- 1Python周刊447期_pivotnacci
- 2【开题报告】基于微信小程序的电影院购票选座系统_微信小程序开题报告拟解决的关键问题
- 3visual studio code(vs code)历史版本下载
- 4Python中Unicode中文字符串转换成 string字符串_python unicode to str
- 5为什么要学Python?这六个理由告诉你
- 6Istio 服务网格如何处理安全问题?_rbac: access denied
- 7TCP 异常断开连接分析_tcp断连问题剖析
- 8centos 安装nginx并配置证书_centos 8 nginx自动更新浏览器可用证书
- 9我的世界java手机版怎么调按键_《我的世界》按键设置 pc版快捷按键代码大全...
- 10vue+elementui实现表格默认选中(el-table)_elementui table 默认选中
PointNet和PointNet++模型训练vscode+ubuntu_pointnet++数据集
赞
踩
项目地址
Pointnet复现的代码pytorch版本
在github中下载压缩包,也可以直接克隆项目,看服务器的了,我这边服务器好像不太行,所以现在下载压缩包到本地,然后在vscode中远程连接服务器,vscode的好处是文件可以直接拖进去,点赞嘿嘿。
pointnet++分类任务
modelnet数据集详解
modelnet数据集是点云的数据集,有model10和modelnet40,其中的modelnet10中有10个类别
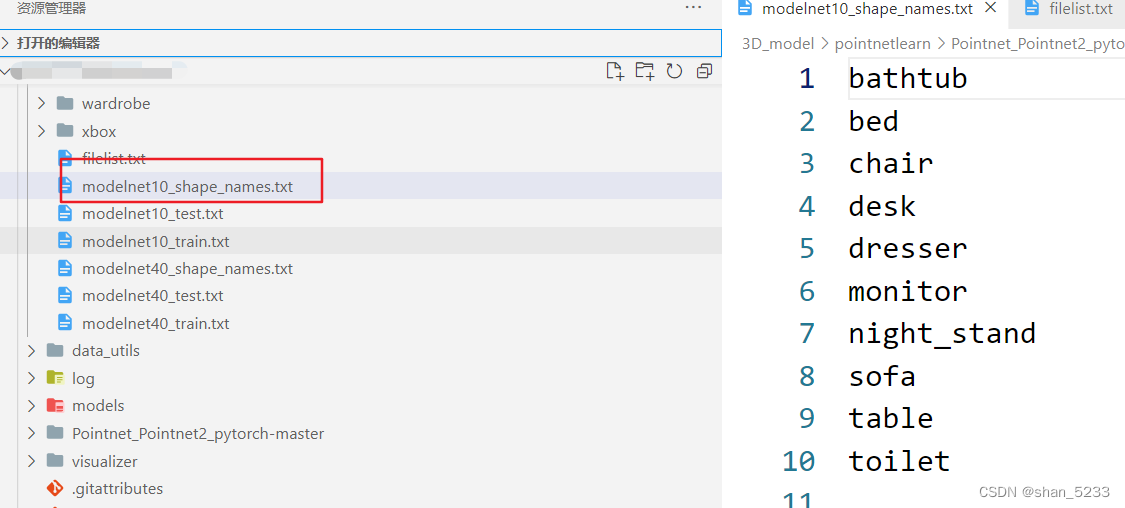
训练数据有3991,测试数据有908个
同样的modelnet40是有40个类别,训练数据9843个,测试数据有2468个。

数据的格式是txt的文件,比如这个飞机由10000个点构成,每一行是点的坐标和法向量。

【遇到的一个小问题】数据集比较大直接拖拽会产生错误,导致最后的数据上传的不完整,使用的方法是本地压缩好,在服务器端解压。
进入文件之后使用unzip modelnet40_normal_resample.zip命令进行压缩,速度超快哈哈哈哈。
训练数据
–normal表示使用法向量信息,后面发现源代码改了使用use_normal,可以在train.py的代码中看到,
–log_dir指定日志文件存储路径


默认显存是24,batch_size 16表示显存是16g的,由于我校服务器是11g的所以这里面的16要改成8。执行训练命令的时候要进入Pointnet_Pointnet2_pytorch-master文件中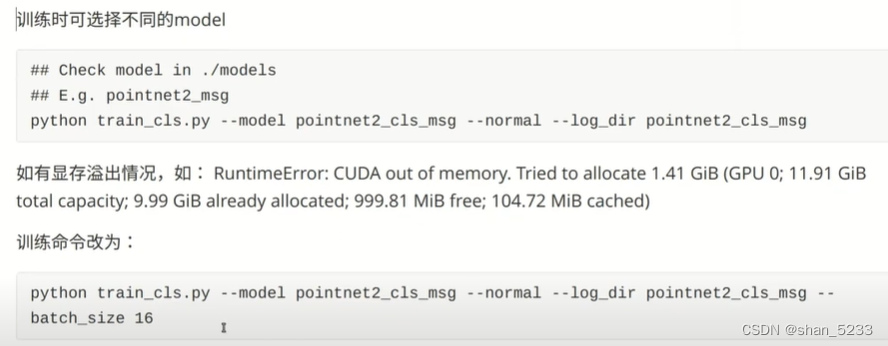 在model文件夹下面是不同的模型pointnet2代表pointnet++,cls代表分类,part_seg用于部件分割,sem用于场景分割
在model文件夹下面是不同的模型pointnet2代表pointnet++,cls代表分类,part_seg用于部件分割,sem用于场景分割
训练好后可以查看日志
使用简单的相对来说模型pointnet_cls试试水,嘿嘿。
等待训练,15:19开始。。。
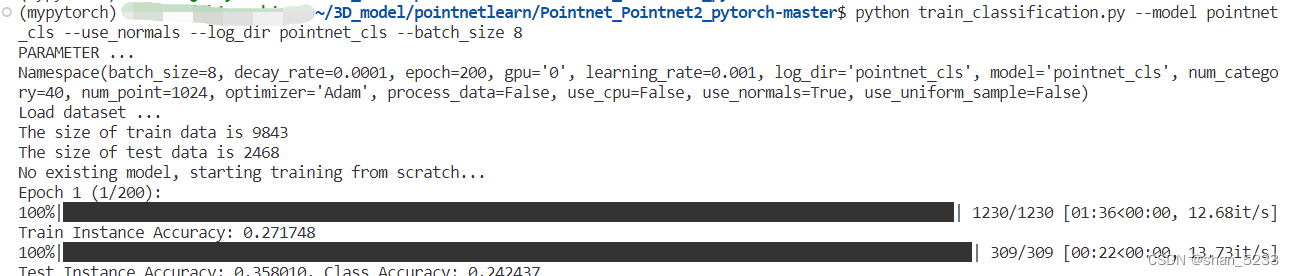
训练日志:
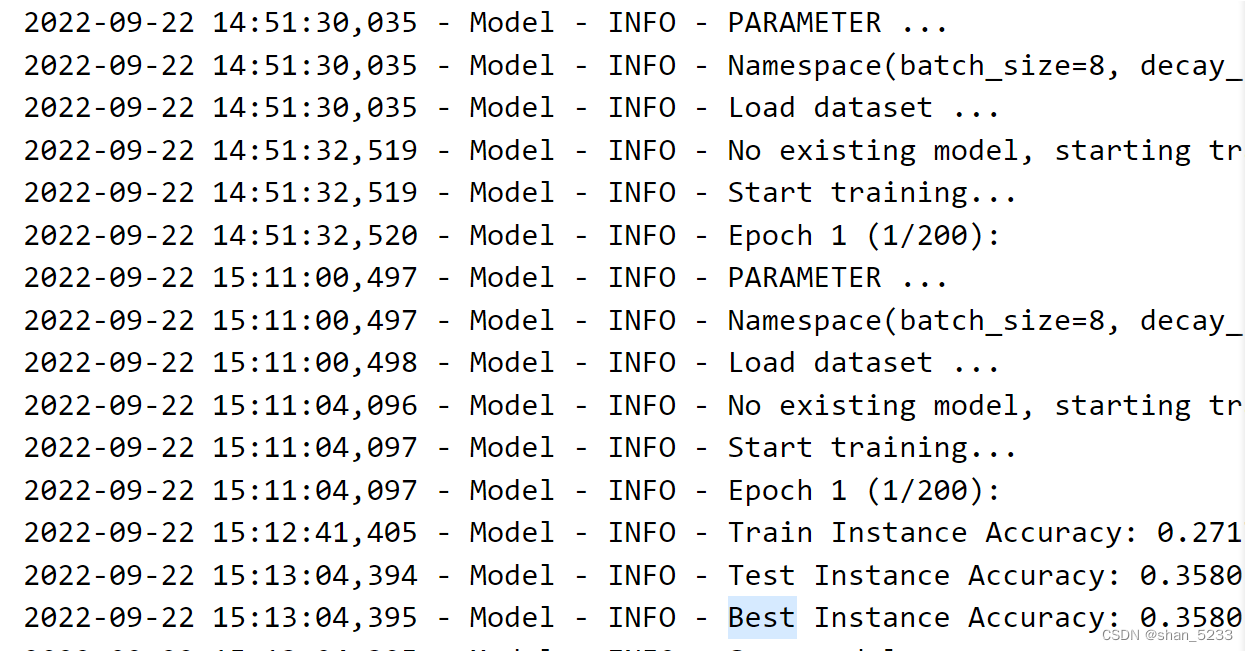
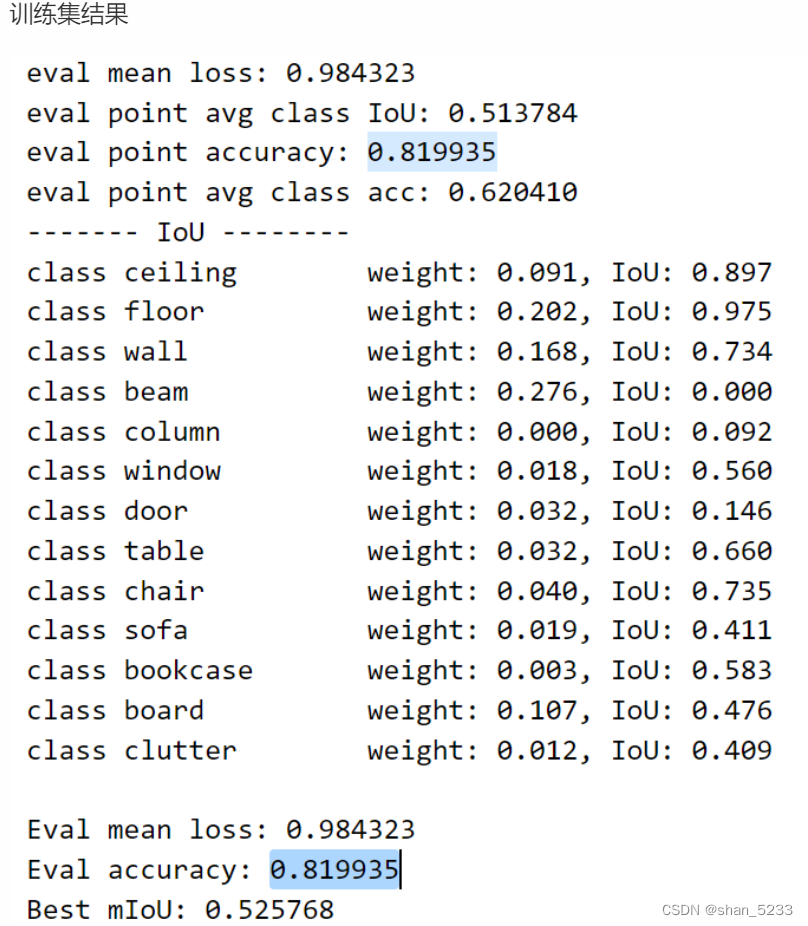
instance accuracy为所有物体分类正确的统计结果,class accuracy为40个类别的准确率平均后的结果。

9月23日上午9点准备训练pointnet++。(今日任务训练数据,阅读论文,写周报)
python train_classification.py --model pointnet2_cls_ssg --use_normals --log_dir pointnet2_cls_ssg_first --batch_size=8
- 1
动态查看gpu情况,每10s刷新一次。
watch -n 10 nvidia-smi
- 1

9月23日跑了一天是46轮,然后晚上把电脑扣上,本来以为程序可以一直运行,结果24号早上一看log,直接关闭了,后来问师兄才知道需要使用screen创建一个单独的窗口,然后在这个里面进行训练即可,关闭vscode测试成功。
screen创建窗口指令
screen -S pointnettrain(这个名字是窗口名称,随便改)
- 1
然后运行上面的训练代码即可。
中途退出screen的窗口ctrl+a+d
恢复窗口指令,如果只有一个窗口可以使用screen -r
screen -r pointnettrain
- 1
查看当前都有什么窗口命令
screen -ls
- 1
结束某个窗口命令
screen -X -S 进程号 quit
- 1
9月25日
早上来看pointnet++的日志发现凌晨四点多跑完了,不得不说screen真香,嘿嘿。

不过发现一个奇怪的现象,在vscode中创建的screen窗口终端没有滚动条。。。。(解决办法参考screen基本操作的博客)
pointnet++语义分割
关于数据集
训练的数据集S3DISDataset,测试的数据集是ScannetDatasetWholeScene,两个都是斯坦福大学的。
下载S3DIS数据集保存到 data/s3dis/Stanford3dDataset_v1.2_Aligned_Version/ 文件下。
处理后的数据保存到 data/stanford_indoor3d/
文件说明:
all_files.txt记录所有h5文件的名字,ply_data_all_i.h5包含不同block的点云(数据和标注),0-22每个文件中包含1000个块,即每个h5文件为1000x4096x9的点云以及1000x4096的点标注。23号文件包含585个块。room_filelist.txt文件包含每个块所属的面积和场景,共23858行。
Stanford3dDataset_v1.2_Aligned_Version/文件下有六个Area_i个文件,Area_1文件中包含室内点云文件比如conferenceRoom、wc,conferenceRoom里面有txt文件包含很多个点的数据,数据信息是六个维度的(x,y,z,r,g,b),可以使用cloudcomputer软件进行查看。

数据需要处理一下使用 python collect_indoor3d_data.py 将处理后的数据保存到data文件下的stanford_indoor3d下,文件下是npy文件。
训练和测试
可视化结果保存在log/sem_seg/pointnet2_sem_seq/visual/,其中的.obj文件可以使用MashLab软件进行可视化。
pointnet++训练执行命令
python train_semseg.py --model pointnet2_sem_seg --test_area 5 --log_dir pointnet2_sem_seg
pointnet++测试执行命令
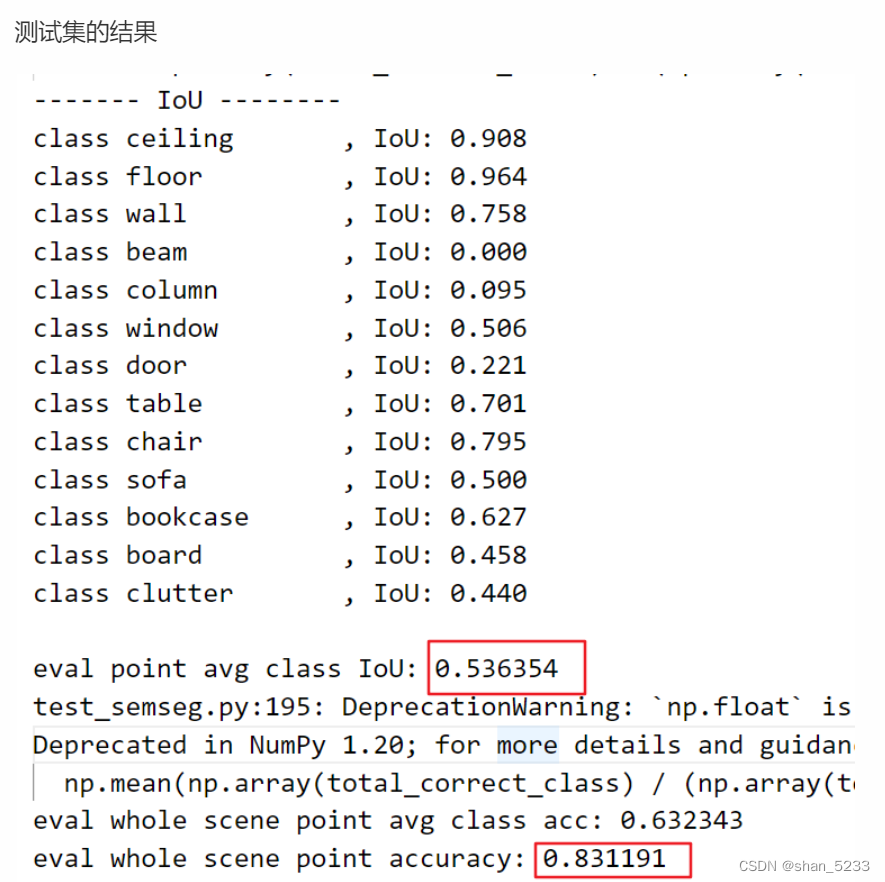
python test_semseg.py --log_dir pointnet2_sem_seg --test_area 5 --visual
- 1
- 2
- 3
- 4
预测的场景左Area_5_conferenceRoom_1_gt.obj 真实的场景右Area_5_conferenceRoom_1_pred.obj
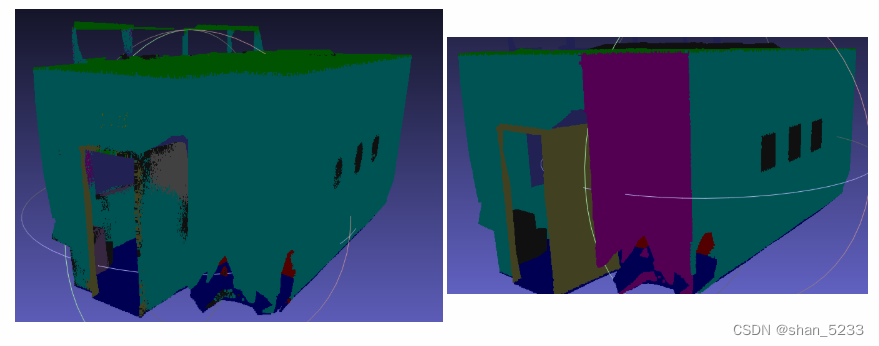
训练结果
测试结果
pointnet++分割原理
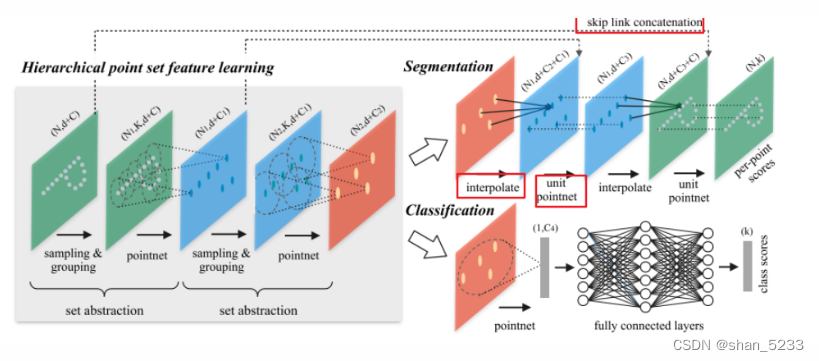
对于稠密预测任务,上采样是非常重要的恢复分辨率的手段。类似CNN中的反卷积上采样操作,PointNet++通过文中所称的Point Feature Propagation模块来实现,该模块由上图中的interplolate, skip links concatenation和unit pointnet构成:
多层次特征提取
最远点采样:最远点选择作为中心点
球查询
插值相当于图像分割中的上卷积,作者把插值方法称为特征传递(feature propagation)。使用的是基于距离的插值,依照距离的倒数决定距离的大小,两个点越远距离越小,这种插值方法称作inverse distance weighted average 。
pointnet++还考虑了非均匀采用的密度:激光扫描的点云数据近密远疏的,非均匀的采样会影响层次化的特征的学习。对于密集的点和稀疏的点的选取的半径不应该相同。
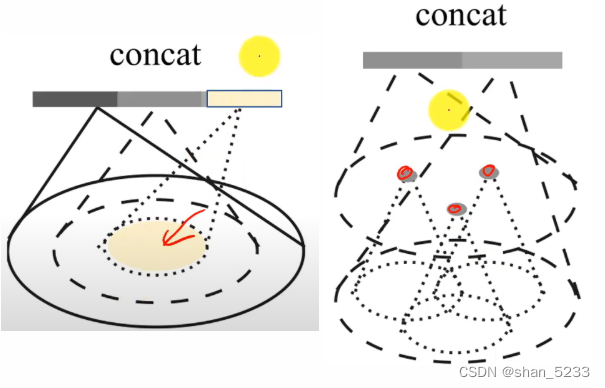
对于非均匀的点云采样的方法,作者提出两个方法
Multi-scale-grouping(MSG)(左):同一级别选取不同的半径。Multi-resolution grouping(MRG)(右):不同级别上相同半径。