
- 1Unity3D 游戏数据本地化存储与管理详解
- 2生成对抗网络(GAN)_对抗网络 共享特征
- 3python+jieba+wordcloud实现超酷的词云_jieba分词后如何使用jupyter输出
- 4go + uniapp 通过 微信 code 获取 appid 等信息 无废话_uniapp获取微信code
- 5go语言有没有简单的流程引擎_go 流程引擎
- 6Mysql---C#在cmd中使用mysqldump导出sql文件
- 7论文阅读【时间序列分析1】Reconstructing Nonlinear Dynamical Systems from Multi-Modal Time Series_多模态时间序列
- 8yolov5调试common.py出现importerror: cannot import name ‘tryexcept‘ from ‘utils‘_cannot import name 'tryexcept' from 'utils
- 9Android:漫画APP开发笔记之ListView中图片按屏幕宽度缩放_android listview可缩放
- 10基于 Nginx Ingress + 云效 AppStack 实现灰度发布
【总结】在嵌入式设备上可以离线运行的LLM--Llama_嵌入式llm
赞
踩
一个令人沮丧的结论在资源受限的嵌入式设备上无法运行LLM(大语言模型)。
一丝曙光:tinyLlama-1.1b(10.1亿参数,需要至少2.98GB的RAM)
基本简介
在本地电脑/嵌入式系统上运行大型语言模型(LLM),需要考虑的关键因素之一就是内存够不够。
1. 怎么看模型名字?
模型名字一般由两部分构成,[模型名称] + [参数量]。比如Gemma 7B里,Gemma是模型的名称,一般指代一个系列的模型。7B代表这个模型文件大约有7 billion / 70亿个参数,一般参数量越高的模型能力越强。
2. 模型精度
除了模型参数量,影响模型大小的另一个比较重要的指标是[精度](precision),一般看到的full precision指的是32bit,half precision指的是16bit,常见的还有8bit,4bit等。这个指标一般能在模型说明里找到。
3. 模型文件大小
模型文件大小可以通过看[参数量]+[精度]来简单计算。全精度/Full precision下,一个参数/parameter通过4byte来存储。1B(10亿)个参数通过4GB来存储,总结如下表:
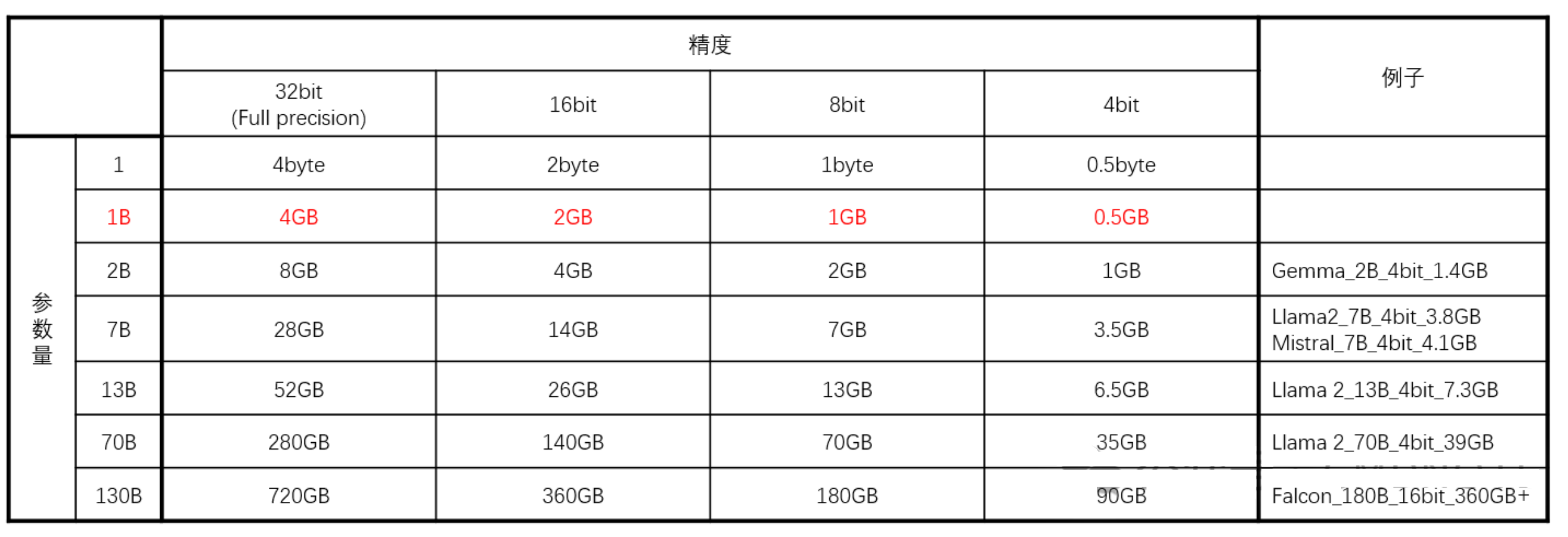 可以看到的是:
可以看到的是:
- 一般模型文件的实际尺寸要比简单计算的尺寸大
- 即使是同样参数和精度的模型,实际尺寸也不一样
- 降低模型精度的过程叫量化(Quantization),不同模型对降低精度的敏感程度不一样,比如在这项(https://huggingface.co/blog/falcon-180b)测试中,研究人员发现Falcon 180B低精度版本在表现上变化不大。
4. 到底要多少内存才够?
以我用ollama + Lllama 7B 4bit 做推断(Inference,问大模型问题)为例,模型文件大小是3.8G,实际运行的时候电脑内存会多占用大概4.8G左右。
具体用哪家的模型可以看各方的评测,有一些模型适合特殊的场景。但是用多大的模型,我见过有专家推荐:跑你能跑的最大的4bit的模型。我感觉这个建议足够普通用户使用了。具体用多大参数的模型,各位可以根据上面的表格来粗略估算一下,比如要跑4bit的Llama2 13B,模型文件就7.3G,8G内存就不太够了,16G内存也要看看是不是运行其他软件的时候够。
https://mp.weixin.qq.com/s/5C9RlA5Yi8avfgVFCJtm4Q
Llama 简介
LLaMA 模型集合由 Meta AI 于 2023 年 2 月推出, 包括四种尺寸(7B 、13B 、30B 和 65B)。由于 LLaMA 的 开放性和有效性, 自从 LLaMA 一经发布, 就受到了研究界和工业界的广泛关注。 LLaMA 模型在开放基准的各 种方面都取得了非常出色的表现, 已成为迄今为止最流行的开放语言模型。大批研究人员通过指令调整或持续 预训练扩展了 LLaMA 模型。特别需要指出的是, 指令调优 LLaMA 已成为一种主要开发定制专门模型的方法, 由于相对较低的计算成本。
LLaMA是在训练一系列模型中, 通过训练比通常来说更多的 tokens,在不同的推理预算下达到尽可能好的性能而最终产生的模型。其参数范围为 70 亿(7B)到 650 亿(65B)。LLaMA 的预训练数据包含: CommonCrawl, C4 ,Github ,Wikipedia ,Books ,ArXiv,以及 StackExchange。
LLaMA 也使用了基本的 transformer 架构,并利用了以前的语言模型提出的各种改进:
预归一化为了提升训练的稳定性, LLaMA 使用了 RMSNorm将每个 transformer 子层的输入归一化而 不是归一化输出。
SwiGLU 激活函数将 ReLU 激活函数替换为 SwiGLU 激活函数,维度变为 2/3 * 4d 而不是 PaLM 中的 4d。
旋转嵌入将每层的绝对位置嵌入替换为旋转位置嵌入(RoPE)。
- 1
- 2
- 3
另外, 该模型使用了 AdamW 优化器进行训练。其超参数为 β 1 = 0.9 ,β2 = 0.95。使用余弦学习率调 度, 使最终学习率为最大学习率的 10%。权重衰减为 0.1,梯度裁剪为 1.0,使用了 2000 个预热步骤, 而且根据 模型大小调整学习率和批次处理大小。
LLaMA 使用了两种方法提高模型的训练速度。首先是使用 causal 多头注意力来减少内存使用量和运行时 间。这种方法可以通过 xformers 库实现。这种效果是由于它不存储注意力权重以及它不计算被掩盖的 key 和 query 的分数而产生的。接着是通过检查点减少向后传播期间重新计算的激活量。这是通过手动实现transformer 的向后传播函数来实现的。为了充分利用这个优化, 需要通过模型和序列并行来减少模型的内存使用。另外, 使 用 all_reduce 尽可能地重叠激活函数计算和GPU 之间通过网络的通信。
从结论上来说, LLaMA- 13B 的性能比 GPT-3 更强, 但模型大小是其十分之一。而 LLaMA-65B 的表现可以 与 Chinchilla-70B 和 PaLM-540B 竞争。与以前的模型不同, LLaMA 展示了仅使用公共数据集也能达到最先进的性能。
运用
深度学习模型计算可以分为训练和推断,前者是用于构建包含大量网络化参数的模型,而后者则是利用这个模型对用户输入进行响应并给出答案。模型里包含的网络化参数越多,相当于脑细胞越多,思维能力越强,像 GPT-3 就有 175B(1750 亿)个网络参数,基于 GPT-3 衍生的大模型让人们意识到 AI 具备非常出色的对话能力,而且在很多情况下都比人类更出色。
GPT-3 的网络参数规模是 1750 亿,执行推断所需要的内存规模会达到百 GiB 级别,目前整套东西弄下来的成本达到 100 万元级别,且不说你能不能抢到相应的硬件资源,光是自己搭配起来也不是一件轻松的事情。
网络参数规模量纲是十亿(billion, b.),可以在手机上部署的LLM是 几十亿参数的 LLM,能在计算能力更弱的嵌入式设备上运行的就是在10亿以下参数的LLM。
会有这样的描述:

在树莓派上运行语音识别和LLama-2 GPT!
类似的模型运行取决于RAM的大小:
| RAM | 参数级别 | |
|---|---|---|
| 2GB及以下 | 无支持的Llama LLM模型 | - |
| 2GB | 无支持的Llama LLM模型 | - |
| 4GB | TinyLlama-1–1B-Chat-v1-0-GGUF | 10亿级参数,1B |
| 8GB | Llama-2–7b-Chat-GGUF | 70亿级参数,7B |
| 16GB | Llama-2–7b-Chat-GGUF | 70亿级参数,7B |
| 32GB | Llama-2–7b-Chat-GGUF | 70亿级参数,7B |
| 模型名字 | 自身大小 | 最小RAM需求 | 最大RAM需求 |
|---|---|---|---|
| tinyllama-1.1b-chat-xxx.gguf | 0.48GB~1.17GB | 2.98GB | 3.67GB |
| llama-2_7b-chat-xxx.gguf | 2.83GB~7.16GB | 5.33GB | 9.66GB |
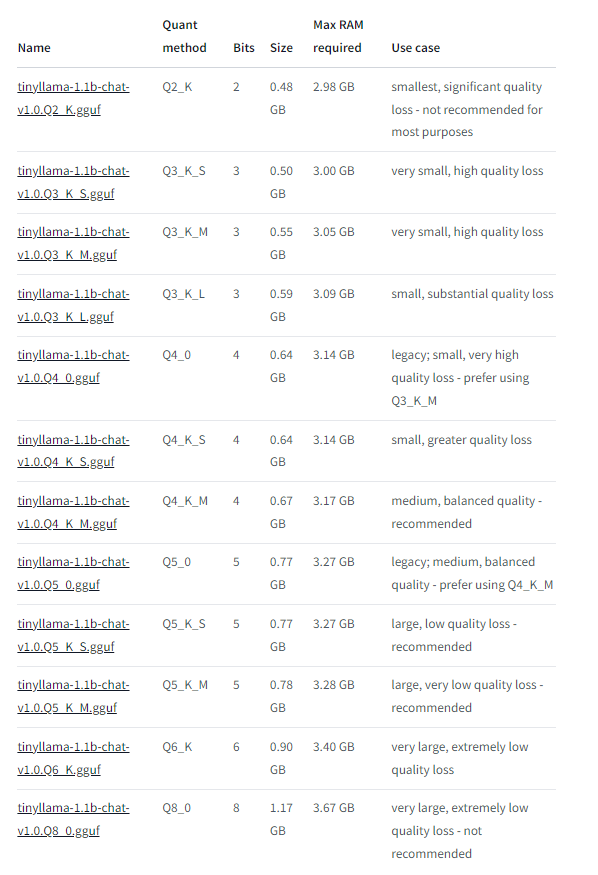
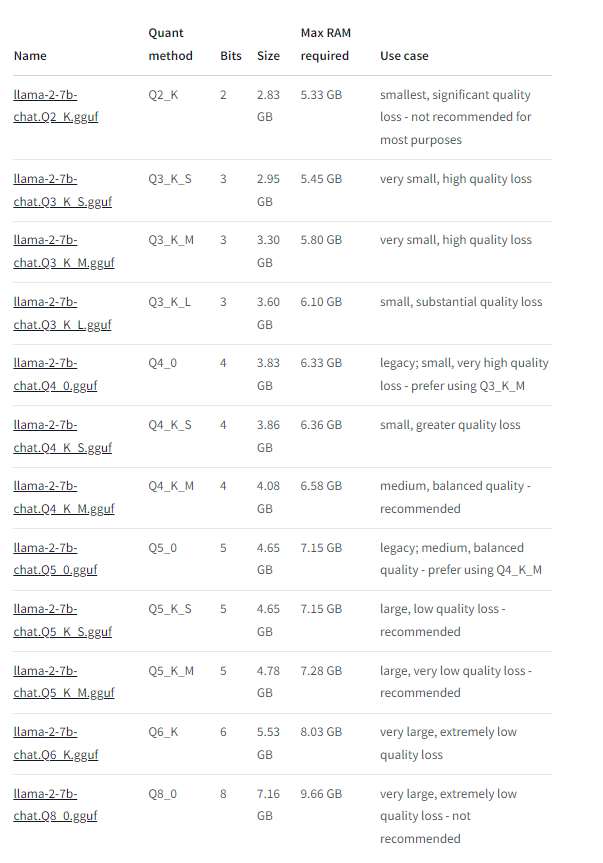
美好的愿景:
根据摩尔定律, 5-10 年后,相同的模型将轻松运行在 1 美元的芯片上,就像现在我们可以运行成熟的 PDP-11 模拟器(PDP在80年代的时候价值10 万美元)在 5 美元的 ESP32 板上。
另一种:MLC-LLM
链接:https://www.zhihu.com/question/598610139/answer/3013322834
出于定制化、个性化或者隐私性的目的,人们想要自己在各种终端设备中本地运行大语言模型,不需要/不希望连接互联网或者依赖于服务器。
尽管现在有云计算、边缘计算等技术对大模型推算的算力支持,但是用户的个人数据安全和隐私也是不得不考虑的问题,那么模型的本地化部署一定会是一个重要的方向,甚至可能会成为刚需。

