- 1探秘亚马逊云科技海外服务器 | 解析跨境云计算的前沿技术与应用
- 2Leetcode Solutions - Part 2_let x1, x2 are solutions to (at a + 碌ii)x = 鈭扐t r,
- 3dubbo源码分析第十六篇一dubbo集群容错策略-BroadcastCluster广播_dubbo broadcast cluster
- 4简单易懂深入PyTorch中RNN、LSTM和GRU使用和理解
- 5《成为一名优秀的架构师:从基础到实践》_现代c++软件架构:方法与实践 pdf
- 6(附源码)基于Java SpringBoot的电影院管理系统设计与实现 毕业设计 011633_电影管理系统java源码
- 7黑马程序员——Objective-C——定义类、方法、创建对象
- 8HTML小游戏13 —— 仿《神庙逃亡》3D风格跑酷游戏《墓地逃亡》(附完整源码)_html神庙逃亡制作代码
- 9chatgpt赋能python:Python量化交易:为什么Python是最好的选择_pyalgotrade optimizer cuda
- 10二战华为成功上岸,准备了小半年,要个27k应该也算不上很高吧~
yolov8实战第四天——yolov8图像分类 && ResNet50图像分类(保姆式教程)
赞
踩
yolov8实战第一天——yolov8部署并训练自己的数据集(保姆式教程)_yolov8训练自己的数据集-CSDN博客在前几天,我们使用yolov8进行了部署,并在目标检测方向上进行自己数据集的训练与测试,今天我们训练下yolov8的图像分类,看看效果如何,同时使用resnet50也训练一个分类模型,看看哪个效果好!
图像分类是指将输入的图像自动分类为不同的类别。它是计算机视觉领域的一个重要应用,可以用于人脸识别、物体识别、场景分类等任务。
通常情况下,图像分类的流程如下:
- 收集和准备数据集:收集与任务相关的图像数据,并将其打上标签。
- 定义模型:选择一种适合于你的任务的深度学习模型,例如卷积神经网络(CNN)。
- 训练模型:使用收集到的数据集对模型进行训练,通过反向传播算法来更新模型参数,使其可以根据输入图像进行正确的分类。
- 评估模型性能:使用测试集对已经训练好的模型进行评估,比较模型预测结果与真实标签之间的差异,从而评估模型的性能。
- 使用模型进行预测:使用已经训练好的模型对新的图像进行分类预测。
在实际应用中,可以使用各种深度学习框架(例如 TensorFlow、PyTorch、Keras 等)来构建图像分类模型,并使用各种数据增强技术(例如旋转、缩放、裁剪等)来增加数据集的多样性和数量。
如果你想学习如何使用深度学习框架来构建图像分类模型,可以参考一些在线教程、书籍或者 MOOC。
一、yolov8图像分类
1.模型选型
下载yolov8分类模型。
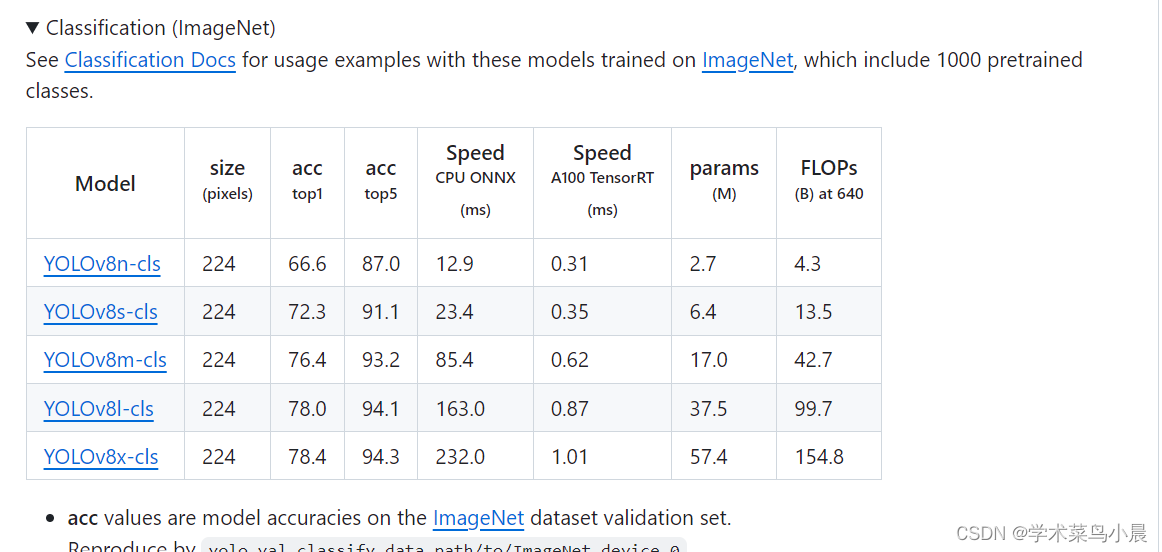
分别使用模型进行测试:
yolov8n-cls效果:

yolov8m-cls效果:

总结:n效果不咋地,还是得使用m进行后续训练工作。
2.数据集准备
同目标检测,还是放在datasets下。
直接改成这个,省去分数据集操作。
3.训练
yolo classify train data=./datasets/skin-cancer-detection model=yolov8n-cls.pt epochs=100
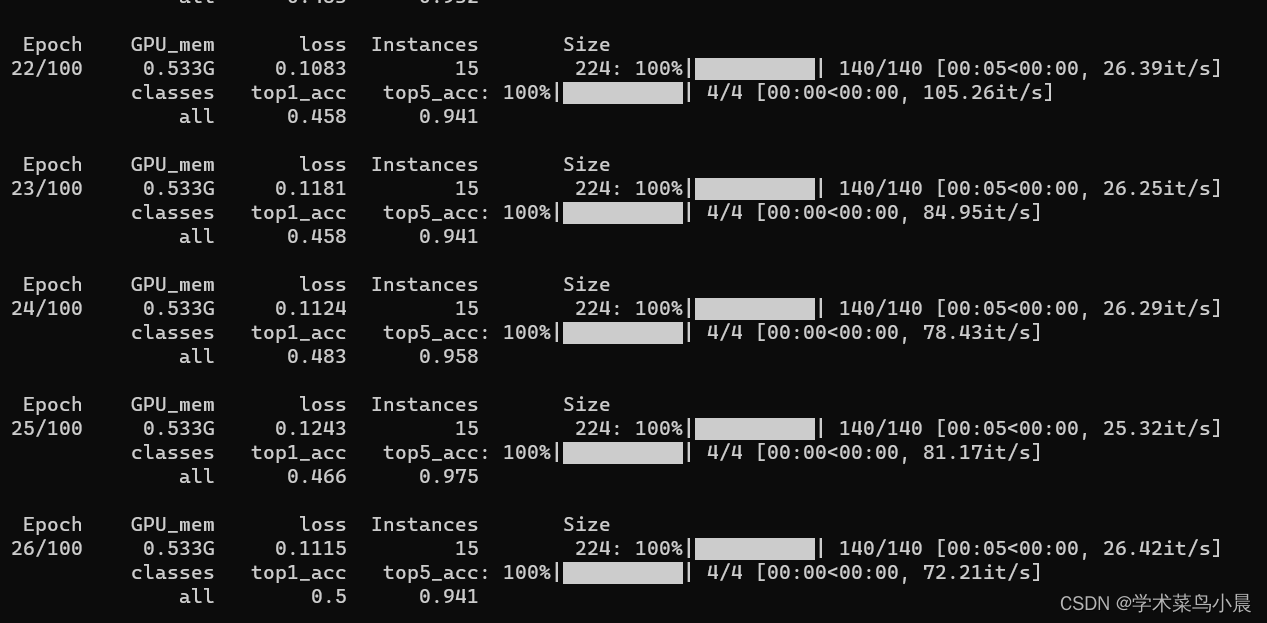
测试:
yolo classify predict model=runs/classify/train4/weights/best.pt source='./datasets/skin-cancer-detection/train/nevus' 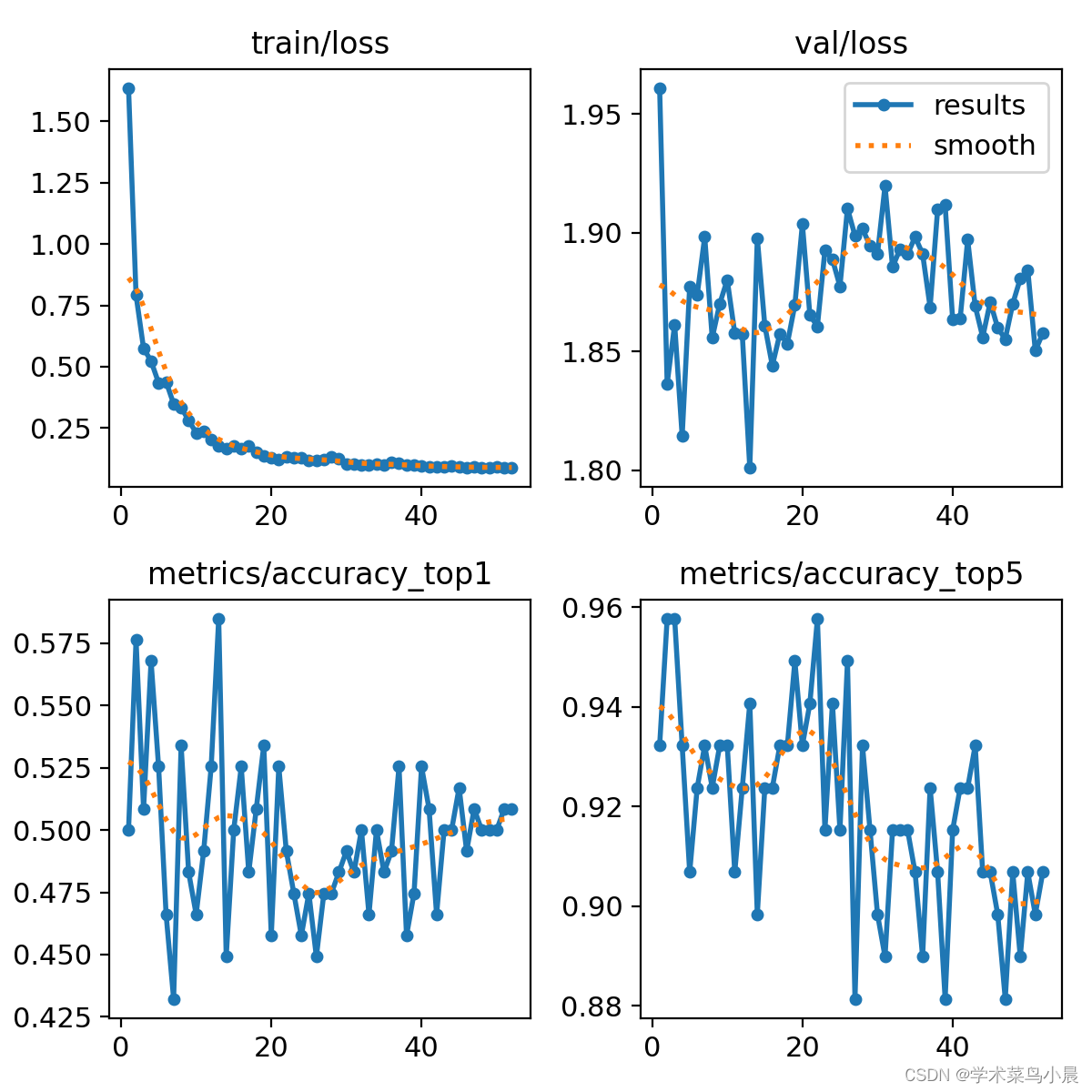
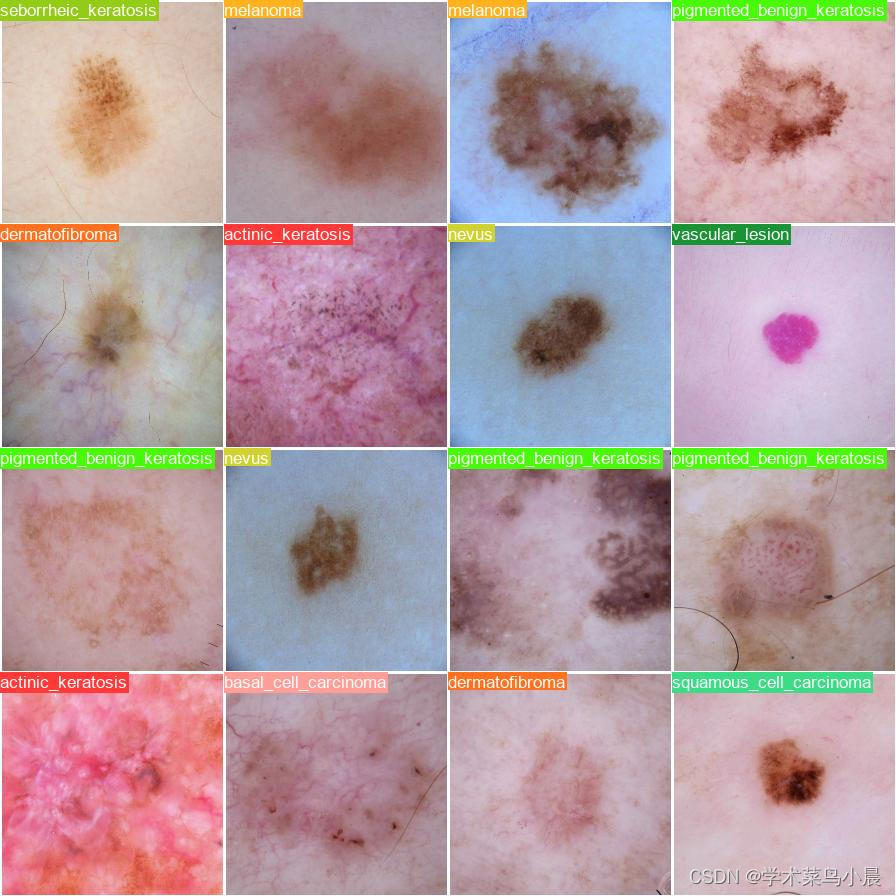
label:
pred:
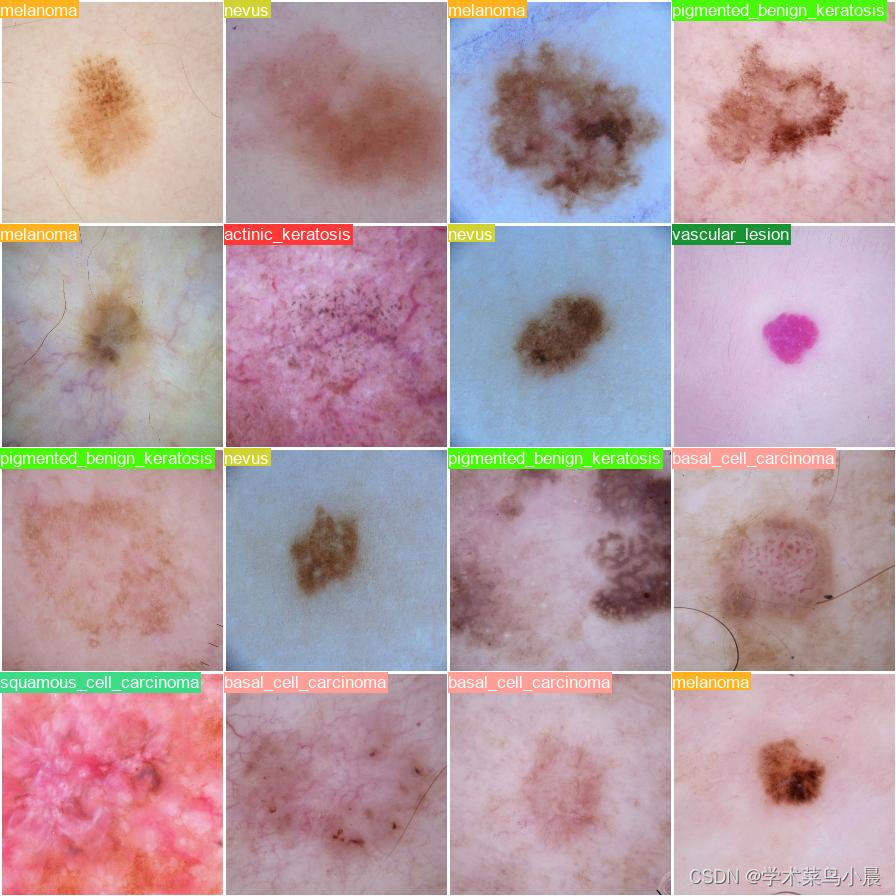
总结:数据集比较小,yolov8效果不太好。
二、resnet50图像分类
Resnet50 网络中包含了 49 个卷积层、一个全连接层。如图下图所示,Resnet50网络结构可以分成七个部分,第一部分不包含残差块,主要对输入进行卷积、正则化、激活函数、最大池化的计算。第二、三、四、五部分结构都包含了残差块,图 中的绿色图块不会改变残差块的尺寸,只用于改变残差块的维度。在 Resnet50 网 络 结 构 中 , 残 差 块 都 有 三 层 卷 积 , 那 网 络 总 共 有1+3×(3+4+6+3)=49个卷积层,加上最后的全连接层总共是 50 层,这也是Resnet50 名称的由来。网络的输入为 224×224×3,经过前五部分的卷积计算,输出为 7×7×2048,池化层会将其转化成一个特征向量,最后分类器会对这个特征向量进行计算并输出类别概率。

运行train.py即可。
train.py
- import torch
- from torchvision import datasets, models, transforms
- import torch.nn as nn
- import torch.optim as optim
- from torch.utils.data import DataLoader
- import time
-
- import numpy as np
- import matplotlib.pyplot as plt
- import os
- from tqdm import tqdm
-
-
- # 一、建立数据集
- # animals-6
- # --train
- # |--dog
- # |--cat
- # ...
- # --valid
- # |--dog
- # |--cat
- # ...
- # --test
- # |--dog
- # |--cat
- # ...
- # 我的数据集中 train 中每个类别60张图片,valid 中每个类别 10 张图片,test 中每个类别几张到几十张不等,一共 6 个类别。
-
- # 二、数据增强
- # 建好的数据集在输入网络之前先进行数据增强,包括随机 resize 裁剪到 256 x 256,随机旋转,随机水平翻转,中心裁剪到 224 x 224,转化成 Tensor,正规化等。
- image_transforms = {
- 'train': transforms.Compose([
- transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
- transforms.RandomRotation(degrees=15),
- transforms.RandomHorizontalFlip(),
- transforms.CenterCrop(size=224),
- transforms.ToTensor(),
- transforms.Normalize([0.485, 0.456, 0.406],
- [0.229, 0.224, 0.225])
- ]),
- 'valid': transforms.Compose([
- transforms.Resize(size=256),
- transforms.CenterCrop(size=224),
- transforms.ToTensor(),
- transforms.Normalize([0.485, 0.456, 0.406],
- [0.229, 0.224, 0.225])
- ])
- }
-
- # 三、加载数据
- # torchvision.transforms包DataLoader是 Pytorch 重要的特性,它们使得数据增加和加载数据变得非常简单。
- # 使用 DataLoader 加载数据的时候就会将之前定义的数据 transform 就会应用的数据上了。
- dataset = 'skin-cancer-detection'
- train_directory = './skin-cancer-detection/train'
- valid_directory = './skin-cancer-detection/val'
-
- batch_size = 32
- num_classes = 9 #分类种类数
- print(train_directory)
- data = {
- 'train': datasets.ImageFolder(root=train_directory, transform=image_transforms['train']),
- 'valid': datasets.ImageFolder(root=valid_directory, transform=image_transforms['valid'])
- }
- print("训练集图片类别及其对应编号(种类名:编号):",data['train'].class_to_idx)
- print("测试集图片类别及其对应编号:",data['valid'].class_to_idx)
-
-
- train_data_size = len(data['train'])
- valid_data_size = len(data['valid'])
-
- train_data = DataLoader(data['train'], batch_size=batch_size, shuffle=True, num_workers=0)
- valid_data = DataLoader(data['valid'], batch_size=batch_size, shuffle=True, num_workers=0)
-
- print("训练集图片数量:",train_data_size, "测试集图片数量:",valid_data_size)
-
- # 四、迁移学习
- # 这里使用ResNet-50的预训练模型。
- #resnet50 = models.resnet50(pretrained=True)
- resnet50 = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V1)
-
-
-
- # 在PyTorch中加载模型时,所有参数的‘requires_grad’字段默认设置为true。这意味着对参数值的每一次更改都将被存储,以便在用于训练的反向传播图中使用。
- # 这增加了内存需求。由于预训练的模型中的大多数参数已经训练好了,因此将requires_grad字段重置为false。
- for param in resnet50.parameters():
- param.requires_grad = False
-
- # 为了适应自己的数据集,将ResNet-50的最后一层替换为,将原来最后一个全连接层的输入喂给一个有256个输出单元的线性层,接着再连接ReLU层和Dropout层,然后是256 x 6的线性层,输出为6通道的softmax层。
- fc_inputs = resnet50.fc.in_features
- resnet50.fc = nn.Sequential(
- nn.Linear(fc_inputs, 256),
- nn.ReLU(),
- nn.Dropout(0.4),
- nn.Linear(256, num_classes),
- nn.LogSoftmax(dim=1)
- )
-
- # 用GPU进行训练。
- resnet50 = resnet50.to('cuda:0')
-
- # 定义损失函数和优化器。
- loss_func = nn.NLLLoss()
- optimizer = optim.Adam(resnet50.parameters())
-
- # 五、训练
- def train_and_valid(model, loss_function, optimizer, epochs=25):
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- history = []
- best_acc = 0.0
- best_epoch = 0
-
- for epoch in range(epochs):
- epoch_start = time.time()
- print("Epoch: {}/{}".format(epoch+1, epochs))
-
- model.train()
-
- train_loss = 0.0
- train_acc = 0.0
- valid_loss = 0.0
- valid_acc = 0.0
-
- for i, (inputs, labels) in enumerate(tqdm(train_data)):
- inputs = inputs.to(device)
- labels = labels.to(device)
-
- #因为这里梯度是累加的,所以每次记得清零
- optimizer.zero_grad()
- outputs = model(inputs)
- loss = loss_function(outputs, labels)
- print("标签值:",labels)
- print("输出值:",outputs)
- loss.backward()
- optimizer.step()
- train_loss += loss.item() * inputs.size(0)
- ret, predictions = torch.max(outputs.data, 1)
- correct_counts = predictions.eq(labels.data.view_as(predictions))
- acc = torch.mean(correct_counts.type(torch.FloatTensor))
- train_acc += acc.item() * inputs.size(0)
-
- with torch.no_grad():
- model.eval()
-
- for j, (inputs, labels) in enumerate(tqdm(valid_data)):
- inputs = inputs.to(device)
- labels = labels.to(device)
- outputs = model(inputs)
- loss = loss_function(outputs, labels)
- valid_loss += loss.item() * inputs.size(0)
- ret, predictions = torch.max(outputs.data, 1)
- correct_counts = predictions.eq(labels.data.view_as(predictions))
- acc = torch.mean(correct_counts.type(torch.FloatTensor))
- valid_acc += acc.item() * inputs.size(0)
-
- avg_train_loss = train_loss/train_data_size
- avg_train_acc = train_acc/train_data_size
-
- avg_valid_loss = valid_loss/valid_data_size
- avg_valid_acc = valid_acc/valid_data_size
-
- history.append([avg_train_loss, avg_valid_loss, avg_train_acc, avg_valid_acc])
-
- if best_acc < avg_valid_acc:
- best_acc = avg_valid_acc
- best_epoch = epoch + 1
-
- epoch_end = time.time()
-
- print("Epoch: {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}%, \n\t\tValidation: Loss: {:.4f}, Accuracy: {:.4f}%, Time: {:.4f}s".format(
- epoch+1, avg_valid_loss, avg_train_acc*100, avg_valid_loss, avg_valid_acc*100, epoch_end-epoch_start
- ))
- print("Best Accuracy for validation : {:.4f} at epoch {:03d}".format(best_acc, best_epoch))
-
- torch.save(model, 'models/'+dataset+'_model_'+str(epoch+1)+'.pt')
- return model, history
-
- num_epochs = 100 #训练周期数
- trained_model, history = train_and_valid(resnet50, loss_func, optimizer, num_epochs)
- torch.save(history, 'models/'+dataset+'_history.pt')
-
- history = np.array(history)
- plt.plot(history[:, 0:2])
- plt.legend(['Tr Loss', 'Val Loss'])
- plt.xlabel('Epoch Number')
- plt.ylabel('Loss')
- plt.ylim(0, 1)
- plt.savefig(dataset+'_loss_curve.png')
- plt.show()
-
- plt.plot(history[:, 2:4])
- plt.legend(['Tr Accuracy', 'Val Accuracy'])
- plt.xlabel('Epoch Number')
- plt.ylabel('Accuracy')
- plt.ylim(0, 1)
- plt.savefig(dataset+'_accuracy_curve.png')
- plt.show()

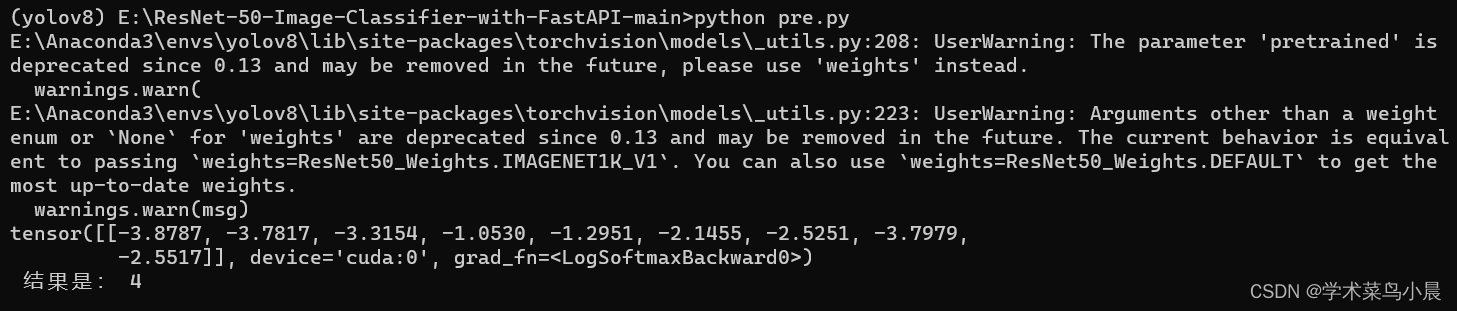
测试:图片名改下即可。
- import torch
- from torchvision import models, transforms
- import torch.nn as nn
- import cv2
- classes = ["1","2","3","4","5","6","7","8","9"] #识别种类名称(顺序要与训练时的数据导入编号顺序对应,可以使用datasets.ImageFolder().class_to_idx来查看)
-
- transf = transforms.ToTensor()
- device = torch.device('cuda:0')
- num_classes = 2
- model_path = "models/skin-cancer-detection_model_3.pt"
- image_input = cv2.imread("ISIC_0000019.jpg")
- image_input = transf(image_input)
- image_input = torch.unsqueeze(image_input,dim=0).cuda()
- #搭建模型
- resnet50 = models.resnet50(pretrained=True)
- for param in resnet50.parameters():
- param.requires_grad = False
-
- fc_inputs = resnet50.fc.in_features
- resnet50.fc = nn.Sequential(
- nn.Linear(fc_inputs, 256),
- nn.ReLU(),
- nn.Dropout(0.4),
- nn.Linear(256, num_classes),
- nn.LogSoftmax(dim=1)
- )
- resnet50 = torch.load(model_path)
-
- outputs = resnet50(image_input)
- value,id =torch.max(outputs,1)
- print(outputs,"\n","结果是:",classes[id])