
- 1cmd输入python但是打开microsoft store问题_cmd输入python就打开microstore
- 2Spring+neo4j_spring+ne4oj
- 3实时数据处理的流式计算框架:Apache Spark Streaming 与 Apache Flink 的实践
- 4数据库常见面试题--MySQL
- 5【实战教程】Spring Boot项目集成华为openGauss数据库的关键步骤与注意事项_springboot集成opengauss
- 6Python 异常处理:Python 中的断言_python断言
- 709 Confluent_Kafka权威指南 第九章:管理kafka集群_confluent.kafka producerconfig
- 8ffmpeg源码编译_centos手动编译github中的ffmpeg源码
- 9如何使用MongoDB+Springboot实现分布式ID?_spring +mongodb id设计策略
- 10一文看懂自然语言处理-NLP(4个典型应用+5个难点+6个实现步骤)_nlp自然语言处理
QOS基础_服务质量admission control
赞
踩
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
QOS
前言
提示:脑子里的东西有点乱,需要有个地方整理一下,姑且当成一个个人博客来看吧。
QOS服务质量。从名字来看就是为网络提供更好的服务,让各种流量传输更加高效快速。当然了,如果想要达到这个效果需要先了解网络有哪些流量,哪些重要的,那些不重要的。重要的流量对网络的哪些参数要求比较高,是带宽,延迟抖动还是丢包率等等。
换句话说就是定义好了这些参数,业务流量就能更高效快速的传输。QoS正是这样一种可以为不同业务类型流量提供差分服务的技术,通过对网络流量进行调控,可避免并管理网络拥塞,减少报文丢包率。
可以实现什么
可以实现为不同类型的业务流量提供不同优先级别的服务。可以给对带宽,延迟,丢包率等敏感的业务流量提供优先服务,使业务能够满足用户的正常需求。
传统网络中,网络设备对报文都是采用先进先出的策略,按照报文到达先后顺序分配资源,尽力把报文送到吗目的地,不对可靠性,延迟丢包率等性能提供保证。
解决的问题
随着业务多样化,一些公司对于某些业务流量的带宽,数据的实时性和连续性有了更高的需求,报文的丢失或是高延迟是用户所不能忍受的,所以这个时候就需要对这些流量进行优先处理。所以这个时候就要求网络能够区分不同的业务流量,进而对流量提供相应等级的服务。QoS正是这样一种可以为不同业务类型报文提供差分服务的技术,通过对网络流量进行调控,可避免并管理网络拥塞,减少报文丢包率。
前面讲了什么是qos以及qos可以解决的问题,下面来讲一下qos是怎么做到这些的。
QOS大致分成3种服务模型,尽力而为模型,综合服务模型和差分服务模型
尽力而为模型是一个单一的服务模型,也是最简单的服务模型。应用程序可以在任何时候,发出任意数量的报文,而且不需要事先获得批准,也不需要通知网络。Best Effort模型中,网络尽最大的可能性来发送报文,但对时延、可靠性等性能不提供任何保证。
综合服务模型是通过硬件方式实现的。这种方式的QOS比较适合对应用流量的处理行为是能够预期的环境中的。
它主要依赖于RSVP资源预留协议。当一个支持RSVP的应用发送数据前需要利用这个协议向RSVP网络请求特定类型的服务,
并且应用把他的流量配置文件发给网络,告知网络按照配置要求给自身分配资源,只有满足了这样的环境后才会发送数据。当网络得到确认后才可以发送数据。当然还得有一些控制措施,就是得通过在PDP策略决策点使用COPS通用开放策略服务来集中完成许可控制。
应用程序首先通过RSVP信令通知网络它的QoS需求(如时延、带宽、丢包率等指标),在收到资源预留请求后,传送路径上的网络节点实施许可控制(Admission control),验证用户的合法性并检查资源的可用性,决定是否为应用程序预留资源。一旦认可并为应用程序的报文分配了资源,则只要应用程序的报文控制在流量参数描述的范围内,网络节点将承若满足应用程序的QoS需求。传输路径上的网路节点可以通过执行报文的分类、流量监管、低延迟的排队调度等行为,来满足对应程序的承诺。
最大的缺点是可扩展性,以及对网络节点的消耗较大。适用于需要保证带宽、低延迟的实时多媒体应用,如电视会议、视频点播等。
另一种就是差分服务模型。相对于综合服务模型更加灵活。它会对数据流进行分类,然后就可以进一步对各种不同类的流量进行控制。这个控制是由策略表来实现。
差分服务模型主要有以下特性,
一、分类
前面也说了它会对数据流进行分类,那么分类的依据就是内部DSCP区别服务编码点。
二层数据帧中的优先级是针对vlan帧的,使用cos来区分不同的数据流,并且只出现在ISL或802.1Q的封装帧中。
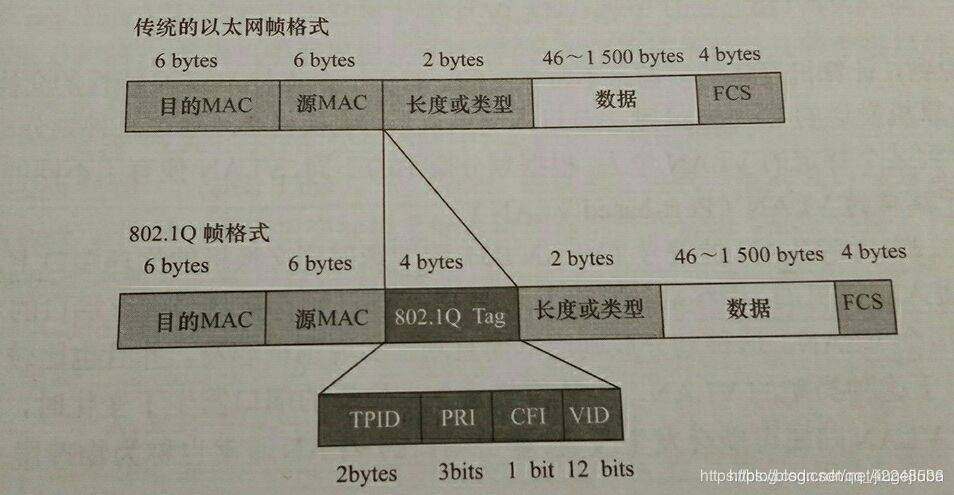
TPID表示这个帧是否带标签。如果该值取值为0x8100,则表示这个帧是带Tag的帧;相反表示其实是传统的、不带Tag标签的帧。
PRI表示优先级,取值范围是0-7,最高级是7。#最高优先级为7,应用于网络管理和关键性网络流量,如路由选择信息协议(RIP)和开放最短路径优先(OSPF)协议的路由表更新;优先级6和5主要用于延迟敏感(delay-sensitive)应用程序,分别对应交互式话音和视频;优先级4到1主要用于受控负载(controlled-load)应用程序、流式多媒体(streaming multimedia)、关键性业务流量(business-scritical traffic),如SAP数据和后台流量。优先级0是缺省值,并在没有设置其他优先级值的情况下自动启用。
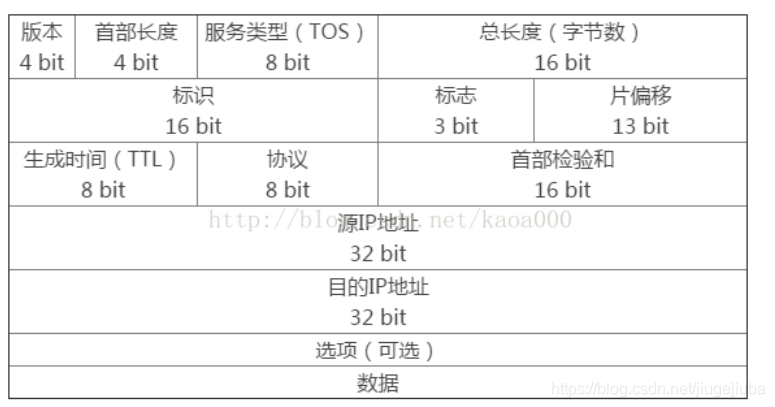

IP优先级部分共3位,取值范围为0~7,值越大越优先。
#6和7一般保留给网络控制数据使用,比如路由;5推荐给话音数据使用;4推荐由视频会议和视频流使用;3推荐给话音控制数据使用;1和2推荐给数据业务使用;0为缺省标记值。在IP优先级配置时,既可以使用0~7这样的数值,也可使用上述对应的优先级名称。
后4位表示tos部分,代表需要为对应报文提供的服务类型。3-6位分别代表延时,吞吐量,可靠性和路径开销。
要注意的是,虽然ToS部分共有4位,但每个IP包中这4位中只能有一位为1
在新的RFC2474标准中,重新定义了原来IP包头部的ToS字段,并改称为DS(DifferentiatedServices,差分服务)字段,也是共一个字节(8位)。总的来说,第0~5位(共6位)用来表示DSCP(Differentiated Services Code Point,差分服务代码点)优先级,取值范围为0~63,共能标识出64个优先级值(值越大,优先级越高),最后两位保留,用于显示拥塞指示特性。
当支持DSCP的设备收到仅支持ToS中的IP优先级的报文时,缺省情况下它们之间是有一种映射关系的。当然,如果设备仅支持ToS的IP优先级,是不能识别报文中的DSCP优先级值的,这时需要事先在接收设备配置好DSCP优先级与IP优先级的映射关系。
说完了分类再来说下分类的方法。
1.按接口信任模式
当没有使用qos的时候,对数据包的处理时尽力而为。这时候就算数据包中有DSCP,只要经过端口就会被设置为0.不信任这些DSCP值。接口信任模式开启后,设备接收到带有cos值 ip优先级DSCP值就会按照默认的映射方式映射到内部dscp值,按照这个值对数据流进行操作。当然也可以手工指定映射关系。
2、acl。就是被acl匹配到的数据流可以看成一个分类。
3.NBAR,基于网络的应用识别。
二、标记
标记指的是对某个参数的数值进行了修改。这个特性可以实现从某个特定的接口进入的数据包的DSCP值,这样就能对某些数据流进行特定服务的目的。可以根据网络的具体环境人为的把一些需要优先对待的数据流打上想要的DSCP。然后这些流量进入设备后OQS会根据DSCP所映射的内部DSCP对流进行一定操作。
三、流量调节
流量调节方面,可以通过两种方式达到效果,一个是用流量监管,一个是用流量整形。
整形测量通信流的速率,来确定并推迟超额的通信流的传输时间,确保通信速率不超过指定的值。这样一来,也就是可以保证所有的这些数据都是可以传输出去的,但是付出的代价就是:延迟有可能会大大的增加。
流量监管TP(Traffic Policing)就是对流量进行控制,通过监督进入网络的流量速率,对超出部分的流量直接丢弃,使进入的流量被限制在一个指定的范围之内,监管适用与对延迟要求比较高的业务,比如语音流量。
监管可以同时作用在出向和入向。
为了控制队列中数据包出队的速率,就需要精确计算单位时间内出队的数据包数量以及大小,而这通常是很复杂的。为了进行简化,现在一般都使用另一种机制:系统以一定的速率产生令牌,每个数据包(或一个字节)对应一个令牌,只有当令牌充足的时候数据包才能出队。
流量监管由三部分组成:
Meter:通过令牌桶机制对网络流量进行度量,其实就是看令牌桶中是否有足够的令牌供流量出队,向Marker输出度量结果。
Marker:根据Meter的度量结果对报文进行染色,报文会被染成green、yellow、red三种颜色。
Action:根据Marker对报文的染色结果,对报文进行一些动作,动作包括:
pass:对测量结果为“符合”的报文继续转发。
remark + pass:修改报文内部优先级后再转发。
discard:对测量结果为“不符合”的报文进行丢弃。
默认情况下,green报文、yellow报文进行转发,red报文丢弃。
流量整形TS(Traffic Shaping)是一种主动调整流量输出速率的措施。当下游设备的入接口速率小于上游设备的出接口速率或发生突发流量时,下游设备入接口处可能出现流量拥塞的情况,此时用户可以通过在上游设备的接口出方向配置流量整形,把上游流量超出的部分缓存起来缓存满了再丢弃,等到令牌桶有足够的令牌后再发送缓存的报文。所以,整形会增加延迟,监管不会。整形只能作用在接口出向。整形适用与对可靠性要求比较高的业务。
当报文到来的时候,首先对报文进行分类,使报文进入不同的队列。
若报文进入的队列没有配置队列整形功能,则直接发送该队列的报文;否则,进入下一步处理。
以用户设定的队列整形速率向令牌桶中放置令牌:
如果令牌桶中有足够的令牌可以用来发送报文,则报文直接被发送,在报文被发送的同时,令牌做相应的减少。
如果令牌桶中没有足够的令牌,则将报文放入缓存队列,如果报文放入缓存队列时,缓存队列已满,则丢弃报文。
缓存队列中有报文的时候,系统按一定的周期从缓存队列中取出报文进行发送,每次发送都会与令牌桶中的令牌数作比较,直到令牌桶中的令牌数减少到缓存队列中的报文不能再发送或缓存队列中的报文全部发送完毕为止。
拥塞管理:
拥塞管理是指在网络间歇性出现拥塞,时延敏感业务要求得到比其它业务更高质量的QoS服务时,通过调整报文的调度次序来满足时延敏感业务高QoS服务的一种流量控制机制。拥塞管理通过队列机制来实现:使用不同的调度算法来发送队列中的报文流。设备上,每个接口出方向都有4或8个队列,以队列索引号进行标识,队列索引号分别为0,1,2,3或者0-7。
对于进入设备的报文,设备将报文携带的优先级映射为内部优先级,然后根据内部优先级与队列之间的映射关系确定报文进入的队列。
PQ是一种优先级队列。针对于关键业务类型应用设计。按照严格优先级进行调度的队列,PQ对队列划分等级,只有高优先级的队列排空以后才会对低一级的队列调度报文,这样重要的业务比其他业务提前获得服务。
针对关键业务应用设计,关键业务在拥塞发生时,需要优先获得服务减少响应延迟。
PQ调度机制:分为4个队列,分别为高优先队列(Top)、中优先队列(Middle)、正常优先队列(Normal)和
低优先队列(bottom)

PQ的优缺点:
1、优点:
①高优先级队列的时延控制的非常好
②实现简单,能够区分多种业务
2、缺点:
①无法做到带宽的合理分配,高优先级的流量比较大时,导致低优先级的流量产生“饿死现象”
②高优先级的流量得到保证的代价是牺牲低优先级的时延
③如果高优先级传送TCP流量,低优先级传送UDP流量,那么TCP增加传送速率,导致UDP流量无法得到足够的带宽。
WRR加权循环调度 在轮询的时候,每个队列发送包的优先级和该队列的权重成正比。当某个队列的流量少的时候,剩余带宽能够被其他队列按照比例占用。
在进行WRR调度时,设备根据每个队列的权值进行轮循调度。调度一轮权值减一,权值减到零的队列不参加调度,当所有队列的权限减到0时,开始下一轮的调度。例如,用户根据需要为接口上8个队列指定的权值分别为4、2、5、3、6、4、2和1。
各队列中的报文流被调度的次数与该队列的权值成正比,权值越大被调度的次数相对越多。由于WRR调度的以报文为单位,因此每个队列没有固定的带宽,同等调度机会下大尺寸报文获得的实际带宽要大于小尺寸报文获得的带宽。
WRR调度避免了采用PQ调度时低优先级队列中的报文可能长时间得不到服务的缺点。WRR队列还有一个优点是,虽然多个队列的调度是轮询进行的,但对每个队列不是固定地分配服务时间片——如果某个队列为空,那么马上换到下一个队列调度,这样带宽资源可以得到充分的利用。但WRR调度无法使低延时需求业务得到及时调度。
WRR优缺点:
1、优点
①能够按照权重分配带宽,并且队列中剩余带宽能够为其他队列公平占用
②实现比较简单、复杂度低
③实现diffserv聚合后的端口
2、缺点
①与RR调度算法一致,在报文长度不一致的时候,调度不准确
②在调度速率低的时候报文的时延控制的不好,时延抖动无法预期。
#对于WRR来说实际上也是按照字节去调度的。
比如说有三个队列,3个队列的权重分别是3,2,1。 这时候来了若干个包,分到不同的队列中后,能够发出的包的数量就是队列1是3个,队列2是2个,队列1是1个。
DRR调度
DRR调度同样也是RR的扩展,相对于WRR来说,解决了WRR只关心报文,同等调度机会下大尺寸报文获得的实际带宽要大于小尺寸报文获得的带宽问题,在调度过程中考虑包长的因素以达到调度的速率公平性。
DRR调度中,Deficit表示队列的带宽赤字,初始值为0。每次调度前,系统按权重为各队列分配带宽,计算Deficit值,如果队列的Deficit值大于0,则参与此轮调度,发送一个报文,并根据所发送报文的长度计算调度后Deficit值,作为下一轮调度的依据;如果队列的Deficit值小于0,则不参与此轮调度,当前Deficit值作为下一轮调度的依据。
假设有两条队列,Q7和Q6,分别获得400byte/s和300。
第一轮调度,赤字Q7是0+400=400,Q6就是0+300=300.从Q7队列取出900byte的报文发送,从Q6取出400byte的报文发送,发送后,Q7的赤字是400-900=-500,,Q6是300-400=-100.
第二轮调度,Q7赤字是-500+400=-100,Q6是-100+300=200,Q7赤字值小于0所以此轮不能参与调度,从Q6中取出300byte的报文发送,发送以后Q6的赤字为200-300=-100。
第三轮,Q7的赤字是-100+400=300,Q6是-100+300=200,Q7取出600byte的报文发送,Q6取出500byte的报文发送,发送以后Q7的赤字值为300-600=-300,Q6就是200-500=-300。
WFQ加权公平队列
报文到达接口后,先对报文进行分类,形成一股流,然后把不同的流分到不同的队列,出队的时候,WFQ按照流的权重分配每个流可以占用的带宽。权重越大所分得的带宽越多。
WFQ有两种分类方式,
一种是按流的会话信息分类,根据报文的协议类型,源目tcp或udp端口,源目ip地址,tos域中的优先级位等自动进行流分类,尽可能多的提供队列,把每个流均匀的放入不同队列,从而在总体上均衡流的延迟。出队时,WFQ按照流的优先级来分配每个流应占带宽。
另一种是按优先级分类,通过优先级映射把流量标记成本地优先级,每个本地优先级对应一个队列号,每个接口预分配8个队列,报文根据队列号进入队列,默认情况下,队列的WFQ权重相同,流量平均分配接口带宽,用户也可以通过配置修改权重,高优先权和低优先权按权重比例分配带宽。
WFQ采用的是五元组的方式去进行分类,如果存在优先级,那么就是六元组。这个优先级就是DSCP
WFQ会把一股流分配到队列中,这个过程叫散列,使用HASH算法来完成。这种方式会尽量把不同特征的流分配到不同的队列。
在出队的时候,WFQ按流的优先级来分配每个流应占有的出口带宽。优先级的数值越小,所得的带宽越少。优先级的数值越大,所得的带宽越多。这样就保证了相同优先级业务之间的公平,体现了不同优先级业务之间的权值。
CBQ基于类的加权公平队列,
是对WFQ功能的扩展,为用户提供了自定义类的支持。CBQ首先根据IP优先级或者DSCP优先级、入接口、IP报文的五元组等规则来对报文进行分类,然后让不同类别的报文进入不同的队列。对于不匹配任何类别的报文,会送入系统定义的缺省类。
CBQ提供了三类队列,分别是最高优先级的EF队列,只有当EF队列的报文调度完成后,才会调度其他队列的报文。为EF定义的DSCP值就是EF,十进制值为46,二进制是101110。
第二种AF队列,提供关键业务流量的带宽保障,每个AF队列分别对应一类报文,用户可以设定每类报文占用的带宽。当系统调度报文出队的时候,会按用户为各类报文设定的带宽将报文进行出队发送,可实现各个类的队列的公平调度。
第三种BE队列,尽力发送业务流量。 当报文不能匹配用户设定的类时,会被送到BE队列中,用接口剩余带宽和WFQ调度方式发送。
在AF队列中为排队操作定义了4中类别,而且每个队列都定义了3个丢弃级别。为了标记数据包并对数据包进行分类,以确定该把数据包放到4个队列的哪一个,同时还要确定各队列中的3个丢弃优先级之一,定义了12种DSCP数值及其含义。AF DSCP名称格式为AFxy,其中x表示队列之一,数值1-4,y表示3个丢弃优先级数值1-3。
建议DSCP名称中x值越大,越优先排队。y值越大,该数据包应该获得越差的丢弃处理(级别越大越可能被丢弃)。
DSCP值0-1bite指定队列等级,3-4指定丢弃优先级,所以仅支持IP优先级的排队工具也能处理dscp值。
优点:提供了自定义类的支持;可为不同的业务定义不同的调度策略。
缺点:由于涉及到复杂的流分类,故启用CBQ会耗费一定的系统资源。
本质上,队列是一种调度的实现。网络链路通常要求数据包以一定的顺序发送,因此可以在网络设备(e.g. 主机、交换机、路由器等)的出口处使用队列来管理数据包。
对队列中对数据包顺序进行排列或重排就叫做调度。
CBS 先进行分类 再限速 cir dir 单位时间内允许多少流量通过就是令牌桶
拥塞避免
指通过监视网络资源的使用情况,有拥塞发生或有加剧的趋势时主动丢弃报文,通过调整网络的流量来解除网络过载的一种流控机制。常用尾部丢包策略和WRED。
传统的尾部丢包策略tail-drop,当队列的长度达到最大值后,所有新入队列的报文(缓存在队列尾部)都将被丢弃。
这种丢弃策略会导致TCP全局同步现象。
TCP全局同步现象:
当网路存在突发流量使得队列几乎是满的,就会导致在短时间内连续大量地丢封包。而TCP流具有自适应特性(Adaptiveness),来源端发现数据包丢失就急剧地减小发送窗口(congestion window,cwnd),数据包到达速率就会迅速下降,于是网络拥塞得以解除。但源端得知网络不再拥塞后又开始增加发送速度,最终又造成网络拥塞,而且这种现象常常会周而复始地进行下去,从而在一段时间内网络处于网络利用率(Network Utilization)很低的用状态,降低了整体吞吐量(throughput),这就是所谓地"TCP全局同步"现象。
WRED加权随机先期检测
为避免TCP全局同步现象,出现了RED技术。通过随机丢弃数据报文,让多个TCP连接不同时降低发送速度,从而避免了tcp全局同步现象。使tcp速率及网络流量都趋于稳定。
基于丢弃参数随机丢弃报文。考虑到高优先级报文的利益并使其被丢弃的概率相对较小,WRED可以为不同业务的报文指定不同的丢弃策略。
WRED技术为每个队列的长度都设定了阈值上下限,并规定:
当队列的长度小于阈值下限时,不丢弃报文。
当队列的长度大于阈值上限时,丢弃所有新收到的报文。
当队列的长度在阈值下限和阈值上限之间时,开始随机丢弃新收到的报文。方法是为每个新收到的报文赋予一个随机数,并用该随机数与当前队列的丢弃概率比较,如果大于丢弃概率则报文被丢弃。队列越长,报文被丢弃的概率越高。
除了阈值外还有一个参数值是MPD标记概率分母,最大丢弃比例就是按照MPD分之1的方式来计算。从最小阈值到最大阈值的丢弃比例就是从0%到MPD%。

第二种就是针对携带不同IPP或DSCP值的数据包分配相应优先级。所以WRED为拥有不同优先级值的数据包使用了不同的丢弃比例。WRED的丢弃级别包含了三个关键的变量,分别是最小阈值,最大阈值和MPD。
IPP 0 和IPP 3的WRED流量配置简档

从图中可以看出优先级为0的流量从到达最小阈值就开始按照比例丢包,直到最大阈值后丢弃所有新收到的包。而优先级为3的流量到达了最小到最大阈值中间的一个位置才开始丢包,并且丢弃的比例还比优先级为0的流量要小。
就像CBQ基于类的加权公平队列里的AF队列。 (EF AF BE)
在AF队列中为排队操作定义了4中类别,而且每个队列都定义了3个丢弃级别。为了标记数据包并对数据包进行分类,以确定该把数据包放到4个队列的哪一个,同时还要确定各队列中的3个丢弃优先级之一,定义了12种DSCP数值及其含义。AF DSCP名称格式为AFxy,其中x表示队列之一,数值1-4,y表示3个丢弃优先级数值1-3。
建议DSCP名称中x值越大,越优先排队。y值越大,该数据包应该获得越差的丢弃处理(级别越大越可能被丢弃)。
在相同队列中的流量表示有相同的优先级,但是如果丢弃级别不同的话就表示值越大就会从越小的阈值按照MPD的值就开始丢包。
分类和标记工具可能会检查数据包的IP地址,入站COS参数以及tcp或udp端口号,然后为匹配的数据包标记ip优先级或dscp值,
此后,其他qos工具在做qos决策前只需要简单的查找这些标记字段就可以了。
分类,仅适用于入站接口,而且要求该接口支持特定的报头字段。
标记,仅适用于出站接口,而且要求接口支持特定的报头字段。
MPLS网络中,可以根据MPLS标签中的EXP字段做qos决策,但是无法查看封装后的IP报头和DSCP字段。此时需要在边缘设备上配置qos工具来查看dscp,然后再标记一个不同的字段。
由于只有部分区域存在非IP报头的可标记字段,所以可以仅在适当的接口利用这些字段分类或标记。
COS 802.1Q报头,DE 帧中继报头,CLP ATM信元头。MPLS EXP mpls报头。
比如在接口配置了CB标记特性,就可以基于cos值分类入站帧,并根据cos值标记出站帧。
MQC
由于qos特性及功能都需要使用自己独立的配置和执行命令,因为大量不同的qos工具和命令使得配置变得繁琐,因此开发了MQC来解决这个问题。它定义了一组常用的配置命令,可以在路由器或交换机上配置常见的qos功能特性。
MQC把qos工具的分类功能分离出来,为此qos包含了三个重要的命令和一些常规命令。
class-map 定义匹配参数,从而把数据包分类到不同的服务类别中
policy-map 定义PHB操作,标记或排队等。
service-policy 命令在接口上启动策略映射。

单个策略可以引用多个类别,在每个类别下单独配置qos操作,比如打上不同的标记。最后是在接口的出或入方向调用。
还是先说用分类映射进行分类,在moc分类映射内部使用match子命令进行分类。在匹配的似乎可以提供多个选项,qos字段,acl以及mac地址。名称区分大小写,match protocol表示使用NBAR基于网络的应用识别来匹配。match any表示匹配任何数据包。
使用多条match命令。在某些时候需要检查数据包中的多项内容来确定是否属于某个类,这时候就可以使用多条match命令。还可以把分类映射嵌套到别的分类映射中。每条match cos,precedence和dscp最多列4个ip优先级或8个dscp值,在数据包中发现这些设置的数值中的任意一个就表示匹配。
如果包含多条match,那么match-any或match-all参数定义的是在or或and的运算。any表示满足任意或都满足要求就匹配。all表示满足所有需求才会匹配。
match class name命令通过名称引用其他分类映射,来嵌套使用被引用的分类的匹配逻辑。
使用NBAR分类。
NBAR通常负责那种很难分类的数据包。比如应用程序使用动态端口,那么静态配置的匹配tcp或udp的match就无法对流量进行分类,而NBAR可以越过TCP或UDP端口号,直接查看http请求中的主机名,url或MIME类型。
NBAR还能越过UDP和tcp的白头识别特定应用信息。它可以用于不同的场合。和qos功能无关,可以把NBAR配置为记录流量类型的种类和每种类型流量的数量。
CB标记要求启用CEF。需要根据MOC分类映射中的匹配逻辑来分类数据包。使用class class-map-name命令引用一个或多个分类映射,对数据包进行分类后标记。使用命令service-policy in | out 在接口的入或出方向启用标记功能。按顺序处理标记的策略映射。数据包和类别匹配后很根据定义的set命令来标记。每个类都可以设置多条set,比如可以同时设置dscp和cos。
如果没有匹配到已定义的类型则会被分到默认类别。如果没设置set,则不会对该类别的数据包进行任何标记操作。

