
热门标签
热门文章
- 1DRF笔记(一):手工实现常见API_武sir drf开发笔记
- 2接触式高精度温度传感芯片M117完美替代TI的TMP117,在可穿戴产品领域的应用_tmp117 stm32
- 3git版本升级[2.13-2.39]_git 2.39.1
- 4大数据OLAP系统(2)——开源组件篇_molap、rolap、mpp
- 5IntelliJ IDEA 2023.1中新的UI增强,加强了IDE编码体验!_idea新ui
- 6Python解释器和Pycharm编辑器安装Windows和Mac(附赠Pycharm专业版免费安装方法)_python苹果电脑解释器
- 7Obsidian 使用 Livesync 同步数据_obsidian 同步
- 8【文学】平凡的世界第一部_平凡的世界第一部卷一
- 9neo4j简单学习
- 10基于springboot+vue.js的秒杀系统(附带文章和源代码设计说明文档ppt)
当前位置: article > 正文
Hugging Face 3000+NLP预训练模型库整理分享_hugfacing的模型资源
作者:小丑西瓜9 | 2024-06-02 11:08:20
赞
踩
hugfacing的模型资源

在自然语言处理(NLP)领域中,使用语言模型预训练方法在多项NLP任务上都获得了不错的提升,广泛受到了各界的关注。在bert之前,将预训练的embedding应用到下游任务的方式大致可以分为2种,一种是feature-based,例如ELMo这种将经过预训练的embedding作为特征引入到下游任务的网络中;一种是fine-tuning,例如GPT这种将下游任务接到预训练模型上,然后一起训练。然而这2种方式都会面临同一个问题,就是无法直接学习到上下文信息,像ELMo只是分别学习上文和下文信息,然后concat起来表示上下文信息,抑或是GPT只能学习上文信息。
随后提出一种基于transformer encoder的预训练模型,可以直接学习到上下文信息,叫做bert。bert使用了12个transformer encoder block,在13G的数据上进行了预训练,可谓是nlp领域大力出奇迹的代表。在整个流程上与transformer encoder没有大的差别,只是在embedding,multi-head attention,loss上有所差别。自此开始,各式各样的预训练自然语言模型层出不穷,并且在各式各样的NLP任务中取得不错的效果。
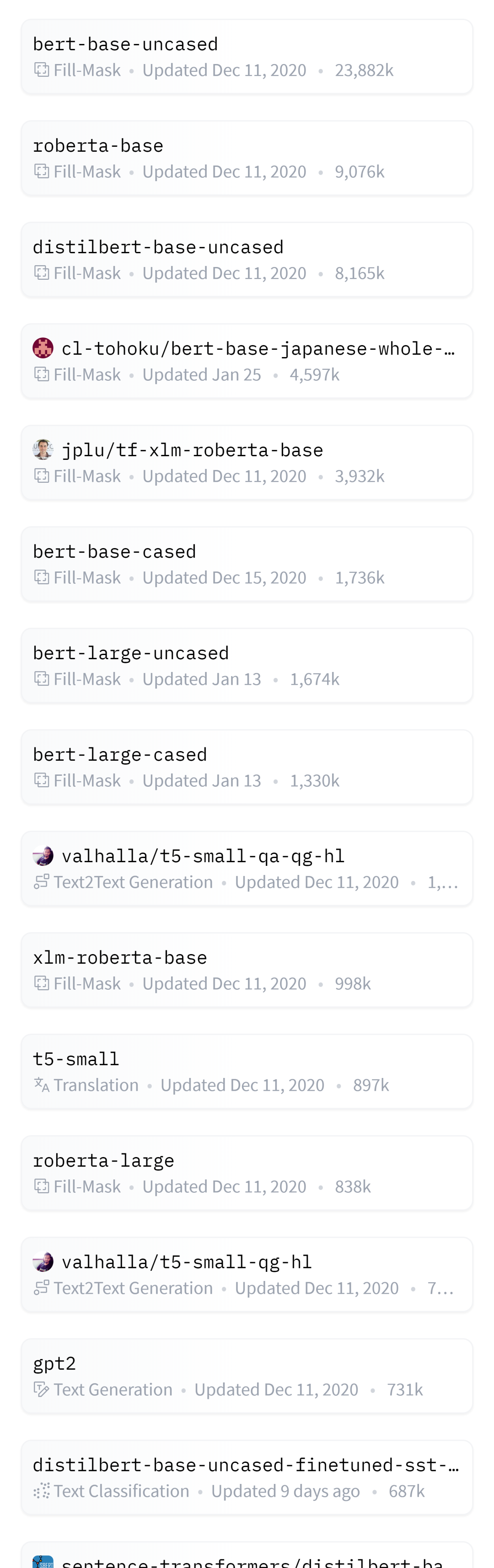
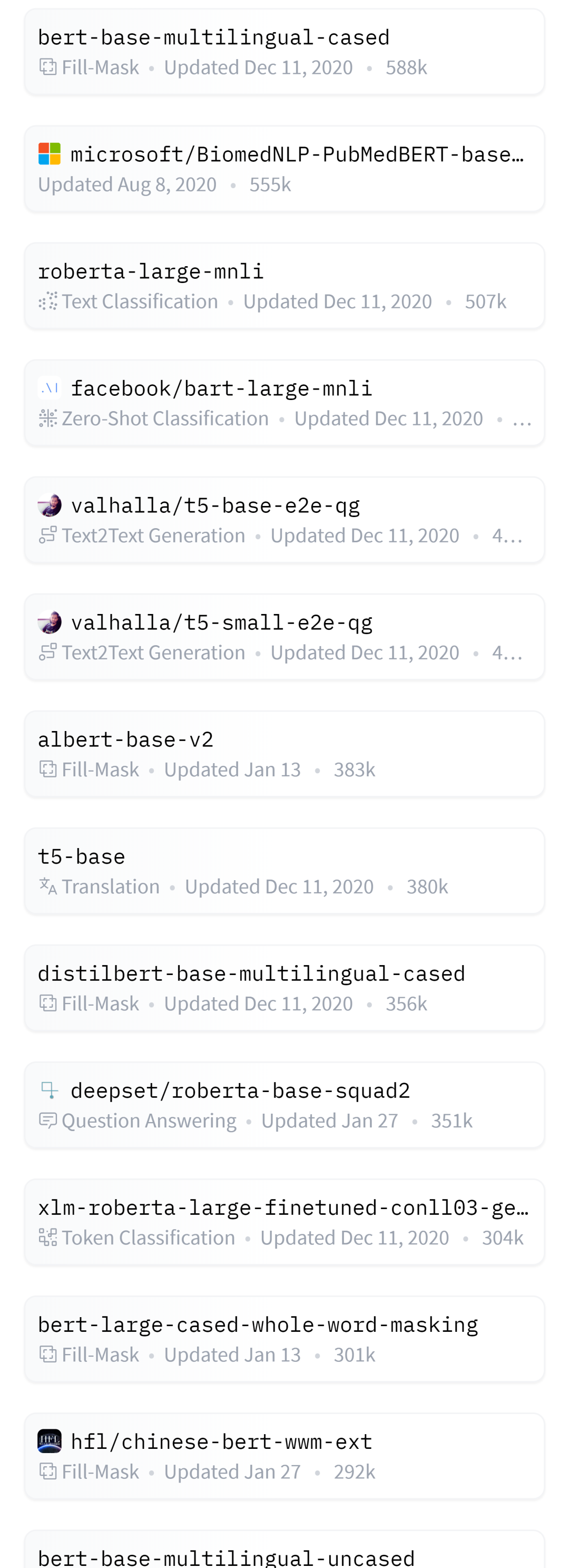
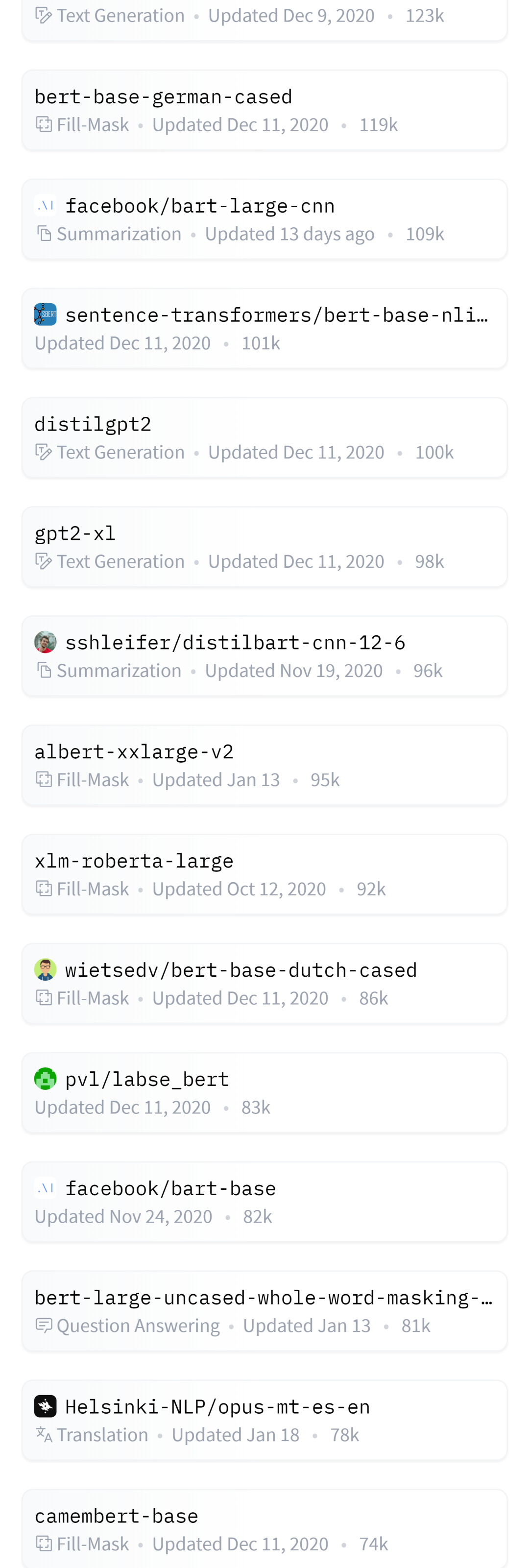
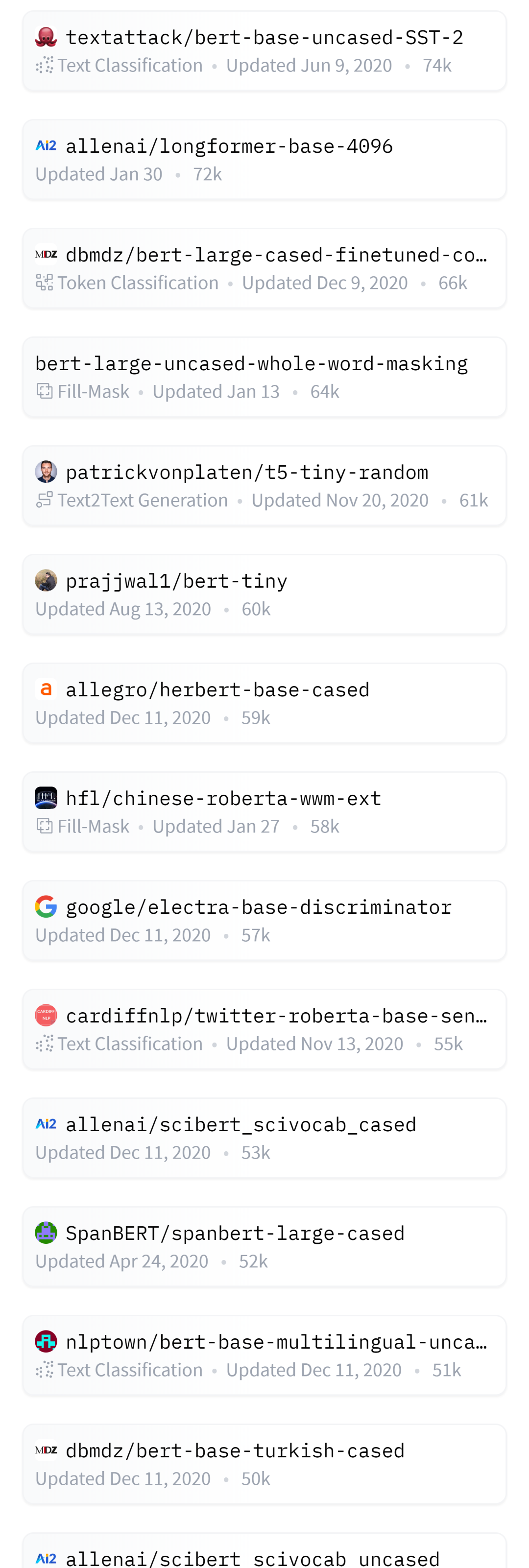
本资源由Hugging Face整理分享,包含了3000+的已经与训练好的自然语言处理模型库,包含了各式各样的NLP模型。
全部数据获取地址:https://huggingface.co/models?p=0
部分数据截图


声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读

相关标签

