
- 1小程序中Echarts实现隐藏x轴,y轴,刻度线,网格_echarts隐藏网格线
- 2Python 断言和异常
- 3ios系统中openDocument API调用成功但是打开文件无反应/空白
- 4协议安全分析工具Proverif 和Proverif Editor的安装与使用_proverif教程
- 5Numpy的argsort()方法_argsort() received an invalid combination of argum
- 6DM达梦数据库快捷键_达梦可视化工具使用快捷键
- 72024年大数据最全一篇文章搞懂数据仓库:三范式与反范式,80后程序员月薪30K+感慨中年危机_数据仓库范式化
- 8git reset版本回退后悔药(图文例子)_git reset 撤销
- 92020阿里招聘岗位要求_阿里巴巴岗位要求
- 10团队协作开发中,5个强大的VS Code插件_vs协作开发
Kylin (六) --------- 查询性能优化_kylin查询的并发调优
赞
踩
前言
在 Kylin4.0 中,查询引擎(SparderContext)也使用 spark 作为计算引擎,它是真正的分布式查询擎,特别是在复杂查询方面,性能会优于 Calcite。然而,仍然有许多关键性能点需要优化。除了上面提到的设置适当的计算资源之外,它还包括减少小的或不均匀的文件,设置适当的分区,以及尽可能多地修剪 parquet 文件。Kylin4.0 和 Spark 提供了一些优化策略来提高查询性能。
一、使用排序列快速读取 parquet 文件
创建 cube 时,可以指定维度列的排序,当保存 cube 数据时,每个 cuboid 的第一个维度列将用于执行排序操作。其目的是在使用排序列进行查询时,通过 parquet 文件的最小最大索引尽可能地过滤不需要的数据。
在 cube 构建配置的高级配置中,rowkey 的顺序就是排序顺序:
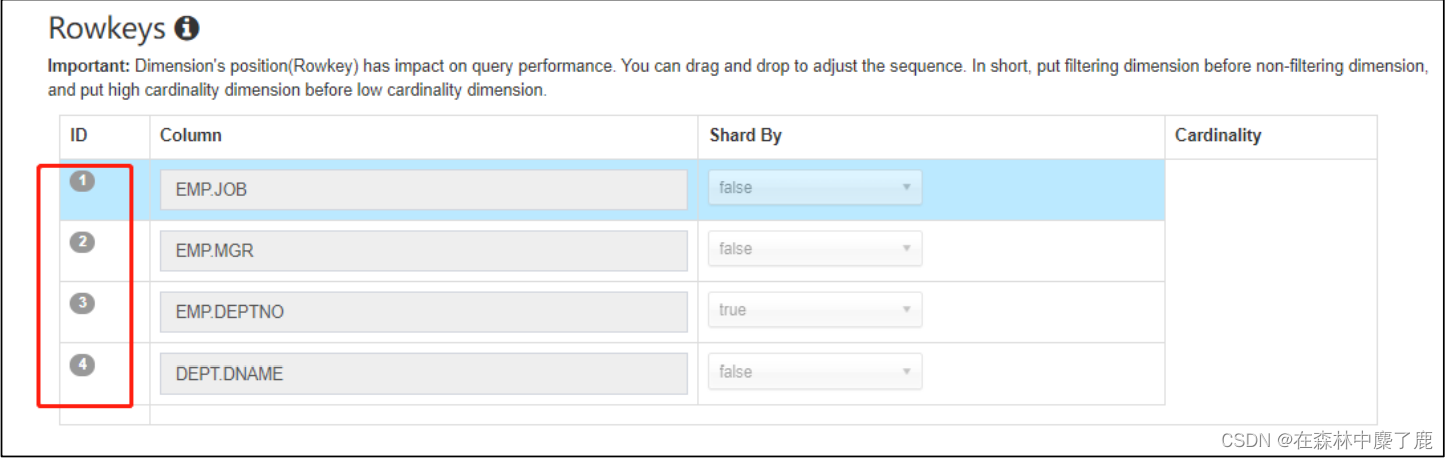
页面中可以左键点击 ID 进行拖拽,调整顺序
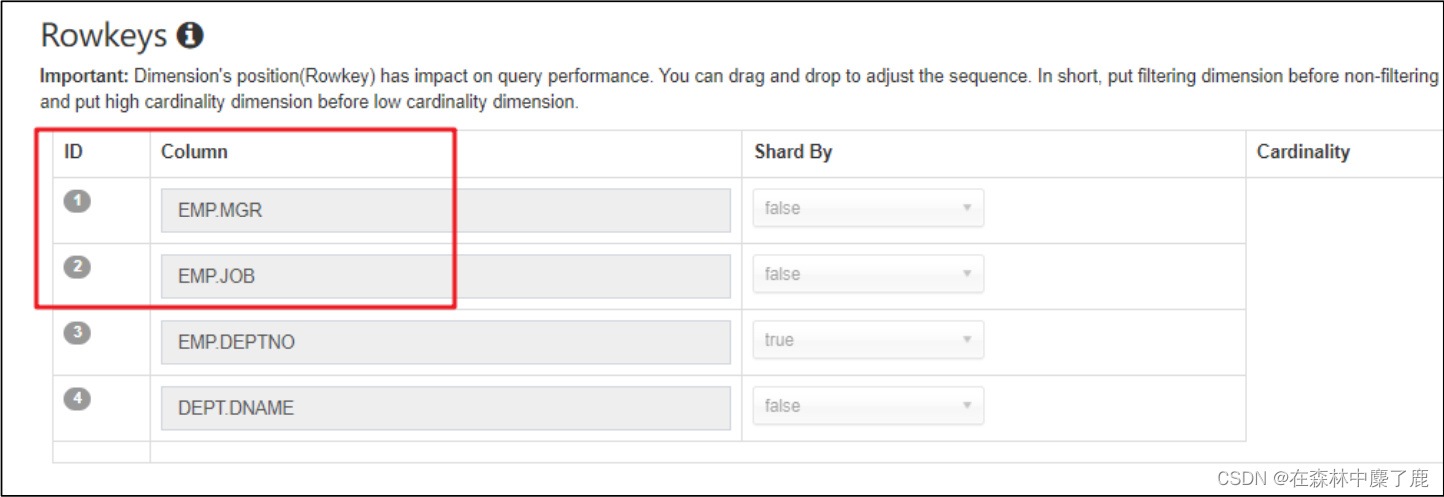
二、使用 shardby 列来裁剪 parquet 文件
Kylin 4.0 底层存储使用的是 Parquet 文件,并且 Parquet 文件在存储的时候是会按照某一列进行分片的。这个分片的列在 Kylin 里面,我们称为是 shardBy 列,Kylin 默认按照 shardBy 列进行分片,分片能够使查询引擎跳过不必要的文件,提高查询性能。我们在创建 Cube 时可以指定某一列作为shardBy 列,最好选择高基列 (基数高的列),并且会在多个 cuboid 中出现的列作为 shardBy 列。
如下图所示,我们按照时间 (月) 过滤,生成对应的 Segment,然后按照维度 A 作为 shardBy 列进行分片,每个 Segment 里面都会有相应的分片。如果我们在查询的时候按照时间和维度 A 进行过滤,Kylin 就会直接选择对应 Segment 的对应分片,大大的提升的查询效率。
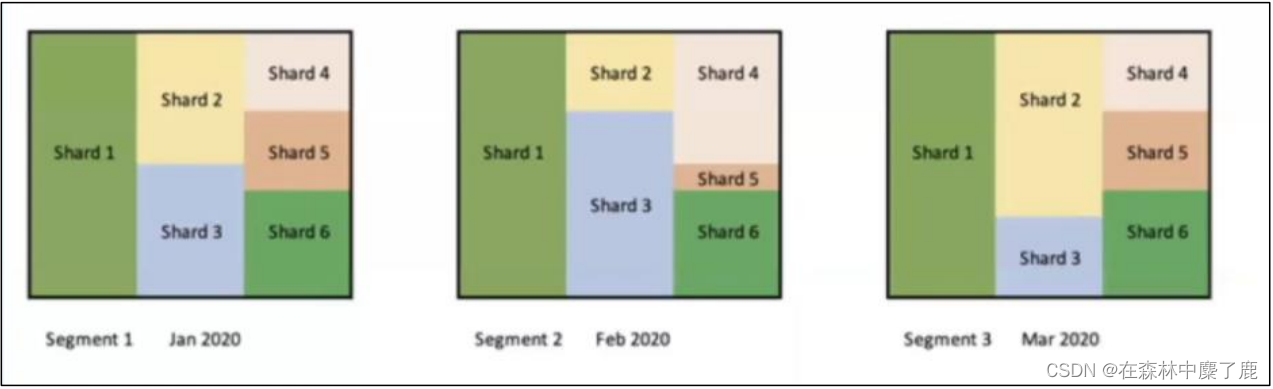
在 Kylin 4.0 中,parquet 文件存储的目录结构如下:

查询时,查询引擎可以通过日期分区列过滤出 segment-level 目录,并通过 cuboid 过滤出 cuboid-level 目录。但是在 cuboid-level 目录中仍有许多 parquet 文件,可以使用 shard by 列进一步裁剪parquet 文件。目前在 SQL 查询中只支持以下过滤操作来裁剪 parquet 文件:Equality、In、InSet、IsNull。
A、修改 cube 配置
这里拿已有的 cube 来做演示,先对已有 cube 清空数据。
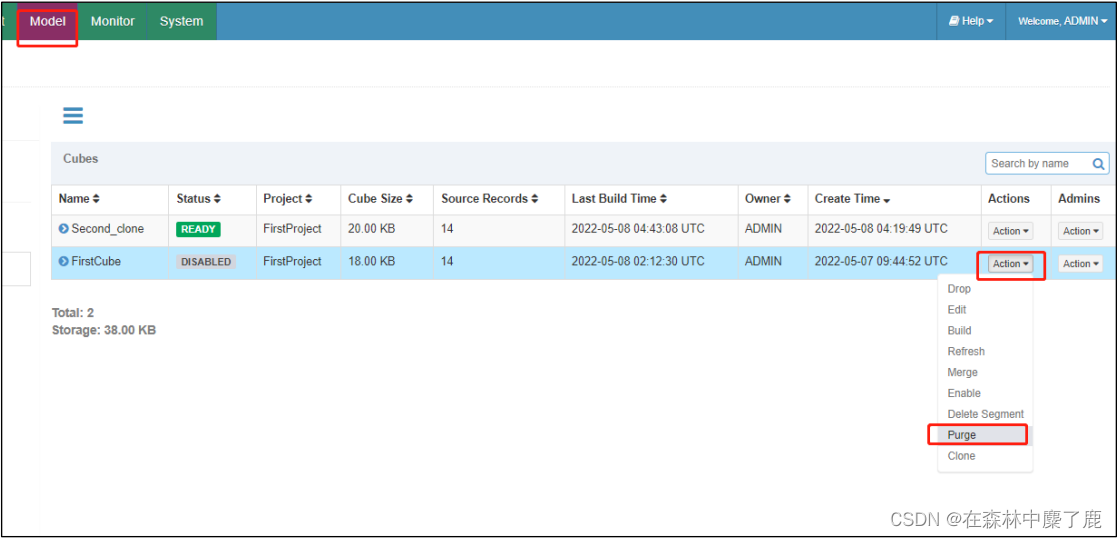
对其 disable 禁用:
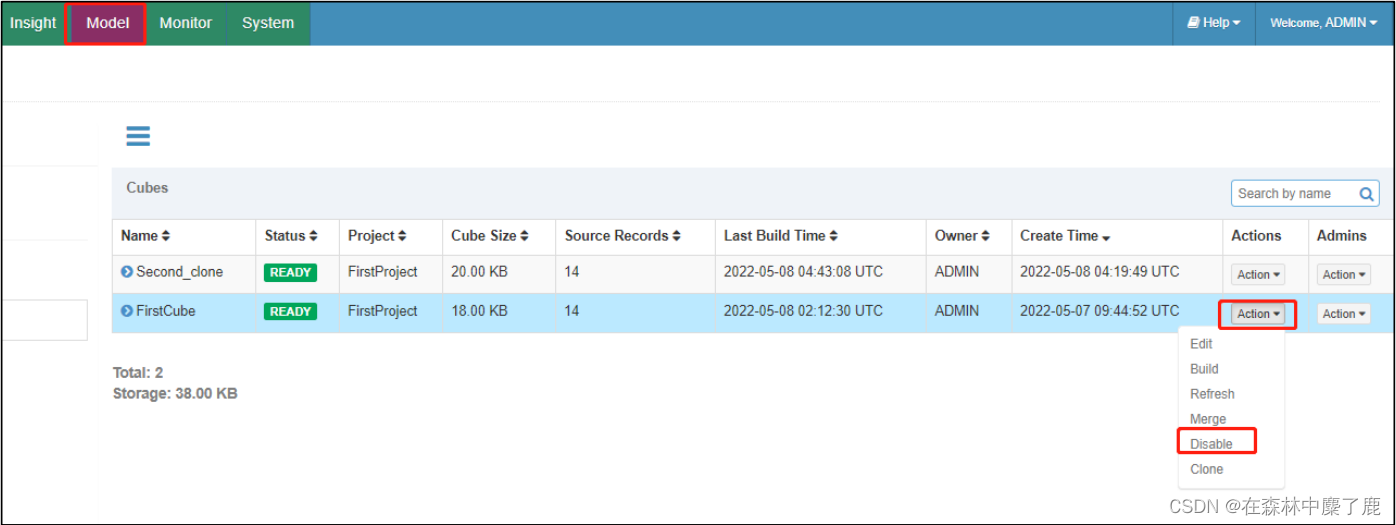
B、指定 shardby 列
进行编辑:
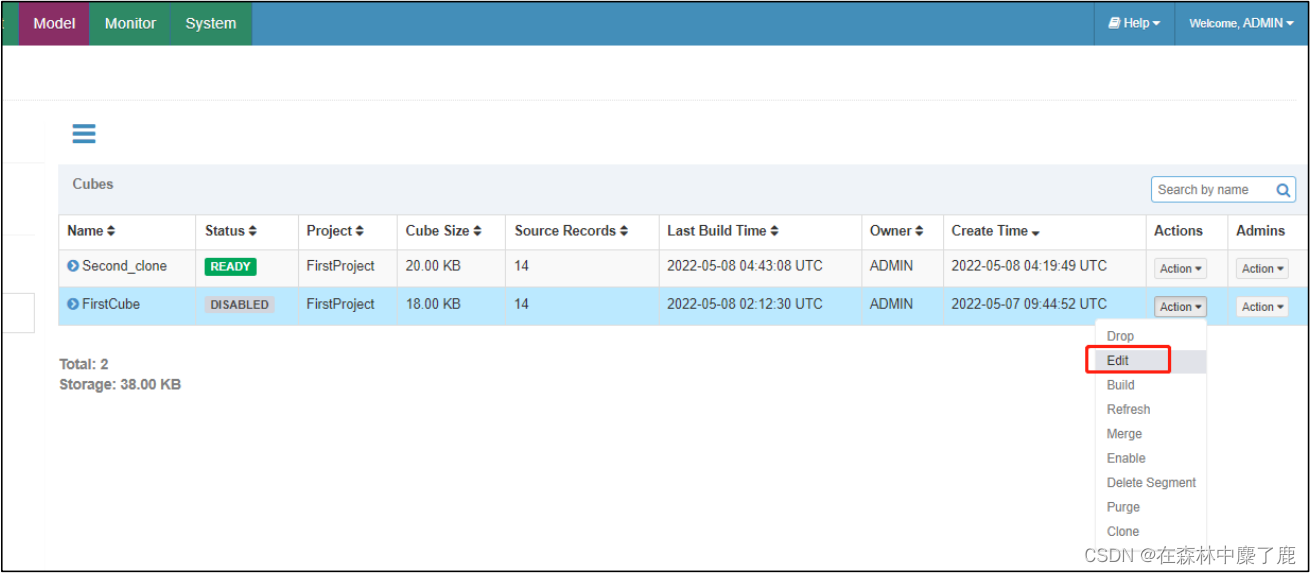
点击高级配置:
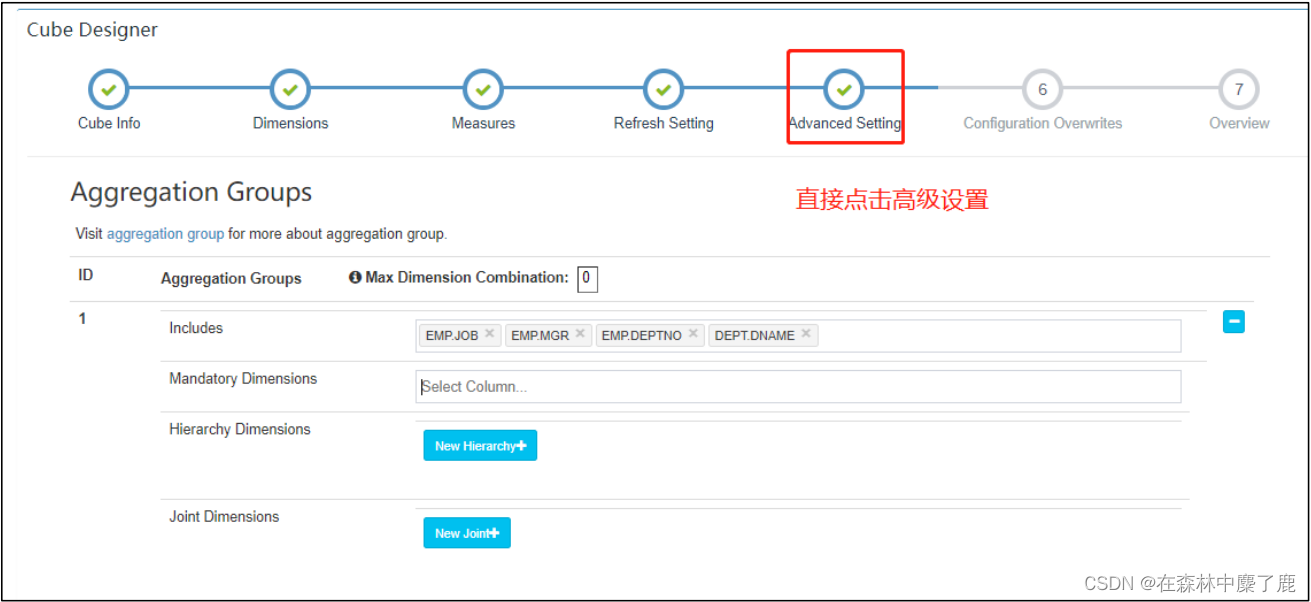
选择需要的列,将 shardby 改成 true。
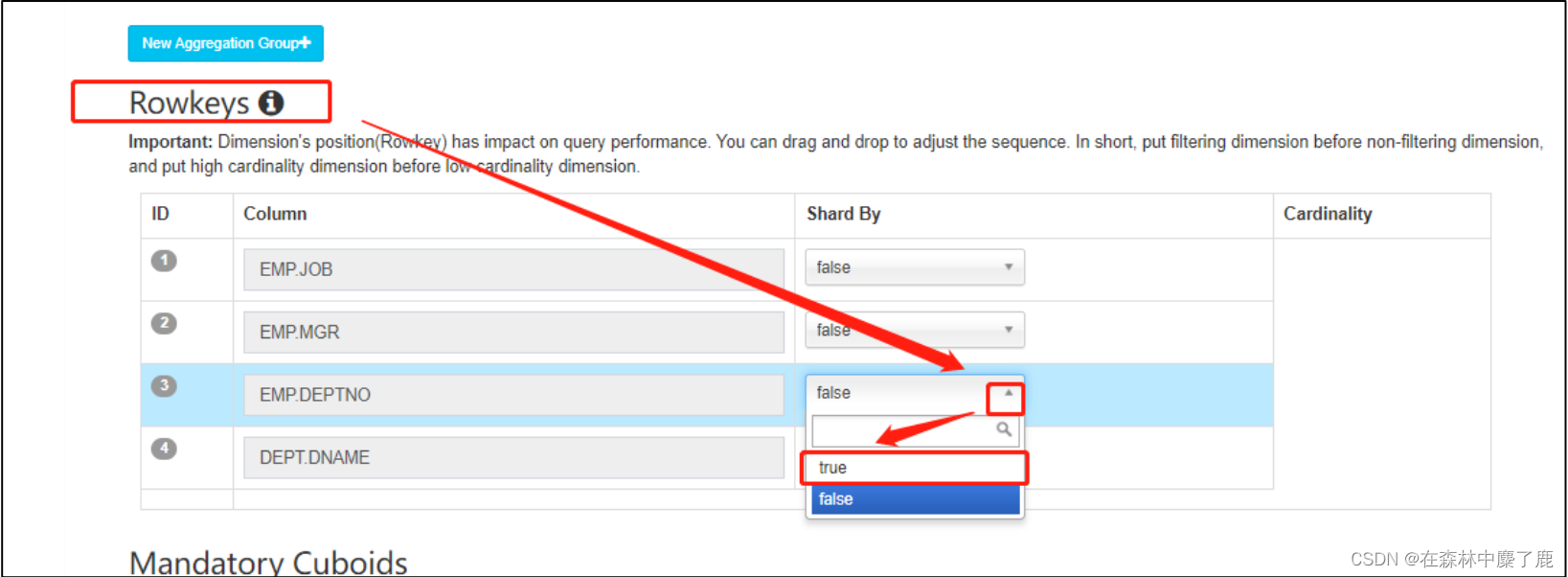
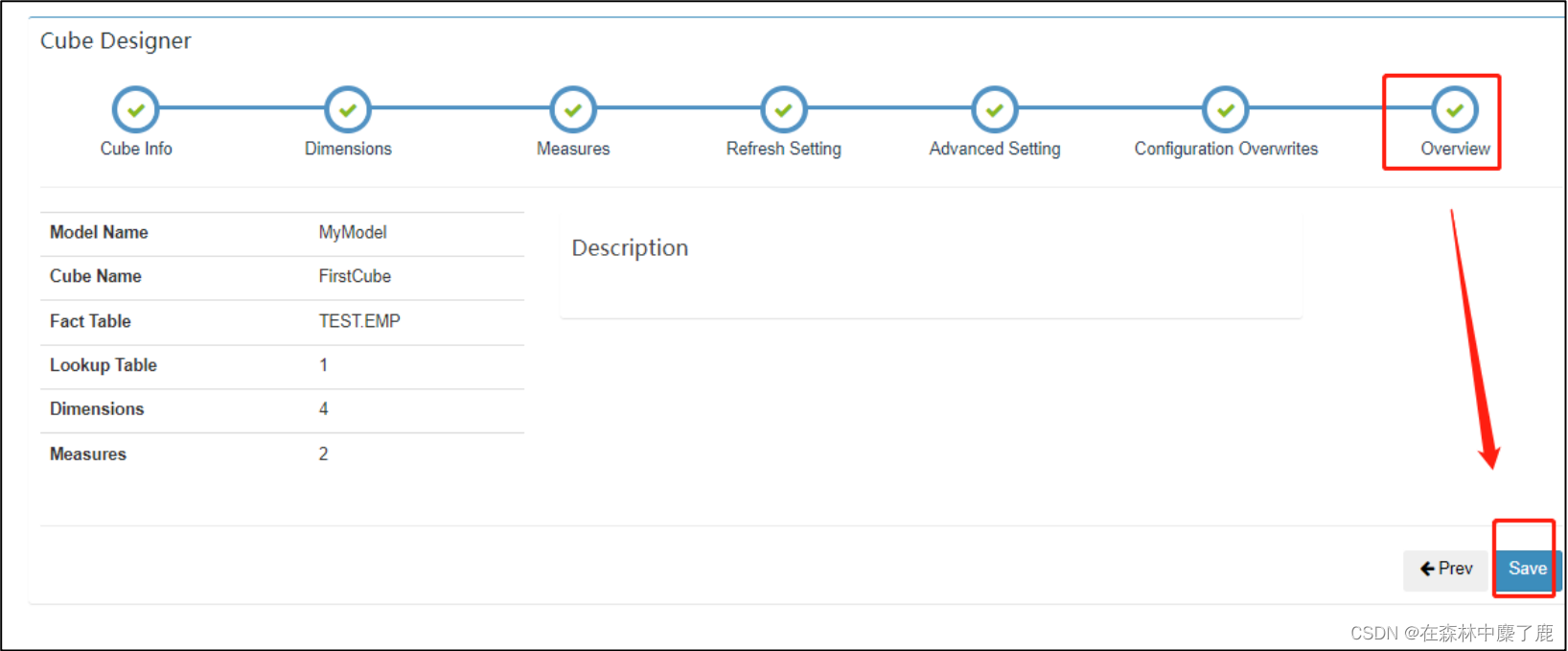
点击 Overview,选择保存:
C、重新构建
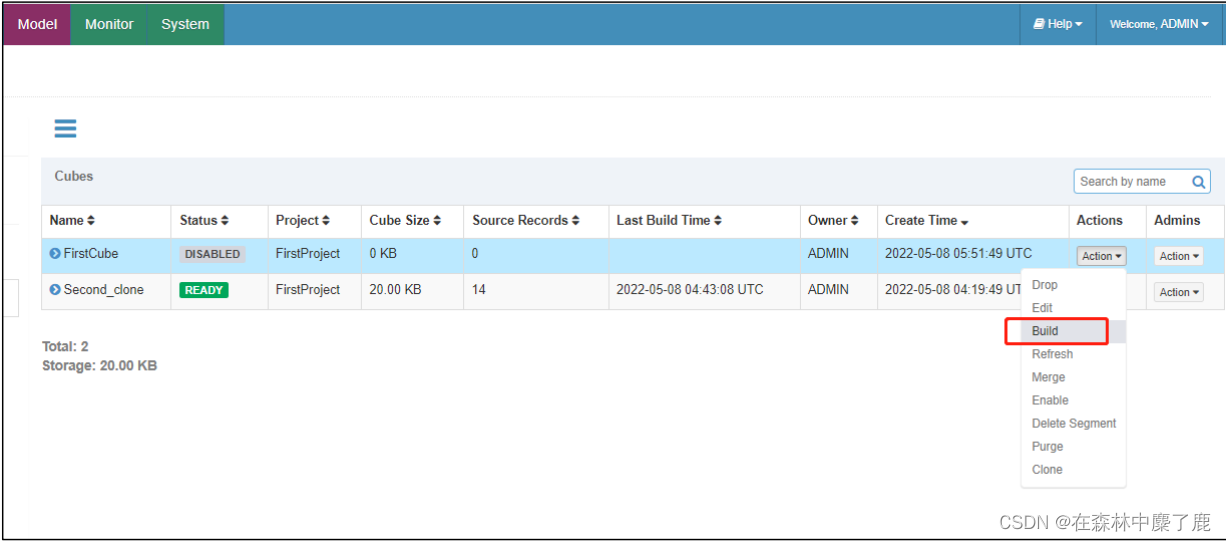
当构建 cube 数据时,它会根据这个 shard 按列对 parquet 文件进行重分区。如果没有指定一个 shardby 的列,则对所有列进行重分区。
三、减少小的或不均匀的 parquet 文件
在查询时读取太多小文件或几个太大的文件会导致性能低下,为了避免这个问题,Kylin4.0 在将 cube 数据作为 parquet 文件构建时,会按照一定策略对 parquet 文件进行重分区,以减少小的或不均匀的 parquet 文件。
1. 相关配置
| 参数名 | 默认值 | 说明 |
|---|---|---|
| kylin.storage.columnar.shard-size-mb | 128MB | 有 shardby 列的 parquet 文件最大大小 |
| kylin.storage.columnar.shard-rowcount | 2500000 | 每个 parquet 文件最多包含的行数 |
| kylin.storage.columnar.shardcountdistinct-rowcount | 1000000 | 指定 cuboid 的 bitmap 大小 |
| kylin.storage.columnar.repartitionthreshold-size-mb | 128MB | 每个 parquet 文件的最大大小 |
2. 重分区的检查策略
如果这个 cuboid 有 shardBy 的列:
parquet 文件的平均大小 < 参数’kylin.storage.columnar.repartition-threshold-size-mb’ 值 ,且parquet 文件数量大于 1,这种情况是为了避免小文件太多
parquet 文件的数量 < (parquet 文件的总行数/ 'kylin.storage.columnar.shardrowcount' * 0.75),如果这个 cuboid 有精确去重的度量值(即 count(distinct)),使用’kylin.storage.columnar.shard-countdistinct-rowcount’ 来代替 ‘kylin.storage.columnar.shardrowcount’; 这种情况是为了避免不均匀的文件;如果满足上述条件之一,它将进行重分区,分区的数量是这样计算的:
${fileLengthRepartitionNum} = Math.ceil(${parquet 文件大小 MB} / ${kylin.storage.columnar.shard-size-mb})
${rowCountRepartitionNum}` =`Math.ceil(${parquet 文件总行数} / ${kylin.storage.columnar.shard-rowcount})
- 1
- 2
分区数量=Math.ceil(( ${fileLengthRepartitionNum} + ${ rowCountRepartitionNum } ) / 2)
3. 合理调整参数的方式
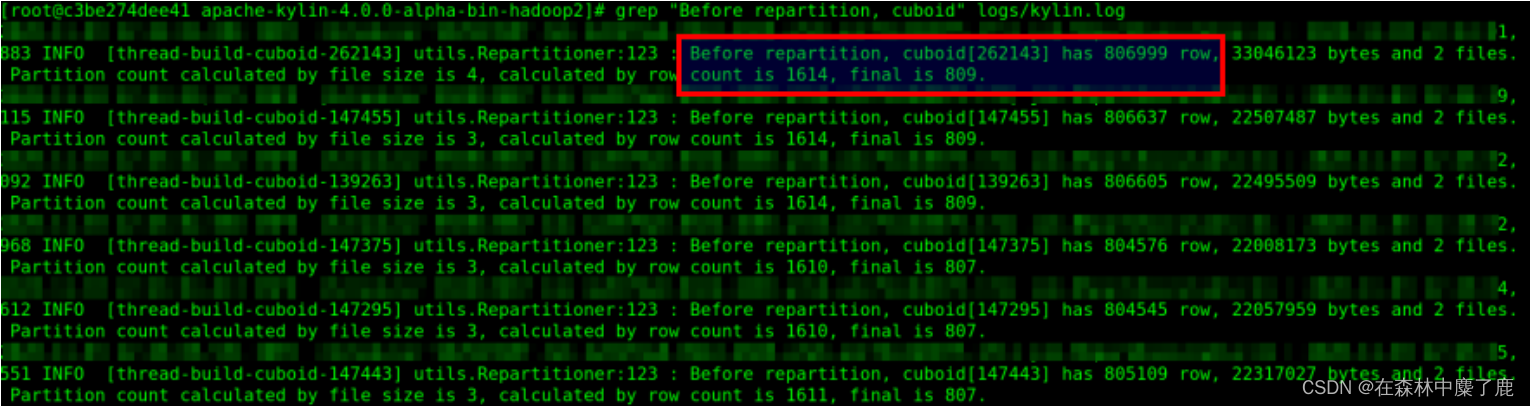
A、查看重分区的信息,可以通过下面命令去 log 中查找
grep "Before repartition, cuboid" logs/kylin.log
- 1
比如官方案例:可以看到分区数有 809 个。
B、增大 ‘kylin.storage.columnar.shard-rowcount’ 或 'kylin.storage.columnar.shard-countdistinctrowcount’的值,重新构建,查看日志:
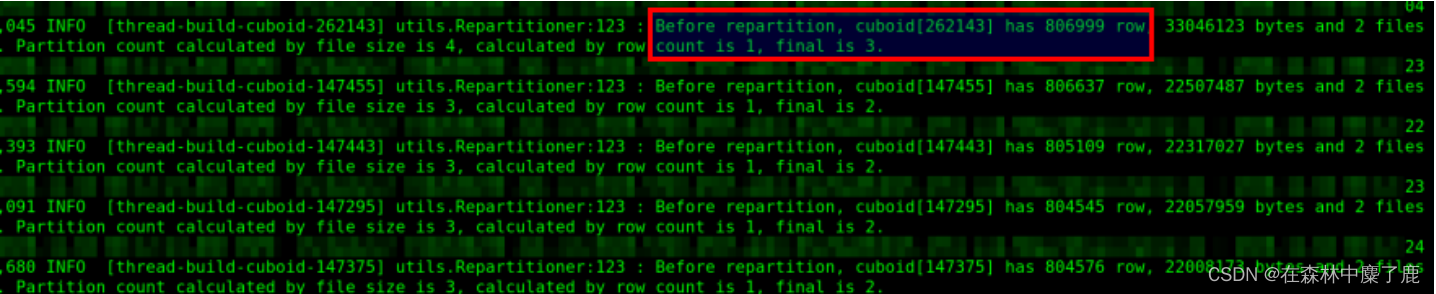

可以看到:分区数变成了 3 个,构建的时间也从 58 分钟降低到 24 分钟。
C、查询性能得到提高
原先查询要 1.7 秒,扫描 58 个文件:
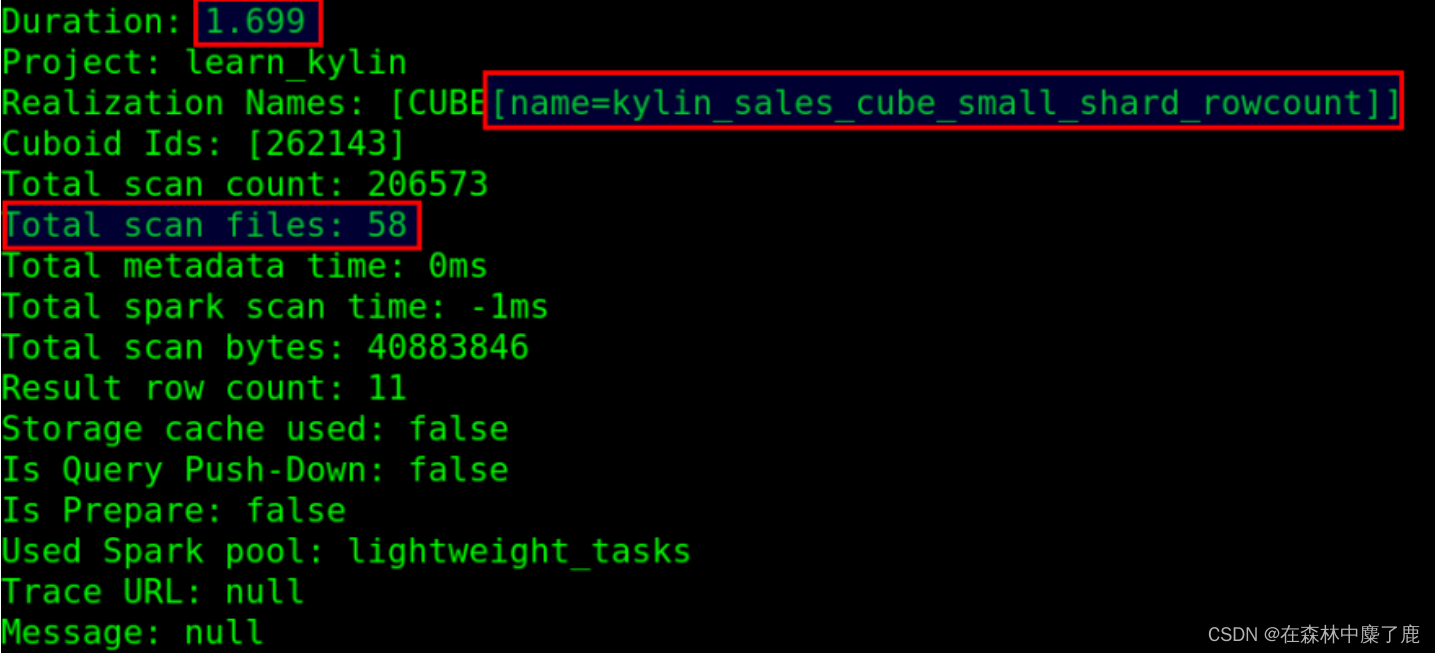
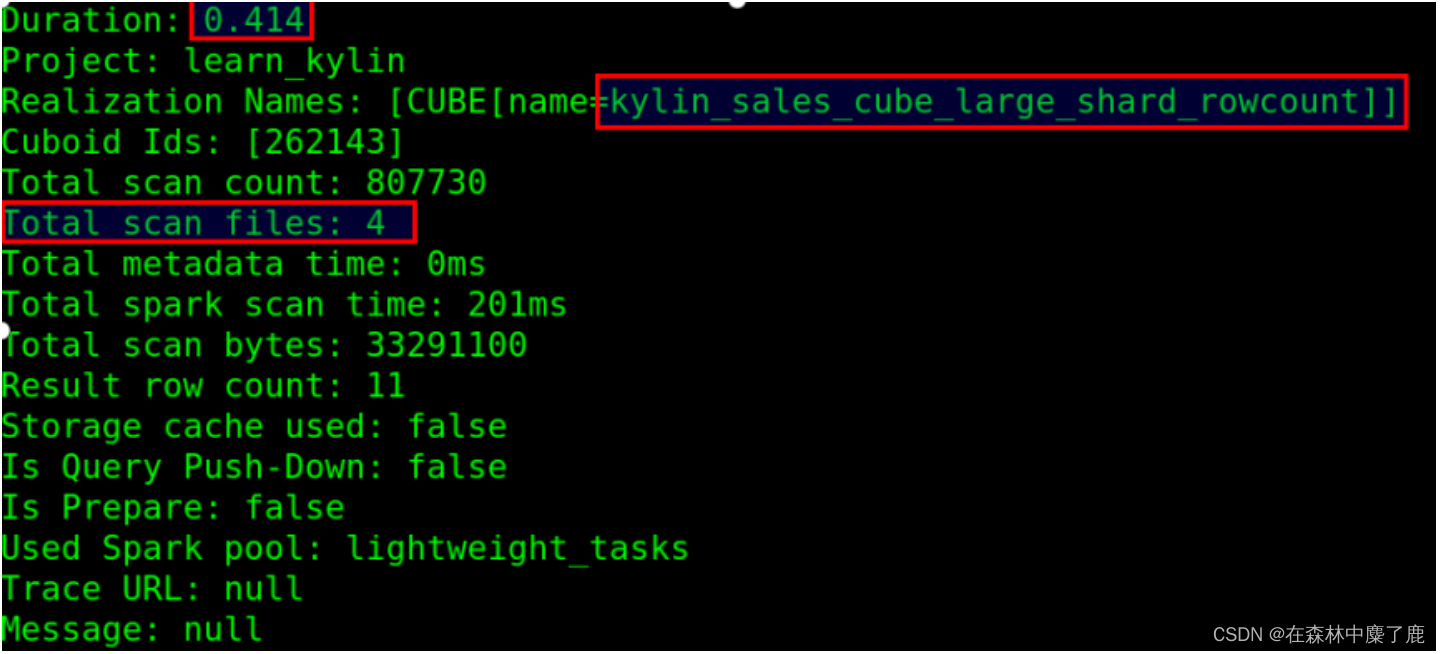
调整参数后,查询只要 0.4 秒,扫描 4 个文件:
四、将多个小文件读取到同一个分区
当已经构建的 segments 中有很多小文件时,可以 修改参数 ‘spark.sql.files.maxPartitionBytes’ (默认值为 128MB) 为合适的值,这样可以让 spark 引擎将一些小文件读取到单个分区中,从而避免需要太多的小任务。
如果有足够的资源,可以减少该参数的值来增加并行度, 但需要同时减少
‘spark.hadoop.parquet.block.size’ (默认值为 128MB) 的值,因为 parquet 文件的最小分割单元是
RowGroup,这个 blocksize 参数表示 parquet 的 RowGroup 的最大大小。
五、使用堆外内存
Spark 可以直接操作堆外内存,减少不必要的内存开销,减少频繁的 GC,提高处理性能。
相关配置:
- spark.memory.offHeap.enabled 设置为 true,使用堆外内存进行 spark shuffle
- spark.memory.offHeap.size 堆外内存的大小

