
- 1Tauri框架:使用Rust构建轻量级桌面应用_rust tarui 文件对话框
- 2架构设计内容分享(六十七):千万级、亿级数据,如何性能优化?_上亿的数据怎么设计架构
- 3uni-app:获取url路径中的数组参数(onshow中获取)_uniapp onshow 读取url参数
- 4答题PK狂欢!欢乐互动的团队多人PK答题小程序源码_网页答题pk代码大全
- 5TDengine 签约精诚瑞宝,开拓更智能的 IT 服务和管理平台
- 6【Unity知识点详解】Button点击事件拓展,单击、双击、长按实现_unity button onclick
- 7Microsoft Remote Desktop Beta for Mac v10.9.7.2194 - 微软远程连接工具_microsoft remote desktop for mac
- 8面试+算法之回文(Java):验证回文串、回文数、最长回文子串、回文链表、分割成回文串、最短回文串、_java 回文串
- 9来自灵魂的拷问——知道什么是SQL执行计划吗?_sql的执行计划是什么
- 10电脑系统重装怎么操作?分享四个win10重装系统方法
数据中台 第6章 数据开发: 批计算、流计算、在线查询和即席分析
赞
踩
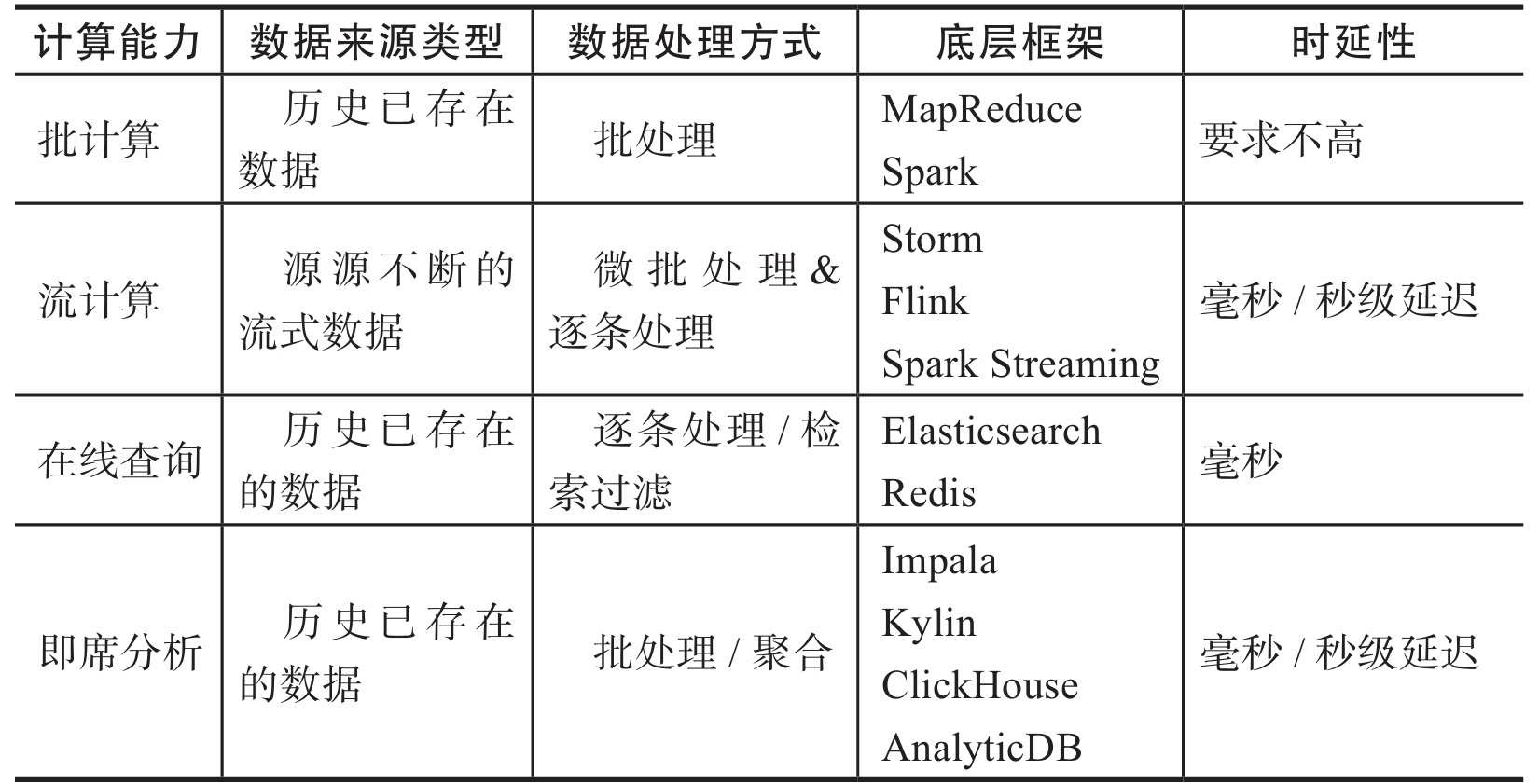
计算能力根据场景抽象分成四大类:批计算、流计算、在线查询和即席分析。 不同场景配合不同的存储和计算框架来实现,以满足业务的复杂需求,
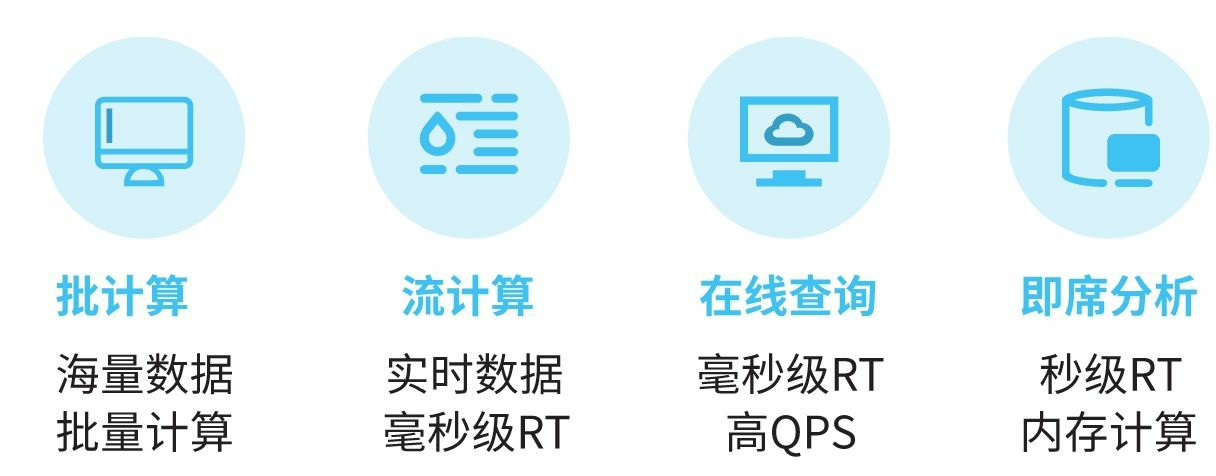
(1)批计算
主要用于批量数据的高延时处理场景,如离线数仓的加工、大规模数据的清洗和挖掘等。目前大多是利用MapReduce、Hive、Spark等计算框架进行处理,其特点是数据吞吐量大、延时高,适合人机交互少的场景。
相比MapReduce,Spark在以下几方面具有优势:
数据处理技术:Spark将执行模型抽象为通用的有向无环图(DAG)执行计划,这可以将多个Stage串联或者并行执行,而无须将Stage的中间结果输出到HDFS中。
·数据格式和内存布局:Spark RDD能支持粗粒度写操作,而对于读操作,RDD可以精确到每条记录,这使得RDD可以用来作为分布式索引。
·执行策略:MapReduce在数据Shuffle之前花费了大量的时间来排序,Spark支持基于Hash的分布式聚合,调度中采用更为通用的任务执行DAG,每一轮的输出结果都可以缓存在内存中。
1、基于内存、消除了冗余的HDFS读写 、
MapReduce在每次执行时都要从磁盘读取数据,计算完毕后都要把数据存放到磁盘上。而Spark是基于内存的。
Hadoop每次shuffle(分区合并排序等……)操作后,必须写到磁盘,而Spark在shuffle后不一定落盘,可以cache到内存中,以便迭代时使用。如果操作复杂,很多的shufle操作,那么Hadoop的读写IO时间会大大增加。少磁盘IO操作
2、DAG优化操作、消除了冗余的MapReduce阶段、
Hadoop的shuffle操作一定连着完整的MapReduce操作,冗余繁琐。
而Spark基于RDD提供了丰富的算子操作,DAG调度等机制。它可以把整个执行过程做一个图,然后进行优化。
DAG引擎,shuffle过程中避免 不必要的sort操作、 且reduce操作产生shuffle数据,可以缓存在内存中。
3.JVM的优化、Task启动(线程池)
Spark Task的启动时间快。Spark 使用多线程池模型来减少task启动开稍、Spark采用fork线程的方式,Spark每次MapReduce操作是基于线程的。Spark的Executor是启动一次JVM,内存的Task操作是在线程池内线程复用的。
而Hadoop采用创建新的进程的方式,启动一个Task便会启动一次JVM。
每次启动JVM的时间可能就需要几秒甚至十几秒,那么当Task多了,这个时间Hadoop不知道比Spark慢了多少。
(2)流计算
也叫实时流计算,对于数据的加工处理和应用有较强的实效性要求,常见于监控告警场景,例如实时分析网络事件,当有异常事件发生时能够及时介入处理。例如,阿里巴巴“双11”的可视化大屏上的数据展现是根据浏览、交易数据经过实时计算后展现在可视化大屏上的一种应用。这类场景目前应用较多的计算框架主要有Flink、Spark Streaming等。
流计算的常见应用场景如下:
- ·流式ETL:集成流计算现有的诸多数据通道和SQL灵活的加工能力,对流式数据进行实时清洗、归并、结构化处理。同时,对离线数仓进行有效补充和优化,为数据的实时传输提供可计算通道。
- ·流式报表:实时采集、加工流式数据,实时监控和展现业务和客户的各类指标,让数据化运营实时化。
- ·监控预警:对系统和用户的行为进行实时检测和分析,实时监测和发现危险行为。
- ·在线系统:实时计算各类数据指标,并利用实时结果及时调整在线系统的相关策略,在内容投放、无线智能推送等领域有大量的应用。
(3)在线查询
主要用于数据结果的在线查询、条件过滤和筛选等,如数据检索、条件过滤等。根据不同的场景也会有多种选择,如营销场景
- 对响应延时要求高的,一般会采集缓存型的存储计算,如Redis等;
- 对响应延时要求正常的,可以选择HBase和MySQL等;
- 需要进行条件过滤、检索的,可以选择Elasticsearch等。
企业一般对在线查询的需求比较旺盛,因此可能会有多套在线计算的能力提供服务。
在线查询的常见应用场景如下:
- ·画像服务:根据对象标识提供具体的查询服务,如通过Redis可以提供低延迟、高并发的查询服务能力;通过HBase可以提供大规模数据的查询服务能力,征信查询就是类似的服务。
- ·搜索的应用场景:提供搜索引擎的能力,为用户提供模糊匹配、意图识别检索等能力,快速检索需要的内容,如常见的文档搜索、商品搜索等。
- ·圈人场景:通过一些特定的条件规则,可以快速筛选出业务所需要的群体,为后续的运营、营销等工作的开展提供支撑
(4)即席分析
主要用于分析型场景和经验统计。一般而言,企业80%的数据处理需求是在线查询和即席分析。针对不同维度的分析,有多种方式可以提供,提前固定计算的维度、根据需求任意维度的交叉分析(ad-hoc)等都是常见的场景。目前也有很多相应的产品、框架来支撑这方面的应用,如Kylin、Impala、ClickHouse、Hawk等。
即席分析的常见应用场景如下:
- ·交互式数据分析:企业运营人员在日常工作中经常需要通过SQL从各个维度对当前业务进行析,提供分析结果以便开展后续工作。离线计算的场景等待时间较久,用户体验不好,即席分析可以比较好地规避这个问题。
- ·群体对比分析场景:在业务中经常会有A/B测试场景,针对不同的群体,从各个维度对比分析也是即席分析经常支撑的场景
6.4 算法开发、
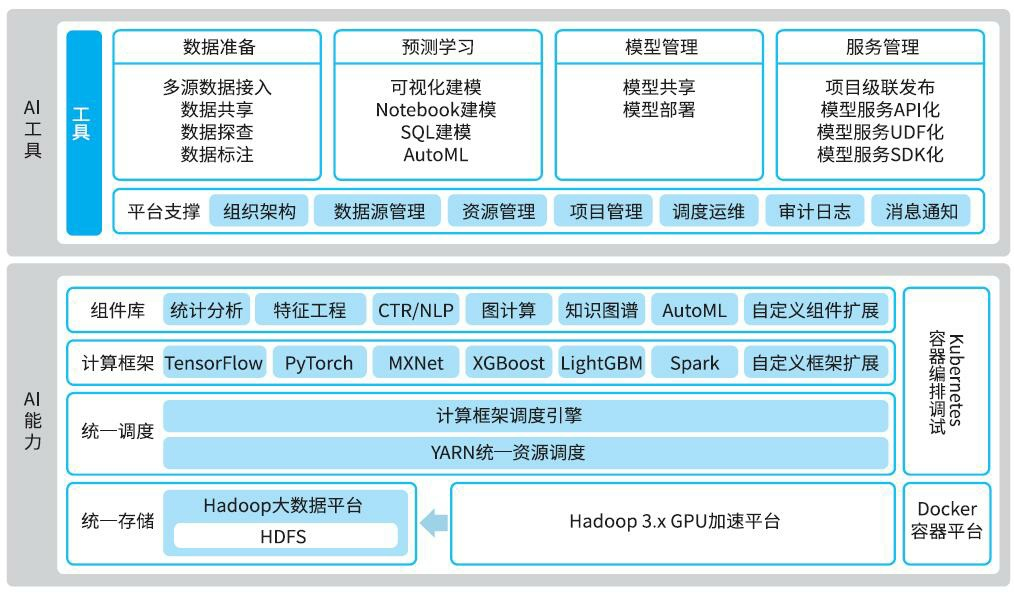
面对前台的智能业务需求,传统的数据加工和分析难以满足,作为数据开发的重要工具,算法开发需要满足复杂的学习预测类智能需求,输出算法模型能力,将数据洞察升级为学习预测,驱动业务创新。当数据开发和资产加工无法满足数据挖掘、算法标签生产等场景的需求时,算法开发可为离线开发和实时开发提供算法模型。加工好的数据和标签资产又能被算法开发用于模型训练和学习预测,支持智能需求研发。不同企业的算法应用场景也不一样,数据的差异性也决定了每个企业的算法效果会有很大差别,数据和特征决定了机器学习的上限
比较常见的应用场景如下:
- ·金融风控和反欺诈:利用关联分析、标签传播、PageRank和社团发现等图算法组件,构建金融反欺诈核心能力,根据客户本身属性和行为数据识别虚假账号和欺诈行为,增强金融监管能力,保障金融业务稳定和安全。
- ·文本挖掘分析:利用命名实体识别 [1] 、图挖掘等文本算法能力,通过分析非结构化的文本信息自动识别其中的实体以及它们之间的关系,构建关系网,可以深度分析以前未处理的一些线索。
- ·广告精准营销:通过深入洞察客户需求、偏好和行为,利用特征分箱、LightGBM、PMI等算法组件构建的机器学习模型来智能挖掘潜在客户,实现可持续的精准营销计划和高质量曝光率,有效提升广告点击率。
- ·个性化推荐:利用协同过滤、XGBoost等推荐场景组件,通过分析海量用户行为数据构建多维用户画像,实现千人千面的推荐,提高转化率。这些场景的落地通过算法开发工具可以大幅提升效率,当企业缺少算法工程师构建场景时,可以降低企业构建智能化场景的门槛,快速实现企业需求。

