
热门标签
热门文章
- 1JavaParser的快速介绍_java parser tutorial
- 2深入剖析 Android 网络开源库 Retrofit 的源码详解_android源码开放网络
- 3redis学习笔记7-阻塞_redis hugepage写操作 是什么
- 4A站 的 Swift 实践 ,收获总结。_swift 实践 改造
- 5推荐文章标题:利用FlutterFire打造跨平台的Firebase应用
- 6RabbitMQ MQTT TLS相关配置
- 7中兴新支点操作系统加入腾讯发起的OpenCloudOS开源社区:希望百花齐放_新支点默认字体都是开源字体吗
- 8Java 单链表的反转_单向链表反转java
- 9仓颉编程语言全攻略:学习秘籍+内测资格申请秘籍!_华为仓颉编程语言官网
- 10Variables Reference for vscode
当前位置: article > 正文
深度学习(11)之Anchor-Free详解
作者:IT小白 | 2024-07-02 01:27:40
赞
踩
anchor-free
一、anchor free 概述
1
、
先要知道anchor 是什么(这需要先了解二阶段如faster rcnn,一阶检测器如YOLO V2以后或SSD等)。
在过去,目标检测通常被建模为对候选框的分类和回归,不过,按照候选区域的产生方式不同,分为二阶段(two-step)检测和单阶段(one-step)检测,前者的候选框通过RPN(区域推荐网络)网络产生proposal,后者通在特定特征图上的每个位置产生不同大小和宽高比的先验框(anchor)。如下图:

2、为什么要抛弃anchor,做anchor free
1)Anchor的设置需要手动去设计(长宽比,尺度大小,以及anchor的数量),对不同数据集也需要不同的设计,相当麻烦。
2)Anchor的匹配机制使得极端尺度(特别大和特别小的object)被匹配到的频率相对于大小适中的object被匹配到的频率更低,DNN在学习的时候不太容易学习好这些极端样本。
3)Anchor的庞大数量使得存在严重的不平衡问题,这里就涉及到一个采样的过程,实际上,类似于Focal loss的策略并不稳定,而且采样中有很多坑。
4)Anchor数量巨多,需要每一个都进行IOU计算,耗费巨大的算力,降低了效率。
3、anchor free 的方向
最早可以追溯到YOLO算法,这应该是最早的anchor-free模型,而最近的anchor-free方法主要分为
基于密集预测
和
基于关键点估计两种。
4、anchor free 的局限性
目前paper 为了达到更好看的结果,在实验上隐藏了一些细节或者有一些不公平的比较(比如骨干网络使用hourglass 对比别人的resnet等)。
5、anchor free 工程推荐
由于YOLOV5的推出,主要了解anchor free 的思想,工程应用主要可以尝试:
1)centerNet(object as point 的版本)
2)extremeNet(将回归边界框改为极值点)
二、anchor free 解读
按照如下结构进行介绍
X、XXXXX
1、主要贡献
2、主要思路
3、具体细节
1)input
2)backbone
3)neck & head
4)loss function
5)trics
4、结果
A. dense box (2015年9月百度IDL&地平线)
1、主要贡献
1)将FCN引入目标检测,可以获得很好的效率和精度;end2end多任务目标检测框架。
2)将目标landmark定位引入DenseBox的多任务学习中,检测精度可以进一步提高;
3)在人脸检测中 DenseBox在MALF和KITTI上取得了sota;
2、主要思路

如上图:
1)使用图像金字塔,输入CNN, 直接在feature map同时预测bbox + 分类得分(也就是一个5层的特征图:4层代表Bbox回归,一层代表二分类人脸得分)
2) DenseBox除NMS步骤外,整个模型都是全卷积操作,没有全连接层,也不需要region proposal生成步骤;
3)图像做了下采样 + 上采样(双线性插值),和分割网络FCN有相似之处;
3、具体细节
1)input
a.训练阶段
原图中包含了太多的背景,训练耗费大量时间在背景区域的计算与判定上,意义不大;因此
使用crop的图像patch参与DenseBox的训练,只要crop出的图像patch包含人脸,且有足够的背景信息就行。
具体操作:DenseBox训练有点图像分割图像的路子,首先从原图中crop出图像patch,再resize至240 x 240,该图像中心位置包含一个高50 pix左右的人脸gt bbox; 这个操作很容易实现,相当于从原图 + gt的图像中crop出patch,但这个patch必须要保证人脸在patch中心,且resize后gt bbox大小变为50 x 50,那么具体crop多大的patch子区域,就需要做个等比例计算即可;举个栗子:原图中一个人脸gt bbox为80 x 80,我们需要保证resize后该人脸尺度为50 x 50,那么原图中需要crop出的patch子区域为240 x 80 / 50 = 384,也即384 x 384子区域即可。
b. 测试阶段
使用图像金字塔
2)backbone

共16层卷积操作,复用了VGG19的前12层网络参数。
3)neck & head
conv 4-4后接4个1 x 1的conv层;从fig 3中可知,其实又分为两个分支:两个1 x 1的conv层最终输出1通道feature map,用于人脸分类得分的计算;另两个1 x 1的conv层输出4通道feature map,用于人脸bbox回归的计算;
conv 3-4与conv 4-4的feature map特征融合,做的是concate;
作者认为低层feature map上的特征,包含更多目标的局部细节信息,更加方便判断目标的局部区域;
高层feature map上的特征,因为有更大的感受野,包含更多的语音信息和上下文信息,更加易于识别目标的全局信息;
conv 3-4的感受野为48 x 48,几乎与人脸gt bbox尺度相当,conv 4-4的感受野为118 x 118,因此可以融合更多的全局信息 + 上下文信息;此外,conv 4-4 feature map的尺度是conv3-4尺度的一半(多了个pool3操作),因此在做concate之前,需要先对conv 4-4做个双线性上采样,确保二者尺度相同;
因为只做concate,而非element-wise相加,就不需要保证通道数相同了。
4)loss
a.
分类loss,feature map上的pixel-wise L2-loss。
作者说在DenseBox中L2-loss性能就很好了,就没尝试诸如hinge loss、cross-entropy loss等。
b.
bbox回归loss,也是feature map上的pixel-wise L2-loss.
4)trick
a.定义正负样本
每次mini-batch迭代中,正负样本数量差异很大,负样本占据绝大多数;如果这些负样本都用于训练,那么最终的loss将会偏向于海量的负样本;同时,如果使用那些
分类边界上的模棱两可的正负样本训练
,模型又学不到有价值的信息,性能也会下降.
在最后的特征图上:
正样本:标注框的中心点(个人理解以及中心点为圆心,标注框高一定比例如0.3为半径的圆内的点);
负样本:上述正样本外的点;
忽略样本:
负样本的像素(x, y),如果它附近两个像素距离内有正样本像素,就将该像素认为忽略样本。
b.困难样本挖掘
mini-batch中,所有样本先做次前向操作,
对所有pixel输出依照公式(1)的loss作降序排序,选择top 1%作为难负样本;
并保留所有的正样本(positive labeled pixels),控制正负样本比例为1:1;所有的负样本,一半来自从non-hard negative(也即剩余top 99%负样本)中随机取样,一半来自从top 1% hard-negative中的采样;每个mini-batch中,通过设置
Fsel = 1
来标识样本是否被选中(正样本 + 难负样本 + 随机选中的负样本)
正样本:输入的240 x 240 pix patch,且patch中心位置包含一个特定尺度范围(50 x 50 pix附近)内的正样本,每个patch中正样本附近可能包含若干个负样本;
负样本:random patch:从图像中随机尺度上随机crop出patch(randomly crop patches at random scale from training images),再resize至240 x 240 pix patch输入网络;训练时,控制正样本与random patch的负样本比例为1:1;
c.数据增强
对正负patch做随机左右翻转,25 pix的平移,尺度变换[0.5,1.25];
B. YOLO V1
1、主要贡献
一阶段、快速、端到端训练
2、主要思路

通过全卷积网络,将输入图像映射为一个7*7*30 的张量,7*7是吧整个图像划为7*7个网格,每个网格设置2个预选框(训练可以理解为进化的思路),如下左图;30是每个位置的编码如下右图。
20个对象分类的概率:YOLO支持识别20种不同的对象(人、鸟、猫、汽车、椅子等)
2个bounding box的位置:每个bounding box需要4个数值来表示其位置,(Center_x,Center_y,width,height)
2个bounding box的置信度:该bounding box内存在对象的概率 * 该bounding box与该对象实际bounding box的IOU。当该格点不含有物体时,该置信度的标签为0;若含有物体时,该置信度的标签为预测框与真实物体框的IOU数值


3、具体细节
1)inout
输入就是原始图像,唯一的要求是缩放到448*448的大小。主要是因为YOLO的网络中,卷积层最后接了两个全连接层,全连接层是要求固定大小的向量作为输入。
2)backbone
Darknet
3)
neck & head
如上面的两个图,总共有 49*2=98 个候选区,没有预先设置2个bounding box的大小和形状,也没有对每个bounding box分别输出一个对象的预测。它的意思仅仅是对一个对象预测出2个bounding box,选择预测得相对比较准的那个。有点不完全算监督算法,而是像进化算法。 一张图片最多可以检测出49个对象。计算出该Object的bounding box的中心位置,这个中心位置落在哪个grid,该grid对应的输出向量中该对象的类别概率是1,负责预测该object;其他grid对该Object的预测概率设为0(不负责预测该对象)。
4)
loss function

5)tricks
a.
不直接回归中心点坐标数值,而是回归相对于格点左上角坐标的位移值
b.
每个格点预测两个或多个矩形框,
在损失函数计算中,只对和真实物体最接近的框计算损失,其余框不进行修正.
作者发现,一个格点的两个框在尺寸、长宽比、或者某些类别上逐渐有所分工,总体的召回率有所提升。
c.
在推理时,使用物体的类别预测最大值 p
乘以 预测框的最大值c
,作为输出预测物体的置信度。
C、FCOS ( Fully Convolutional One-Stage Object Detection 已开源)
1、主要贡献
1)如何解决重叠点:采用FPN分层+同层重叠归属面积最小框
2)如何解决逐像素低质量框:提出了center——ness策略(个人认为
其实本质感觉和YOLOV1的预测object是一样的
)
2、主要思路
使用FPN,在特征图上
对所有的点进行:
预测分类+位置回归+是否是中心(
个人认为
其实本质感觉和YOLOV1的预测object是一样的)

3、具体细节
1)input
无特殊要求
2)backbone
无特殊,实验尝试过resnext-32x8d-101-fpn等
3)neck & head
a.如上面figure2,需要注意的是
与FPN原生实现稍有不同的是:
FCOS采用了backbone输出的C3、C4、C5特征图,横向合成得到P3、P4、P5;P6、P7是P5、P6经过一个步长为2的卷积层得到的。所有最后的特征图总共有5个,下采样倍数分别为8,16,32,64,128。
b.label 有分类+回归构成。
给定一个位置(x,y),如果该点落在任意一个GT bounding box中,那么该位置就会被识别为正例并给它附上类别标签c*,否则c*=0表示背景;此外对于这个位置(x,y),还要给它一个4维向量t
=(l*,t*,r*,b*
)作为回归的目标。
(
l*,t*,r*,b*
分别表示该点到bounding box 左(left),上(top),右(right),下(bottom)的距离
)如下图。

回归目标几乎都是正样本,因此利用exp()函数,将回归目标映射到(0,∞),这样做的好处是增加了bounding box的辨识度。
给定一张image,通过FCOS得到每个位置的类别得分Px,y和位置回归预测t (x,y),然后选择px,y>0.05的位置作为正例。
anchor-based方法在选取anchor box时,考虑的是其与GT的IOU比,超过阈值的为正样本,与之不同的是,FCOS可以利用尽可能多的前景样本进行训练回归。
c.重叠区域处理

第一种情况(在同一层特征图):
选择区域小的那个bounding box作为回归目标,通过这种处理能极大的减少模糊样本。
第二种情况(由于有FPN,在不同层特征图):
利用不同层的feature map检测不同尺寸的物体。
具体做法:
if a location satisfies max(l∗, t∗, r∗, b∗) > mi or max(l∗, t∗, r∗, b∗) < mi-1, it is set as a negative sample and is thus not required to regress a bounding box anymore. Here mi is the maximum distance that feature level i needs to regress. In this work, m2, m3, m4, m5, m6 and m7 are set as 0, 64, 128, 256, 512 and ∞
d.center-ness

采用了FPN之后,网络的效果和state-of-the-art目标检测算法还是有一些差距,分析之后发现是
低质量检测框
导致的。
由于卷积神经网络中,特征图上一点,对应的是感受野的正中心,所以图五中橘黄色的点预测当前person的效果,一定要比两个绿色点好。那么两个绿色点就被成为低质量预测点。center-ness就是为了抑制绿色点的权重。先看center-ness的计算公式:

根据公式可知,离ground truth中心越近的点,center-ness值越高。但是新问题来了,center-ness有两种获得方式,一:根据预测数值l*,r*,t*,b*,直接计算出center-ness;二:单独回归一个center-ness值,根据标签数值l,r,t,b来训练该分支。从图四网络结构可知,作者采用了方法二,实际上两种方法作者进行了对比:

结果说了算,就是单独center-ness回归分支,提高了mAP。
4)loss function

类别损失函数使用focal loss,回归损失函数使用UnitBox论文中的IOU loss。
看代码后,其实还有一个centerness 损失函数分支,该分支使用的是BCEloss,只不过label为上面centerness计算出来的,并不是onehot编码的二分类label。
5)trics
无
4、结果
论文中的对比实验结果:
 图八 FCOS精度对比
图八 FCOS精度对比
至少可以看出,FCOS精度超过了老牌经典算法Faster R-CNN。

FCOS性能
论文中没有详细提及速率的具体数值,上图截自论文官网代码,可能机器不同数值略有差异。推理速度并没有比二阶段的Faster R-CNN快,但也基本满足了实时性。mAP确实超越了Faster R-CNN不少。
D、
FSAF(Feature Selective Anchor-Free Module for Single-Shot Object Detection)
1、主要贡献
针对当前使用FPN的目标检测匹配ground truth和anchor思路主要依靠iou或者分层机制给出自动匹配的方式。
2、主要思路
尝试使用FPN的每一层去检测instance,然后看哪一层的的检测结果是的这个instance的损失最小,这一层就最适合检测这个instance。
3、具体细节
1)input
无分辨率要求
2)backbone
作者实验了resnext-101
3)
neck & head
a、分支结构
FSAF模块让每个instance自动的选择FPN中最合适的特征层,在这个模块中,
feature 选择的依据由原来的instance size变成了instance content,实现了模型自动化学习选择FPN中最合适的特征层。
FSAF以RetinaNet为基础结构,添加一个FSAF分支和原来的classification subnet、regression subnet并行,可以不改变原有结构的基础上实现完全的end-to-end training。FSAF同样包含
classification(使用的是sigmoid函数)
和
box regression
两个分支,用于预测目标所属的类别和坐标值,如图

b. babel定义
第一:一个目标(Instance),假设它的类别是lable = c,并且边界框坐标是
 ,(x,y)是目标的中心坐标,
,(x,y)是目标的中心坐标,
(w,h)是目标的宽和高。
第二:此目标在FPN中的第
 特征层投影的坐标是
特征层投影的坐标是
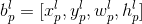 ,其中
,其中
 。
。
第三:定义投影的有效目标框坐标是
 ,也就是图3中的"car"class的白色区域,其中
,也就是图3中的"car"class的白色区域,其中
 ,式中的
。
,式中的
。
第四:定义投影的忽略目标框坐标是
,也就是图3中的"car"class的灰色区域,其中
,式中的
 。
。

class output:
class output是和anchor-base brances并行结构,它的维度是W×H×K,K是总的类别数
(应该包含背景类别)
, c
lass output总共有K个feature maps,在上面我们假设此目标的类别是c(图中的车类别),那么class output 的标签维度是W×H×K的张量,在K个feature
maps
中的第c个feature
map
的定义是图3中的“car”class。其中白 色区域就是正的目标区域
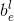 定义值是1,灰色是忽略区域也就是
定义值是1,灰色是忽略区域也就是
 不进行梯度反向传播,黑色是负的目标区域
定义值是0. 采用的损失函数是Focal Loss。
不进行梯度反向传播,黑色是负的目标区域
定义值是0. 采用的损失函数是Focal Loss。
box output:
box
output是和anchor-base brances并行结构,它的维度是W×H×4,4代表偏移量。举例说明偏移量的含义:
box output的标签是
对于有效区域
 中像素点
中像素点
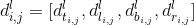 ,4个维度的值是
,其中
,
,4个维度的值是
,其中
,
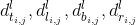 是像素位置
是像素位置
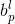 分别相对于
的 top, left, bottom, right,
如图4
,此外S=4.0。采用的损失函数 是IoU Loss。
分别相对于
的 top, left, bottom, right,
如图4
,此外S=4.0。采用的损失函数 是IoU Loss。
在像素点
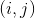 ,如果预测的偏移量是
,如果预测的偏移量是
 ,那么
,那么
 到
的距离是
到
的距离是
 ,预
测的左上角和右下角的坐标分别是
,预
测的左上角和右下角的坐标分别是
 和
和
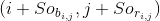 ,则预测的边界框坐标就是将和
和
分别乘上
,则预测的边界框坐标就是将和
和
分别乘上
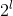 。
。

3)loss function
a. 在anchor-based算法中,通常是基于目标的size分配到指定的特征层,而FSAF模块是基于目标的内容选择最优特征层。记目标分配到第个特征层的分类损失和定位损失分别如下:

其中是有效区域像素点的个数。
那么预测目标最优的特征层是由下式得到,也就是联合损失函数最小。
b.
如何将anchors-free brances和anchors-base brances结合?
在inference中,FSAF可以单独作为一个分支输出预测结果,也可以和原来的anchor-based分支同时输出预测结果。两者都存在时,两个分支的输出结果结合然后使用NMS得到最后预测结果。在training中,采用multi-task loss,即公式如下。
权重系数为0.5.
5)trics
无
4、结果
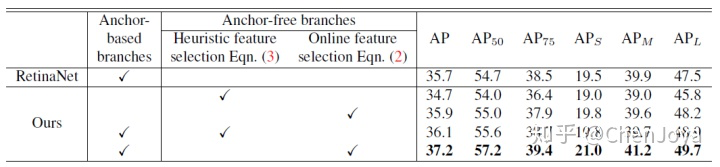
E、FeveaBox
1、主要贡献
由于和fcos、FSAF很多思路很像,区别在于回归
并不是直接学习目标中心到四个边的距离,而是去学习一个预测坐标与真实坐标的映射关系。
2、主要思路
直接学习目标的存在概率和真实框的坐标(不产生预选框)。主要通过两个分支:
预测一个类别敏感的语义图作为目标存在的概率
预测一个中心点和边框坐标的一个映射关系

3、具体细节
1)输入
图像分辨率无特殊要求。
2)backbone
主要是与retina net对比,backbone尝试过ResNet101 和ResNext101。
3)neck & head
a.为了公平的与RetinaNet进行比对,作者使用了一模一样的网络结构,也就是ResNet+FPN的结构,其中金字塔的层数
 .而且
.而且
 输入图像的分辨率。
输入图像的分辨率。

b.匹配Bbox
假设FPN中每一个层预测一定范围内的bounding box,而每个特征金字塔都有一个basic area,即32*32到512*512,所以表示为
 ,并设置
,并设置
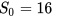 。正好当l=3 时,整体面积为1024=32*32。但FoveaBox为了使每个层去响应特定的物体尺度,对每个金字塔层L 都计算一个有效范围如下,其中用来控制这个尺度范围(我的理解就是依靠面积做的匹配):
。正好当l=3 时,整体面积为1024=32*32。但FoveaBox为了使每个层去响应特定的物体尺度,对每个金字塔层L 都计算一个有效范围如下,其中用来控制这个尺度范围(我的理解就是依靠面积做的匹配):
作者经过试验,发现当这个控制因子为2是为最优情况。

c. 正负区域确定
首先我们来看预测分类的子网络,其输出为一个金字塔heatmap的集合,而每个heatmap的尺寸为HxW,维度为K,其中K为类别数量。如果给定真实框为 (x1,y1,x2,y2)
,首先将其映射目标金字塔,即:

而正样本区域(fovea)被设计为原区域的一个衰减区域,这个与DenseBox的设置一样,这样设置的原因是为了防止语义区域的相互交叠!其中
 为缩放因子,正样本区域的每一个cell都被指定相对应的类别标签。对于负样本,我们也设置了一个缩放因子
为缩放因子,正样本区域的每一个cell都被指定相对应的类别标签。对于负样本,我们也设置了一个缩放因子
 ,用于生成负样本区域。如果一个cell没有被分配,那么就是ignore区域不参与反向传播。这样的设置和FSAF又很像!由于样本间不均衡,所以我们使用focal loss来优化。Fovea区域计算公式如下:
,用于生成负样本区域。如果一个cell没有被分配,那么就是ignore区域不参与反向传播。这样的设置和FSAF又很像!由于样本间不均衡,所以我们使用focal loss来优化。Fovea区域计算公式如下:
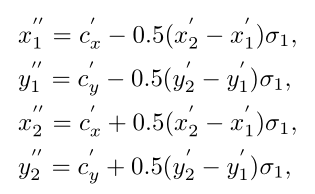
如下图所示,通过缩放因子的设置,划分成正负区域和忽略区域。可以看到,正样区域相对于整张feature map来说,所占的比重较小,在训练中就会让正负样本失衡,所以分类的loss为focal loss

4)loss function
采用分类+回归损失(边框预测)
a.分类损失
分类采用focal loss的,具体的实现论文没有提及,猜测是每个类(分类分支的每个特征图,注意正负以及忽略区域)分别做二分类,然后采用sigmod。
b.回归分支
与DenseBox和UnitBox不同,FoveaBox并不是直接学习目标中心到四个边的距离,而是去学习一个预测坐标与真实坐标的映射关系,假如真实框为
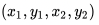 ,我们目标就是学习一个映射关系
,我们目标就是学习一个映射关系
 ,这个关系是中心点与边框坐标的关系,如下
,这个关系是中心点与边框坐标的关系,如下
接着使用简单的L1损失来进行优化,其中为
 一个归一化因子,将输出空间映射到中心为1的空间,使得训练稳定。最后使用log空间函数进行正则化。
一个归一化因子,将输出空间映射到中心为1的空间,使得训练稳定。最后使用log空间函数进行正则化。
5)trics
无
4、结果

通过上图我们可以看到,相比于anchor-based的,anchor-free的算法对于目标的尺度更具有鲁棒性,并且完全不需要去费劲的设计anchor的尺寸。
接下来是AP和AR的比较:
1)FoveaBox与RetinaNet的比较

2)与ASFA(CVPR2019)的比较
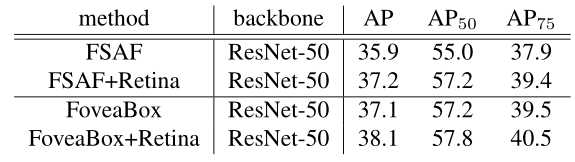
3)与其他SOTA方法的对比(coco test-dev)

F、CenterNet(Object as Points 已开源)
1、主要贡献
1)该算法去除低效复杂的Anchors操作,进一步提升了检测算法性能;
2)该算法直接在heatmap图上面执行了过滤操作,去除了耗时的NMS后处理操作,进一步提升了整个算法的运行速度;
3)该算法不仅可以应用到2D目标检测中,经过简单的改变它还可以应用3D目标检测与人体关键点检测等其它的任务中,即具有很好的通用性。
2、主要思路

CenterNet将目标检测问题转换成中心点预测问题,即用目标的中心点来表示该目标,并通过预测目标中心点的偏移量与宽高来获取目标的矩形框。
模块包含3个分支,具体包括中心点heatmap图分支、中心点offset分支、目标大小分支:
1)heatmap图分支包含C个通道,每一个通道包含一个类别,heatmap中白色的亮区域表示目标的中心 点位置;
2)中心点offset分支用来弥补将池化后的低heatmap上的点映射到原图中所带来的像素误差;
3)目标大小分支用来预测目标矩形框的w与h偏差值。
CenterNet网络的推理阶段的实现步骤如下所述:
步骤1-输入一张图像,将图像尺寸处理成512*512大小后作为网络的输入;
步骤2-执行网络的前向计算将得到3个输出:[1,80,128,128]大小的heatmap;[1,2,128,128]大小的尺寸预测,;[1,2,128,128]大小的offset预测;
步骤3-heatmap会经过一个sigmoid函数使得范围为0到1,接下来对heatmap执行一个最大池化操作(kernel设置为3,stride设置为1,pad设置为1,这一步其实是在做重复框过滤,这也是为什么后续不再需要NMS操作的一个重要原因,毕竟这里3✖️3大小的kernel加上特征图和输入图像之间的stride=4,相当于输入图像中每12✖️12大小的区域都不会有重复的中心点,想法非常简单有效)。然后再基于heatmap选择top K个得分最高的点(默认K=100,这样就确定了100个置信度最高的预测框的中心点位置了,这一步也会去掉一定的重复框)。可以设定一个置信度阈值,高于阈值的才输出;
步骤4-通过输出的尺寸预测值和offset确定预测框的大小。得到的预测框信息都是在128✖️128大小的特征图上,因此最后将预测框信息再映射到输入图像上就得到最终的预测结果。
3、具体细节
1)input
512*512
输入图片需要裁减到512*512大小,
即长边缩放到512,短边补0
,具体的效果如下图所示,由于原图的W>512,因而直接将其缩放为512;由于原图的H<512,因而对其执行补0操作;

2)backbone
论文中尝试了Hourglass、ResNet与DLA3种网络架构,各个网络架构的精度及帧率为:
Resnet-18 with up-convolutional layers:28.1% coco and 142 FPS
DLA-34:37.4% COCOAP and 52 FPS
Hourglass-104:45.1% COCOAP and 1.4 FPS

3)neck & head
该模块包含3个分支,具体包括中心点heatmap图分支、中心点offset分支、目标大小分支。
heatmap图分支包含C个通道,每一个通道包含一个类别,heatmap中白色的亮区域表示目标的中心点位置;
中心点offset分支用来弥补将池化后的低heatmap上的点映射到原图中所带来的像素误差;
目标大小分支用来预测目标矩形框的w与h偏差值。
a.
Heatmap表示分类信息,每一个类别将会产生一个单独的Heatmap图。对于每张Heatmap图而言,当某个坐标处包含目标的中心点时,则会在该目标处产生一个关键点,我们利用高斯圆(
只要预测的corner点在中心点的某一个半径r内,而且该矩形框与gt_bbox之间的IoU大于0.7时,我们将这些点处的值设置为一个高斯分布的数值,而不是数值0。
)来表示整个关键点,下图展示了具体的细节。

生成Heatmap图的具体步骤如下所示:
步骤1-将输入的图片缩放成512*512大小,对该图像执行R=4的下采样操作之后,获得一个128*128大小的Heatmap图;
步骤2-将输入图片中的Box缩放到128*128大小的Heatmap图上面,计算该Box的中心点坐标,并执行向下取整操作,并将其定义为point;
步骤3-根据目标Box大小来计算高斯圆的半径R;
关于高斯圆的半径确定,主要还是依赖于目标box的宽高, 实际情况下通常会取IOU=0.7,即下图中的overlap=0.7作为临界值,然后分别计算出三种情况的半径,取最小值作为高斯核的半径R,具体的实现细节如下图所示:
(1)情况1-预测框pred_bbox包含gt_bbox框,对应于下图中的第1种情况,将整个IoU公式展开之后,成为一个二元一次方程的求解问题。
(2)情况2-gt_bbox包含预测框pred_bbox框,对应于下图中的第2种情况,将整个IoU公式展开之后,成为一个二元一次方程的求解问题。
(3)情况3-gt_bbox与预测框pred_bbox框相互重叠,对应于下图中的第3种情况,将整个IoU公式展开之后,成为一个二元一次方程的求解问题。

步骤4-在128*128大小的Heatmap图上面,以point为中心点,半径为R计算高斯值,point点处数值最大,随着半径R的增加数值不断减小;

上图
展示了一个样例,左边表示经过裁剪之后的512512大小的输入图片,右边表示经过高斯操作之后生成的128128大小的Heatmap图。由于图中包含两只猫,这两只猫属于一个类别,因此在同一个Heatmap图上面生成了两个高斯圆,高斯圆的大小与矩形框的大小有关。
4)loss function
整体loss 由三部分组成:L k 表示 heatmap中心点损失,Loff 表示目标中心点偏移损失,L size 表示目标长宽损失函数。

a. Heatmap 损失函数

N是输入图片中目标的个数,也是heatmap中关键点的个数。上式中的
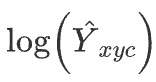 和
和
 是交叉熵损失函数,
和
是交叉熵损失函数,
和
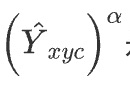 是focal loss项,
压制半径范围内的损失,因为这些位置里物体的bounding box中心很近。
是focal loss项,
压制半径范围内的损失,因为这些位置里物体的bounding box中心很近。
b.offset 损失函数
其中O ^ p ~
表示网络预测的偏移量数值,p表示图像中心点坐标,R表示Heatmap的缩放因子,
p
~
表示缩放后中心点的近似整数坐标,整个过程利用L1 Loss计算正样本块的偏移损失。由于骨干网络输出的 feature map 的空间分辨率是原始输入图像的四分之一。即输出 feature map 上的每一个像素点对应到原始图像的一个4x4 区域,这会带来较大的误差,因此引入了偏置的损失值。
假设目标中心点p为(125, 63),由于输入图片大小为512*512,缩放尺度R=4,因此缩放后的128x128尺寸下中心点坐标为(31.25, 15.75), 相对于整数坐标(31, 15)的偏移值即为(0.25, 0.75)。
c. 目标长宽损失函数
其中N表示关键点的个数,Sk表示目标的真实尺寸,S ^ p k
表示预测的尺寸,整个过程利用L1 Loss来计算正样本块的长宽损失。
5)trics
a. 如果两个物体的heat map有交集,那么该处的值,取最大的那个。
b. 如果两个物体的中心点重合,该算并未解决,在论文评测集中(coco数据集),该情况只占0.1%。
4、结果

上表展示了CenterNet目标检测在COCO验证集上面的精度与速度。第1行展示了利用Hourglass-104作为基准网络后不仅能够获得40.4AP,而且可以获得14FPS的速度;第2行展示了利用DLA-34作为基准网络后获得的AP与FPS;第3行与第4行分别展示了ResNet-101与ResNet-18基准网络在COCO验证集上面的效果。通过观察我们可以发现,基于DLA-34的基准网络能够在精度与速度之间达到一个折中。
基于密集检测总结
FSAF、FCOS、FoveaBox的异同点:
1.都利用FPN来进行多尺度目标检测。
2.都将分类和回归解耦成2个子网络来处理。
3.都是通过密集预测进行分类和回归的。
4.FSAF和FCOS的回归预测的是到4个边界的距离,而FoveaBox的回归预测的是一个坐标转换。
5.FSAF通过在线特征选择的方式,选择更加合适的特征来提升性能,FCOS通过center-ness分支剔除掉低质量bbox来提升性能,FoveaBox通过只预测目标中心区域来提升性能。
(DenseBox、YOLO)和(FSAF、FCOS、FoveaBox)的异同点:
1.都是通过密集预测进行分类和回归的。
2.(FSAF、FCOS、FoveaBox)利用FPN进行多尺度目标检测,而(DenseBox、YOLO)只有单尺度目标检测。
3.(DenseBox、FSAF、FCOS、FoveaBox)将分类和回归解耦成2个子网络来得到,而(YOLO)分类和定位统一得到。
以下为基于关键点估计的anchor free检测
A、CornerNet(开源)
1、主要贡献
1)
设计了一个针对top-left和bottom-right的heatmap,找出那些最有可能是top-left和bottom-right的点,并使用一个分支输出embedding vector,帮助判断top-left与bottom-right之间的匹配关系。
2)
提出了Corner Pooling,因为检测任务的变化,传统的Pooling方法并不是非常适用该网络框架。(后面介绍)
2、主要思路

网络有两个分支,一个分支预测Top-left Corners,另一个预测Bottom-right corners。
每个分支有三个线路,heatmaps预测哪些点最有可能是Corners点,embeddings主要预测每个点所属的目标(解决如何匹配一个物体的左上角点和右下角点),最后的offsets用于对点的位置进行修正。
在检测角点部分,CornerNet产生两个热点图,分别对应左上角和右下角。热点图可以表示不同类别的角点在图中的位置并且对每个角点附上一个置信度分数,此外还产生一个嵌入向量和偏移量,嵌入向量用来确认左上角和右下角的两个点是否属于同一个物体,偏移量对角点的位置进行微调。在生成目标候选框阶段,排名top-k的左上角和右下角角点被从heatmaps中选择出来,然后,计算一对角点间的嵌入向量的距离,如果距离小于预设的阈值,就认为这两个点属于同一个物体,就会根据这两个角点生成一个bounding box,同时,根据两个角点的得分计算一个平均分数作为该bounding box的得分。
3、具体细节
1)input
511 × 511 (四倍下采样后输出为128*128)
2)backbone
hourglass网络(修改过,且没有pre train)
3)neck & head
分四个部分介绍:heatmap分支(预测类目)、offset分支(精修角点偏移量)、embedding分支(匹配上下角点)、Corner Pooling
a. Heatmaps与Reduce penalty策略
每个Heatmaps都有C个Channels,其中C是类别数量,不含BG类,heatmap在gt位置处的值最大,其它位置,越靠近gt值越大。实现就是构造高斯函数,中心就是gt位置,离这个中心越远衰减得越厉害,即:

sigma是半径的三分之一,半径的求法:是使得构成的bbox与GT的iou 的最小值大于0.3。
b. offset分支
作者预测出来的featmap和原图的输入尺寸是不同的,假设下采样因子是n,那么原来的位置(x, y)到feature map上对应的位置是([x/n], [y/n]),其中[ ]代表取整操作,在remap回原图位置时候,无疑会产生一定误差,offsets路线正是在这个基础上修正位置的,收敛目标表示为:
c.
embedding分支
这个分支的主要作用是用来group corners,作者使用的是1维的embeddings……换而言之,给不同的目标分配不同的id,比如1,2,3……然后在预测的时候,如果top-left的corner和bottom-right的corner的embedding值特别接近,比如一个是1.2另一个是1.3,那么这两个很有可能属于一个目标;如果是1.2和2.3这样差距很大的,则一般就是两个不同的目标。要想实现这样的预测,必须做到两点:
·同一个目标的两个corners预测出来的embedding值应当尽可能地接近
-
·不同目标预测出来的embedding值应当尽可能地远
d.
Corner Pooling
我们常用的max pooling一般以当前位置为中心,大小是3x3的kernel,感受野自然也是以当前位置为中心的。但是corner的检测相对于这样一个方形的感受野,更关心单一方向的……以top-left为例,它更关心的是水平向右和垂直向下这两个方向上的信息,考虑到这个原因,作者提出了一种Corner Pooling,原理如下:

例如feature map的大小是10x10,现在的一个点是(2,1),那么top-left corner pooling就是计算(2,1)到(2,10)这条线上的最大值和(2,1)到(10,1)这条线上的最大值,并将它们进行叠加。实际计算的时候,可以通过反向计算来实现,示意图如下:

以上图2,1,3,0,2这一行为例,最后的2保持不变,倒数第二个是max(0,2)=2,因此得到2,2。然后倒数第三个为max(3,2)=3……依次类推。
实现个人觉得就是通过一维max pooling,公式如下:

另外,作者在Backbone和最后的predict的预测结构上使用了resnet的残差结构作为基础进行更改,具体做法是改了第一个3x3卷积操作,最后的预测结构为:

4)loss function
分为三部分:heatmap分支(预测类目)、embedding分支(匹配上下角点)、offset分支(精修角点偏移量)
a. Heatmaps

其中p是预测值,y是真实值,这个函数是在focal loss的基础上修改的来。
b. offset分支

c.
embedding分支

其中etk和ebk是top-left和bottom-right两个分支预测出来的embeddings,ek是两者的平均值,Lpull起到的作用就是把同一个目标的预测值拉近,而Lpush起到的作用就是把不同目标的embeddings值推远。
整体损失如下:
其中超参数:阿尔法和贝塔为0.1,伽马为1。
5)trics
4、结果
在测试的时候,会使用3x3的max pooling对heatmap进行非极大值的抑制,并取heatmap上的前100个结果,然后按照L1距离进行匹配;注意的是匹配是在每个类别之间的,不同类别或者L1距离过大的一般都会不考虑在内,作者最后的实验结果如下:

在single-stage方法中算是非常好的结果了,和很多two-stages方法也有一战之力。
B、CenterNet(开源)
需要注意这个centerNet 是CornerNet的改进版,原论文名为:CenterNet: Keypoint Triplets for Object Detection
1、主要贡献
提出了两个方法来丰富中心点和角点的信息:
center pooling:在分支中预测中心关键点。中心池化能够帮助中心关键点在一个object中变得更可识别,
来帮助筛选候选框。
cascade Corner pooling:在CornerNet Corner pooling的基础上,使得Corner具有感知内部信息的能力。
2、主要思路

1)使用Hourglass作为backbone提取图像的feature;
2)使用Cascade Corner Pooling模块提取图像的Corner heatmaps,并采用与CornerNet中一样的方法,根据左上角和右下角点,得到物体的bounding box。
所有bounding box都定义一个中心区域(后面具体细节-neck&head 介绍)

3)使用Center Pooling模块,提取图像的Center heatmap,根据Center map得到所有的物体中心点。
具体为:
在center heatmap中,根据heatmap的响应值,选择top-k个center keypoints,
使用对应的offset map对这些keypoint进行微调,得到更加精确地keypoint位置。
4)使用物体中心点对2)中提取到的bounding box进行进一步过滤:如果box的中间区域没有中心点存在,则认为此box不可靠;如果某个center点落在了这个中心区域,则此bounding box保留,其bbox的score变为三个点的均值。
3、具体细节
1)input
544*511(四倍下采样后特征图为128*128)
2)backbone
hourglass
3)neck & head
这里需要注意如下概念:center pooling、cascade Corner pooling、中心区域设置。
a.Center pooling
物体的绝对几何中心传达的信息并不一定是最准确的,比如对人识别来说,脸部是重要的信息来源,但是人作为一个整体目标的中心点却不在脸部。为了解决这个问题,提出了center pooling来捕捉更丰富的视觉信息。
如下图所示是Center pooling的过程,具体做法为:通过网络主干得到一个feature map,逐像素检验是否为中心点,方法为:分别在水平和垂直方向上找到最大值并进行相加,通过这种操作,center pooling能够帮助我们更好的找到中心点。
备注:其分支与CornerNet的分支类似,只不过裁减掉了embed分支,heatmap为类别数,offset特征图为两层。

实现方式:
结合Corner pooling来轻松实现,如下图a,比如我们要选择水平方向上的最大值,只需要将left pooling和right pooling串联在一起。

b.Cascade corner pooling
Corner也就是角点,通常是游离于真正的物体之外,,Corner pooling旨在找到在垂直和水平方向上的最大值,以此来决定Corner位置,然而对边界很敏感,想让Corner“看到”物体内部的信息,就是cascade Corner pooling:首先沿着边界找到一个最大值,然后在最大值的方向“往里看”,找到一个内部最大值。如上图b。
c.中心区域
中心区域的大小设置至关重要。举例来说,对小的bounding box来说,中心区域越小,召回率(recall)会越低,因为有很多正例会被判为负例;对大的bounding box来说,中心区域越大,查准率(precision)会越低,因为很多负例会被判为正例;因此本文提出了尺度感知的中心区域来自适应bounding box的大小,在大的bounding box中生成相对较小的中心区域,这样可以有效地提高查准率(precision);同样的,在小的bounding box中生成相对较大的中心区域,可以有效提高召回率(recall)。

其中,tlx,tly为top-left Corner的坐标;brx,bry为bottom-right的坐标;ctlx,ctly为中心区域的左上角坐标;cbrx,cbry为中心区域右下角的坐标。n是一个奇数,决定了中心区域的尺寸,
确定中心区域的方法非常简单,就是讲bbox均分成9份(n=3)或者25份(n=5),作者说当bbox的size大于150时,n取5, 小于150时,n取3。
最终的图示效果如下:实心矩形表示bounding box,阴影部分表示中心区域。

4)loss function
其中,前两项分别是检测Corner点和center点带来的损失,用的是focal loss;相应的后面跟CornerNer类似,利用一个pull一个push来正确分类角点;最后两个是利用L1损失对角点和中心点位置进行微调。loss的具体含义原文没有提及,主要是在Cornernet上的改进,参考CornerNet。
超参数设置:
α,β, γ=0.1,0.1,1。
5)trics
4、结果
效果很牛,是目前anchor free和one-stage方法中效果最好的。

C、ExtremeNet(已开源)
1、主要贡献
提出检测极值点代替检测角点,
通过几何关系组合来直接得到检测结果。
解决如下问题:
1)从自下而上的检测方法来说,相比于CornerNet,检测的角点往往是位于目标之外,检测更难。
2)标注难度:人工标注极值点比标注监测框更容易,耗时更短。
2、主要思路
CornerNet基础上的改进做法,预测物体的4个极点(extreme point)和1个中心点,根据几何的分布来进行组合,由极点构造出预测框,得到预测结果。

3、具体细节
1)input
511*511
2)backbone
Hourglass-104
(
实际上该网络的计算量非常大,256x256的输入下大约有140T,同等条件下,ResNet50约8T,这也导致了整体的速度很慢。)
3)neck & head
经过预测头输出5个 H*W
热力图,对应4个极点和中心点,每个热力图通道数为 C
,对应物体类别数。
另外预测产生4个通道为2的offset输出,对应4个极点,用于对极点坐标下采样精度损失的微调。其不区分类别,且中心点不需要微调。
使用
Center Grouping过程将4个极点以及中心点进行组合。


4)loss function
ExtremeNet的loss计算也沿用了CornerNet中的一些做法,计算focal loss变形的分类损失
和下采样导致的定位精度损失
,而没有CornerNet中Embedding的过程。


5)
trics
a. 训练样本产生
使用COCO数据集来进行训练,由于没有直接的极点标签,因此使用了分割的mask标签,计算得到极点,然后使用极点进行训练。
(
ExtremeNet的训练数据集与普通的目标检测数据集不太一致,或者说训练数据中包含的信息是更多的,即极点比角点有更多的语义信息。
从实际运用上来说,人工标注极点的效率要比角点高,从使用上来看,还是有优势的。
)
b.
Ghost box suppression
由于极点的组合是穷举的过程,且只根据极点和中心点的坐标关系来确定,会引入一种假阳性结果。如三个同类别小物体并列出现时,左边物体的左极点和右边物体的右极点经过坐标计算后,为中心物体的中心点,也会有较高的响应,结果就是判断产生了一个同时包含三个小物体的长物体。

抑制的做法为:如果一个目标框中包含的所有目标框的分数和超过了目标框自身分数的3倍,则目标框自身的分数除以2。
-
这里的3倍是一个下限,如果包含更多的物体(如5个),同样会进行抑制。
-
除以2降低大预测框的分数,在之后的NMS过程中可以过滤掉大的目标框。
c.
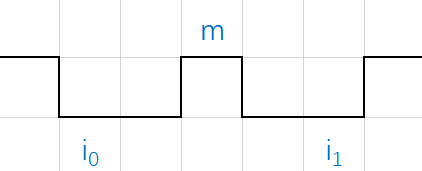
Edge aggregation(目前未理解)
预测极点还有一个问题就是,如果物体有一条和坐标轴平行的边,按照设计,应该整条边上的点都会产生极点的响应,问题是可能每个点的响应可能比较低,或者低于旋转一定角度后唯一的极点,Edge aggregation是打算增强平行边的响应,来提高预测效果。


4、结果
消融实验的结果:

-
其中第1行为标准的ExtremeNet,第2行的multi-scale为对输入图像进行多尺度增广。
-
第二部分中,去掉Center grouping时,将组合过程替换为类似CornerNet的Embedding,性能下降了2.1%mAP。
-
Edge aggregation和Ghost removal对于大物体的提升比较明显,对小物体影响很小。
-
第三部分是错误分析,用ground truth替换预测结果。替换center后的提升不是特别大,说明center特征的提取还可以。替换extreme后,以及同时替换center,带来了很大提升,说明对于extreme的提取、极点中心点的组合过程还是有很大的提升空间。
和其他目标检测框架的比较:

参考链接:
6、13种anchor free综述:
https://bbs.cvmart.net/articles/442/zhong-bang-13-pian-ji-yu-anchor-free-de-mu-biao-jian-ce-fang-fa
8、densebox:
https://zhuanlan.zhihu.com/p/40221183
9、yolov1:
https://zhuanlan.zhihu.com/p/70387154
10、yolov1损失函数;
https://blog.csdn.net/qq_38236744/article/details/106724596
16、feveabox:
https://zhuanlan.zhihu.com/p/63190983
17、feveabox:
https://zhuanlan.zhihu.com/p/68075721
18、centernet(object as point)详细:
https://blog.csdn.net/WZZ18191171661/article/details/113753991
19、centernet(object as point)详细:
https://mp.weixin.qq.com/s/hlc1IKhKLh7Zmr5k_NAykw
20、centernet(object as point)详细:
https://zhuanlan.zhihu.com/p/66048276
21、centernet(object as point)讲解高斯核半径:
https://zhuanlan.zhihu.com/p/96856635
22、CornerNet:
https://zhuanlan.zhihu.com/p/44449116
23、 cornetNet:
https://arxiv.org/abs/1808.01244
24、CornerNet:
https://zhuanlan.zhihu.com/p/53407590
25、CornerNet:
https://blog.csdn.net/gbyy42299/article/details/89878489
26、centernet:
https://zhuanlan.zhihu.com/p/66326413
27、centernet:
https://zhuanlan.zhihu.com/p/60072845
28、extremeNet:
https://zhuanlan.zhihu.com/p/117597564
29、extremeNet:
https://zhuanlan.zhihu.com/p/57254154
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/778221
推荐阅读
相关标签

