
- 1Manjaro的安装与配置_manjaro哪个桌面环境好
- 2PCB设计时铜箔厚度,走线宽度和电流的关系_2oz铜厚可以多少电流
- 3在Git存储库中查找并恢复已删除的文件_为什么推送到git远程仓库的文件会显示被delete了
- 4【vue-2】v-on、v-show、v-if及按键修饰符
- 5【AIGC调研系列】通义千问、文心一言、抖音云雀、智谱清言、讯飞星火的特点分析_通义千问和文心一言哪个更好用
- 6Host头攻击-使用加密和身份验证机制
- 7欠薪6个月:外包公司干(混)了4年,我决定换个活法
- 8数字温度传感器-DS18B20_ds18b20温度传感器csdn
- 9使用cloudreve搭建个人网盘
- 10idea所有子模块启动都出现Error:Kotlin: Module was compiled with an incompatible version of Kotlin.报错
LLM多模态——GPT-4o改变人机交互的多模式 AI 模型应用
赞
踩
1. 概述
OpenAI 发布了迄今为止最新、最先进的语言模型 – GPT-4o也称为“全“ 模型。这一革命性的人工智能系统代表了一次巨大的飞跃,其能力模糊了人类和人工智能之间的界限。
GPT-4o 的核心在于其原生的多模式特性,使其能够无缝处理和生成文本、音频、图像和视频内容。这种将多种模式集成到单一模型中的做法尚属首次,有望重塑我们与人工智能助手互动的方式。
但 GPT-4o 不仅仅是一个多模式系统。与前身 GPT-4 相比,它拥有惊人的性能改进,并将 Gemini 1.5 Pro、Claude 3 和 Llama 3-70B 等竞争型号远远甩在身后。让我们更深入地探讨一下是什么让这个人工智能模型真正具有开创性。
2. 无与伦比的性能和效率
GPT-4o 最令人印象深刻的方面之一是其前所未有的性能能力。根据 OpenAI 的评估,该模型比之前表现最好的 GPT-60 Turbo 领先 4 Elo 点。这一显着优势使 GPT-4o 独树一帜,甚至超越了目前最先进的人工智能模型。
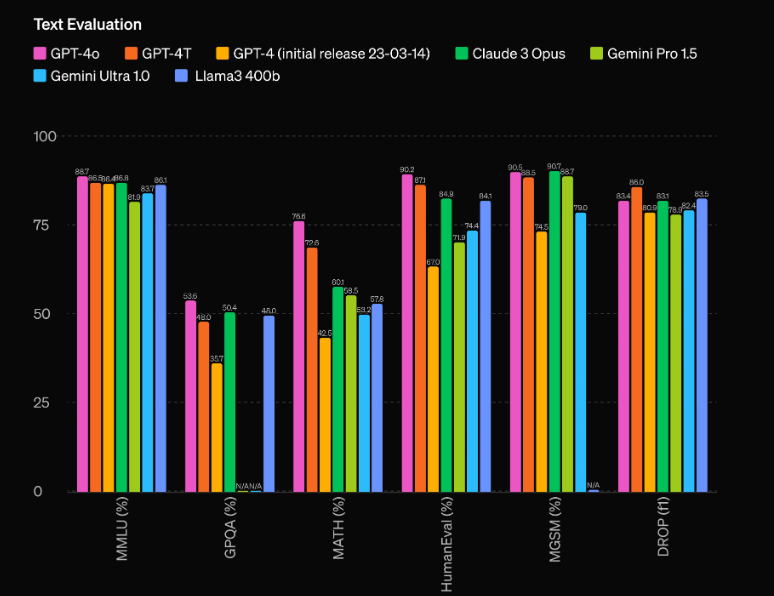
但原始性能并不是 GPT-4o 的唯一亮点。该模型还拥有令人印象深刻的效率,运行速度是 GPT-4 Turbo 的两倍,而运行成本仅为 GPT-4 Turbo 的一半。卓越的性能和成本效益的结合使 GPT-XNUMXo 对于希望将尖端人工智能功能集成到其应用程序中的开发人员和企业来说极具吸引力。
3. 多模式功能:混合文本、音频和视觉
也许 GPT-4o 最具突破性的方面是其原生的多模态特性,这使得它能够跨多种模态(包括文本、音频和视觉)无缝处理和生成内容。这种将多种模式集成到单一模型中的做法尚属首次,它有望彻底改变我们与人工智能助手互动的方式。
借助 GPT-4o,用户可以使用语音进行自然、实时的对话,模型可以立即识别和响应音频输入。但功能并不止于此 - GPT-4o 还可以解释和生成视觉内容,为从图像分析和生成到视频理解和创建的应用开辟了一个充满可能性的世界。
GPT-4o 多模态功能最令人印象深刻的展示之一是它能够实时分析场景或图像,准确描述和解释其感知的视觉元素。此功能对于视障者辅助技术等应用以及安全、监控和自动化等领域具有深远的影响。
但 GPT-4o 的多模式功能不仅仅限于理解和生成不同模式的内容。该模型还可以无缝地融合这些模式,创造真正身临其境且引人入胜的体验。例如,在 OpenAI 的现场演示中,GPT-4o 能够根据输入条件生成一首歌曲,将对语言、音乐理论和音频生成的理解融入到一个有凝聚力且令人印象深刻的输出中。
4. 使用 Python 使用 GPT0
4.1 代码调用
import openai
# Replace with your actual API key
OPENAI_API_KEY = "your_openai_api_key_here"
# Function to extract the response content
def get_response_content(response_dict, exclude_tokens=None):
if exclude_tokens is None:
exclude_tokens = []
if response_dict and response_dict.get("choices") and len(response_dict["choices"]) > 0:
content = response_dict["choices"][0]["message"]["content"].strip()
if content:
for token in exclude_tokens:
content = content.replace(token, '')
return content
raise ValueError(f"Unable to resolve response: {response_dict}")
# Asynchronous function to send a request to the OpenAI chat API
async def send_openai_chat_request(prompt, model_name, temperature=0.0):
openai.api_key = OPENAI_API_KEY
message = {"role": "user", "content": prompt}
response = await openai.ChatCompletion.acreate(
model=model_name,
messages=[message],
temperature=temperature,
)
return get_response_content(response)
# Example usage
async def main():
prompt = "Hello!"
model_name = "gpt-4o-2024-05-13"
response = await send_openai_chat_request(prompt, model_name)
print(response)
if __name__ == "__main__":
import asyncio
asyncio.run(main())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 直接导入openai模块,而不是使用自定义类。
- 将 openai_chat_resolve 函数重命名为 get_response_content 并对其实现进行了一些细微更改。
- 将 AsyncOpenAI 类替换为 openai.ChatCompletion.acreate 函数,这是 OpenAI Python 库提供的官方异步方法。
- 添加了一个示例主函数,演示如何使用 send_openai_chat_request 函数。
请注意,您需要将“your_openai_api_key_here”替换为您的实际 OpenAI API 密钥,代码才能正常工作。
4.2情商和自然互动
GPT-4o 的另一个突破性方面是它能够解释和生成情绪反应,这是人工智能系统长期以来无法实现的一种能力。在现场演示中,OpenAI 工程师展示了 GPT-4o 如何准确检测和响应用户的情绪状态,从而相应地调整其语气和响应。
在一个特别引人注目的例子中,一名工程师假装换气过度,GPT-4o 立即从他们的声音和呼吸模式中识别出了痛苦的迹象。然后,该模型平静地引导工程师进行一系列呼吸练习,将其音调调整为舒缓和放心的方式,直到模拟的痛苦消退。
这种解释和响应情绪线索的能力是迈向与人工智能系统真正自然和类人交互的重要一步。通过了解对话的情感背景,GPT-4o 可以以一种感觉更自然、更有同理心的方式定制其响应,最终带来更具吸引力和令人满意的用户体验。
4.3 无障碍服务
OpenAI 决定向所有用户免费提供 GPT-4o 的功能。这种定价模型设定了一个新标准,竞争对手通常会收取大量订阅费来访问其模型。
虽然 OpenAI 仍将提供付费的“ChatGPT Plus”等级,并具有更高的使用限制和优先访问权等优势,但 GPT-4o 的核心功能将免费提供给所有人。
4.4 实际应用和未来发展
GPT-4o 功能的影响是巨大而深远的,潜在应用跨越众多行业和领域。例如,在客户服务和支持领域,GPT-4o 可以彻底改变企业与客户的互动方式,跨多种方式(包括语音、文本和视觉辅助)提供自然、实时的帮助。
在教育领域,GPT-4o 可以用来创造沉浸式和个性化的学习体验,该模型可以调整其教学风格和内容交付,以满足每个学生的需求和偏好。想象一下,一个虚拟导师不仅可以通过自然语言解释复杂的概念,还可以即时生成视觉辅助工具和交互式模拟。

娱乐行业是 GPT-4o 多模式功能大放异彩的另一个领域。从为视频游戏和电影生成动态且引人入胜的叙事,到创作原创音乐和配乐,可能性是无限的。
展望未来,OpenAI 制定了雄心勃勃的计划,将继续扩展其模型的功能,重点是增强推理能力并进一步整合个性化数据。一个诱人的前景是将 GPT-4o 与针对特定领域(例如医学或法律知识库)训练的大型语言模型相集成。这可以为高度专业化的人工智能助手铺平道路,使其能够在各自领域提供专家级的建议和支持。
未来发展的另一个令人兴奋的途径是 GPT-4o 与其他人工智能模型和系统的集成,从而实现跨不同领域和模式的无缝协作和知识共享。想象一下这样一个场景:GPT-4o 可以利用尖端计算机视觉模型的功能来分析和解释复杂的视觉数据,或者与机器人系统协作,在物理任务中提供实时指导和支持。
5.道德考虑和负责任的人工智能
与任何强大的技术一样,GPT-4o 和类似人工智能模型的开发和部署提高了 重要的道德考虑。 OpenAI 一直直言不讳地致力于负责任的人工智能开发,实施各种保障措施和措施来减轻潜在风险和滥用。
一个关键问题是 GPT-4o 等人工智能模型是否有可能延续或放大现有模型 偏见以及训练数据中存在的有害刻板印象。为了解决这个问题,OpenAI 实施了严格的去偏差技术和滤波器,以最大限度地减少模型输出中此类偏差的传播。
另一个关键问题是 GPT-4o 的功能可能被滥用于恶意目的,例如生成 deepfakes、传播错误信息或参与其他形式的数字操纵。 OpenAI 实施了强大的内容过滤和审核系统,以检测和防止滥用其模型进行有害或非法活动。
此外,该公司强调人工智能开发中透明度和问责制的重要性,定期发布有关其模型和方法的研究论文和技术细节。这种对更广泛科学界的开放和审查的承诺对于培养信任并确保负责任地开发和部署 GPT-4o 等人工智能技术至关重要。
6. 结论
OpenAI 的 GPT-4o 代表了人工智能领域真正的范式转变,开创了多模式、情感智能和自然人机交互的新时代。凭借其无与伦比的性能、文本、音频和视觉的无缝集成以及颠覆性的定价模型,GPT-4o 有望实现尖端人工智能功能的民主化,并从根本上改变我们与技术交互的方式。
虽然这一突破性模型的影响和潜在应用是巨大且令人兴奋的,但至关重要的是,其开发和部署必须以对道德原则和负责任的人工智能实践的坚定承诺为指导。

