
- 1mysql 查询重复数据_mysql查询重复数据
- 2Redis高级面试题汇总
- 3设计模式-迭代器模式
- 4如何快速进阶自动化测试?听听这3位BAT大厂测试工程师的切身感想...._大厂如何做自动化测试
- 5mysql的面试题及答案,一位大龄程序员所经历的面试的历炼和思考,java面试大全笔记
- 6nginx配置备忘录_upstream mgr{}
- 7Eureka注册中心快速入门_eureka http接口
- 8如何设置vscode编辑器代码格式化(settings.json)_vscode代码格式化setting配置
- 9微信小程序封装wx.request接口(两种方式)_wx.request({
- 10VMware虚拟机安装(非常详细)从零基础入门到精通,看完这一篇就够了_vmware虚拟机安装教程(1)
leetcode-二叉搜索树_建立 二叉搜索树 leetcode
赞
踩
99-恢复二叉搜索树
给你二叉搜索树的根节点 root ,该树中的 恰好 两个节点的值被错误地交换。请在不改变其结构的情况下,恢复这棵树 。

方法一:显式中序遍历
我们需要考虑两个节点被错误地交换后对原二叉搜索树造成了什么影响。对于二叉搜索树,我们知道如果对其进行中序遍历,得到的值序列是递增有序的,而如果我们错误地交换了两个节点,等价于在这个值序列中交换了两个值,破坏了值序列的递增性。
我们来看下如果在一个递增的序列中交换两个值会造成什么影响。假设有一个递增序列 a=[1,2,3,4,5,6,7]。如果我们交换两个不相邻的数字,例如 2和 6,原序列变成了 a=[1,6,3,4,5,2,7],那么显然序列中有两个位置不满足 ai <ai+1,在这个序列中体现为 6>3,5>2,因此只要我们找到这两个位置,即可找到被错误交换的两个节点。如果我们交换两个相邻的数字,例如 2 和 3,此时交换后的序列只有一个位置不满足 ai<ai+1
。因此整个值序列中不满足条件的位置或者有两个,或者有一个。
至此,解题方法已经呼之欲出了:
找到二叉搜索树中序遍历得到值序列的不满足条件的位置。
- 如果有两个,我们记为 i 和 j(i<j 且ai >ai+1&& aj>aj+1),那么对应被错误交换的节点即为 ai对应的节点和aj+1对应的节点,我们分别记为x 和 y。
- 如果有一个,我们记为 i,那么对应被错误交换的节点即为ai对应的节点和ai+1对应的节点,我们分别记为 x 和 y。
交换 x 和 y 两个节点即可。
实现部分,本方法开辟一个新数组nums 来记录中序遍历得到的值序列,然后线性遍历找到两个位置 i 和 j,并重新遍历原二叉搜索树修改对应节点的值完成修复,具体实现可以看下面的代码。
class Solution { public: void recoverTree(TreeNode* root) { vector< TreeNode*>vec; // TreeNode*node=root; int index1=0,index2=0; inorderHelper(vec,root); int i=0; for(;i<vec.size()-1;++i) { if(vec[i]->val>vec[i+1]->val) { index1=i; break; } } for(i++;i<vec.size()-1;++i) { if(vec[i]->val>vec[i+1]->val) index2=i+1; } if(index2==0) swap(vec[index1]->val,vec[index1+1]->val); else swap(vec[index2]->val,vec[index1]->val); } void inorderHelper(vector<TreeNode*>&vec,TreeNode*root) { if(root==nullptr)return; inorderHelper(vec,root->left); vec.emplace_back(root); inorderHelper(vec,root->right); } };

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 时间复杂度:O(n)
- 空间复杂度:O(n)
方法二:隐式中序遍历
方法一是显式地将中序遍历的值序列保存在一个数组中,然后再去寻找被错误交换的节点,但我们也可以隐式地在中序遍历的过程就找到被错误交换的节点 x 和 y。
具体来说,由于我们只关心中序遍历的值序列中每个相邻的位置的大小关系是否满足条件,且错误交换后最多两个位置不满足条件,因此在中序遍历的过程我们只需要维护当前中序遍历到的最后一个节点pred,然后在遍历到下一个节点的时候,看两个节点的值是否满足前者小于后者即可,如果不满足说明找到了一个交换的节点,且在找到两次以后就可以终止遍历。
这样我们就可以在中序遍历中直接找到被错误交换的两个节点 x 和 y,不用显式建立 nums 数组。
中序遍历的实现有迭代和递归两种等价的写法,在本方法中提供迭代实现的写法。使用迭代实现中序遍历需要手动维护栈。
class Solution { public: void recoverTree(TreeNode* root) { stack<TreeNode*> stk; TreeNode* x = nullptr; TreeNode* y = nullptr; TreeNode* pred = nullptr; while (!stk.empty() || root != nullptr) { while (root != nullptr) { stk.push(root); root = root->left; } root = stk.top(); stk.pop(); if (pred != nullptr && root->val < pred->val) { y = root; if (x == nullptr) { x = pred; } else break; } pred = root; root = root->right; } swap(x->val, y->val); } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 时间复杂度:最坏情况下(即待交换节点为二叉搜索树最右侧的叶子节点)我们需要遍历整棵树,时间复杂度为O(N),其中 N 为二叉搜索树的节点个数。
- 空间复杂度:O(H),其中 H 为二叉搜索树的高度。中序遍历的时候栈的深度取决于二叉搜索树的高度。
方法三:Morris中序遍历
class Solution { public: void recoverTree(TreeNode* root) { TreeNode *x = nullptr, *y = nullptr, *pred = nullptr, *predecessor = nullptr; while (root != nullptr) { if (root->left != nullptr) { // predecessor 节点就是当前 root 节点向左走一步,然后一直向右走至无法走为止 predecessor = root->left; while (predecessor->right != nullptr && predecessor->right != root) { predecessor = predecessor->right; } // 让 predecessor 的右指针指向 root,继续遍历左子树 if (predecessor->right == nullptr) { predecessor->right = root; root = root->left; } // 说明左子树已经访问完了,我们需要断开链接 else { if (pred != nullptr && root->val < pred->val) { y = root; if (x == nullptr) { x = pred; } } pred = root; predecessor->right = nullptr; root = root->right; } } // 如果没有左孩子,则直接访问右孩子 else { if (pred != nullptr && root->val < pred->val) { y = root; if (x == nullptr) { x = pred; } } pred = root; root = root->right; } } swap(x->val, y->val); } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 时间复杂度:O(N),其中 N 为二叉搜索树的高度。Morris 遍历中每个节点会被访问两次,因此总时间复杂度为 O(2N)=O(N)。
- 空间复杂度:O(1)。
285-二叉搜索树中的中序后继
给定一棵二叉搜索树和其中的一个节点 p ,找到该节点在树中的中序后继。如果节点没有中序后继,请返回 null 。
节点 p 的后继是值比 p.val 大的节点中键值最小的节点,即按中序遍历的顺序节点 p 的下一个节点。
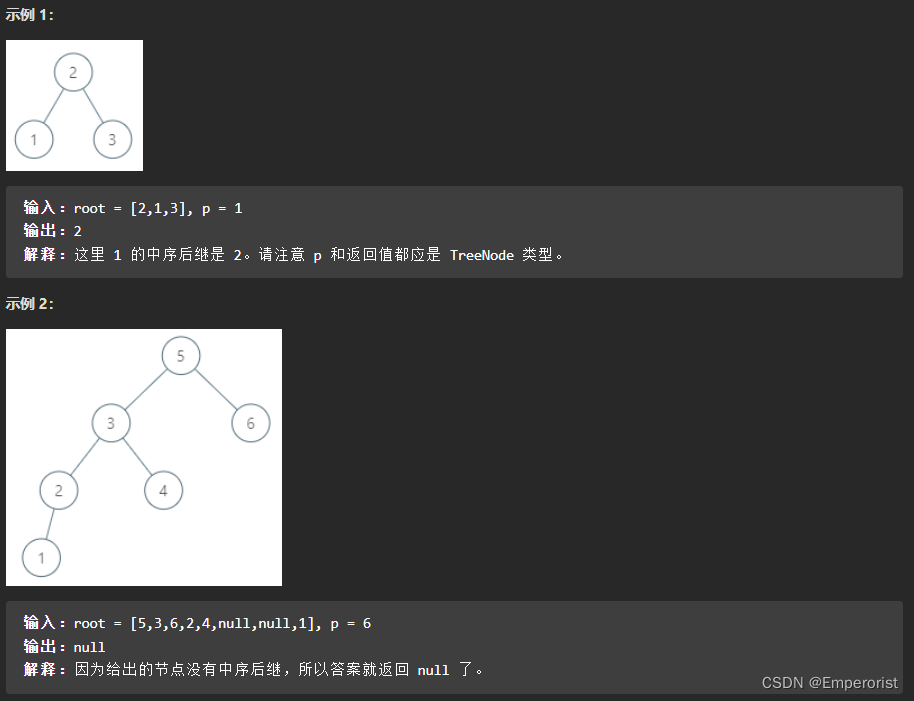
方法一:中序遍历
为了找到二叉搜索树中的节点 p 的中序后继,最直观的方法是中序遍历。由于只需要找到节点 p 的中序后继,因此不需要维护完整的中序遍历序列,只需要在中序遍历的过程中维护上一个访问的节点和当前访问的节点。如果上一个访问的节点是节点 p,则当前访问的节点即为节点 p 的中序后继。
class Solution { public: TreeNode* inorderSuccessor(TreeNode* root, TreeNode* p) { stack<TreeNode*> st; TreeNode *prev = nullptr, *curr = root; while (!st.empty() || curr != nullptr) { while (curr != nullptr) { st.emplace(curr); curr = curr->left; } curr = st.top(); st.pop(); if (prev == p) { return curr; } prev = curr; curr = curr->right; } return nullptr; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
class Solution:
def inorderSuccessor(self, root: 'TreeNode', p: 'TreeNode') -> 'TreeNode':
st, pre, cur = [], None, root
while st or cur:
while cur:
st.append(cur)
cur = cur.left
cur = st.pop()
if pre == p:
return cur
pre = cur
cur = cur.right
return None
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 时间复杂度:O(n),其中 n 是二叉搜索树的节点数。中序遍历最多需要访问二叉搜索树中的每个节点一次。
- 空间复杂度:O(n),其中 n 是二叉搜索树的节点数。空间复杂度取决于栈深度,平均情况是 O(logn),最坏情况是 O(n)。
方法二:利用二叉搜索树的性质
二叉搜索树的一个性质是中序遍历序列单调递增,因此二叉搜索树中的节点 p 的中序后继满足以下条件:
中序后继的节点值大于 p 的节点值;
中序后继是节点值大于 p 的节点值的所有节点中节点值最小的一个节点。
利用二叉搜索树的性质,可以在不做中序遍历的情况下找到节点 p 的中序后继。
如果节点 p 的右子树不为空,则节点 p 的中序后继在其右子树中,在其右子树中定位到最左边的节点,即为节点 p 的中序后继。
如果节点 p 的右子树为空,则需要从根节点开始遍历寻找节点 p 的祖先节点。
将答案初始化为null。用 node 表示遍历到的节点,初始时node=root。每次比较 node 的节点值和 p 的节点值,执行相应操作:
如果 node 的节点值大于 p 的节点值,则 p 的中序后继可能是 node 或者在 node 的左子树中,因此用node 更新答案,并将node 移动到其左子节点继续遍历;
如果node 的节点值小于或等于 p 的节点值,则 p 的中序后继可能在 node 的右子树中,因此将 node 移动到其右子节点继续遍历。
由于在遍历过程中,当且仅当node 的节点值大于 p 的节点值的情况下,才会用 node 更新答案,因此当节点 p 有中序后继时一定可以找到中序后继,当节点 p 没有中序后继时答案一定为null。
class Solution { public: TreeNode* inorderSuccessor(TreeNode* root, TreeNode* p) { TreeNode *successor = nullptr; if (p->right != nullptr) { successor = p->right; while (successor->left != nullptr) { successor = successor->left; } return successor; } TreeNode *node = root; while (node != nullptr) { if (node->val > p->val) { successor = node; node = node->left; } else { node = node->right; } } return successor; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
class Solution: def inorderSuccessor(self, root: 'TreeNode', p: 'TreeNode') -> 'TreeNode': successor = None if p.right: successor = p.right while successor.left: successor = successor.left return successor node = root while node: if node.val > p.val: successor = node node = node.left else: node = node.right return successor
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 时间复杂度:O(n),其中 n 是二叉搜索树的节点数。遍历的节点数不超过二叉搜索树的高度,平均情况是 O(logn),最坏情况是 O(n)。
- 空间复杂度:O(1)。
108-将有序数组转换为二叉搜索树
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。
如果数组长度是奇数,则根节点的选择是唯一的,如果数组长度是偶数,则可以选择中间位置左边的数组作为根节点,或者选择中间位置右边的数字作为根节点,选择不同的数字作为根节点则创建的平衡二叉树也是不同的。
方法一:中序遍历,总是选择中间位置左边的数字作为根节点
选择中间位置左边的数字作为根节点,则根节点的下标为mid=(left+right)/2,此处的除法为整数除法。
class Solution { public: TreeNode* sortedArrayToBST(vector<int>& nums) { int n=nums.size(); return sortedArrayToBSTCore(nums,0,n-1); } TreeNode* sortedArrayToBSTCore(vector<int>&nums,int left,int right) { if(left>right) return nullptr; int mid=(left+right)/2; //选择中间位置左边的数字作为根节点,右边位置:mid=(left+right+1)/2,随机位置:mid=(left+right+rand()%2)/2 TreeNode *root=new TreeNode(nums[mid]); root->left=sortedArrayToBSTCore(nums,left,mid-1); root->right=sortedArrayToBSTCore(nums,mid+1,right); return root; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 时间复杂度:O(n)
- 空间复杂度:O(logn),递归栈的深度是O(logn)。
230-二叉搜索树的第K小的元素
给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 个最小元素(从 1 开始计数)。

方法一:中序遍历(迭代)
二叉搜索树具有如下性质:
结点的左子树只包含小于当前结点的数。
结点的右子树只包含大于当前结点的数。
所有左子树和右子树自身必须也是二叉搜索树。
二叉树的中序遍历即按照访问左子树——根结点——右子树的方式遍历二叉树;在访问其左子树和右子树时,我们也按照同样的方式遍历;直到遍历完整棵树。
思路和算法
因为二叉搜索树和中序遍历的性质,所以二叉搜索树的中序遍历是按照键增加的顺序进行的。于是,我们可以通过中序遍历找到第 k 个最小元素。
具体地,我们使用迭代方法,这样可以在找到答案后停止,不需要遍历整棵树。
class Solution { public: int kthSmallest(TreeNode* root, int k) { stack<TreeNode *> stack; while (root != nullptr || stack.size() > 0) { while (root != nullptr) { stack.push(root); root = root->left; } root = stack.top(); stack.pop(); --k; if (k == 0) { break; } root = root->right; } return root->val; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
class Solution:
def kthSmallest(self, root: Optional[TreeNode], k: int) -> int:
stack=[]
while root or stack:
while root:
stack.append(root)
root=root.left
root=stack.pop()
k-=1
if k==0:
return root.val
root=root.right
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 时间复杂度:O(H+k),其中 H 是树的高度。在开始遍历之前,我们需要 O(H) 到达叶结点。当树是平衡树时,时间复杂度取得最小值 O(logN+k);当树是线性树(树中每个结点都只有一个子结点或没有子结点)时,时间复杂度取得最大值 O(N+k)。
- 空间复杂度:O(H),栈中最多需要存储 H 个元素。当树是平衡树时,空间复杂度取得最小值 O(logN);当树是线性树时,空间复杂度取得最大值 O(N)。
中序遍历(递归)
TreeNode*KthNode(TreeNode*root, int k) { if (root == nullptr || k == 0) return nullptr; return KthNodeCore(root, k); } TreeNode *KthNodeCore(TreeNode*root, int &k) { TreeNode *target = nullptr; if (root->left != nullptr) target = KthNodeCore(root->left, k); if (target == nullptr) { if (k == 1) target = root; k--; } if (target == nullptr&&root->right != nullptr) target = KthNodeCore(root->right, k); return target; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 时间复杂度:O(N),遇到第K大节点不会提前结束,递归会执行完成
- 空间复杂度:O(N)
方法二:记录子树的结点数
在方法一中,我们之所以需要中序遍历前 k 个元素,是因为我们不知道子树的结点数量,不得不通过遍历子树的方式来获知。
因此,我们可以记录下以每个结点为根结点的子树的结点数,并在查找第 k 小的值时,使用如下方法搜索:
- 令 node 等于根结点,开始搜索。
- 对当前结点 node 进行如下操作:
如果 node 的左子树的结点数left 小于 k−1,则第 k小的元素一定在node 的右子树中,令 node 等于其的右子结点,k 等于k−left−1,并继续搜索;
如果 node 的左子树的结点数left 等于 k−1,则第 k 小的元素即为 node ,结束搜索并返回node 即可;
如果 node 的左子树的结点数 left大于 k−1,则第 k 小的元素一定在node 的左子树中,令 node等于其左子结点,并继续搜索。
在实现中,我们既可以将以每个结点为根结点的子树的结点数存储在结点中,也可以将其记录在哈希表中。
class MyBst { public: MyBst(TreeNode *root) { this->root = root; countNodeNum(root); } // 返回二叉搜索树中第k小的元素 int kthSmallest(int k) { TreeNode *node = root; while (node != nullptr) { int left = getNodeNum(node->left); if (left < k - 1) { node = node->right; k -= left + 1; } else if (left == k - 1) { break; } else { node = node->left; } } return node->val; } private: TreeNode *root; unordered_map<TreeNode *, int> nodeNum; // 统计以node为根结点的子树的结点数 int countNodeNum(TreeNode * node) { if (node == nullptr) { return 0; } nodeNum[node] = 1 + countNodeNum(node->left) + countNodeNum(node->right); return nodeNum[node]; } // 获取以node为根结点的子树的结点数 int getNodeNum(TreeNode * node) { if (node != nullptr && nodeNum.count(node)) { return nodeNum[node]; }else{ return 0; } } }; class Solution { public: int kthSmallest(TreeNode* root, int k) { MyBst bst(root); return bst.kthSmallest(k); } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
class MyBst: def __init__(self, root: TreeNode): self.root = root # 统计以每个结点为根结点的子树的结点数,并存储在哈希表中 self._node_num = {} self._count_node_num(root) def kth_smallest(self, k: int): """返回二叉搜索树中第k小的元素""" node = self.root while node: left = self._get_node_num(node.left) if left < k - 1: node = node.right k -= left + 1 elif left == k - 1: return node.val else: node = node.left def _count_node_num(self, node) -> int: """统计以node为根结点的子树的结点数""" if not node: return 0 self._node_num[node] = 1 + self._count_node_num(node.left) + self._count_node_num(node.right) return self._node_num[node] def _get_node_num(self, node) -> int: """获取以node为根结点的子树的结点数""" return self._node_num[node] if node is not None else 0 class Solution: def kthSmallest(self, root: TreeNode, k: int) -> int: bst = MyBst(root) return bst.kth_smallest(k)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 时间复杂度:预处理的时间复杂度为 O(N),其中 N 是树中结点的总数;我们需要遍历树中所有结点来统计以每个结点为根结点的子树的结点数。搜索的时间复杂度为 O(H),其中 H 是树的高度;当树是平衡树时,时间复杂度取得最小值 O(logN);当树是线性树时,时间复杂度取得最大值 O(N)
- 空间复杂度:O(N),用于存储以每个结点为根结点的子树的结点数。
方法三:平衡二叉搜索树
预备知识
方法三需要先掌握 平衡二叉搜索树(AVL树) 的知识。平衡二叉搜索树具有如下性质:
平衡二叉搜索树中每个结点的左子树和右子树的高度最多相差 1;
平衡二叉搜索树的子树也是平衡二叉搜索树;
一棵存有 nn 个结点的平衡二叉搜索树的高度是 O(logn)。
思路和算法
我们注意到在方法二中搜索二叉搜索树的时间复杂度为 O(H),其中 H 是树的高度;当树是平衡树时,时间复杂度取得最小值O(logN)。因此,我们在记录子树的结点数的基础上,将二叉搜索树转换为平衡二叉搜索树,并在插入和删除操作中维护它的平衡状态。
其中,将二叉搜索树转换为平衡二叉搜索树,可以参考「1382. 将二叉搜索树变平衡的官方题解」。在插入和删除操作中维护平衡状态相对复杂,读者可以阅读下面的代码和注释,理解如何通过旋转和重组实现它。
// 平衡二叉搜索树结点 struct Node { int val; Node * parent; Node * left; Node * right; int size; int height; Node(int val) { this->val = val; this->parent = nullptr; this->left = nullptr; this->right = nullptr; this->height = 0; // 结点高度:以node为根节点的子树的高度(高度定义:叶结点的高度是0) this->size = 1; // 结点元素数:以node为根节点的子树的节点总数 } Node(int val, Node * parent) { this->val = val; this->parent = parent; this->left = nullptr; this->right = nullptr; this->height = 0; // 结点高度:以node为根节点的子树的高度(高度定义:叶结点的高度是0) this->size = 1; // 结点元素数:以node为根节点的子树的节点总数 } Node(int val, Node * parent, Node * left, Node * right) { this->val = val; this->parent = parent; this->left = left; this->right = right; this->height = 0; // 结点高度:以node为根节点的子树的高度(高度定义:叶结点的高度是0) this->size = 1; // 结点元素数:以node为根节点的子树的节点总数 } }; // 平衡二叉搜索树(AVL树):允许重复值 class AVL { public: AVL(vector<int> & vals) { if (!vals.empty()) { root = build(vals, 0, vals.size() - 1, nullptr); } } // 根据vals[l:r]构造平衡二叉搜索树 -> 返回根结点 Node * build(vector<int> & vals, int l, int r, Node * parent) { int m = (l + r) >> 1; Node * node = new Node(vals[m], parent); if (l <= m - 1) { node->left = build(vals, l, m - 1, node); } if (m + 1 <= r) { node->right = build(vals, m + 1, r, node); } recompute(node); return node; } // 返回二叉搜索树中第k小的元素 int kthSmallest(int k) { Node * node = root; while (node != nullptr) { int left = getSize(node->left); if (left < k - 1) { node = node->right; k -= left + 1; } else if (left == k - 1) { break; } else { node = node->left; } } return node->val; } void insert(int v) { if (root == nullptr) { root = new Node(v); } else { // 计算新结点的添加位置 Node * node = subtreeSearch(root, v); bool isAddLeft = v <= node->val; // 是否将新结点添加到node的左子结点 if (node->val == v) { // 如果值为v的结点已存在 if (node->left != nullptr) { // 值为v的结点存在左子结点,则添加到其左子树的最右侧 node = subtreeLast(node->left); isAddLeft = false; } else { // 值为v的结点不存在左子结点,则添加到其左子结点 isAddLeft = true; } } // 添加新结点 Node * leaf = new Node(v, node); if (isAddLeft) { node->left = leaf; } else { node->right = leaf; } rebalance(leaf); } } // 删除值为v的结点 -> 返回是否成功删除结点 bool Delete(int v) { if (root == nullptr) { return false; } Node * node = subtreeSearch(root, v); if (node->val != v) { // 没有找到需要删除的结点 return false; } // 处理当前结点既有左子树也有右子树的情况 // 若左子树比右子树高度低,则将当前结点替换为右子树最左侧的结点,并移除右子树最左侧的结点 // 若右子树比左子树高度低,则将当前结点替换为左子树最右侧的结点,并移除左子树最右侧的结点 if (node->left != nullptr && node->right != nullptr) { Node * replacement = nullptr; if (node->left->height <= node->right->height) { replacement = subtreeFirst(node->right); } else { replacement = subtreeLast(node->left); } node->val = replacement->val; node = replacement; } Node * parent = node->parent; Delete(node); rebalance(parent); return true; } private: Node * root; // 删除结点p并用它的子结点代替它,结点p至多只能有1个子结点 void Delete(Node * node) { if (node->left != nullptr && node->right != nullptr) { return; // throw new Exception("Node has two children"); } Node * child = node->left != nullptr ? node->left : node->right; if (child != nullptr) { child->parent = node->parent; } if (node == root) { root = child; } else { Node * parent = node->parent; if (node == parent->left) { parent->left = child; } else { parent->right = child; } } node->parent = node; } // 在以node为根结点的子树中搜索值为v的结点,如果没有值为v的结点,则返回值为v的结点应该在的位置的父结点 Node * subtreeSearch(Node * node, int v) { if (node->val < v && node->right != nullptr) { return subtreeSearch(node->right, v); } else if (node->val > v && node->left != nullptr) { return subtreeSearch(node->left, v); } else { return node; } } // 重新计算node结点的高度和元素数 void recompute(Node * node) { node->height = 1 + max(getHeight(node->left), getHeight(node->right)); node->size = 1 + getSize(node->left) + getSize(node->right); } // 从node结点开始(含node结点)逐个向上重新平衡二叉树,并更新结点高度和元素数 void rebalance(Node * node) { while (node != nullptr) { int oldHeight = node->height, oldSize = node->size; if (!isBalanced(node)) { node = restructure(tallGrandchild(node)); recompute(node->left); recompute(node->right); } recompute(node); if (node->height == oldHeight && node->size == oldSize) { node = nullptr; // 如果结点高度和元素数都没有变化则不需要再继续向上调整 } else { node = node->parent; } } } // 判断node结点是否平衡 bool isBalanced(Node * node) { return abs(getHeight(node->left) - getHeight(node->right)) <= 1; } // 获取node结点更高的子树 Node * tallChild(Node * node) { if (getHeight(node->left) > getHeight(node->right)) { return node->left; } else { return node->right; } } // 获取node结点更高的子树中的更高的子树 Node * tallGrandchild(Node * node) { Node * child = tallChild(node); return tallChild(child); } // 重新连接父结点和子结点(子结点允许为空) static void relink(Node * parent, Node * child, bool isLeft) { if (isLeft) { parent->left = child; } else { parent->right = child; } if (child != nullptr) { child->parent = parent; } } // 旋转操作 void rotate(Node * node) { Node * parent = node->parent; Node * grandparent = parent->parent; if (grandparent == nullptr) { root = node; node->parent = nullptr; } else { relink(grandparent, node, parent == grandparent->left); } if (node == parent->left) { relink(parent, node->right, true); relink(node, parent, false); } else { relink(parent, node->left, false); relink(node, parent, true); } } // trinode操作 Node * restructure(Node * node) { Node * parent = node->parent; Node * grandparent = parent->parent; if ((node == parent->right) == (parent == grandparent->right)) { // 处理需要一次旋转的情况 rotate(parent); return parent; } else { // 处理需要两次旋转的情况:第1次旋转后即成为需要一次旋转的情况 rotate(node); rotate(node); return node; } } // 返回以node为根结点的子树的第1个元素 static Node * subtreeFirst(Node * node) { while (node->left != nullptr) { node = node->left; } return node; } // 返回以node为根结点的子树的最后1个元素 static Node * subtreeLast(Node * node) { while (node->right != nullptr) { node = node->right; } return node; } // 获取以node为根结点的子树的高度 static int getHeight(Node * node) { return node != nullptr ? node->height : 0; } // 获取以node为根结点的子树的结点数 static int getSize(Node * node) { return node != nullptr ? node->size : 0; } }; class Solution { public: int kthSmallest(TreeNode * root, int k) { // 中序遍历生成数值列表 vector<int> inorderList; inorder(root, inorderList); // 构造平衡二叉搜索树 AVL avl(inorderList); // 模拟1000次插入和删除操作 vector<int> randomNums(1000); std::random_device rd; for (int i = 0; i < 1000; ++i) { randomNums[i] = rd()%(10001); avl.insert(randomNums[i]); } shuffle(randomNums); // 列表乱序 for (int i = 0; i < 1000; ++i) { avl.Delete(randomNums[i]); } return avl.kthSmallest(k); } private: void inorder(TreeNode * node, vector<int> & inorderList) { if (node->left != nullptr) { inorder(node->left, inorderList); } inorderList.push_back(node->val); if (node->right != nullptr) { inorder(node->right, inorderList); } } void shuffle(vector<int> & arr) { std::random_device rd; int length = arr.size(); for (int i = 0; i < length; i++) { int randIndex = rd()%length; swap(arr[i],arr[randIndex]); } } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 时间复杂度:预处理的时间复杂度为 O(N),其中 N是树中结点的总数。插入、删除和搜索的时间复杂度均为O(logN)。
- 空间复杂度:O(N),用于存储平衡二叉搜索树。
538- 把二叉搜索树转换为累加树
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
提醒一下,二叉搜索树满足下列约束条件:
节点的左子树仅包含键 小于 节点键的节点。
节点的右子树仅包含键 大于 节点键的节点。
左右子树也必须是二叉搜索树。

方法一:反向递归中序遍历
二叉搜索树是一棵空树,或者是具有下列性质的二叉树:
若它的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
若它的右子树不空,则右子树上所有节点的值均大于它的根节点的值;
它的左、右子树也分别为二叉搜索树。
由这样的性质我们可以发现,二叉搜索树的中序遍历是一个单调递增的有序序列。如果我们反序地中序遍历该二叉搜索树,即可得到一个单调递减的有序序列。
本题中要求我们将每个节点的值修改为原来的节点值加上所有大于它的节点值之和。这样我们只需要反序中序遍历该二叉搜索树,记录过程中的节点值之和,并不断更新当前遍历到的节点的节点值,即可得到题目要求的累加树。
class Solution {
public:
int sum=0;
TreeNode* convertBST(TreeNode* root) {
if(root==nullptr)
return nullptr;
convertBST(root->right);
sum+=root->val;
root->val=sum;
convertBST(root->left);
return root;
}
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
class Solution:
def convertBST(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
def dfs(root:TreeNode):
nonlocal total
if root:
dfs(root.right)
total+=root.val
root.val=total
dfs(root.left)
total=0
dfs(root)
return root
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 时间复杂度:O(n),其中n是二叉搜索树的节点树,每一个节点恰好被遍历一次
- 空间复杂度:O(n),为递归过程的栈开销,平均情况下为O(logn),最坏情况下树呈现链状,为O(n)
方法二:迭代法
迭代法需要一个变量存储原始根节点,即root1=root
class Solution { public: int sum=0; TreeNode* convertBST(TreeNode* root) { TreeNode *root1=root; stack<TreeNode*> stk; while (root != nullptr || !stk.empty()) { while (root != nullptr) { stk.push(root); root = root->right; } root = stk.top(); stk.pop(); sum+=root->val; root->val=sum; root = root->left; } return root1; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
class Solution: def convertBST(self, root: Optional[TreeNode]) -> Optional[TreeNode]: stk=[] node=root sum=0 while stk or node: while node: stk.append(node) node=node.right node=stk.pop() sum=sum+node.val node.val=sum node=node.left return root
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
复杂度同迭代
Morris中序遍历
相对于从左至右的中序遍历,修改left->right,right->left,即可实现从右向左遍历。再将添加当前节点的值替换为添加累加值。
class Solution { public: int sum=0; TreeNode* convertBST(TreeNode* root) { TreeNode *root1=root; TreeNode *predecessor = nullptr; while (root != nullptr) { if (root->right != nullptr) { // predecessor 节点就是当前 root 节点向左走一步,然后一直向右走至无法走为止 predecessor = root->right; while (predecessor->left != nullptr && predecessor->left != root) { predecessor = predecessor->left; } // 让 predecessor 的右指针指向 root,继续遍历左子树 if (predecessor->left == nullptr) { predecessor->left = root; root = root->right; } // 说明左子树已经访问完了,我们需要断开链接 else { sum+=root->val; root->val=sum; predecessor->left = nullptr; root = root->left; } } // 如果没有左孩子,则直接访问右孩子 else { sum+=root->val; root->val=sum; root = root->left; } } return root1; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
时间复杂度:O(n),其中 n是二叉搜索树的节点数。没有左子树的节点只被访问一次,有左子树的节点被访问两次。
空间复杂度:O(1),只操作已经存在的指针(树的空闲指针),因此只需要常数的额外空间。
96-不同的二叉搜索树
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。

方法一:动态规划
给定一个有序序列 1⋯n,为了构建出一棵二叉搜索树,我们可以遍历每个数字 i,将该数字作为树根,将 1⋯(i−1) 序列作为左子树,将 (i+1)⋯n 序列作为右子树。接着我们可以按照同样的方式递归构建左子树和右子树。
在上述构建的过程中,由于根的值不同,因此我们能保证每棵二叉搜索树是唯一的。
由此可见,原问题可以分解成规模较小的两个子问题,且子问题的解可以复用。因此,我们可以想到使用动态规划来求解本题。
算法
题目要求是计算不同二叉搜索树的个数。为此,我们可以定义两个函数:
- G(n): 长度为 n 的序列能构成的不同二叉搜索树的个数。
- F(i,n): 以 i 为根、序列长度为 n 的不同二叉搜索树个数(1≤i≤n)。
可见,G(n) 是我们求解需要的函数。
稍后我们将看到,G(n) 可以从F(i,n) 得到,而 F(i,n) 又会递归地依赖于G(n)。
首先,根据上一节中的思路,不同的二叉搜索树的总数 G(n),是对遍历所有 i (1≤i≤n) 的 F(i,n) 之和。换言之:
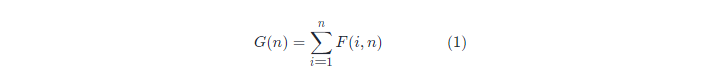
对于边界情况,当序列长度为 1(只有根)或为 0(空树)时,只有一种情况,即:
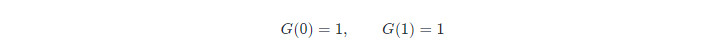
给定序列 1⋯n,我们选择数字 i作为根,则根为 i 的所有二叉搜索树的集合是左子树集合和右子树集合的笛卡尔积,对于笛卡尔积中的每个元素,加上根节点之后形成完整的二叉搜索树,如下图所示:

举例而言,创建以 3 为根、长度为 7 的不同二叉搜索树,整个序列是[1,2,3,4,5,6,7],我们需要从左子序列 [1,2] 构建左子树,从右子序列 [4,5,6,7] 构建右子树,然后将它们组合(即笛卡尔积)。
对于这个例子,不同二叉搜索树的个数为F(3,7)。我们将 [1,2] 构建不同左子树的数量表示为 G(2), 从 [4,5,6,7] 构建不同右子树的数量表示为 G(4),注意到 G(n) 和序列的内容无关,只和序列的长度有关。于是,F(3,7) =G(2)⋅G(4)。 因此,我们可以得到以下公式:
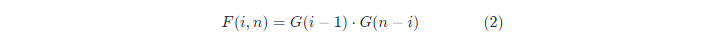
将公式 (1),(2) 结合,可以得到 G(n) 的递归表达式:
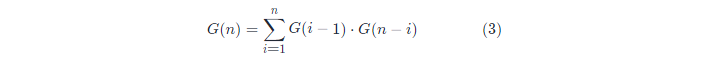
至此,我们从小到大计算 G 函数即可,因为 G(n) 的值依赖于 G(0)⋯G(n−1)。
class Solution { public: int numTrees(int n) { vector<int> G(n + 1, 0); G[0] = 1; G[1] = 1; for (int i = 2; i <= n; ++i) { for (int j = 1; j <= i; ++j) { G[i] += G[j - 1] * G[i - j]; } } return G[n]; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 时间复杂度 : O(n^2) ),其中 n 表示二叉搜索树的节点个数。G(n) 函数一共有 n个值需要求解,每次求解需要 O(n) 的时间复杂度,因此总时间复杂度为 O(n^2)。
- 空间复杂度 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/702991
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

