
- 1VS中已经审核过的Code Review如何查纪录_代码review结果记录
- 2Java学习笔记(五)——Java集合
- 3滑雪(动态规划)_滑雪动态规划
- 4详解如何使用BenchmarkDotNet进行.NET性能测试和优化
- 5项目经理必备的软技能,你有吗?_项目管理者 软技能
- 6RabbitMQ深入 —— 交换机_rabbitmq交换机
- 7强强联合!当RAG遇到长上下文,滑铁卢大学发布LongRAG,效果领先GPT-4 Turbo 50%
- 8当个 PM 式程序员「GitHub 热点速览」
- 9Git 常用命令大全_git 查看所有分支的命令
- 10[FPGA开发工具使用总结]VIVADO在线调试(1)-信号抓取工具的使用_vivado编译提示找不到ltx文件
LoRA: 大语言模型个性化的最佳实践_lora nlp
赞
踩
出品人: Towhee 技术团队
大型语言模型(LLM)在今年获得了极大的关注。在以往,预训练+微调(finetuning)成为了让模型适配于特定数据的最佳范式。然而随着大型模型的出现,这种完全微调(重新训练所有模型参数)将变得越来越不可行。例如,如果使用GPT-3 175B,部署独立的经微调的模型实例(每个实例都有175B个参数)成本过高。在2021年,微软提出了一个方法叫LoRA(低秩适应),在大模型时代越来越受到重视,并且带来了非常好的效果。该方法冻结预训练模型的权重,并将可训练的秩分解矩阵注入到Transformer体系结构的每个层中,从而大大减少了下游任务所需的可训练参数数量。相对于使用Adam算法微调的GPT-3 175B模型,LoRA可以将可训练参数数量降低10,000倍,GPU内存需求减少3倍。此外,LoRA在RoBERTa、DeBERTa、GPT-2和GPT-3模型的模型质量方面表现与微调相当或更好,尽管它具有较少的可训练参数,更高的训练吞吐量,并且不像适配器(adapters),不会增加推理延迟。
|LoRA's reparametrization: only train A and B. 
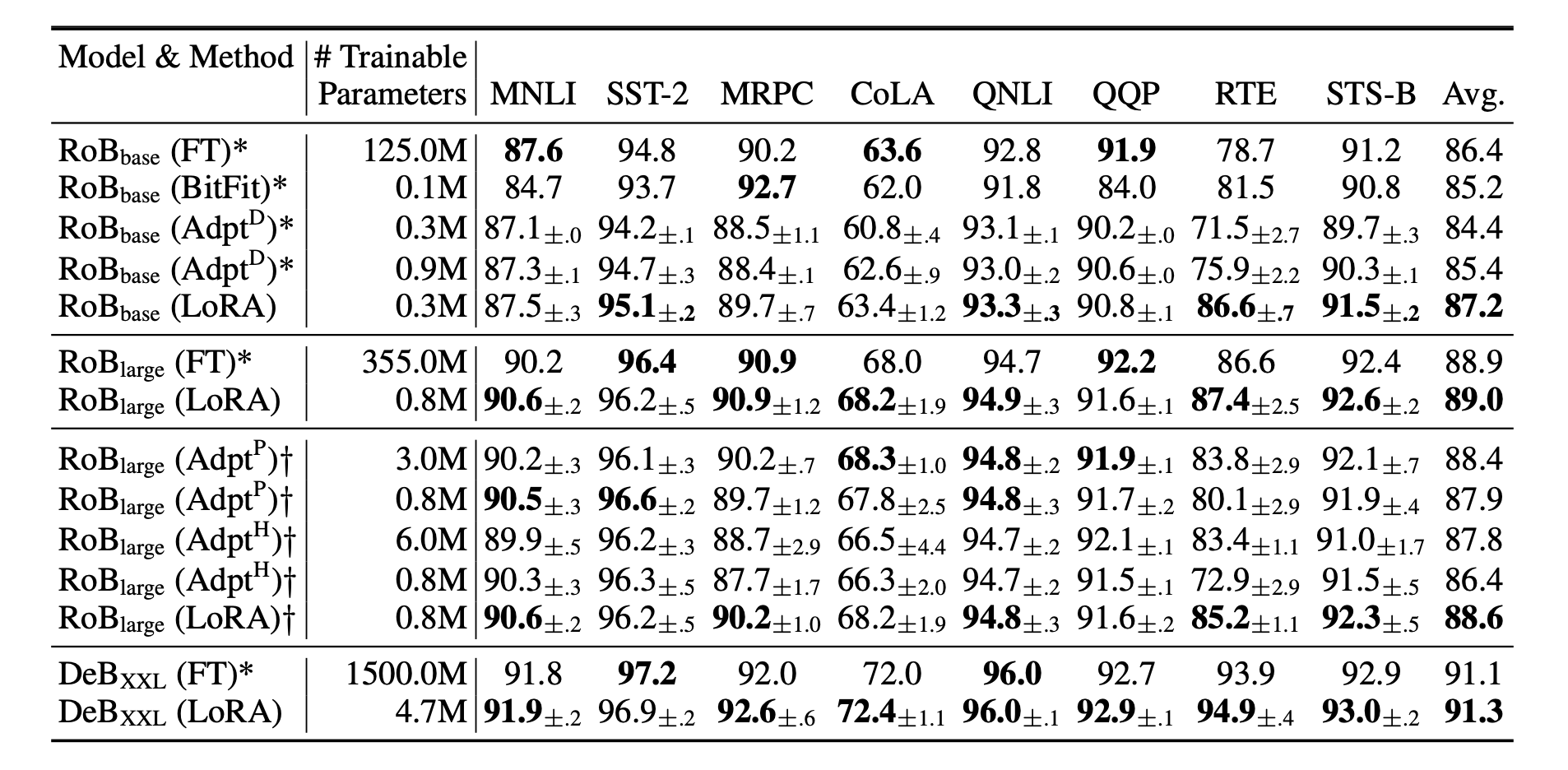
|Performance of RoBERTa pretrained with/without LoRA
这个实验结果很好地说明了这个算法的有效性。作者使用了RoBERTa模型在各个下游任务做finetune。FT就是使用全部参数进行训练,BitFit是只训练bias vector冻结住其他全部的权重。可以看出除了完全finetune,几种其他适配方法所训练的参数量都比较小。而LoRA可以训练较少的参数得到更好的结果。
LoRA不仅在NLP可以证明自己是很有效的办法,因为现在越来越多的算法都是基于transformer开发,而这个方法针对transformer非常容易适配。现在很火的stable-diffusion也已经被LoRA所攻陷,让大部分只拥有有限算力的用户可以快速finetune出一个针对自己数据所使用的LoRA模型。随着大模型越来越受到重视,成为各种任务的基线,相信这个方法会成为大模型时代的最常规的操作。
相关资料:
本文由 mdnice 多平台发布

