
- 16-25 数据结构考题 - 折半查找
- 2数据开发|一文讲清楚精益数据方法论在数据治理中的应用
- 3大数据----Hive学习(3)----Hive 基本操作1_三、hive1、创建一个数据库2、显示数据库3、删除有表的数据库4、在上面创建的
- 4ShardingSphere-Proxy分表分库、读写分离基本使用(v5.4.1版本)_shardingsphereproxy5.4.1数据加密
- 5GitHub打不开?试一试开源加速神器_github加速地址
- 6高防服务器的重要性
- 7为什么说Python 是胶水语言?_python 胶水语言 体现
- 8Mac OS Git 安装_mac安装git
- 9git清除凭证
- 10「MySQL」MySQL面试题全解析:常见问题与高级技巧详解_mysql高级面试题
对于领域任务:大语言模型、NLP建模、Agents适用场景探讨
赞
踩

- 来源:FIN AI 探索 大数据文摘
- 本文约2400字,建议阅读5分钟
- 短期内,Agents还是提效为主.

在国内大语言模型领域应用如火如荼,笔者这些日子有几点感受:
更小规模参数模型有可能在特定任务效果更好.
通常当然是模型参数越大效果越好,但具体场景,还是要多个模型测测.所以对领域NLP问题,准备好验证测试集尤为重要.
NLP建模仍然是重要的方案之一
即使大模型越来越强,在实时性、准确性更高的场景,构建特定问题的NLP模型,并用特定数据训练还是不可或缺的方案.就如量化投资中的舆情因子,用大模型当然能做,可要更实时、更准确还是要单独建模.
Agents是最终方案吗?
1月5日有消息称OpenAI即将推出GPT Store用于开发者定制基于ChatGPT不同用途的Agents. 想象下,各行各业都是Agents,以后Agents得到个用户授权就自己找其他Agents去解决问题了.基于长链路问题,大模型并没有有效的方案,笔者认为,短期内,Agents还是提效为主.
接下来是以上观点的相关论述.
一、即使大语言模型是人类知识的概要,也不能独立解决领域问题.
ChatGPT是在构建全部人类知识的概要.博尔赫斯的《通天塔图书馆》,伟大的博尔赫斯具有天才的想象力,在他1941年发表的短篇小说描述这样一个图书馆:
宇宙(别的人把它叫做图书馆)是由一个数目不明确的,也许是无限数的六面体回廊所构成,每一个六面体的每一边墙,排列着书架......所有书籍不论怎么千变万化,都由同样的因素组成,即空格、句号、逗号和二十二个字母。他还引证了所有旅人已经确认的一个事实:在那庞大的图书馆里没有两本书是完全相同的。根据这些不容置疑的前提,他推断说这个图书馆是完全的,它的书架上收藏着二十多个书写符号的(数目尽管很多,却并不是无限的)全部可能实现的组合,或者全部可能表现的一切,包括所有文字可能表现的一切。
在某个六面体的某个书架上(人们都这样认为),一定存在着一本书,它是其他所有一切书的完整缩本或概要。有一个图书馆员看见过它,说它是一个神的类似物。

那本全宇宙知识的概要不正是ChatGPT等大模型的训练想要的结果吗?通天塔可不是一天建成,现在的技术还远达不生成全人类知道的概要.让我们设想下,在通天塔图书馆中找到那本神之书,就不再需要其他书了吗?
如同人生不是轨道,是旷野,所以不需要机器去指唯一明路。
所谓概要就如同统计一样,会抹灭了多样性.就如同有了数据、算法,还需要市场问题一样,市场不只是一个涉及收益、风险、资源有效配置,它也是关于选择、关于未来的解决方案。这也是通天塔图书馆中那本概要神之书也不能完全代替其他书的原因.如米兰·昆德拉说的“向前走,就是不管往哪儿走都行。”笔一划,就此打住,继续讨论行业领域方案.
二、数据+Finetuning的领域大模型还具备通用大模型的优点吗?
理想中的领域大模型是在ChatGPT基础上对领域问题进行数据+Finetuning处理,模型即能有效解决领域问题有具备大模型的通用知识.

Mata公司的研究人员发现,只使用1000个高质量的样本数据进行微调,在没有任何强化学习或人类偏好建模情况下。65B的LLaMA模型表现出非常优异的性能。论文认为模型的知识和能力几乎完全是在预训练期间学习的,而有监督微调(SFT)则教会它在与用户互动时应该使用哪种子分布的格式,少量高质量数据就能达到预期效果。这对我们做大模型应用的人当然是福音,在领域中使用少量高质量数据就可以解决问题。
领域问题,还行怎么行。
通常少量的高质量样本数据Finetuning只能达到更大参数一般性效果,但你想用更多高质量数据优化时就碰到问题了.更多高质量数据Finetuning也很难取得线性的提升. 看到篇论文,Mistral 7B (https://arxiv.org/abs/2310.06825)在各种 benchmark测试中,表现优于更大的同类模型,比如它的表现超过了13B Llama 2 模型。Mistral中使用的The sliding window attention mechanism,它只允许当前标记关注特定数量的前一个Token.但你完全无法确认是否模型性能提升是来自于模型优化,因为很可能和其训练数据强相关.
给人感觉又回到NLP炼丹的时代,对于一个问题,需要找最合适、相关的数据,在基础预训练模型上用个样参数、技巧、模型调优.论文Self-Instruct: Aligning Language Model with Self Generated Instructions就给出了系统性的方案,从 GPT-4 提炼数据,创建一个合成数据集来训练大模型。自然就让人想到借鸡生蛋的方案,基于GPT4等大参数模型,结合生成预训练数据的指令集,生成指令、输入和输出样本,然后对它们进行循环修剪,再用它们来微调自有大模型。这也是很多领域大模型的训练方案.
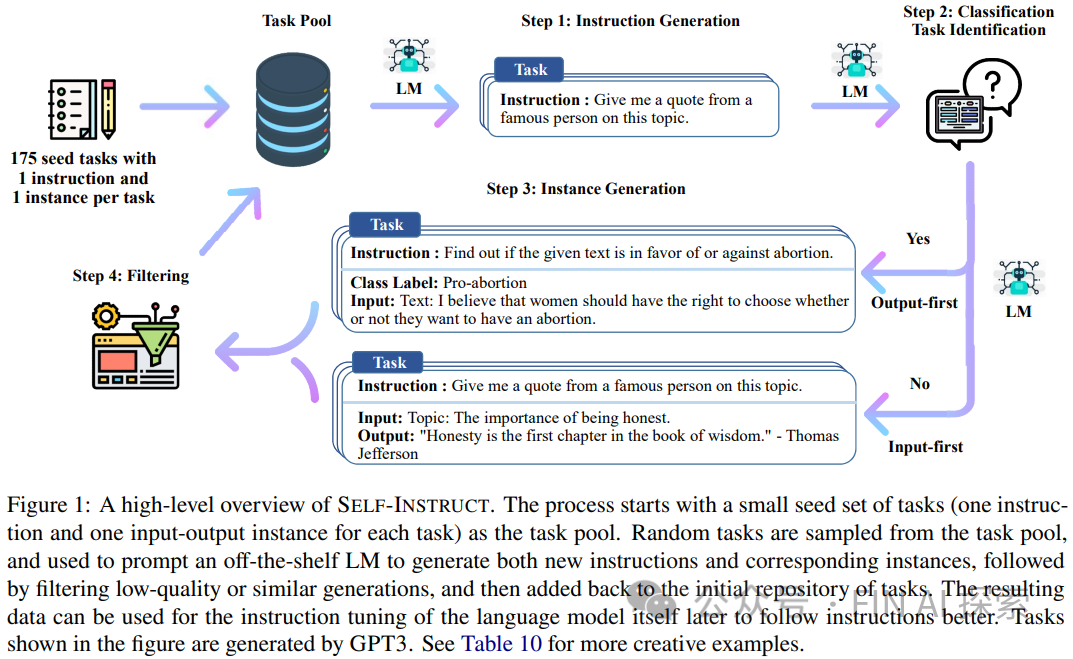
看起来这是自学习的过程.但本来大模型就用生成模型生产数据,这样的数据加工套娃方案的效果上限可想而之.
人类的原典还是你大爷
陈寅恪被誉为三百年学问第一人,一人担任了清华大学历史、中文、哲学三系教授,精通二十多门外语。上课号称“前人讲过的,我不讲;近日讲过的,我不讲;外国人讲过的,我不讲;我自己过去讲过的,我不讲。”他对读书的建议是读原典,“中国真正的原籍经典(原典)也只不过一百多部,其余的书都是在这些书的基础上互为引述参照而已。” 2023年诺贝尔生理学或医学奖得主卡塔林·考里科在访谈中也说:我的爱好之一是阅读经典的科学论文。当我意识到RNA中的尿苷会引爆免疫细胞,导致炎症和干扰素的产生时,我想知道以前是否有人注意到这一点。果不其然,在1963年的一篇论文中发现,从哺乳动物细胞中分离的核糖核酸不会诱导干扰素的产生。

人类原典还是不可替代的作用,不是套娃的机器教机器就能代替. 当然,如果大模型有能力预测一个并不存在的、理想中的、全能的“神”的下一个词,新的原典将诞生?可以想见ChatGPT5也远达不到能猜到全能神的下一个词。
三、Agents领域方案
之前OpenAI Assistant API提供了持久线程和代码解析器,调用第三方函数等功能.将领域流程系统化也能工作.但不够通用智能,期待Agents能有进一步的解决方案.基于Agents的领域方案是重要方向之一,值得期待.
作者简介:
袁峻峰,《人工智能为金融投资带来了什么》作者,复旦大学金融学硕士,FRM金融风险管理师,目前就职于国内某大型券商,本文仅代表个人观点,不可作为投资上的建议。



