
- 1Windows10彻底删除android studio_android studio产生的文件怎么彻底清除
- 2【水果识别】基于深度学习卷积神经网络CNN实现水果识别分类附Matlab代码_卷积神经网络水果识别
- 3小白怎么入门CTF,看这一篇就够了(内附学习笔记、靶场、工具包下载)_ctf竞赛入门指南
- 4关于分布式计算的一些概念
- 5Python--关于学生信息管理系统的课设
- 6101个著名的管理学及心理学效应(2)_心理学 每个人干的加起来超过100%
- 7Android开发——RadioButton控件_android radiobutton
- 8golang和rust嵌入式开发初探_go 嵌入式开发
- 9了解MySQL_mysql的描述
- 10深入了解ChatGPT:原理、架构、发展与使用指南_chatgpt 架构
Bench 2022 | 第一届 OpenBench 国际研讨会精彩回顾
赞
踩

2022 年 11月 6 日,由国际开放测试基准和标准委员会(BenchCouncil,国际测试委员会)与 X-lab 开放实验室、开源社 ONES Group 共同发起的 第一届 OpenBench Workshop 在 Bench 2022 全球大会期间顺利召开。本次论坛采用全线上模式,共有 50 多位来自全球该领域的专家与学者参加了本次活动。
国际开源软件生态基准论坛(OpenBench Workshop)旨在通过建立国际化共识的基准(Benchmarks)、标准(Standards)与评价(Evaluations),以促进开源软件生态系统的可持续性增长与演变。论坛邀请来自工业界、学术界、基金会、协会和政府组织等研究人员,共同探索开源软件生态基准这一前沿方向,包括但不限于能够反映开源软件生态持续发展的开放数据集(代码、活动、供应链关系等)、计量和测量方法、数据质量标准、代表性基准数据、开源软件生态系统基准任务、开源社区健康指标基准、开源软件安全基准、企业开源软件研发效能基准、OSPO组织基准、开源教育评价基准、商业开源投资基准、以及各基准的应用场景与案例等方面。
本次论坛邀请来自各界专家共同探索开源软件生态基准这一前沿方向,包括但不限于能够反映开源软件生态持续发展的开放数据集(代码、活动、供应链关系等)、计量和测量方法、数据质量标准、代表性基准数据、开源软件生态系统基准任务、开源社区健康指标基准、开源软件安全基准、企业开源软件研发效能基准、OSPO 组织基准、开源教育评价基准、商业开源投资基准、以及各基准的应用场景与案例等方面。
本次论坛由华东师范大学博士研究生、CHAOSS 社区成员夏小雅作主持。首先由华东师范大学教授王伟老师致辞,王伟老师介绍了 OpenBench 的愿景和开源生态数据的五类基准测试,希望能够借此形成业界在开源生态评测与标准方面的共识。OpenBench 将作为一个国际学术平台,聚焦于开源软件生态可持续发展过程当中的基准、标准、评价三个方面的科学问题,通过数据与量化的方式,形成相关共识,为企业、社区、政府、投资机构等不同主体提供一个系统的开源工具集。
第一个议题来自华为开源专家、Apache 软件基金会董事姜宁老师,介绍 “Data-driven of Open Source & InnerSource community build evaluation”。姜宁老师首先介绍了内源的发展,阐述企业和组织应该如何从开源模式中践行内源。该报告重点介绍了以 Apache 为最佳实践如何践行“The open source way”,以及我们应该如何借鉴 Apache 的实践对内源的成熟度进行度量。
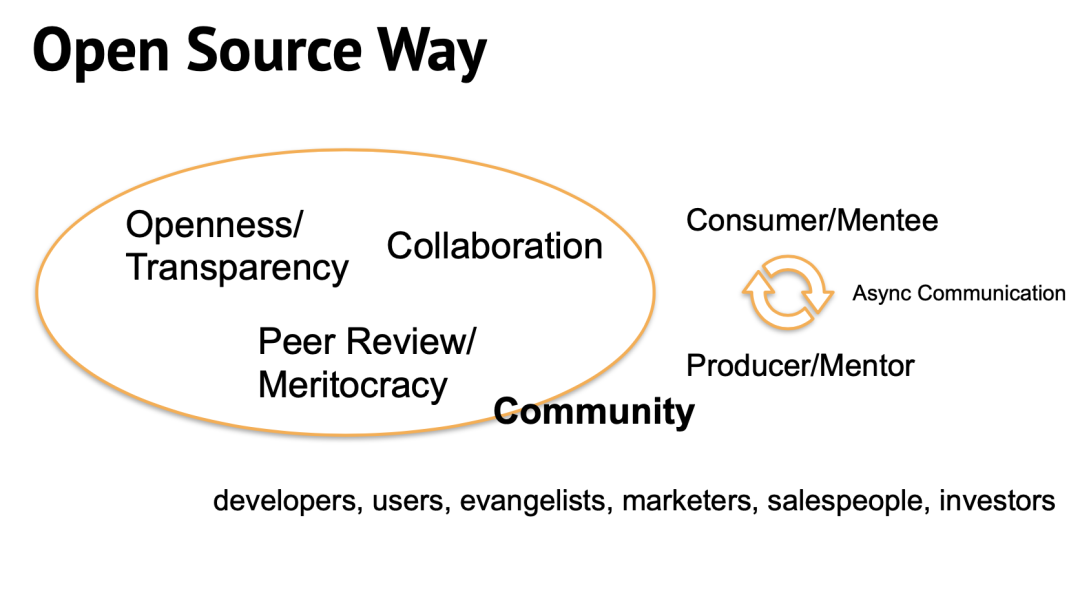
第二个议题来自 CHAOSS 社区的全栈市场运营专家 Samantha Venia Logan,介绍“Measuring qualitative data with predictability”。Samantha 从社会科学视角向我们全面、系统地介绍了如何定性的对社区进行度量,同时她提到了在线社区中的社会资本和社交货币理论,以及我们如何从多维度视角对社会资本进行度量。
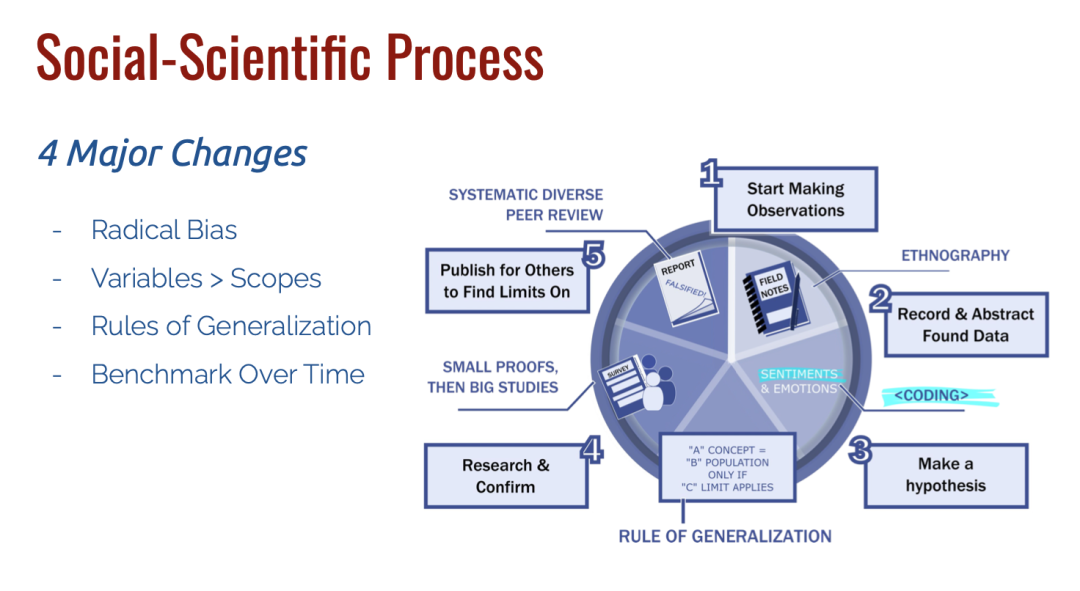
第三个议题来自南洋理工大学的刘杨教授,介绍 “Open Source Security: Challenges, Solutions, and Opportunities”。刘教授从安全的视角向我们介绍了开源软件供应链漏洞扫描和安全解决方案的相关工作。该报告还重点介绍了和开源软件安全相关的几篇工作,包括:三方库匹配、漏洞签名匹配、SCA 检测和许可证分析。

第四个议题来自蚂蚁 OSPO 的技术战略专家边思康老师,介绍 “Explore the Use of Data Heuristics in OSPO work”。从企业开源项目办公室的视角,边思康老师介绍了 OSPO 如何从顶层数字化治理企业相关的开源项目和规范化治理流程工作。最后,该报告也向学术界、产业界的专家学者们提出一个发人深省的思考:如何度量 OSPO 的成效与工作?
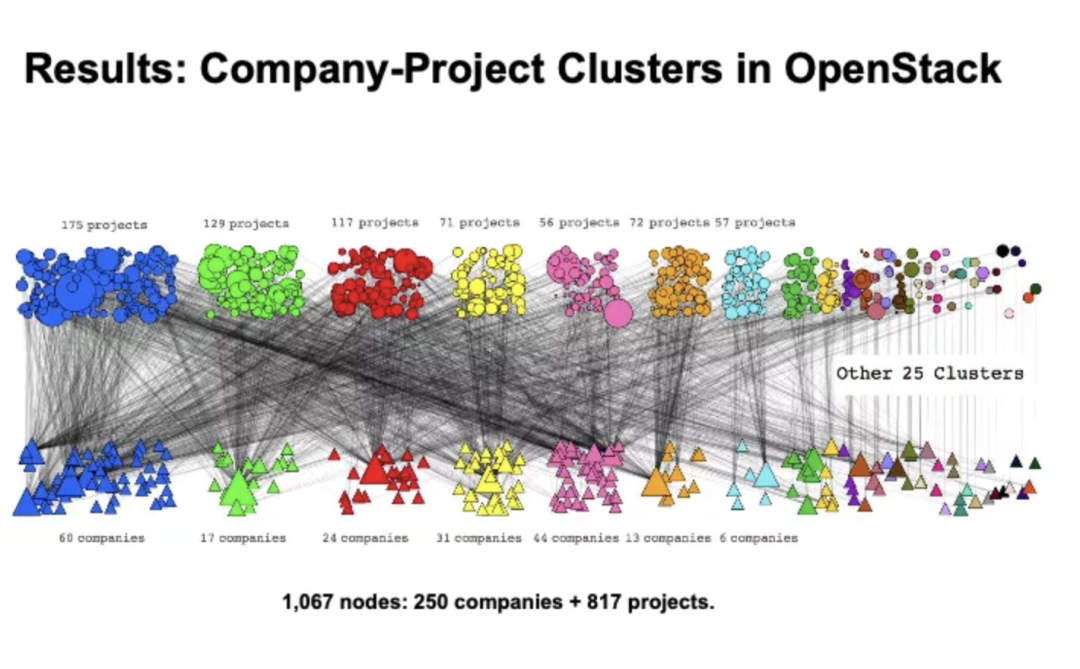
第五个议题来自北京理工大学计算机科学与技术学院的助理教授张宇霞老师,介绍“Commercial Participation in OSS Development”。以 OpenStack 作为案例,张老师的工作研究开源软件(OSS)中的商业参与的程度、形态和模式,意在理解商业参与对开源的本质可能带来的影响,同时对公司参与开源社区中的协作模式带来借鉴意义。
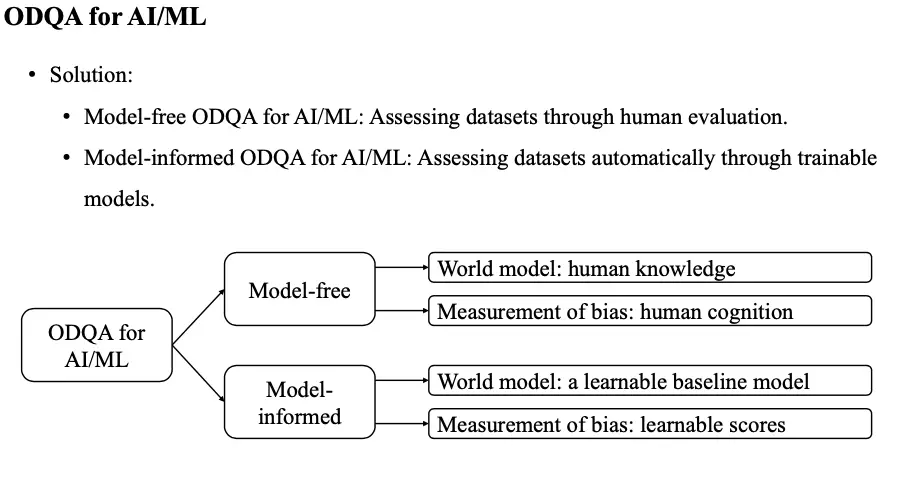
第六个议题来自上海交通大学的田济东和金耀辉老师,介绍“Model-informed Automatic Quality Assessment for Open Datasets”。和开源生态数据类似,近些年来,AI/ML 的开放研究数据集成爆炸式增长,然而数据集质量和评估标准亟待成形。该报告向我们介绍了评估开放数据集质量(ODQA,Open Dataset Quality Assessment)的几种模式。
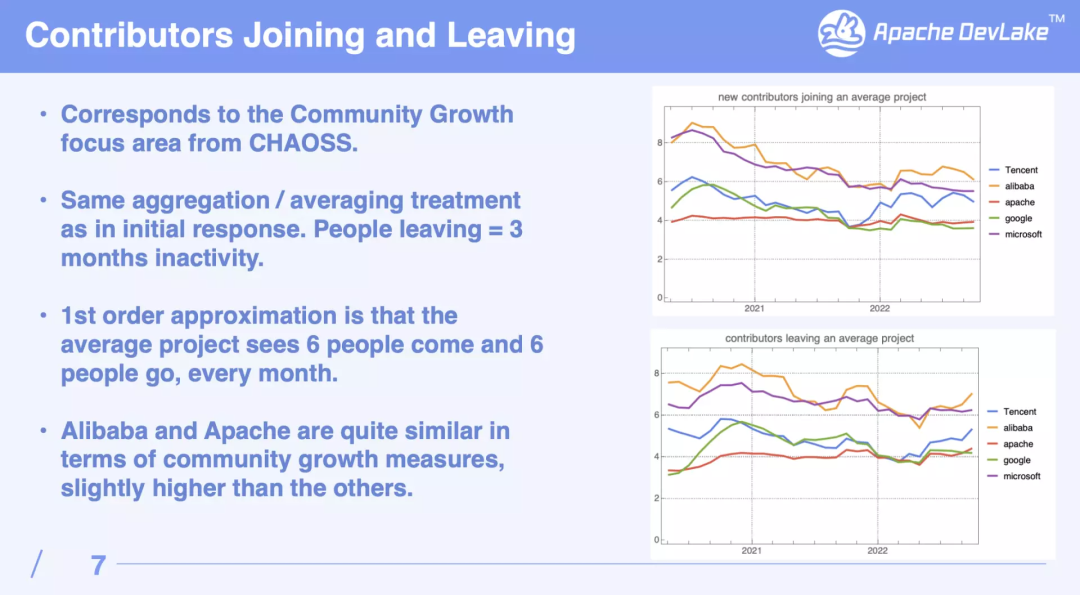
第七个议题来自 Apache DevLake 的数据科学专家张晨晖老师,介绍“Community Responsiveness Studies with Apache DevLake”。作为一款开源的研发数据平台,张晨晖老师以两个社区度量指标“社区响应度”和“社区增长”为例,介绍了 Apache DeveLake 如何进行数据收集与处理、机器人数据清洗,以及提供可视化分析的能力。
OpenBench 的仓库地址为:
https://github.com/X-lab2017/OpenBench
基于这次研讨会的成果,我们接下来将组建 OpenBench 的程序委员会(Program committee,PC),并计划在国际期刊《BenchCouncil Transactions on Benchmarks, Standards and Evaluations (TBench)》上组织相应的专刊,诚邀学术界、产业界和政府机构的专家学者们投稿,共同探索开源生态大数据的基准测试。同时也开始筹备 OpenBench 2023 的事宜,在今年成功召开的基础上,进一步扩大活动类型,除了特邀报告,还将计划征集包括:学术论文(CFP)、代表性基准(Benchmark)、开放基准数据集(Open data)、基准测试工具套件(Toolsets)等,这些内容也将通过 OpenPerf 开源项目进行沉淀,希望邀请广大感兴趣的研究学者共同建立,为繁荣开源软件生态的发展提供支撑。

本次研讨会的所有在线回放已陆续公开上传,点击阅读原文查收~
编辑丨姚王薇
相
关
阅
读


开源“摩尔定律”即将打破,《2022开源大数据热力报告》重磅发布

字节跳动开源BitSail,助力企业走好数字化“第一步”
开源社简介
开源社成立于 2014 年,是由志愿贡献于开源事业的个人成员,依 “贡献、共识、共治” 原则所组成,始终维持厂商中立、公益、非营利的特点,是最早以 “开源治理、国际接轨、社区发展、开源项目” 为使命的开源社区联合体。开源社积极与支持开源的社区、企业以及政府相关单位紧密合作,以 “立足中国、贡献全球” 为愿景,旨在共创健康可持续发展的开源生态,推动中国开源社区成为全球开源体系的积极参与及贡献者。
2017 年,开源社转型为完全由个人成员组成,参照 ASF 等国际顶级开源基金会的治理模式运作。近八年来,链接了数万名开源人,集聚了上千名社区成员及志愿者、海内外数百位讲师,合作了近百家赞助、媒体、社区伙伴。


