
- 1这个 Charles 爬取微信小程序 HTTPS 请求的技巧,我怎么没早点发现!_charels如何抓取微信
- 2connection could not be acquired from the uderlying database
- 3AFNetworking源码学习
- 4浅析微信小程序的底层架构原理_exparser
- 5chatgpt赋能python:Python大文件切分:解决瓶颈问题
- 6Python str函数_str()
- 7hive安装完成后遇到的问题
- 8大数据从入门到精通(超详细版)之HDFS安装部署 , 跟着部署 , 真的有手就行 !_hdfs部署
- 9【leetcode基础题】刷题清单,刷完算法入门
- 10流程图 自定义函数_任意波形 / 函数发生器能做的25 件日常工作你知道吗?
2023 IoTDB Summit:清华大学软件学院院长王建民《清华数为:可组装的工业大数据软件栈》...
赞
踩
12 月 3 日,2023 IoTDB 用户大会在北京成功举行,收获强烈反响。本次峰会汇集了超 20 位大咖嘉宾带来工业互联网行业、技术、应用方向的精彩议题,多位学术泰斗、企业代表、开发者,深度分享了工业物联网时序数据库 IoTDB 的技术创新、应用效果,与各行业标杆用户的落地实践、解决方案,并共同探讨时序数据管理领域的行业趋势。
我们邀请到清华大学软件学院院长王建民参加此次大会,并做主题报告——《清华数为:可组装的工业大数据软件栈》。以下为内容全文。
目录
工业大数据
工业物联网数据库
“清华数为”组件
IoTDB 未来工作
尊敬的 Mohan 院士,还有我们从德国远道而来的 Julian,尉迟坚司长、文剑秘书长、郭院长、赵总,各位嘉宾、各位朋友,大家上午好。非常高兴今天有机会跟大家汇报一下清华大数据软件团队过去十年做的一点工作。
我们做的工作的载体,我们管它叫清华数为,英文就叫 Tsinghua Dataway,就是这个数据怎么来创造价值的一种方式。我们把它叫成一个可以组装的大数据系统的软件栈。
01
工业大数据
首先,今天大家讲了很多关于数据的事情,工业大数据今天已经成为一个流行语了。
我们看到工业大数据产生的一个背景,在制造业来讲,就是产品的智能化。产品的智能化从产品装上一个 CPU 开始,然后在 CPU 的这个基础上再装上一个传感器,这个产品就变成一个联网的产品。其实我们的车间的设备也是这样的,原来是一个机械的设备,加上传感器之后再加上现场的网络,就把它连接起来,也形成了一个可以说话的一个设备。
那么在这个可以说话的设备基础上,就可以变成设备的集群。在我们企业当中就是一条生产线,在我们的工程装备里头,可能就是一个联合作业的一个集群,比如在矿山里头,就从采矿、运输、碎石、搅拌开始,就形成一个机器的系统。那么有了这样的一个机器的系统,我们就说现在的数字化转型,各行各业的数字化转型,包括尉迟坚司长前面讲过,写过一本书叫做《价值魔方》,整个的业务、经济就会发生变化。所以我们说,现在我们走在数字经济的时代,中国要走新型的工业化,那么它的所有的起点,都是装备的一个改变。

那么,升级成了一个智能网联产品以后,我们就会看到什么呢?尉迟坚司长前面回顾了软件的发展历程的一种困惑和艰辛,那么其实企业的信息化、数字化也是从上个世纪的六十年代开始,我们把图板甩掉,然后把车间自动化,然后把我们的物流自动化、把我们的供应链自动化,就形成了企业信息化的这样一个数据。那么当年,九十年代,我当时从北大毕业到清华孙家广老师这儿,那个时候就经历了我们国家的整个信息化的一个开端。
走到新的世纪以后,我们看到机器设备的不断的联网,我们就看到现在的工业物联网。那么物联网广域化以后,就把我们的产品都给它连接起来了,无论我们的产品天南地北,对吧?那么做 IoTDB 的一个起点就是,十二年前和三一重工,他们把所有的全球设备连接起来,就提出的一个需求:怎么把传感器,端上的这些盒子的数据给收集上来,然后形成在长沙的一个大屏,叫 ECC,能够全球的控制。
那么说到今天,到了人工智能时代,我们就看到互联网的跨界数据,这些非结构化的数据,我们的气象、地理、环境,特别现在我们新能源的光电、风电这些的发展,就带来了一些互联网的跨界数据。其实这些数据形成了我们今天数字化转型的工业数据。前面跟赵主任来一起讨论的时候也在讲,时序数据再加上业务数据,广泛的融合,才形成了新的这个工业大数据的价值。

那么清华数为也遵循了一个从数据,到信息,到知识,到智慧的这样的一个整体的加工的过程,我们说它是一个金字塔的蒸馏。那么我们看到,刚才看到的这个信息化的数据、物联网的数据、互联网+的数据,对于工业数据来讲都是原始的数据,都是 0 层的数据,这是我们做数据加工的一个起点。那么通过对这些数据经过交互式的编程序的处理,从一个数据集到达另外一个数据集,我们就说这是一个商务智能的一个时代。那么刚才 Mohan 教授来讲了 OLTP,我们主要在信息化的时候在使用,那么 OLAP 主要在 BI 的年代,我们在做这样的一个处理。那么今天我们走到了人工智能的时代,特别是机器学习的发展,我们要从这些数据集里头把它学习出来知识,变成大模型,变成一个解决问题的实际的模型,所以我们就走到了人工智能时代。
所以我们会看到,今天的应用就是什么?物联网的应用,它有感知、预警,然后我们再做控制。我们会有信息化的应用,我们会把这些数据存起来进行检索和查询,这就是 IS 的应用。我们会把它变成一张一张的报表,变成转换和度量,能够帮助我们决策的这种 BI 的系统。然后我们可以把它透过 AI 形成预测,我们不仅看昨天,我们还要预测明天,在预测明天的过程当中,我们还能进行干预,这就是我们 AI 的时代。那么最后我们要进行跨界的融合,就变成了一个互联网+的应用。那么这些应用是现在,要全场景的利用工业大数据,我们要走的一个路径。

02
工业物联网数据库
那么,这样的一个思路指导下,今天我们讲的工业大数据时代的增量,那么它的最重要的增量就是物联网数据。我们说信息化的时候,我们走了很多很多年,物联网我们走了新的二十年,那么这个时候物联网的数据库,它这个场景就是在空天地海,这样的智能联网的产品就构成了现在的工业物联网。那么它每天都在产生的数据,都汇聚在我们的这个数据中心,然后供我们的用户来使用。
我们今天看到南海上有很多的钻井平台,那么这些钻井平台之所以能够立足、定位在那,就是因为它是一个智能联网的设备,它有各种的传感器,有各种水下的这样的引擎和螺旋桨,那么才能够把我们很多的资源把它开采出来。我们刚才片子里头讲了核电工业,刚才旭嘉处长也在,那么也是从核导的这个一回路、二回路、三回路,能够把它打通连接起来,对吧?等等,它就不断的在产生这种时序数据。

那么这件事情,时序数据也是工业大数据提出来的一个重要的触发器。

那么今天我们都在讲,工业物联网里头,上行就在端上采集,在边缘汇聚,在云中处理。下行的时候,我们要在云中去训练,边缘推理,然后在端上执行。我们就看它完全是一个 OT 和 IT 融合得非常深入的一个网络。今天如果我们不在这个框架上来看待物联网的话,可能我们确实已经没有感受到现在的脉搏。
那么,现在 IoTDB 不仅是在 IT 网络上,现在我们正在和像翼辉信息这样的实时操作系统进行连接,要进入这个物理层,也就是在链路层上边,我们能够直接和下边的控制单元说话。那么这个就是我们整个的愿景。
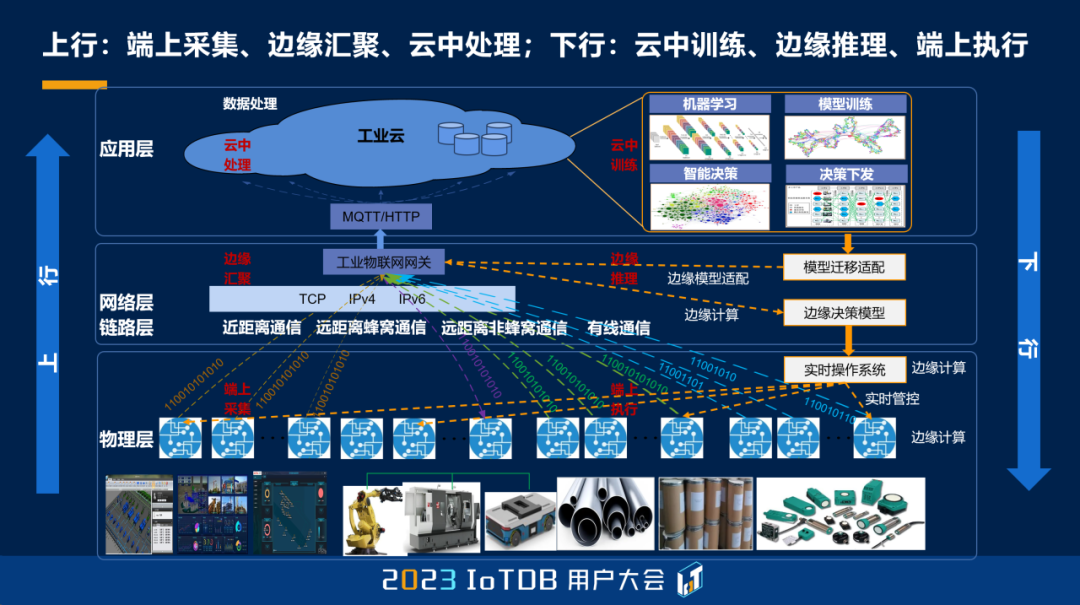
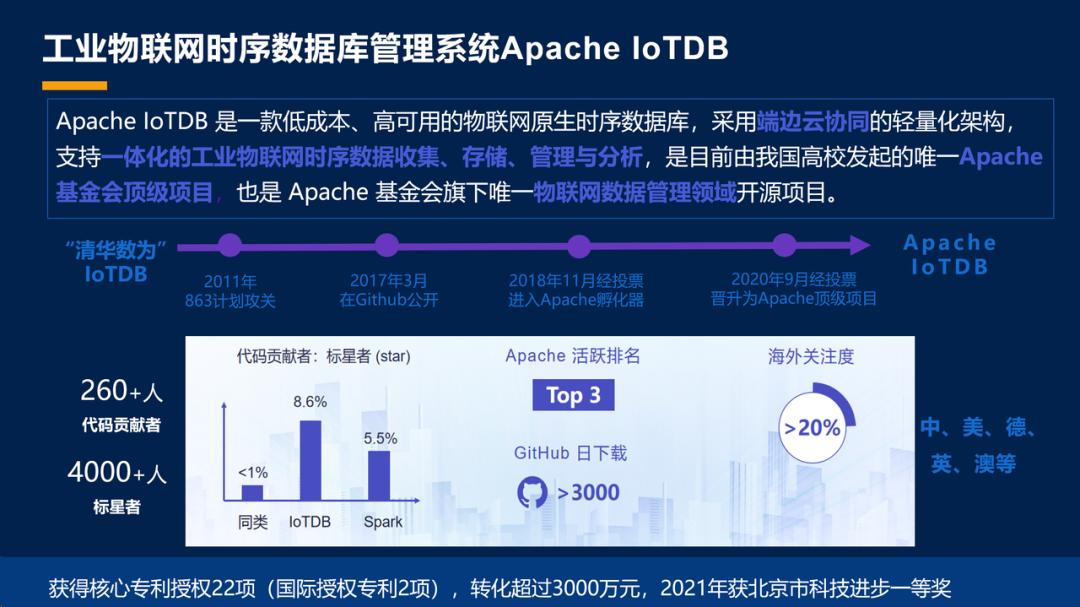
这个我就不展开了,这个向东他们一会儿还有很多和大家分享。总的来说,我们一开始就是希望有一个物联网原生的一个数据库。这个物联网原生就是把端、设备也看成我们这个系统的一部分,不仅仅是数据库,后边我们会看到。
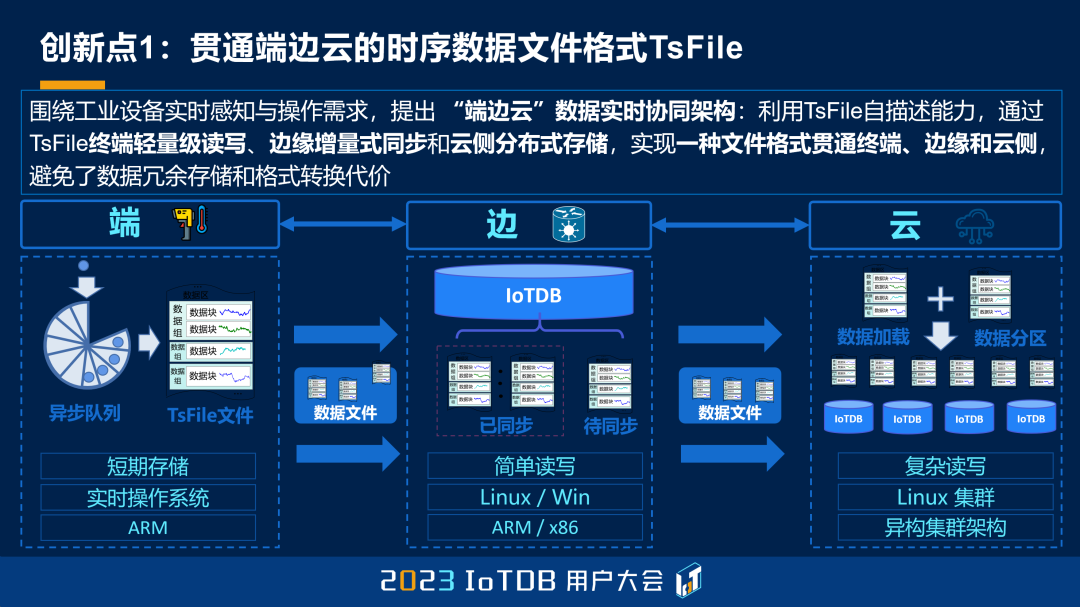
那么这件事情的一个最重要的,前面的初心,因为端上面的计算能力很弱,所以我们就把我们的文件系统单独的拿出来。我们一开始就建立了一个自描述的文件系统,所以它可以很方便地放在端上。那么同时这里头有很多的压缩的考虑,有很多的加速查询的索引的考虑,有自描述的元数据,就是 schema 信息的考虑。

这就是能够一个格式走到底,做端边云的贯通。
那么第二件事情就是做时序压缩的算法,宋韶旭老师带了一波人不断的在做。那么在对高频的周期性的数据,我们有好的办法。
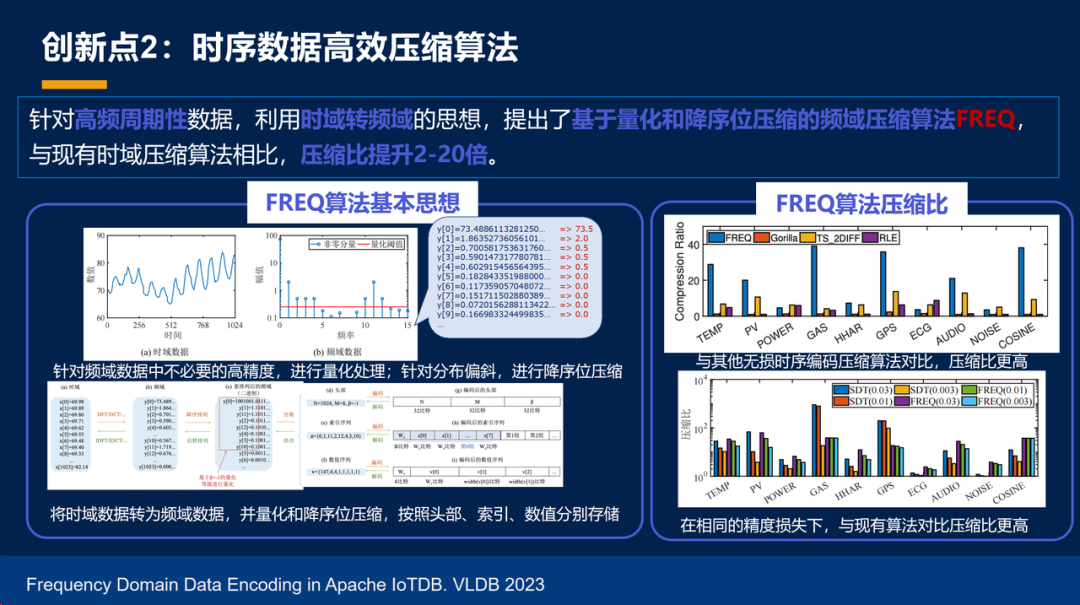
对高频的振荡数据,我们同样也有好的办法。
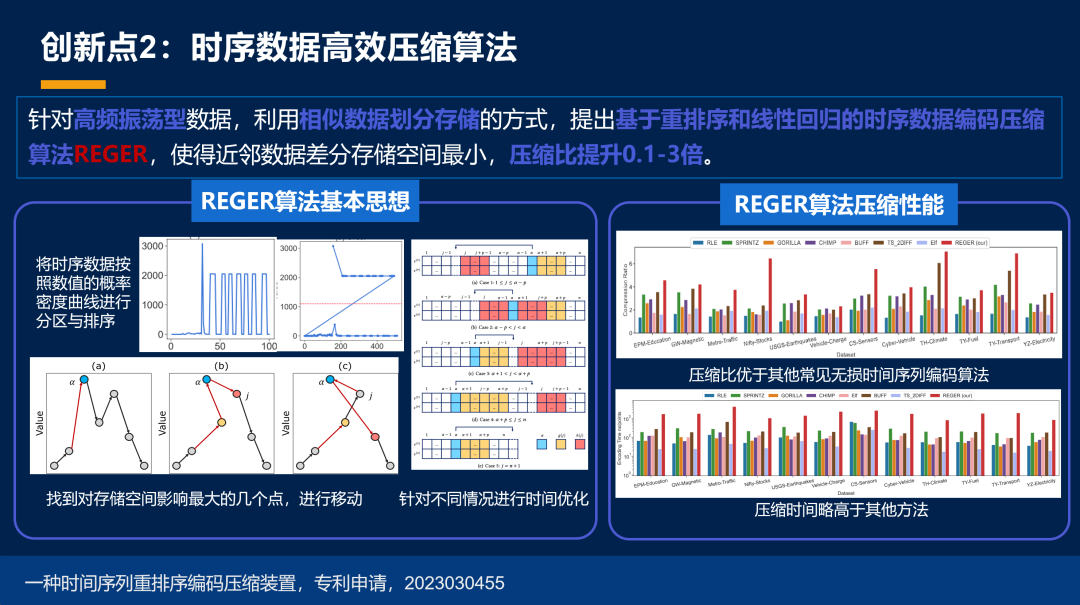
同时我们对所有的这个压缩算法给出了自己的一套指标体系,同时也能够根据数据的特征,选择最好的压缩算法。总的来说,物联网这件事情就是唯小不破,唯小不快。

第三个就是说,我们在大规模、在后端的系统当中,我们要把这个系统的平台做强,所以我们有一个多场景、多副本的一致性协议。这是在斯坦福的这个 Raft 协议上面做了改进。

也提出了我们自己的控制多副本一致性的一个办法。
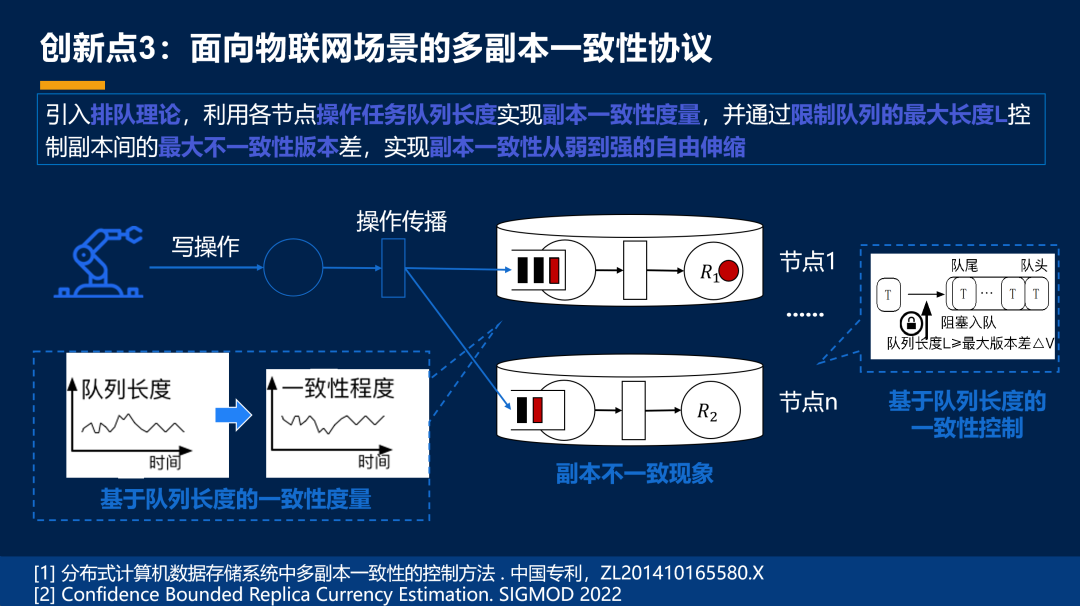
我们认为,本来物联网的数据,它的采集、存储、查询、分析就应该是一体化的,所以我们就把分析做成了我们自己的一个原生的节点,一会儿龙明盛教授会分享,就是我们把机器学习看成了物联网数据库的一部分。

好,那么现在看我们今天来的,也特别感谢今天来的各位用户,在能源、在制造、在交通、在我们的这个流程行业等等,做了非常多的推广和应用,给我们大量的反馈。

03
“清华数为”组件
那么这样的一个过程当中我想,我们除了 IoTDB,再回顾一下,只有时序数据也不能完全解决企业哪怕是设备当中的问题,所以我们还会围绕着整个时序数据的再进一步的应用,我们有一个面向 AIoT 场景的这样的清华数为,我们管它叫一个兔子模型。
那么当然一个耳朵就是 IoTDB,要把物联网的数据从端到边到云,把它打通,再从上行和下行把它打通。那么第二件事情就是,如果大家进一步的要把这些数据变成知识,需要什么?

需要一个把大数据机器学习看成一个工程化方法的这样一个平台,我们就叫做 Anylearn。那么它是一款大数据机器学习研发管理的系统,它支持数据集、算法族、模型库等数据资产,来支持机器学习研发的过程管理、知识沉淀、模型的迁移,来满足资源的统筹利用、团队的高效协作,这样的把人工智能工程化的一种需求。

那么这件事情不展开,这里头它有这种交互层,有业务层,有系统层。

来支撑机器学习在工业场景当中落地,那么大家可以在网上来查找我们相关的信息。

第二个就是 FLOK。那么这是一款把大数据进行拖拽,就可以交互设计的一款软件,能够把一个数据集方便的转换成另外一个数据集。

大家会看到,它就相当于一个小的引擎,能够把您原来的各种各样的数据,把它连接起来,然后便处理成自己的可用的数据集。
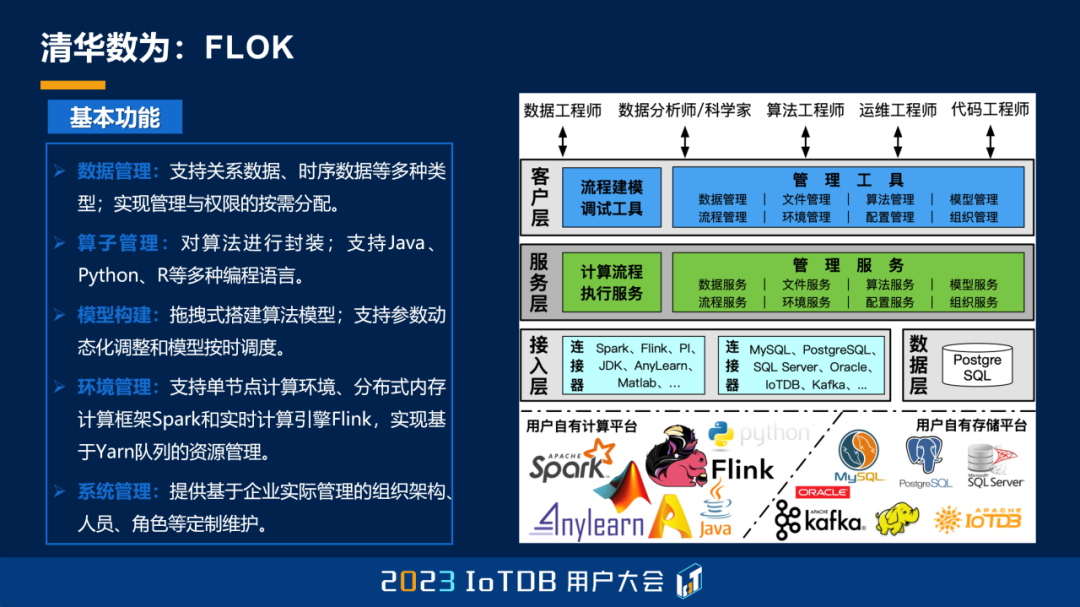
那么最后一个,其实我们无论做什么样的数据分析、数据产品,都要有一个开发工具,变成一个应用,所以刘英博教授也在这,我们在开发一款大数据应用的低代码开发工具,通过拖拉拽就可以把系统开发出来。这是我们的一个希望,能够把数据变成软件产品,递交到最终用户的这样的一个工具。

那么它这里头就有数据的开发人员和最终用户。

那么这个产品透过在英业达集团的应用,应该说几年的这样的打磨,应该是得到了广泛的应用。那么最近,因为英业达是一家台湾的公司,可能也随着他们公司会走到东南亚去。这都是在围绕着工业数据的应用的一些产品。

04
IoTDB 未来工作
那么回到今天的主题,我想 IoTDB 未来一定要构建成一个新一代的、跨越端边云的、工业物联网数据的一个基础设施。那么我们看端上边,我们就会把它落到这个 TsFile,在设备上、在实时操作系统当中,你就可以随时的落盘,比如现在我们在成飞的靶机上,在我们有很多电力系统它那个前端的盒子上。那么它最大的好处,你落了盘之后,它就非常的小,它小的时候就省我们的网络,省我们的磁盘。
然后就可以到边上去,只要去 load tsfile,只要在你的 IoTDB 上 load tsfile ,这个就变成你数据库的一个部分,是新的 database,是你采用了新的设备,因为什么?因为这个 TsFile 是自描述的,所以它可以不断在往上层走。
然后再到云上面,大家会看到还是 TsFile,不用转码。那么下边就进到了你的 IoTDB 的集群,也就会未来能够用,马上一会龙教授要分享的 IoTDB 的 AINode 来处理你的 TsFile。
所以这样的话,它就是一个整体的,从端到边到云,就用一个格式贯通的一个以作为工业物联网、作为一台计算机的这样一个理念的数据处理的平台。那么同样可以下行控制到你的终端,形成这样的一个体系。

那么我想,未来的工业里头就是要实时,一定要 Real Time。AI 如果在工业里头没有 Real Time,恐怕是不能用的,所以就要一个实时训练的这样的一个机制。
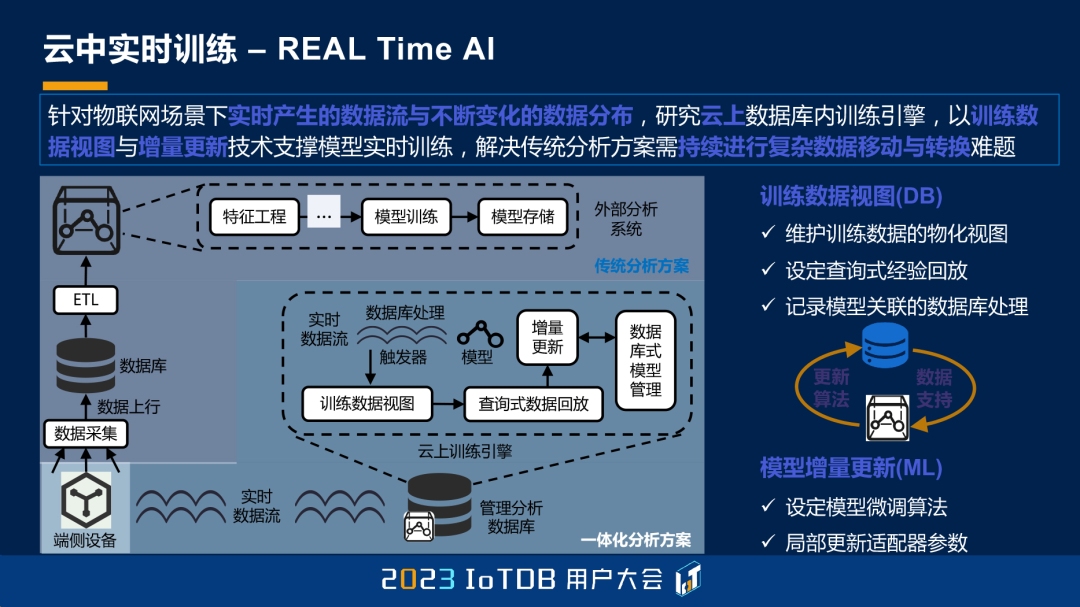
就会有一个边上实时推理的机制。当然大家很容易就想到,如果有这种机制的话,我们就可以很容易的用现在的大模型,来加持你的边和端。
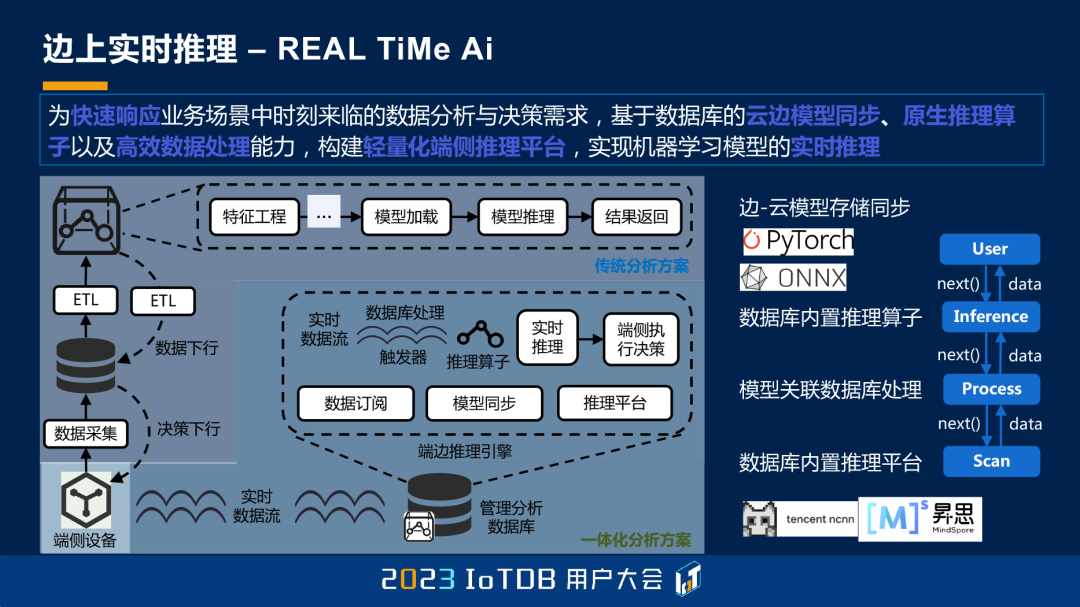
我想今天,文剑秘书长,一会我们开源技术委员会就会开会,所以今天的软件一定是一个开放的生态,从根上就要做开放。所以我们说,今天非常感谢我们 IoTDB 社区的所有的参与者,感谢我们所有的用户。

那么这一次,我们孙家广院士带领我们创建的清华大学的大数据软件团队,我们希望把清华数为的大数据的软件栈能够做得更加的能用、管用、好用。
我的汇报就到这。我在这里再次感谢清华大学的大数据团队的各位伙伴,感谢天谋科技公司我们的各位非常努力工作的小伙伴们,还要感谢支持清华数为、感谢支持 IoTDB 发展的各位朋友,谢谢大家!

可加欧欧获取大会相关PPT
微信号:apache_iotdb
更多内容推荐:
• 回顾 IoTDB 2023 大会全内容


