanager 配置文件改不了
- 7Pytorch :从零搭建一个神经网络_pytorch从零搭建神经网络
- 8激活函数写在forward和Sequential里一样吗
- 9Android应用性能优化
- 10WPA2与WPA3_wpa3和wpa2有什么区别
中车*IoTDB | 构建城市轨道交通车辆智能运维系统,应对日百万人次客流量_全要素与全过程数据融合的城市轨道交通车辆智能运维系统
赞
踩
本文整理自:IoTDB 物联网数据库在城市轨道交通车辆智能运维系统中的应用, 城市轨道交通研究, 2021
原论文作者:姜仕军;徐晓晨;徐燕芬;杜广林
城市轨道交通(以下简称“城轨”)作为大中城市公共交通的主动脉,每天客流量高达几百万人次,且客流量还在不断上升,这对各城市的轨道交通公司的运维能力提出了较高的要求:一方面,要保障的线路安全可靠运行,避免发生安全事故;另一方面,要优化维修计划,将“计划修”转变为“状态修”,从而减少车辆维修时间,降低维修成本。因此,需要采用一种智能化的城轨车辆运维方案,实现对城轨列车关键系统和部件运行状态的实时监测,并依托大数据、人工智能等技术,结合车辆运行和检修数据进行分析挖掘,诊断并预测设备的健康状态,从而保障的车辆安全性和可靠性,即建立城轨车辆智能运维系统。

中国中车股份有限公司(英语:CRRC Corporation Limited,缩写:CRRC),简称中国中车,是中国一家从事铁路机车、铁路车辆、动车组、地铁及其零部件的研发、制造、厂修及 IGBT、公车等周边产业的大型中央企业,是全球最大的轨道交通设备制造商和解决方案供应商。

基于IoTDB时序数据库的特点和优势和其在城轨车辆智能运维系统构建中的适用性,中国中车选择 IoTDB 作为城轨车辆智能运维系统的核心部分,设计了一种轻量化的系统架构,有效提高了存储空间利用率和数据检索效率。
1►业务需求痛点
城轨车辆智能运维系统需要实现从数据采集、数据存储到数据分析、数据展示的全流程、全功能的覆盖。流转于系统内的数据具有变量多、周期短、变化小、时效性强等特点,因此对系统中各功能模块的性能提出了较高要求。
1.1 毫秒级实时数据接收
城轨车辆上安装的数据采集和发送装置可实时采集和发送车辆的运行状态数据和故障数据。城轨车辆智能运维系统可实时获取列车信息。系统需在一个周期(一般为毫秒级)内完成对所有车辆发送的当前周期内数据的校验和存储操作。
1.2 TB级数据存储
城轨车辆智能运维系统所需数据存储空间大。一条城轨线路的列车数量一般在20列以上,每列列车上各子系统的传感器数量可达上万个,需回传至地面系统的变量一般为3000~5000个左右,每个变量至少需14字节(标识符占4字节,时间戳占6字节,值占4字节)。按照500ms的发送周期,及最小的列车数量、变量数、字节数计算,城轨车辆智能运维系统覆盖一条线路时一年所需的存储空间为52980480000000字节,约为48.19TB。当覆盖的线路增多时,数据量将会呈线性增长。
1.3 实时监控
城轨车辆智能运维系统需实现城轨列车运行状态的实时监控,这就要求系统必须在一个数据接收周期内将所有变量当前的最新值更新至显示前端。同时,系统还应提供对历史数据的查询和展示功能,即将一段时间范围内的数据以美观、易理解的图表形式向用户展示出来,并在用户可接受的时间内返回结果。
1.4 便捷计算统计
城轨车辆智能运维系统所接收的数据中,有些需要先进行计算、换算或者统计,然后再进行展示,并希望无需编写复杂的 SQL 语句就能实现计算功能。例如:通过电流值和电压值计算功率值、换算载荷值的单位,统计牵引能耗在某小时、某天、某月内的最大值、最小值、平均值、累计值等。
2►数据库选型
目前,城轨车辆智能运维系统大多以关系型或非关系型数据库作为其数据存储的核心架构。这种数据库虽然实现了时序数据的存储需求,但写入和查询性能较差,且在数据压缩、数据展示等方面功能不够完善。为解决需求痛点,中车使用时序数据库 IoTDB 作为城轨车辆智能运维系统的核心部分,应用于对城轨车辆实时数据的采集、存储和展示。城轨车辆智能运维系统之所以以 IoTDB 时序数据库为核心进行构建,原因为下述几个 IoTDB 的技术、性能和功能优势。
2.1 IoTDB应用架构体系
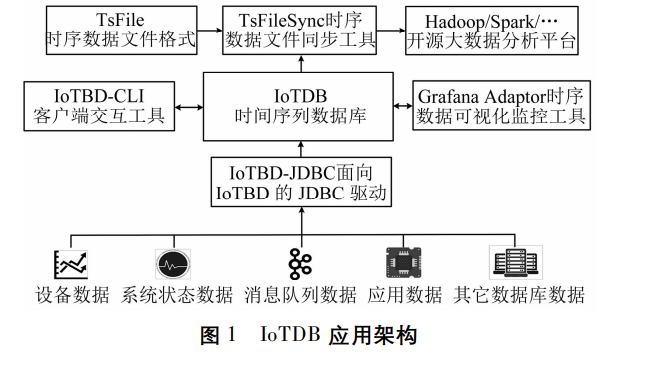
IoTDB 由多个组件构成,涵盖数据收集、数据写入、数据存储、数据查询、数据分析、数据可视化等多个功能。IoTDB应用架构如下图所示。IoTDB 通过 JDBC(Java 数据库连接)驱动,广泛地支持多种异构数据源的接入,包括设备数据、系统状态数据、消息队列数据、应用数据以及其它数据库中的数据等。用户通过命令行客户端交互工具能够对数据库进行写入和查询操作,也可以通过 Grafana 监控工具以图形化方式查看数据变化趋势。TsFile 是一种专门为时间序列数据而设计的存储格式,支持高效的压缩和查询能力,是 IoTDB 的核心组成部分。对于写入 TsFile 文件中的数据,可以通过 TsFileSync 同步工具将文件同步至 HDFS(Hadoop分布式文件系统)中,进而实现在 Hadoop 或 Spark 等开源平台上进行时序数据的处理和分析。
2.2 技术优势
2.2.1 高效存储数据结构
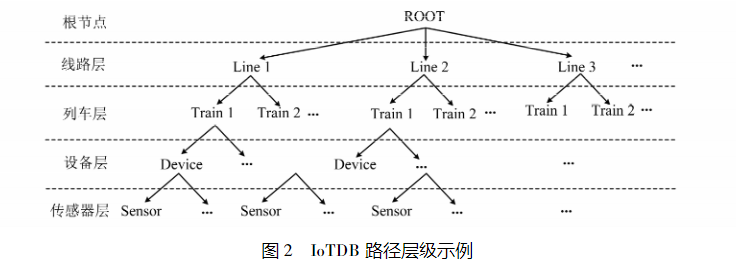
对实时数据和历史数据存储是时序数据库最基础、最核心的功能。下图展示了 IoTDB 的路径层级示例。通过“路径+时间范围”的组合,可以唯一确定 IoTDB 中的时序数据。此外,采用路径的层级设计,可以实现通过路径划分不同的存储空间,属于同一路径层级的数据能够存储在连续的磁盘空间上,避免了频繁的I/O(输入/输出)切换,并且隔离了不同的时序数据。
2.2.2 一写多读根据数据量灵活扩展
IoTDB支持“一写多读”的部署模式,即一个系统内可以部署多套 IoTDB。通过写入节点负责写入、查询负载,多个查询节点负责历史数据的查询负载,IoTDB 有效均衡了写入和查询工作量,避免两种操作对磁盘、网络的相互影响。随着数据量的不断增加,只需扩展查询节点的硬件设备,无需中断系统的正常运行。此外,IoTDB 基于 Raft 协议实现了一种分布式框架,将数据按时间序列组进行分区,以多副本的方式实现数据的可靠存储,并通过共识协议保证数据的强一致性。
2.3 性能优势
2.3.1 高频数据写入和查询
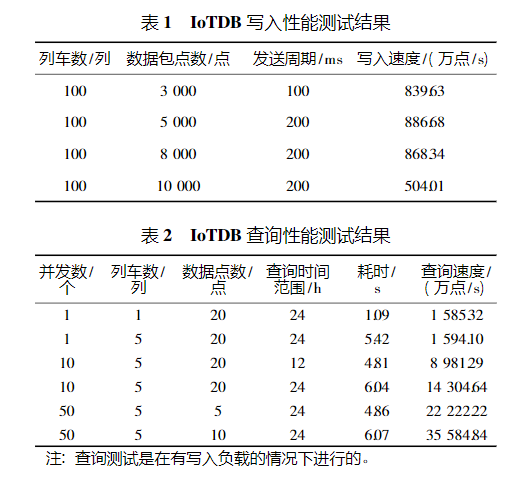
IoTDB对时序数据的处理具有天然的优势,能够实现每秒数百万数据点写入和查询的能力。中国中车通过模拟城轨车辆运行状态数据,对 IoTDB-v0.11.2进行了写入和查询性能测试,测试结果汇总于表1和表2中。根据测试结果可以看出,IoTDB 能够有效支撑线网级城轨车辆智能运维系统的写入和查询性能需求。
2.3.2 多种历史数据压缩方式节省成本
利用 IoTDB 的历史数据压缩能力可以有效减少城轨车辆智能运维系统历史数据的数据量,节省存储介质成本。历史数据压缩是利用各种算法缩小历史数据的冗余部分,同时尽量减少或避免数据失真。历史数据的压缩方式一般分为有损压缩、无损压缩和二级压缩三种。有损压缩能够实现较高的压缩比,但会导致数据精度下降;无损压缩不会降低原数据的精度,但要在压缩率、压缩速度和解压速度三者之间进行权衡;二级压缩则是结合了上述两种压缩方式的优点,即先对数据进行第一级有损压缩,再使用无损压缩算法进行第二级压缩。此外,压缩算法的效果还依赖于数据本身,数据变化越小、精度要求越低,则压缩效果越好。
2.4 功能优势
2.4.1 支持异常数据处理场景
由于网络延迟、软件性能、设备故障等原因不可避免地会出现数据无序到达、产生错误数据和重复数据等异常情况。IoTDB 能够支持数据异常情况下的工业应用场景,包括时间序列数据的乱序写入、时间序列数据的批量更新,以及对无效、无用时间序列数据的清理删除。
2.4.2 数据降采样提升查询响应速度
数据降采样是指数据库对查询到的结果集按照一定规则进行重新筛选,使筛选后的数据量小于原始数据量,且又不影响数据查询者的应用需求。IoTDB 通过聚合操作实现数据的降采样功能,既能保证图表的准确性,也能有效减少数据传输量,提高响应速度,不出现如数据点过于密集导致影响整体展示效果。
2.4.3 多种操作提升预处理效果
城轨车辆上的子系统、设备、传感器种类繁多,各自具有不同的采样频率,在进行数据分析之前,需要对时序数据进行预处理。IoTDB 支持多种基于时间序列维度的数据操作,如按照时间戳进行数据对齐、按时间戳进行时序数据分割等,有效减少了数据预处理的难度和复杂度。
2.4.4 可自定义计算方式及保存计算结果
相比于关系型数据库,IoTDB 时序数据库能够提供更为强大的计算能力。通过 IoTDB 内置的统计分析计算函数,可以根据时序数据的时间戳进行基于时间断面的计算、基于年月日的统计计算等。结合各类函数和自定义的计算公式,能够实现对原始数据进行复杂计算,计算结果可保存在 IoTDB 中,也可用于再次计算。
2.4.5 兼容大数据分析工具
基于大数据技术和Hadoop生态软件进行城轨列车运维数据分析是当前的一个热门课题。IoTDB 能够完美对接Hadoop生态中的各种软件,配合 Ha-doop 提供的分布式计算、存储机制,可提高城轨车辆智能运维系统在大数据管理和分析方面的运行效率和处理能力。此外,IoTDB 还可以对接 Spark 实时计算引擎,提供一种轻量级的数据分析解决方案,降低硬件资源部署量。
2.4.6 提供可视化工具展示数据
存入 IoTDB 的时序数据可通过可视化工具进行展示,便于城轨车辆智能运维系统的用户对进入系统的原始数据进行观察和分析。Grafana 是一款开源的度量分析和可视化工具,具有数据监控、数据统计和告警等功能。通过开发 IoTDB-Grafana 适配器,用户可利用 Grafana 的 Web 页面以可视化图表的方式直接查看IoTDB中的数据并进行分析,也可以在 Grafana 上进行一些数据探索工作。
3►解决方案架构
城轨车辆智能运维系统以保障城轨车辆运行安全、提高车辆检修质量、提升运营管理整体效能为目标,结合物联网、云计算、大数据等技术,实现对列车运行过程的全息感知和实时监控,有效辅助管理人员进行科学决策。
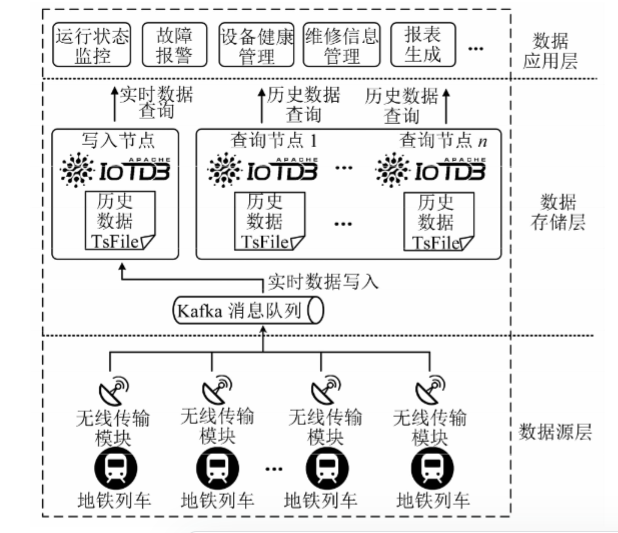
基于IoTDB时序数据库构建城轨车辆智能运维系统,其总体架构如上图所示,共分为3层,包括数据源层、数据存储层和数据应用层。该设计以 IoTDB 时序数据库代替了传统的关系型数据库和 NoSQL 数据库,显著提高了对城轨列车时序数据的写入和查询效率,且能够满足数据量持续增长的需求。
3.1 数据源层
数据源层覆盖所有城轨列车,列车上不同子系统、不同设备上的传感器产生的数据。这些数据按照特定发送周期,通过无线传输模块以 TCP、MQTT 等协议发送至城轨运营公司的数据中心。
3.2 数据存储层
数据存储层主要由IoTDB时序数据库和Kafka消息队列组成。数据源层发来的时序数据首先进入Kafka消息队列进行缓存,按照一定的规则或算法进入不同的 Topic 和 Partition。这样既能分担写入任务的负载,也能通过Kafka的副本机制,确保接收到的数据不会丢失。IoTDB-JDBC接口从 Kafka 的消费者端接收列车的实时数据,并存入写入节点的实时数据 TsFile 文件中。
随着数据量的不断扩大,当单个 IoTDB 节点的存储能力无法支撑数据存储时,可采用横向扩展的方式再部署一个或多个 IoTDB 查询节点,并设置为只读模式。在“一写多读”方式下,为避免单点故障,实现高可用,将写入节点配置为主备模式,通过 IoTDB 自身的同步机制实现数据同步。
IoTDB 处理过的实时数据为监视控制类应用提供支撑,历史数据为数据分析和挖掘类应用提供训练和测试样本。由于采用了数据压缩技术,历史数据所占用的存储空间能够得到有效控制。
3.3 数据应用层
数据应用层是系统对外输出能力的展现,提供如车辆运行状态监控、故障报警、设备健康管理、维修信息管理、报表生成等多种应用。城轨运营公司基于这些应用,可实现智能化管理,减少人力成本,提升城轨交通服务水平。
4►总结
在 IoTDB 的助力下,城轨车辆智能运维系统可以充分发挥其处理城轨列车时序数据的天然优势,同时又可以无缝对接大数据管理分析平台,具有高性能、高可靠性和高易用性等特点。未来,本案例给出的轻量化系统架构设计,可为城轨车辆智能运维系统的后续开发提供参考和借鉴。IoTDB 会继续支持中国中车对于时序数据的处理及分析需求,以更加丰富的功能帮助城轨车辆智能运维系统实现优化。

5►关于我们
Apache IoTDB——海量时序数据管理的解决方案,一款高吞吐、高压缩、高可用、物联网原生的开源时序数据库。从0到1自研时序存储方案、物联网数据模型、低流量数据传输方案,使得纳秒级采样数据写入无压力、TB级数据查询毫秒级、数据存储无损压缩数十倍。核心技术源自清华、自主可控。目前已在国家电网、国家气象局、中航成飞、中核集团、长安汽车、金风科技等企业广泛应用。

作为全球性开源项目,截至目前 Apache IoTDB 已拥有 212 名贡献者、2.1K Star、701 Forks。我们为大家提供了参与指南,欢迎越来越多的小伙伴助力 Apache IoTDB 项目的不断发展与前进。
欢迎迈出加入 Apache IoTDB 社区的第一步!
QQ群:659990460
微信群:添加好友qinchuqing
GitHub仓库:https://github.com/apache/iotdb
官网:http://iotdb.apache.org/
更多内容推荐:
• 了解更多 IoTDB 应用案例

