
- 1聊聊开源的 流程引擎 的选型!
- 2Android studio 最新版本(2022.3.1)的Logcat用法_android studio 2022.3.1 logcat
- 32024年,我还没找到工作,已经失业一年多(1),2024年最新移动端开发工程师面试问些什么
- 4【动态规划】之石子合并问题_石子合并问题动态规划
- 5登Cell Press子刊,武汉理工大学团队基于集成学习提出简化电化学模型,0.17s完成3500s的1C恒流放电
- 6Hadoop3:MapReduce源码解读之Map阶段的CombineFileInputFormat切片机制(4)
- 7什么是docker_什么是Docker?
- 8达梦数据库 linux odbc连接,达梦数据库学习之ODBC
- 9深度学习算法中的基于自注意力机制的神经网络(Neural Networks with Self-Attention Mechanism)_自注意力神经网络
- 10树莓派通过网线连接电脑并且设置设置链接wifi_树莓派网线怎么连接电脑
二叉树及其作用浅析_二叉树的应用
赞
踩
在学习数据结构和算法时看到各种树,把人都整蒙了,枯燥且提不起学习兴趣。等逐渐感受到二叉树的神奇作用和巨大的应用价值后,觉得二叉树原来也这么有趣,值得好好学习。
树是数据结构中的重中之重,尤其以各类二叉树为学习的难点。先从整体上认识下二叉树及其他各种树的区别和用途。
大致有哪些树?
树有很多种,其中二拆树因为其特殊的结构和特点在计算上最为常用。
常见的二叉树:二叉查找树,平衡二叉树(AVL),红黑树,字典树,满二叉树,完全二叉树,霍夫曼树,伸展树,最小堆,最大堆等,B+树,B-树则属于多路搜索树。
二叉树有什么用?
二叉树应用非常广泛。
在操作系统源程序中,树和森林被用来构造文件系统。我们看到的window和linux等文件管理系统都是树型结构。在编译系统中,如C编译器源代码中,二叉树的中序遍历形式被用来存放C 语言中的表达式。其次二叉树本身的应用也非常多,如哈夫曼二叉树用于JPEG编解码系统(压缩与解压缩过程)的源代码中,甚至于编写处理器的指令也可以用二叉树构成变长指令系统,另外二叉排序树被用于数据的排序和快速查找。
咱程序员常用的高级语言中的map和hashmap用着怪爽,它们的底层实现就有二叉树的影子。后续有机会打算使用二叉树实现一遍map和hashmap练练手。
源码参考:
- pulseaudio\src\pulsecore\hashmap.c
- code-v3.0-LTS\OpenHarmony\third_party\eudev\src\shared\hashmap.c
- code-v3.0-LTS\OpenHarmony\third_party\e2fsprogs\lib\ext2fs\hashmap.c
- code-v3.0-LTS\OpenHarmony\kernel\linux\linux-5.10\tools\lib\bpf\hashmap.c
- code-v3.0-LTS\OpenHarmony\third_party\jerryscript\jerry-core\ecma\base\ecma-property-hashmap.c
拿查找来举例,感受下二叉树的威力
有个棋盘与米粒的故事讲,在古印度有个老人发明了一个象棋游戏,给皇帝带来了乐趣,皇帝想要奖赏他,但他什么都不要只要米。要第一格棋盘上1粒,第二个格子里放2粒,在第3个格子里放4粒,在第4个格子里放8粒,以此类推。结果,即便全国积攒上千年的粮食都填不完这64个棋盘格。这就是裂变和倍增原理的威力。

假若这些米粒都是存在计算机上的海量数据,完全按照有序的平衡二叉树来排列。查找到任一米粒需要多久呢?想想这可是海量的数据。但是有了平衡二叉树,找到这其中的任一米粒的耗时,不会超过树的高度。也就是说在一个树中查找一个数字, 第一次在根节点判断,第二次在第二层节点判断 以此类推,树的高度是多少就会判断多少次 树的高度和节点的关系就是以2为底,树的节点总数n的对数。二叉树的算法时间复杂度表示为:O(logn)。拿这64格子棋盘举例,查找任一米粒所耗的时间,不超过64次,这速度难以置信吧。
平衡二叉树的优点:
平衡二叉树结合了有序数组和链表的优点,可以实现快速的查找,也可以快速的删除,查找。这是有序数组和链表不能比的。
有序数组:查找很快,二分法实现的查找所需要的时间为O(logN),遍历也很快,但是在有序数组中插入,删除却需要先 找到位置,在把数组部分元素后移,效率并不高。
链表:链表的插入和删除都是很快速的,仅仅需要改变下引用值就行了,时间仅为O(1),但是在链表中查找数据却需要遍历所有的元素, 这个效率有些慢了。
二叉查找树(搜索树,排序树)
查找树,搜索树,排序树都是一个意思。
根节点的左右2个节点,小于根节点在放在左侧,大于根节点的放在右侧。
根节点的值大于其左子树中任意一个节点的值,小于其右节点中任意一节点的值,这一规则适用于二叉查找树中的每一个节点。
本文章重点来讨论一下关于二叉查找树删除节点的问题。
有一下二叉查找树,如图:
平衡二叉树(AVL树)
简称平衡树,是由Adelson-Velskii和Landis于1962年首先提出的,所以又称为AVL树。他的定义很简单,就是若一棵二叉树的每个左右节点的高度差最多相差1,此二叉树即是平衡二叉树。把二叉树的每个节点的左子树减去右子树定义为该节点的平衡因子。二叉平衡树的平衡因子只能是1、0或者-1。
平衡二叉树是对二叉搜索树(又称为二叉排序树)的一种改进。二叉搜索树有一个缺点就是,树的结构是无法预料的,随意性很大,它只与节点的值和插入的顺序有关系,往往得到的是一个不平衡的二叉树。在最坏的情况下,可能得到的是一个单支二叉树,其高度和节点数相同,相当于一个单链表,对其正常的时间复杂度有O(lb n)变成了O(n),从而丧失了二叉排序树的一些应该有的优点。
红黑树
R-B Tree,全称是Red-Black Tree,又称为“红黑树”,它一种特殊的二叉查找树。红黑树的每个节点上都有存储位表示节点的颜色,可以是红(Red)或黑(Black)。
红黑树的特性:
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]
(4)如果一个节点是红色的,则它的子节点必须是黑色的。
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
注意:
(01) 特性(3)中的叶子节点,是只为空(NIL或null)的节点。
(02) 特性(5),确保没有一条路径会比其他路径长出俩倍。因而,红黑树是相对是接近平衡的二叉树。

最小堆
最小堆,是一种经过排序的完全二叉树,其中任一非终端节点的数据值均不大于其左子节点和右子节点的值。
二叉搜索树上的基本操作所花费的时间与这棵树的高度成正比。对于有n个结点的一棵完全二叉树来说,这些操作的最坏运行时间为Θ ( lg n ) \Theta(\lg n)Θ(lgn)。然而,如果这棵树是一条n nn个结点组成的线性链,那么同样的操作就要花费Θ ( n ) \Theta(n)Θ(n)的最坏运行时间。
哈夫曼树(Huffman Tree)
哈夫曼树是一种带权路径长度最短的二叉树,也称为最优二叉树。霍夫曼树是二叉树的一种特殊形式,其主要作用在于数据压缩和编码长度的优化。
一般可以按下面步骤构建:
1,将所有左,右子树都为空的作为根节点。
2,在森林中选出两棵根节点的权值最小的树作为一棵新树的左,右子树,且置新树的附加根节点的权值为其左,右子树上根节点的权值之和。注意,左子树的权值应小于右子树的权值。
3,从森林中删除这两棵树,同时把新树加入到森林中。
4,重复2,3步骤,直到森林中只有一棵树为止,此树便是哈夫曼树。
大家可听说过的是哈夫曼编码,其实就是哈夫曼树的应用。即如何让电文中出现较多的字符采用尽可能短的编码且保证在译码时不出现歧义。
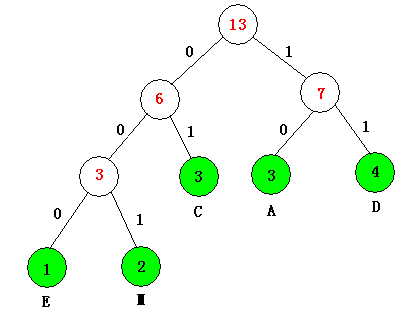
哈夫曼树的故事:
1951年,哈夫曼在麻省理工学院(MIT)攻读博士学位,他和修读信息论课程的同学得选择是完成学期报告还是期末考试。导师罗伯特·法诺(Robert Fano)出的学期报告题目是:查找最有效的二进制编码。由于无法证明哪个已有编码是最有效的,哈夫曼放弃对已有编码的研究,转向新的探索,最终发现了基于有序频率二叉树编码的想法,并很快证明了这个方法是最有效的。哈夫曼使用自底向上的方法构建二叉树,避免了次优算法香农-范诺编码(Shannon–Fano coding)的最大弊端──自顶向下构建树。
1952年,于论文《一种构建极小多余编码的方法》(A Method for the Construction of Minimum-Redundancy Codes)中发表了这个编码方法。
二叉树在计算机上的使用举例
Libevent
Libevent 是一个用c语言编写的、轻量级的开源高性能事件通知库,主要有以下几个亮点:事件驱动( event-driven),高性能;轻量级,专注于网络,不如 ACE 那么臃肿庞大;源代码相当精炼、易读;跨平台,支持 Windows、 Linux、 *BSD 和 Mac Os;支持多种 I/O 多路复用技术, epoll、 poll、 dev/poll、 select 和 kqueue 等;支持 I/O,定时器和信号等事件;注册事件优先级。
Libevent 已经被广泛的应用,作为底层的网络库;比如 memcached、 Vomit、 Nylon、 Netchat等等。Libevent的数据结构原来使用的是红黑树,自version 1.4起已由红黑树改为最小堆(Min Heap),以提高效率;网络IO和信号的数据结构采用了双向队列(TAILQ)。在实现上主要有3种链表: EVLIST_INSERTED, EVLIST_ACTIVE, EVLIST_TIMEOUT,一个ev在这3种链表之间被插入或删除,处于EVLIST_ACTIVE链表中的ev最后将会被调度执行。
Libevent提供了DNS,HTTP Server,RPC等组件,HTTP Server可以说是Libevent的经典应用。从http.c可看到Libevent的很多标准写法。写非阻塞式的HTTP Server很容易将socket处理与HTTP协议处理纠缠在一起,Libevent在这点上似乎也有值得推敲的地方。
ext2fs
EXT2FS第二代扩展文件系统,是LINUX内核所用的文件系统。它开始由Rémy Card设计,用以代替ext,于1993年1月加入linux核心支持之中。ext2 的经典实现为LINUX内核中的ext2fs文件系统驱动,最大可支持2TB的文件系统,至linux核心2.6版时,扩展到可支持32TB。其他的实现包括GNU Hurd,Mac OS X (第3方),Darwin (第3方),BSD。ext2为数个LINUX发行版的默认文件系统,如Debian、Red Hat Linux等 。
EXT2FS文件系统中,使用二叉树的地方有很多。ext2fs源码中直接能搜到红黑树的源码rbtree.c
鸿蒙OpenHarmony3.0源码中,红黑树rbtree.c源码位置:
- code-v3.0-LTS\OpenHarmony\third_party\mtd-utils\jffsX-utils\rbtree.c
-
- code-v3.0-LTS\OpenHarmony\third_party\e2fsprogs\lib\ext2fs\rbtree.c
- code-v3.0-LTS\OpenHarmony\kernel\liteos_a\lib\libscrew\src\los_rbtree.c
- code-v3.0-LTS\OpenHarmony\kernel\linux\linux-5.10\scripts\gdb\linux\rbtree.py
- code-v3.0-LTS\OpenHarmony\kernel\linux\linux-5.10\lib\rbtree.c
- code-v3.0-LTS\OpenHarmony\kernel\linux\linux-5.10\drivers\base\regmap\regcache-rbtree.c
- code-v3.0-LTS\OpenHarmony\kernel\linux\linux-4.19\net\netfilter\nft_set_rbtree.c
- ......
备注:时间复杂度
O(1):最低的时空复杂度,也就是耗时与输入数据大小无关,无论输入数据增大多少倍,耗时/耗空间都不变。哈希算法就是典型的O(1)时间复杂度,无论数据规模多大,都可以在一次计算后找到目标。
O(n):代表数据量增大几倍,耗时也增大几倍。比如常见的遍历算法。
O(logn):当数据增大n倍时,耗时增大logn倍(这里的log是以2为底的,比如,当数据增大256倍时,耗时只增大8倍,是比线性还要低的时间复杂度)。二分查找就是O(logn)的算法,每找一次排除一半的可能,256个数据中查找只要找8次就可以找到目标。
引用
平衡二叉树及其应用场景_huiguixian的专栏-CSDN博客_平衡二叉树应用场景
红黑树(一)之 原理和算法详细介绍 - 如果天空不死 - 博客园
最全二叉树:完整详解二叉树的遍历以及完全二叉树等6种二叉树_lyl5454的博客-CSDN博客_二叉树遍历
《算法导论笔记》——十分钟带你了解二叉搜索树(BST)!_lost-person的博客-CSDN博客_二叉搜索树数据结构之树_lishinho的博客-CSDN博客_数据结构树最小堆 构建、插入、删除的过程图解_hrn1216的博客-CSDN博客_最小堆《算法导论笔记》——十分钟带你了解二叉搜索树(BST)!_lost-person的博客-CSDN博客_二叉搜索树红黑树 vs 最小堆_枯树无花-CSDN博客二叉树的种类_GHOST-CSDN博客_二叉树有哪些深入学习二叉树(三) 霍夫曼树 - 简书

