
热门标签
当前位置: article > 正文
yolov8-opencv-ffmpeg-mediamtx实现视频中实时检测安全帽_yolov8头盔
作者:小小林熬夜学编程 | 2024-02-12 15:06:28
赞
踩
yolov8头盔
yolov8-opencv-ffmpeg-mediamtx实现视频中实时检测安全帽
模型训练
安全帽数据集
本人是从kaggle上面下载的数据集,找了一个yolo能直接使用的,
训练
首先安装ultralyticsplus
然后新建
safehat.yaml
train: D:\data\archive\css-data\train\images\
val: D:\data\archive\css-data\valid\images\
test: D:\data\archive\css-data\test\images\
nc: 10
names: [Hardhat, Mask, NO-Hardhat, NO-Mask, NO-Safety Vest, Person, Safety Cone, Safety Vest, machinery, vehicle]
- 1
- 2
- 3
- 4
- 5
from ultralyticsplus import YOLO, render_result
def train():
model = YOLO('yolov8n.pt')
model.train(data='safehat.yaml', epochs=100)
model.val()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
训练完成后会print保存权重的路径
测试
model = YOLO('yolopt/best.pt')
image = 'imgs/test_dec.jpg'
results = model.predict('imgs/test_dec.jpg', save = True, classes = [0, 2])
- 1
- 2
- 3
results是返回结果,save为True可以保存推理结果
后面会根据结果实现标注
opencv获取视频流
没有找到合适的在线流地址,本人使用的数据集中的视频进行测试,有条件的可以使用视频流的地址
先装一个mediamtx
自行百度下载,下载完成解压后打开;我这边是windows,直接打开exe;linux没测试
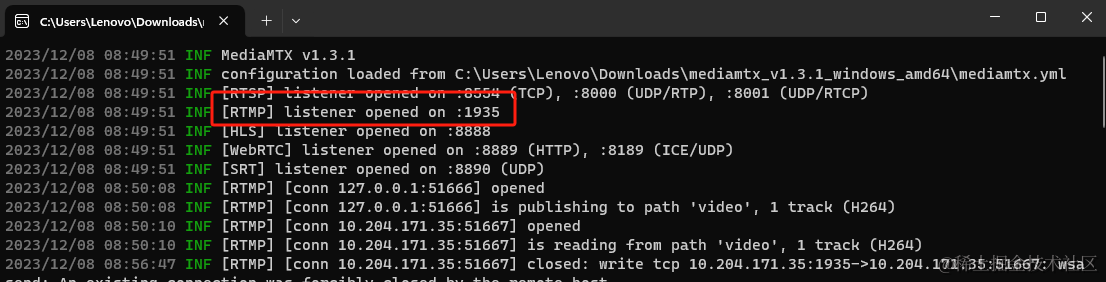
后面根据这个端口进行推流
实现推送类
import subprocess class StreamPusher: def __init__(self, rtmp_url, width, height): # 接受一个参数rtmq_url 该参数受用于指定rtmq服务器地址的字符串 # 创建FFmpeg命令行参数 ffmpeg_cmd = ['ffmpeg', '-y', # 覆盖已存在的文件 '-f', 'rawvideo', # 指定输入格式为原始视频帧数据 '-pixel_format', 'bgr24', # 指定输入数据的像素格式为BGR24(一种图像颜色编码格式) '-video_size', '{}x{}'.format(width, height), # 指定输入视频的尺寸 '-i', '-', # 从标准输入读取数据 '-c:v', 'libx264', # 指定视频编码器为libx264(H.264编码器) '-preset', 'ultrafast', # 使用ultrafast预设,以获得更快的编码速度 '-tune', 'zerolatency', # 使用zerolatency调整 以降低延迟 '-pix_fmt', 'yuv420p', # 指定输出视频像素格式为yuv420p '-f', 'flv', # 指定输出格式为FLV rtmp_url] # 指定输出目标为‘rtmp_url' 即RTMP服务器地址 print('ffmpeg_cmd:', ffmpeg_cmd) # 启动 ffmpeg self.ffmepg_process = subprocess.Popen(ffmpeg_cmd, stdin=subprocess.PIPE) def streamPush(self, frame): # 用于推送视频帧数据到FFmpeg进程 self.ffmepg_process.stdin.write(frame.tobytes())

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
图片标注
def draw_dect(image, results):
names = results[0].names
result = results[0]
detections = sv.Detections.from_yolov8(result)
# detections = detections[detections.class_id == 0]
# 绘制检测框
box_annotator = sv.BoxAnnotator(thickness=2, text_thickness=2, text_scale=2)
labels = [f"{names[class_id]} {confidence:0.2f}" for area, box_area, confidence, class_id, xyxy in detections]
frame = box_annotator.annotate(scene=image, detections=detections, labels=labels)
return frame
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
获取视频流
cap = cv2.VideoCapture(r'D:\data\archive\source_files\source_files\JapanPPE.mp4') width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))) pusher = StreamPusher(rtmp_server, width, height) # model_best = YOLO('runs/detect/train12/weights/best.pt') model_best = YOLO('yolopt/best.pt') while True: success, src_img = cap.read() t1 = time.time() results = model_best.predict(src_img, save=True, classes=[0, 2]) dst_img = draw_dect(src_img, results) print(time.time() - t1) pusher.streamPush(dst_img)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
下个vlc,看下效果,放个截图:
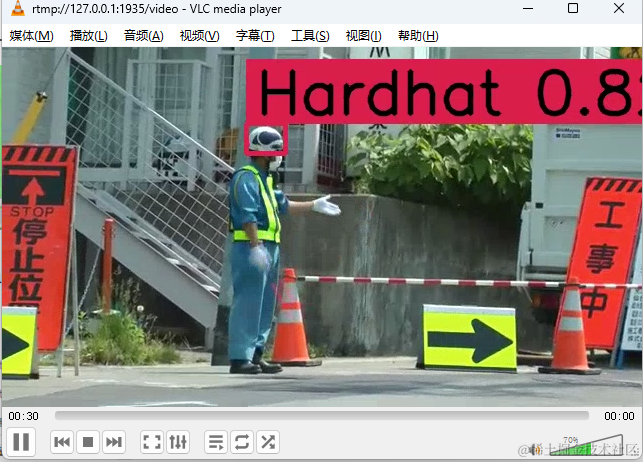
第一次写,写的不好,多多见谅
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

