
- 1深度学习(11)之Anchor-Free详解
- 2算法训练营第六十九天 | 并查集理论基础、寻找存在的路径、冗余连接、冗余连接II_卡码网
- 3Git常用命令大全_git rename
- 4弹出框 custombox.min.js 使用时候由于滚动条隐藏造成网页抖动变形的解决办法
- 5【前端系列】20种 Button 样式_前端按钮
- 6uniapp:完成商品分类页面(scroll-view),左侧导航,右侧商品_uniapp左侧导航右侧内容
- 7深度学习实战—基于TensorFlow 2.0的人工智能开发应用_深度学习实战:基于tensorflow
- 8QT网络编程之实现TCP客户端和服务端_qt tcp客户端
- 9哈工大(HIT)计算机网络 翻转课堂 实验 mooc答案 总结_哈工大计网mooc答案
- 10Stable Diffusion学习笔记_马尔科夫链的反向过程是
环境搭建_HDFS搭建_hdfs环境搭建
赞
踩
序言:本文介绍HDFS分布式搭建,使用4台新的虚拟机,文中部分需要使用到wget等工具,请自行下载。菜鸟作者用来整整2天的时候才搭建成功,中间遇到了种种坑~~~
环境:

1. 使得主机之间可以互相通信
1.1 修改主机名:
hostnamectl set-hostname 主机名
- 1
1.2 修改hosts文件
vim /etc/hosts
- 1
加入以下语句
192.168.174.128 master
192.168.174.129 slave1
192.168.174.130 slave2
192.168.174.131 slave3
- 1
- 2
- 3
- 4
2.安装jdk(如已安装,则跳过此步骤)
2.1 创建jdk目录
mkdir jdk
- 1
2.2 进入jdk目录
cd jdk
- 1
2.3 下载jdk
wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/8u141-b15/336fa29ff2bb4ef291e347e091f7f4a7/jdk-8u141-linux-x64.tar.gz"
- 1
2.4 解压jdk
tar xzf jdk-8u141-linux-x64.tar.gz
- 1
2.5 配置环境变量(文件在 /etc/profile)

JAVA_HOME=/jdk/jdk1.8.0_141
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
- 1
- 2
- 3
- 4
2.6 刷新配置文件
source /etc/profile
- 1
2.7 验证是否安装成功

java -version
- 1
3.安装hadoop
3.1 创建hadoop目录
mkdir hadoop
- 1
3.2 进入hadoop目录
cd hadoop
- 1
3.3 下载hadoop
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.1.1/hadoop-3.1.1.tar.gz
- 1
3.4 解压hadoop
tar -zxvf hadoop-3.1.1.tar.gz
- 1
3.5 修改/hadoop/hadoop-3.1.1/etc/hadoop/hadoop-env.sh 文件,添加java环境变量
export JAVA_HOME=/jdk/jdk1.8.0_141
- 1
3.6 etc/profile添加环境变量
export PATH=$PATH:/hadoop/hadoop-3.1.1/bin:/hadoop/hadoop-3.1.1/sbin
- 1
3.7 刷新配置文件
source /etc/profile
- 1
3.8 检测是否安装成功
hadoop
- 1
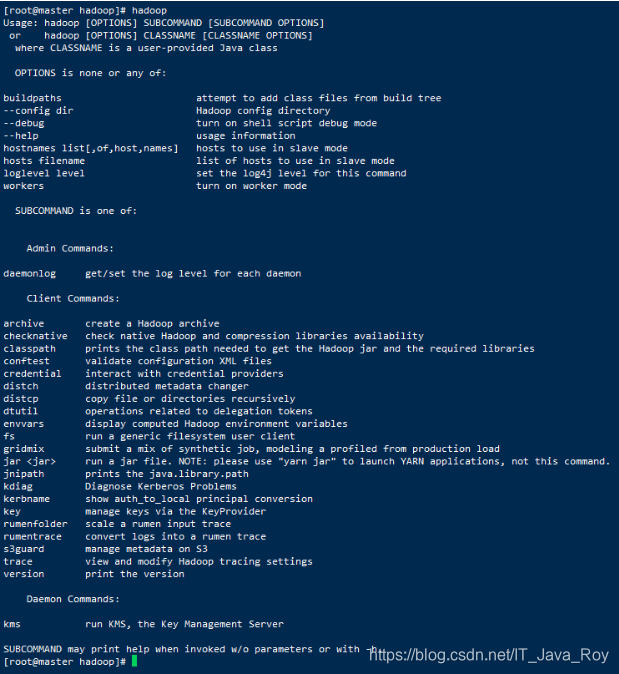
4.统一时间
4.1 安装ntp工具
yum install ntp -y
- 1
4.2 用阿里云的时间服务器
ntpdate ntp1.aliyun.com
- 1
5.设置免密登陆
5.1进入master节点,生成秘钥
ssh-keygen -t rsa
- 1
出现以下界面说明生成私钥id_rsa和公钥id_rsa.pub

5.2 把生成的公钥id依次发送到 master、slave1、slave2、slave3、slave4机器上,并输入节点的密码
ssh-copy-id slave1
- 1

5.3 尝试连接
ssh slave1
- 1

master未加入的情况下,可能出现如下报错:

6.配置HDFS
6.1 在hadoop目录下创建文件夹Hadoop存放数据的文件夹
mkdir ../hadoop/hadoopData
- 1
6.2 在 /hadoop/hadoop-3.1.1/etc/hadoop/core-site.xml文件中的configuration加入
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/hadoop/hadoopData</value> </property> <property> <name>fs.trash.interval</name> <value>4320</value> </property> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
6.3 在 /hadoop/hadoop-3.1.1/etc/hadoop/hdfs-site.xml文件中的configuration加入
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/hadoop/hadoopData/dfs/name</value> </property> <property> <name>dfs.http.address</name> <value>0.0.0.0:50070</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/hadoop/hadoopData/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.permissions.superusergroup</name> <value>staff</value> </property> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
6.4 在 /hadoop/hadoop-3.1.1/etc/hadoop/yarn-site.xml文件中的configuration加入
<configuration> <!--rm失联后重新链接的时间--> <property> <name>yarn.resourcemanager.connect.retry-interval.ms</name> <value>2000</value> </property> <!--开启resourcemanagerHA,默认为false--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--配置resourcemanager--> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>node222:2181,node224:2181,node225:2181</value> </property> <!--开启故障自动切换--> <property> <name>yarn.resourcemanager.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>node222</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>node224</value> </property> <!--***********不同节点需要修改****************--> <property> <name>yarn.resourcemanager.ha.id</name> <value>rm1</value> <description>If we want to launch more than one RM in single node,we need this configuration</description> </property> <!--开启自动恢复功能--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--配置与zookeeper的连接地址--> <property> <name>yarn.resourcemanager.zk-state-store.address</name> <value>node222:2181,node224:2181,node225:2181</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>node222:2181,node224:2181,node225:2181</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>ns1-yarn</value> </property> <!--schelduler失联等待连接时间--> <property> <name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name> <value>5000</value> </property> <!--配置rm1--> <property> <name>yarn.resourcemanager.address.rm1</name> <value>node222:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>node222:8030</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>node222:8088</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>node222:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm1</name> <value>node222:8033</value> </property> <property> <name>yarn.resourcemanager.ha.admin.address.rm1</name> <value>node222:23142</value> </property> <!--配置rm2--> <property> <name>yarn.resourcemanager.address.rm2</name> <value>node224:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>node224:8030</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>node224:8088</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>node224:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm2</name> <value>node224:8033</value> </property> <property> <name>yarn.resourcemanager.ha.admin.address.rm2</name> <value>node224:23142</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>/usr/local/hadoop-2.6.5/yarn/local</value> </property> <property> <name>yarn.nodemanager.log-dirs</name> <value>/home/hadoop/log/yarn</value> </property> <property> <name>mapreduce.shuffle.port</name> <value>23080</value> </property> <!--故障处理类--> <property> <name>yarn.client.failover-proxy-provider</name> <value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value> </property> <property> <name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name> <value>/yarn-leader-election</value> <description>Optionalsetting.Thedefaultvalueis/yarn-leader-election</description> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
6.5 在 /hadoop/hadoop-3.1.1/etc/hadoop/mapred-site.xml文件中的configuration加入
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 --> <property> <name>mapreduce.jobhistory.address</name> <value>0.0.0.0:10020</value> <description>MapReduce JobHistory Server IPC host:port</description> </property> <!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>0.0.0.0:19888</value> <description>MapReduce JobHistory Server Web UI host:port</description> </property> <property> <name>mapreduce.task.io.sort.mb</name> <value>64</value> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/user/history/done_intermediate</value> </property> <property> <name>mapreduce.jobhistory.done-dir</name> <value>/user/history</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
6.6 在master下操作,进入/hadoop/hadoop-3.1.1/etc/hadoop/slaves文件(hadoop3.0后slaves改名为workers),接入节点

注:这相当于是一份对于DN的白名单,只有在白名单里面的主机才能被NN识别
7.指定用户
7.1.配置sbin目录下 start-dfs.sh、 stop-dfs.sh添加
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
- 1
- 2
- 3
- 4
7.2.配置sbin目录下 start-yarn.sh、stop-yarn.sh添加
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
- 1
- 2
- 3
未指定,可能出现如下报错:

8.格式化NameNode、启动HDFS系统
8.1 在master下操作,输入HDFS格式化命令
hdfs namenode -format
- 1
8.2 启动HDFS文件系统
start-all.sh
- 1
8.3查看HDFS状态:
hdfs dfsadmin -report
- 1
打开HDFS的管理界面:
http://192.168.174.128:50070


