
- 1Android Studio导入Android系统源码_android studio 导入安卓系统源码
- 2MaxCompute常用函数(ODPS常用函数)_odps函数
- 3【概述】spark(一):spark特点、知识范畴、spark架构、任务提交流程、支持哪些运行环境_spark技术综述
- 4Spark——Partition的分区规则和分区数_spark partition range
- 5Java学习Hutool工具库中的DateUtil工具类_hutool dateutil
- 6芯片全流程培训
- 7机器学习笔记五:广义线性模型(GLM)_广义线性模型建模过程
- 8Faiss(12):python接口faiss.py文件分析_faiss python接口多核
- 9从前序与中序遍历序列构造二叉树_头歌第1关:从先序与中序遍历序列构造二叉树
- 10MCtalk 创业声音丨领跑“手办”题材2年,《高能手办团》如何实现国内出海两开花?
时序问题及混合模型_序列依赖 和时间依赖的区别
赞
踩
时间序列的笔记
本notebook记录在kaggle网站中学习处理时间序列特征相关问题时所遇到的较为重要的方法和代码段
1. Indicators & Fourier
本节介绍的Indicators(周期性)和Fourier(傅里叶特征)用于处理具有周期性的数据。
1.1 Indicators
适用于观测较少的情况,比如每周一次的特征。
因为indicators普遍是one-hot向量,过长的周期无法使用统一的一个值代表周期内的所有向量
| Date | Spring | Summer | Autumn |
|---|---|---|---|
| 2014-1-1 | 0 | 0 | 0 |
| 2014-6-8 | 0 | 1 | 0 |
| 2014-9-8 | 0 | 0 | 1 |
类似上边的例子,因为春夏秋冬只需知道其中三个就可以推出最后一个,所以只需要三维的one-hot向量表示。用n-1维的one-hot向量表示是有利于线性回归模型的。
1.2 Fourier
适用于观测较多的情况,比如每年一次的特征。
indicators指标通常需要先验知识,但还有一类数据,由于其值的连续性,往往很容易通过图像观测到,但无法使用周期性indicators来捕捉周期性。
通常使用傅里叶特征捕捉此类周期特征。
傅里叶特征就是一对正弦和余弦曲线,一维sin(0x) & cos(0x),一维sin(x) & cos(x),二维sin(2x) & cos(2x) …傅里叶对特征建模年度周期性特征的频率可以为:一年一次,一年两次…
- 下面是自定义代码以实现获取傅里叶特征
import numpy as np import pandas as pd def fourier_features(index, freq, order): ''' 根据输入的index和周期freq,返回order阶数的傅里叶特征 :index : 输入的数组,(我们只关心它的长度) :freq : 周期 :order : 阶数 :return : ''' time = np.arange(len (index), dtype = np.float32) k = 2 * np.pi * (1 / freq) * time # 最后求的是 sin(k) = sin(2Πω * x) features = {} for Order in range(1, order + 1): # 建立1,2,3...,order阶傅里叶 features.update({ f'sin_{freq}_{Order}':np.sin(Order * k), f'cos_{freq}_{Order}':np.cos(Order * k) }) return pd.DataFrame(features, index = index) fourier_features(np.arange(1000), 365//4, 4)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
除此之外,还可以使用stasmodels.tsa.deterministic库创建indicators和Fourier特征
2. 自相关
首先引入相关性的概念。
2.1 相关性
相关性是两个随机变量 X i 和 Y j {X_{i}} 和 {Y_{j}} Xi和Yj之间线性关系的强度和方向。
相关系数越接近于 1,表明二者越具有正相关性;越接近 -1,越具有负相关性。
2.1.1 皮尔逊相关系数
计算随即变量之间相关性的函数有很多,其中最常用的便是皮尔逊相关系数。
ρ
X
,
Y
=
c
o
v
(
X
,
Y
)
σ
X
σ
Y
=
E
(
(
X
−
μ
X
)
(
Y
−
μ
Y
)
)
σ
X
σ
Y
\rho_{X, Y} = \frac{cov(X, Y)}{\sigma_{X} \sigma_{Y}} = \frac{E((X - \mu_{X})(Y - \mu_{Y}))}{\sigma_{X} \sigma_{Y}}
ρX,Y=σXσYcov(X,Y)=σXσYE((X−μX)(Y−μY))
2.1.2 平均移动曲线
平均移动曲线一类又称为滚动统计特征。通常使用GBDT算法,如XGBoost算法时,是一个经常被选择的优秀特征。但要注意在作为特征使用时要避免超前,例如将center设置为False,lag设置为1
y_ = y.shift(1)
y_ = y_.rolling(
window = 8,
center = False
).mean()
y_ = y_.dropna()
- 1
- 2
- 3
- 4
- 5
- 6
2.2 自相关 autocorrelation
又称作序列相关(serial correlation),指一个时间序列这些值前后自己相关,也就是 X i − 1 和 X i X_{i-1} 和 X_{i} Xi−1和Xi之间的相关系数。
一个时间序列的自相关系数又叫做自相关函数(ACF)。
在选择**滞后(lag)**作为特征加入特征集时,无需将所有延迟都加进来。因为2位滞后的数据所含的信息往往是1阶滞后信息的衰减信息,所以如果滞后2中没有产生新的信息,我们就没有理由再去添加它了。
2.3 偏相关 partial autocorrelation
所谓滞后k偏自相关系数就是指,在给定中间k-1个随机变量
X
t
−
1
,
X
t
−
2
,
.
.
.
X
t
−
k
+
1
X_{t-1}, X_{t-2},... X_{t-k+1}
Xt−1,Xt−2,...Xt−k+1的条件下,即剔除了中间k-1个随机变量的干扰后,
X
t
−
k
X_{t-k}
Xt−k对
X
t
X_{t}
Xt影响的相关度量。
ρ
X
t
,
X
t
−
k
∣
X
t
−
1
.
.
.
X
t
−
k
+
1
=
E
[
(
X
t
−
E
^
X
t
)
(
X
t
−
k
−
E
^
X
t
−
k
)
]
E
(
X
t
−
k
−
E
^
X
t
−
k
)
2
\rho_{X_{t}, X_{t-k}|X_{t-1}...X_{t-k+1}} = \frac{E[(X_{t} -\hat{E}X_{t})(X_{t-k} - \hat{E}X_{t-k})]}{E(X_{t-k} - \hat{E}X_{t-k})^{2}}
ρXt,Xt−k∣Xt−1...Xt−k+1=E(Xt−k−E^Xt−k)2E[(Xt−E^Xt)(Xt−k−E^Xt−k)]
- 概括地讲:偏相关系数反应本次滞后带来的新的信息的数量。

从上图可以得到的信息有,滞后1-6是有用的,而从滞后7开始,新的增益在置信区间外,可以视为无关特征。至于滞后11所显示出的有用增益,需要认为是假阳性。但要注意的是,并不是所有的间隔着无关特征的滞后(如滞后11)都需要认为是假阳性,有可能当天数据就与12天前的数据相关。
上图称为相关图,本质上就代表着傅里叶特征。因为真实世界中存在着大量的非线性相关数据,所以在采用之后特征之前需要先进行相关图的绘制和观察。
使用df.corr()计算两个数组的相关系数
2.3 平稳性 stationarity
- 指一个时间序列的概率分布不随时间变化的性质。
一般通过差分使数据变得平稳。但是做了差分操作后会丢失部分数据的性质。非平稳的数据不可以直接做回归,例如国家GDP的随机变量X在增长,身高随机变量Y也在增长,但不能说身高的增长导致了GDP的增长,原因就是这两个时间序列都是不平稳的。
2.4 时间依赖性和序列依赖性
时间依赖性指周期性明显的依赖于时间,随时间的变化而呈现出周期性。一般直观理解的具有周期性的数据都是具有时间依赖性的。本节着重介绍序列依赖性
序列依赖性
不同于时间依赖性,尽管序列依赖性也呈现出与时间相关的周期性,但其每个点的实际取值和所在时间段,或者说受时间步长的影响不大,更加直接的反应其周期性的是,某一时刻的值如何依赖前一时刻的值。
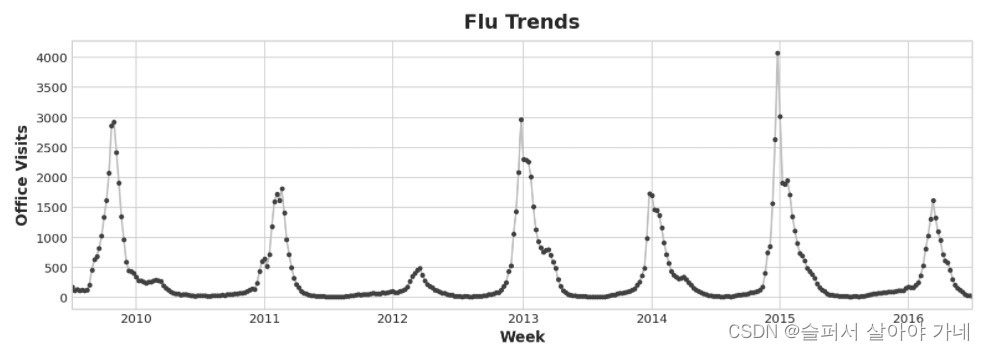
如图所示,流感(上图数据)趋势数据显示的是不规则的周期(区别于没有周期),而非正常的周期性:
- 流感的高峰期往往发生在新年前后, 但有时会提前或滞后
- 有时会更大或更小。
使用滞后特征来对问题建模使得可以根据不断变化的条件做出反应,而不像时间依赖性数据那样被固定在特定时间上。
import pandas as pd
def make_lags(ts, lags):
return pd.concat({
f'y_{lags}_{i}':ts.shift(i)
for i in range(1, lags + 1)
},
axis = 1)
X = make_lags(flu_tends.Fluvists, lags=4)
X = X.fillna(0,0)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
! 待解决的问题
使用滞后特征的模型在预测时,因为需要预测前一天的结果,就不得不使用测试集中的数据。至于如何解决此问题,将在以后作答
2.5 去季节化 Deseasonalize
对一个并没有很好的季节性和趋势的时间序列进行建模时, 趋势和季节性都会在相关图和滞后图中产生序列依赖性。为了去除纯粹的季节性行为,需要首先对数据进行去季节化处理(Deseasonalize)。
去季节化采用的操作通常是使用季节性特征进行预测,然后用原始数据减去预测结果得到去季节化后的数据。
fourier = CalendarFourier(freq = 'M', order = 4) y = pd... dp = DeterministicProcess( constant = True, order = 1, seasonal = True, drop = True, index = y.index, additional_items = [fourier] ) X = dp.in_sample() model = LinearRegression() model.fit(X, y) pred = model.predict(X) y_deseason = y - pred
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3. 混合模型
线性回归可以很好的推断趋势;XGBoost模型可以很好的反应交互,结合二者的优点可以做到更好。
3.1 组件
“趋势,时间依赖和序列依赖” 加上一些不可避免的误差就构成了时间序列的组件。记公式为
s
e
r
i
e
s
=
t
r
e
n
d
+
s
e
a
s
o
n
s
+
c
y
c
l
e
s
+
e
r
r
o
r
s
series = trend + seasons + cycles + errors
series=trend+seasons+cycles+errors
其中每个成员都叫做一个组件(component)
模型的残差是模型训练的目标和模型预测差值。根据特征绘制残差,就可以得到模型从未从特征中了解的信息。
将学习时间序列的组件作为一个迭代的过程。首先学习趋势,减去它的级数,然后学习周期(时间依赖和季节依赖)并减去周期,最后就只剩下那些不可预知的错误。
然后将所有学习到的组件加在一起,就得到了完整的模型。
以上就是线性回归要做的内容
3.2 残差 Residuals
3.1节中使用单一的算法——线性回归一次性学习了所有的组件,但是实际应用上可能对不同组件使用不同模型,为每个组件选择其最好的算法。为此,我们使用一种算法去拟合原始序列,另一种算法去拟合残差序列。
# 使用第一种模型训练原始序列
model1.fit(X_train_1, y_train_1)
y_pred = model1.pred(X_train) # 为了得到残差,这里在训练集上预测
# 使用第二种模型训练残差
model_2.fit(X_train_2, y_train - y_pred_1)
y_pred_2 = model2.pred(X_train_2)
# 最后得到总的预测结果
y_pred = y_pred_1 + y_pred_2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这里X_train_1和X_train_2的维度不同但个数相同。原因是,因为我们希望两次训练模型训练的内容不同,例如采用第一个模型了解趋势,那么第二个模型训练时X_train_2通常不需要趋势特征。
3.3 混合模型
构造混合模型常见的策略是,一个简单的学习算法(通常是线性模型)后跟着一个复杂的、非线性的模型如GBDT或深度神经网络。
3.3.1 回归问题
回归模型通常分为两种预测策略,一种是转换特征,一种是转换目标
-
回归——转换特征 :
特征转换学习算法是学习一些特征函数,将特征作为输入,然后组合和转换他们,以产生符合目标值的输出。常见的有线性回归和神经网络。 -
回归——转换目标 :
目标转换算法是利用特征将targets进行分组,然后通过平均目标值进行预测。一组特征仅仅表明要平均哪个组,代表性的算法有决策树和k邻近。
3.3.2 决策树不能预测趋势
特征转换算法通常可以推断出训练集之外的结果,但是会在一定程度上受限于训练集。
如果给出了一段time dummy,线性回归会在训练集外按照相同的time dummy继续绘制趋势曲线。
但是决策树一类算法只会依据训练集的最后一步推断未来。也就是说决策树类算法不能用于趋势回归,同样的,基于决策树的XGBoost和GBDT算法也不能用于趋势回归问题。
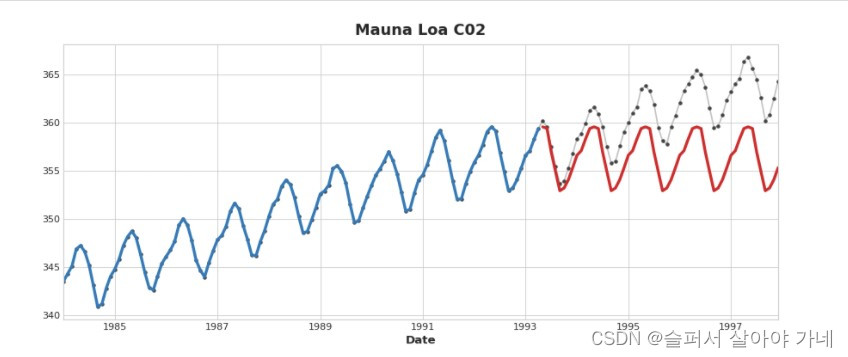
红色曲线是决策树预测的效果
3.3.3 堆叠的混合模型 stacked hybrids
混合模型设计的初衷就是为了弥补决策树的这种缺点。使用线性回归推断趋势,转换目标以消除趋势,然后将XGBoost用于非趋势残差。为了混合一个神经网络,可以将另一个模型的预测作为一个特征。
残差拟合的方法和梯度增强(gradient boosting)算法的方法是一样的,所以称为混合增强算法,使用预测作为特征的方法被称作“叠加”,统称 堆叠的混合模型 stacked hybrids
3.4 大致过程
1. 首先使用线性回归模型了解每个系列的趋势。
- 构建趋势特征
dp = DeterministicProcess(
order = 2,
constant = True,
index = df.index,
drop = True
)
X = dp.in_sample()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
如果想要预测多组数据:线性回归可以实现多输出回归,但XGBoost不能。所以使用XGboost时需要转换为长格式(类别按行索引),然后设置一个标签使XGBoost区分种类
2. 从日期中提取月份(或周)创建季节性特征
3. 把得到的趋势预测结果转换为长格式,然后从原始序列中减去他们。这将得到XGBoost需要的残差序列。
这样一来,XGBoost就弥补了其无法预测长期趋势的缺点。
3.5 常用的混合模型
3.5.1 自定义类
通常采用自定义class为模型。
class BoostedHybrid:
def __init__(self, model_1, model_2):
self.model_1 = model_1
self.model_2 = model_2
self.y_columns = None
- 1
- 2
- 3
- 4
- 5
这样在实例化的时候传入相应的模型,例如model = BoostedHybrid(LinearRegression(), XGBRegression())
3.5.2 向类中添加方法
- 首先添加模型拟合函数
def fit(self, X_1, X_2, y):
'''
:params X_1: 特征向量1,用于第一个模型预测时序特征
:params X_2: 特征向量2,剔除时序特征后的剩余特征向量
:params y: 标签
:return : 在fit方法中,先后fit两个model
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 添加预测函数
def predict(self, X_1, X_2): ''' :params X_1: 带预测的时序特征向量 :params X_2: 提出时序特征的特征向量 :return : 返回预测的结果 ''' y_pred = pd.DataFrame( # 时序模型预测的结果 self.model_1.predict(X_1), index = X_1.index, columns = self.y_columns ) # y_pred = y_pred.stack().squeeze() # 将多个输出目标扩展成长格式 y_pred += self.model_2.predict(X_2) # 无时序特征的结果加上时序模型预测的结果作为最后的预测结果 return y_pred.stack()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 将两个方法加入到model类中
BoostedHybrid.fit= fit
BoostedHybrid.predict= predict
- 1
- 2
3.5.3 常用的趋势预测模型和复杂模型
- 常用的趋势预测模型
ElasticNetFrom linear_modelLassoFrom linear_modelRidgeFrom linear_model
- 常用的复杂模型
ExtraTreesRegressorFrom sklearn.ensembleRandomForestRegressorFrom sklearn.ensembleKNeiborsRegressorFrom sklearn.neighborsMLPRegressorFrom MLPRegressor
形如
myModel = BoostedHybrid(
model_1 = Ridge(),
model_2 = MLPRegressor()
)
- 1
- 2
- 3
- 4
3.6 使用机器学习预测
在预测实际问题之前,有两件事需要实现确认
- 可以从数据集中获取哪些特征
- 需要预测的时间范围(time period)

- Origin:预测起源(forecast origin),开始预测的时间,可以被认为是最后一个可供训练的数据出现的时间
- Horizon:预测时间段(forecast horizon),指我们要预测的时间段
- Lead Time:提前期,有时也采用延后期(latency),由于数据获取或处理的延时,通常需要提前几步预测

通常对多输出模型需要构建类似上图的DataFrame。上图表示了三步预测,采用五步滞后的模型,且提前期为两天。
下面介绍几种常见的多输出模型策略
3.6.1 多输出模型 Multioutput Model
使用可以产生多个输出值的模型,例如线性回归模型和神经网络,这种方法简单而有效但并不适用于任何一个模型,例如XGBoost。

3.6.2 直接策略 Directory Strategy
为训练周期(forecast horizon)内的每个步骤单独训练一个模型,第一个模型为一步模型(提前期为1), 第二个模型是二步模型(提前期为2),…每次lead time取得不同,就是不同的模型,使用不同的模型预测每步会对结果有所帮助,但算法开销很大。

使用XGBoost多输出预测可以采用封装的sklearn.MultiOutputRegressor
3.6.3 递归策略 Recursive strategy
训练一个单一的一步模型,并使用他的预测来更新下一步的滞后特征。如此只需要训练一个模型,就可以做到预测任意长度时间的预测。但是这样做错误也会逐级传递,故长期预测可能是不准的。

3.6.4 结合策略 DirRec strategy
直接策略和递归策略的组合。训练每个步骤的模型,并使用前面模型的预测作为新的滞后特性,逐步的每个模型都会得到一个额外的滞后输入。因此DirRec可以比Direct策略捕捉到更好的时序依赖性,但同样的可能会受到错误传播的影响。
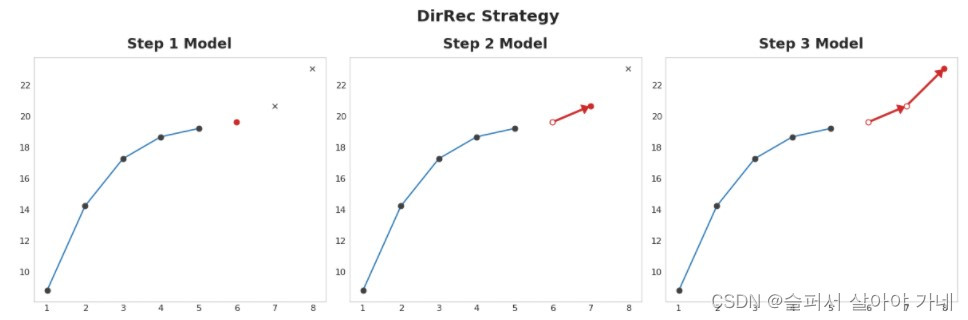
需要使用sklearn.RegressionChain替换MultiOutputRegressor,并自己编写递归过程。
modle = RegressionChain(base_estimator = XGBRegressor())
- 1

