
- 1Python中的iter()与next()函数_calliter.__next__()
- 2Zabbix绘制流量拓扑图_zabbix 流量地图
- 3Anaconda3 下载安装及不同python环境配置(Linux/Windows)_如何下载到指定python版本的anaconda
- 4基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的智能监考系统(Python+PySide6界面+训练代码)
- 52022完整版:云计算面试题和答案(学习复习资料)_云计算售前面试
- 6pip换源命令(一行命令完成)
- 7Python打包exe和生成安装程序_python生产安装包
- 8Java项目:博客论坛管理系统(java+SpringBoot+JSP+LayUI+maven+mysql)_layui制作论坛列表带内容系统
- 9黑客爱用的HOOK技术大揭秘!_hook计算机是什么意思
- 10在 Java 中实现单例模式通常有两种方法_java两种单例创建
SLAM综述阅读笔记六:基于图像语义的SLAM调研:移动机器人自主导航面向应用的解决方案 2020_与slam相关的语义导航
赞
踩
转自【【论文阅读】A survey of image semantics-based visual simultaneous localization and mapping 语义视觉SLAM综述 - 知乎】A survey of image semantics-based visual simultaneous localization and mapping: Application-oriented solutions to autonomous navigation of mobile robots[J]. International Journal of Advanced Robotic Systems, 2020, 17(3): 1729881420919185.
摘要
作为机器人自主导航典型的面向应用的解决方案之一,视觉同步定位和建图本质上局限于基于图像几何特征的单纯环境理解。相比之下,以高级环境感知为特征的语义SLAM,显然已经打开了应用图像语义来有效地估计姿态、检测闭环、构建3D地图等等的大门。本文详细综述了语义SLAM的最新进展,主要包括在感知、鲁棒性和准确性方面的处理。具体来说,首先提出了“Semantic Extractor语义提取器”的概念和“Modern Visual Simultaneous Localization and Mapping现代视觉同时定位和建图”的框架。随着与感知、鲁棒性和准确性相关的挑战正在被陈述,我们将从宏观的角度进一步讨论一些开放的问题,并试图找到答案。我们认为多尺度的地图表示、对象同步定位建图系统以及基于深度神经网络的SLAM方案能有效的解决融合图像语义的视觉SLAM问题。
关键词
语义SLAM、视觉SLAM、自主导航、移动机器人、鲁棒性、环境感知
1. 引言 Introduction
自主机器人能够独立地执行特定的任务,而无需任何人为的干预。作为自主机器人的主要属性之一,自主运动(autonomous motion)在很大程度上依赖于精确的自我运动估计(ego-motion estimation)和高级别周围环境感知(high-level surrounding environment perception)。然而,在人工路标未知或机器人本身在没有GPS信号的环境下估计自我运动或感知场景会遇到很大的困难。
“SLAM”这个术语代表同时定位和建图(由Smith和Cheeseman在1986年提出),被认为是在一个未知的环境内的一个未知地点中进行移动机器人自我定位的杰出工具。从技术上讲,移动机器人逐步建立一个相关环境的全局一致地图,同时确定其在该地图中的位置。从数学角度来看,SLAM过程可以抽象为一个并发估计问题,主要包括机器人的姿态估计和可用路标的位置估计。SLAM问题的示意图如图1所示。
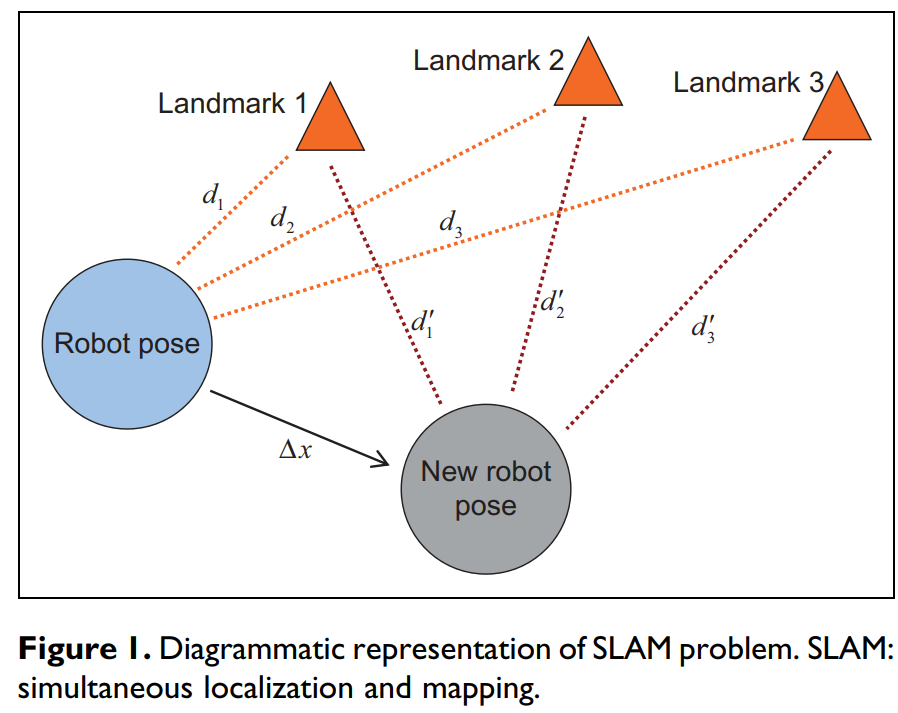
图1 SLAM问题的图示
长期以来,SLAM问题基本上通过一系列距离传感器来解决,如光检测与测距/激光雷达(Light Detection and Ranging,LiDAR)、红外辐射(Infrared Radiation,IR)或小规模静态环境测距范围内的声音导航与测距(距离传感器的形式符合其各自的物理原理)。然而,基于距离传感器的SLAM可能不得不在动态、复杂和大规模的环境中面临重大挑战。
通过外部摄像头(作为唯一的外部传感器)实现的SLAM被称为视觉SLAM(V-SLAM)。与其他典型的SLAM框架(如基于距离传感器的SLAM)相比,视觉SLAM的显著优势是由于更丰富的图像纹理和更简单的传感器配置,它在实际应用中的适应能力。此外,计算机视觉(CV)的发展和成熟使视觉SLAM能够获得图形和视觉支持。重要的是要认识到,计算机视觉的解决方案已经解决了VSLAM领域的一些主要困难,如图像特征的检测、描述和匹配、闭环检测和3D地图重建等等。目前,通过许多开源算法,V-SLAM系统的体系结构已经建立起来。然而,我们必须承认,当机器人的运动或环境太具挑战性时,V-SLAM是脆弱的(比如,机器人快速运动、高可变环境、剧烈光照变化,高度限制的视野,或者复杂的弱纹理场景)。
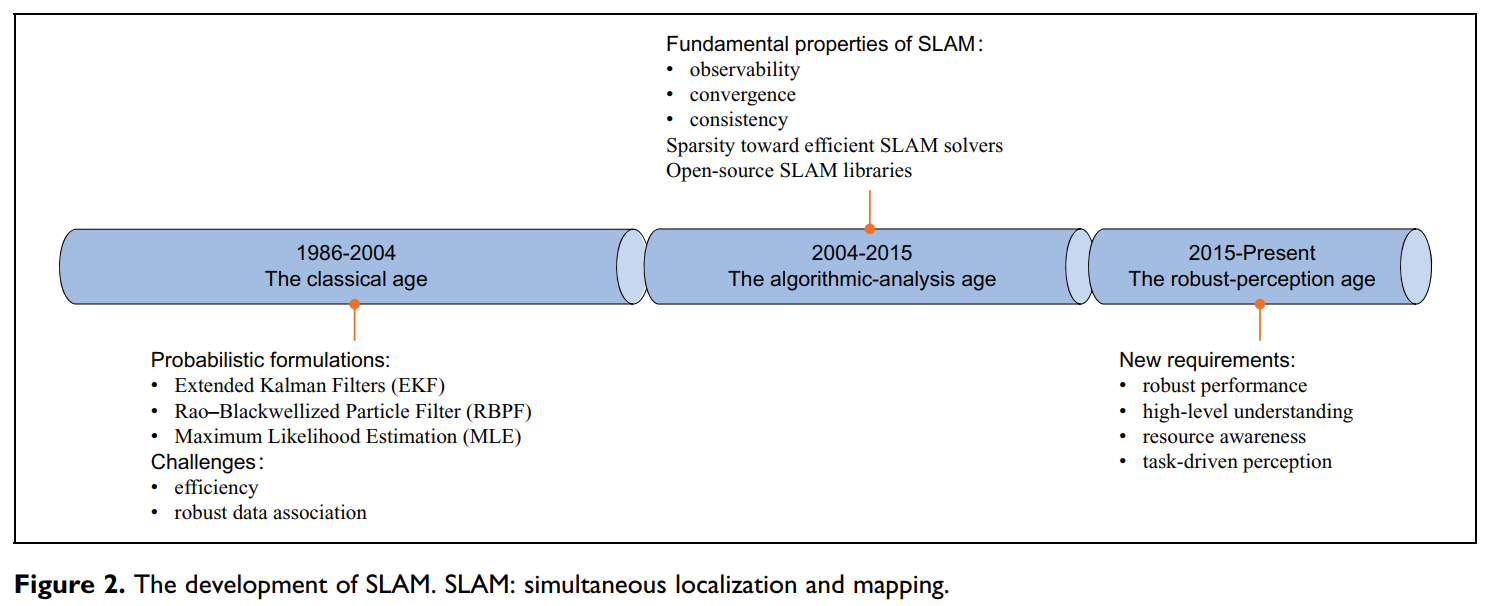
图2 SLAM的发展时间线
Cadena等人首先将SLAM的时间线分为三个阶段,并进一步总结了个别成果,如图2所示。从技术上讲,他们说我们现在正在进入SLAM的第三个阶段,一个鲁棒感知(robust perception)的阶段:鲁棒性能的实现、高级别的理解与资源意识,而任务驱动的感知(task-driven perception)代表了这个时代的主题。SLAM的研究人员一直致力于解决高级感知和理解的方法。由于它们在包括提升鲁棒性、直观的可视化和高效的人-机-环境交互等方面的优势,他们一直努力针对语义展开研究。与基于语义的鲁棒性/准确性增强或语义建图相关的研究被称为语义SLAM。由于视觉SLAM可以在一个联合公式中进行定位和建图,因此很自然地,语义SLAM的上述两个过程也可以由一个估计器同时进行评估。
表1列出了2006年至今目前关于SLAM的主要综述。如前所述,很少有关于语义SLAM的综述文章(只有Cadena等人提到了基于语义概念的建图)。沿着SLAM发展的主线,我们试图对当前的语义SLAM领域进行广泛地综述,并进一步阐明一些有待解决的问题和我们对未来研究的见解。
本次综述的其余部分的大纲如下。第二部分主要是详细介绍了语义提取器(Semantic Extractors),一个现代视觉SLAM系统的基本体系结构,以及主流的开源算法。然后特别注意语义SLAM的显著性质。分别与人-机-环境交互相关的感知、鲁棒性和准确性问题,环境适应和可靠的导航在第三、第四和第五部分进行阐述。第六部分集中讨论关于语义SLAM的挑战性,寻求这些基本问题的答案。第七部分得出了结论。
2. 语义SLAM系统的组成 The components of a semantic SLAM system
语义SLAM系统由两个基本组件构成:语义提取器(Semantic Extractors)和现代视觉SLAM框架。具体来说,语义信息主要是从两个信息中提取出来的过程。它们是目标检测和语义分割。
2.1 语义提取器 Semantic Extractor
对象检测具有轻量级的适用性,不仅可以用于所谓的对象级的分类,还可以用于确定相关对象的2D位置。相比之下,语义分割导致了像素级的分类获取,即单个图像中的所有像素都有自己独特的类别。显然,由于精确边界,后者表现出更有利的精度。下面是一个逐节的描述。
对象检测 Object detection。对象检测被认为是计算机视觉的一个重要分支,其发展大致可分为基于手工特征的机器学习阶段(2001-2013年)和基于学习特征的深度学习阶段(2013年至今)。前者非常依赖于图像的手工特征。事实上,在那个时期,研究人员致力于通过多样化的描述子设计来加强手工特征的表现。此外,由于计算资源有限,他们不得不探索更有效、更实用的计算方法。尽管他们努力实现手工特征表示和计算效率之间的平衡,然而目标检测实验出乎意料的设计复杂,鲁棒性差。
近年来,由于深度学习和图形处理单元的引入,高精度的目标检测在理论和实践上都取得了很大的进展。特别是融合深度神经网络(DNN)的目标检测已经达到了首选的鲁棒性和准确性,其方案可以按照以下两阶段进行近似设计:
- 阶段1:获取对象的二维位置;
- 阶段2:分类对象
区域卷积神经网络(R-CNN)系列属于典型的两阶段网络,包括R-CNN、Fast R-CNN、Faster R-CNN以及最新的Mask R-CNN。R-CNN不仅是R-CNN系列网络的开创性工作,同时也是基于CNN的目标检测任务中最早采用的方法。
原则上,R-CNN通过选择性搜索(Selective Search)生成区域建议,特征提取和分类分别通过AlexNet和支持向量机(SVMs)来实现。与此不同的是,Fast R-CNN改变了生成区域建议和提取图像特征的顺序,用Softmax代替SVM。Faster R-CNN受益于生成的对象建议通过区域建议网络、补充锚点和共享功能来提高检测速度。很明显,Faster R-CNN会更快,但对于实时SLAM仍然不够快。相比之下,Mask R-CNN为了更精确的语义分割而牺牲了部分检测速度。因此,它到达了一个实例级的结果,即每个被检测到的对象中的所有像素都有它们自己独特的类别
值得注意的是,最新的物体检测算法同时实现了物体定位和分类,而不是首先推导出物体的二维位置。具有代表性的YOLO系列(被称为最快的语义提取器)使用 SXS 网格来替代区域建议,因此,这些网格的分类是最终检测的理想候选方法。一般来说,YOLO系列的速度可以被实时语义SLAM系统所接受,但为了获得更高的准确性,最新的CenterNet提供了一个新的基于特征点的方法。为了清楚地描述目标检测网络的发展,图3是其发展的时时间线。
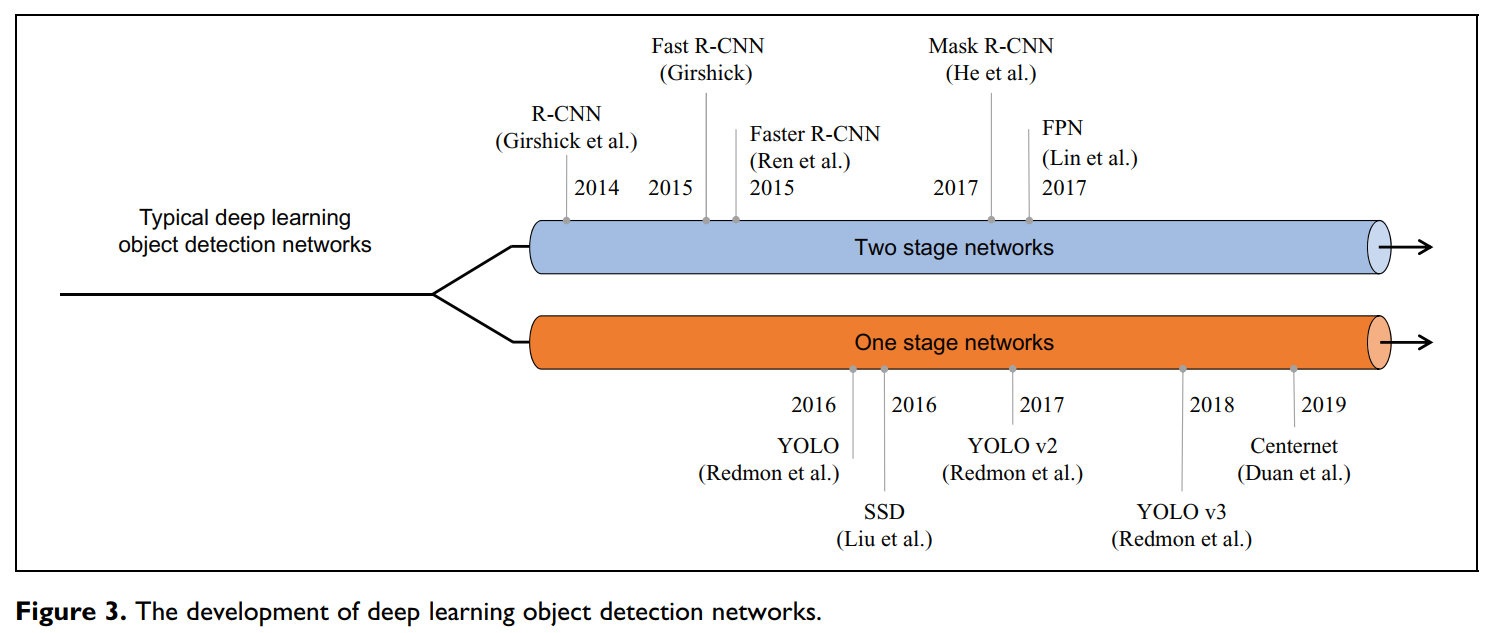
3. 深度学习目标检测网络的发展
语义分割 Semantic Segmentation。在涉及到非常复杂场景的情况下,需要注意,为了保证鲁棒定位和建图,精细场景推理,就是说,需要进一步考虑在众多对象之间的深度关联挖掘。相比之下,目标检测适用于粗糙的场景推断,而语义分割更一般化,因为它适用于精细的场景处理。类似地,语义分割的进化已经经历了从“基于机器学习的方法”到“基于深度学习的方法”的转变。如今,CNN的引入极大地提高了分割的准确性和效率;因此,对于构建语义SLAM系统的情况,基于CNN的解决方案通常优于其他解决方案。
考虑到语义分割在语义SLAM系统中的实际应用,需要研究与网络相关的两点(出于语义分割的目的)。一个是技术指标(包括精度和效率),另一个即应用条件(表示网络是否有效于视频分割还是三维图像分割)。该部分致力于描述基于深度学习的语义分割网络,主要遵循上述思路。典型CNN在语义分割上的性能比较情况如表2所示。
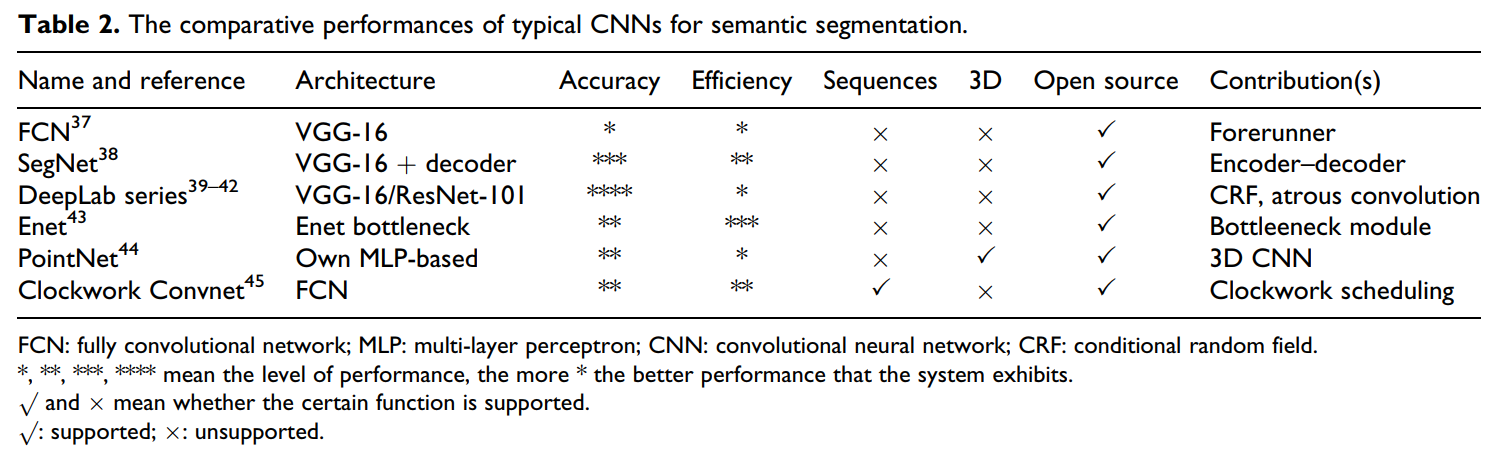
表2 典型用于语义分割的CNN网络的对比性能
一般来说,几乎所有基于深度学习的语义分割网络都继承了全卷积网络(FCN)的模型(Long等人认为是里程碑式的工作【37】)。顾名思义,作者修改了所有最流行的分类网络(AlexNet,VGG-16,GoogleNet),形成匹配的FCNs,从而允许从任意大小的图像输入中进行密集的分割。此外,CNN的编码能够生成不同的细粒度语义分割映射,当映射融合成跳跃式连接结构时,就可以得到所需的语义分割结果。然而,FCNs本身实际上对于技术索引和语义SLAM所需要的应用条件都不是有效的(原因见表2)。更关注解码过程的“SegNet”似乎是可用的【38】,因此采用了卷积编码器-解码器结构来替代。DeepLab系列网络的贡献(包括DeepLab-v1,DeepLab-v2、DeepLab-v3,DeepLab-v3+)包括它们完全整合了不同尺度上的图像信息(称为“图像的全局上下文”),以及它们有效地解决了在FCN或SegNet中可能遇到的“模糊边界”问题。具体来说,DeepLab-v1将一个概率图模型(如条件随机场(CRF))插入到一个基于CNN的框架中,并进一步将分割结果建模为一个概率图。这个概率图肯定考虑了图像的全局上下文(即所有像素之间的相互作用,而不是只考虑相邻的像素),并有助于更精细的分割结果,但它不可避免地加重了计算的负担。DeepLab-v1率先在CNN模型中使用了“空洞卷积Astrous Convolution”,它在没有任何复杂性负荷的情况下获得了更广泛的接受域。相比之下,DeepLab-v2在不同尺度上的上下文信息捕获方面的开创性工作是采用了基于原子卷积的空间金字塔池化(Astrous Spatial Pyramid Pooling)。DeepLab-v3和DeepLab-v3+进一步做了一些小的修改。
我们认为SegNet和DeepLab(没有CRF)满足了构建语义SLAM系统的技术指标需求。为了举一些具体的例子,让我们参考一些研究。Yu等人利用SegNet成功构建了一个面向动态场景的SLAM系统。Li等人通过DeepLab-v2(未使用CRF)有效地解决了在线单目语义SLAM的构建问题。如果重点关注细粒度的语义地图,而不是有效的建图,那么DeepLab系列网络(使用CRF)将被认为是理想的工具。相反,如果强烈要求高效建图,则应对某些网络进行评估并进一步应用。Enet让人想起了为实时语义分割而专门设计的网络,但其在语义分割中的准确性上相对较差。
当涉及到语义分割过程的“应用条件”问题时,让我们回顾一下两个候选网络:PointNet和Clockwork Convnet。前者适用于非结构化三维点云的直接分割,后者涉及视频或图像序列的时间线索(建立在时间尺度上的图像上下文)。这两种方法代表了领先的有利工具,尽管它们似乎在准确性或效率方面都没有显著的优势。但我们仍然认为,随着计算机技术的快速发展,有关PointNet和Clockwork Convnet的相关研究将具有现实意义。
2.2 现代视觉SLAM系统 Modern VSLAM System
现代视觉SLAM系统的架构通常包括:
- 传感器数据采集 Sensor Data Acquistion:通过摄像机获取图像或视频。
- 视觉里程计 Visual Odometry(VO):通过图像序列中的相邻帧,初步估计机器人的姿态和地标位置。
- 状态估计 State Estimation:利用VO和闭环检测提供的融合结果对状态进行全局估计。
- 重定位 Relocalization:在跟踪失败或重新加载地图时机器人进行重新定位。
- 闭环检测 Loop Detection:确定机器人是否位于之前到过的位置。
- 建图 Mapping:根据任务的要求进行建图。
关于传感器数据的流向和任务水平,视觉LAM系统一般包括两部分:前端和后端,其原理图解释如图4所示。视觉里程计VO和闭环检测模块同时接收某些传感器提供的输入。在这里,
视觉里程计VO的功能是提供初步的机器人姿态估计
闭环检测模块的功能是提供场景相似性。
推导出的机器人姿态和场景相似度构成了机器人全局优化姿态和路标的来源,并进一步绘制了运动轨迹和环境地图。在数学上,前端任务和后端任务可以分别抽象为“数据关联 Data Association”问题和“状态估计 State Estimation”问题。

图4. 现代视觉SLAM系统的架构
前端 The Front End:数据关联 Data Association
前端在一个图像序列的不同帧上跟踪相同的特征(特征点或代表性像素)的过程被称为“数据关联”。
一般来说,早期的视觉SLAM系统通过特征匹配来处理“数据关联”。显然,对局部图像特征的描述不足,导致数据关联错误的概率很高,然后会产生错误的位姿和路标估计。一些研究提出侧重于消除数据关联错误(如随机样本共识RANSAC),但尚未基本解决的问题使它仍然不尽如人意。后来研究人员开始评估概率思想中的“数据关联”(即做出一个软决策,将新特征输入跟踪序列)。概率数据关联(Probilistic Data Association)充分考虑了特征分配的不确定性,并将错误关联最小化。图5中的特性说明了这一点。
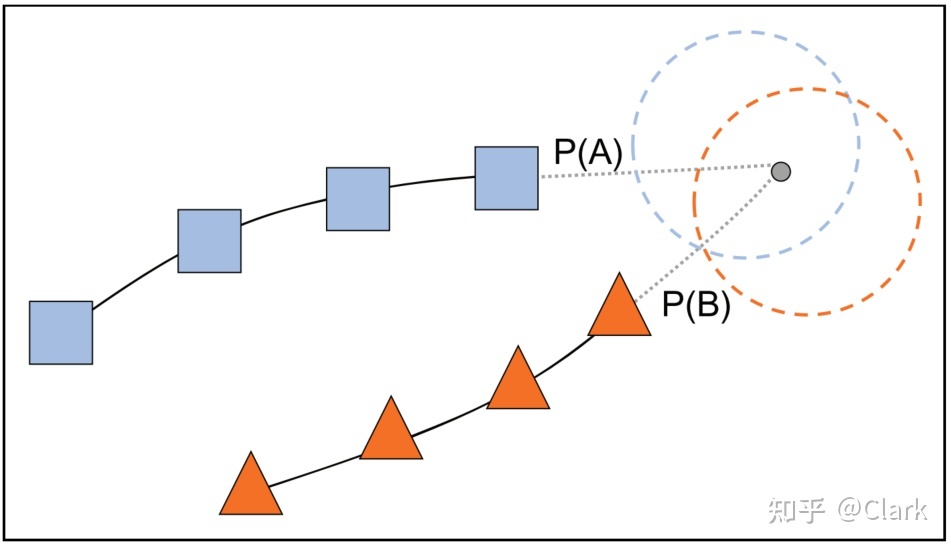
图5. 概率数据关联图示

最重要的SLAM结果之一是由Davison等人提出的,他率先通过扩展卡尔曼滤波器EKF更新相机的状态和路标点。与此不同的是,基于代表性捆机调整Bundle Adjustment的非线性优化通过状态变量融合全局约束得到最优来解决最大后验概率估计问题,而不是EKF的纯迭代。相比之下,在处理小规模场景应用时,基于EKF的SLAM比基于优化的SLAM具有优越的效率,但对于大规模场景进行SLAM,基于滤波器的解决方案由于协方差矩阵的规模较大,显得优势不足。
老实说,目前的视觉SLAM框架涉及大量的图像特征,这限制了传统的SLAM任务中基于EKF的解决方案;因此,特别关注基于BA的非线性优化方法。BA的思想可以追溯到21世纪早期的使用。它是解决与三维重建相关的运动恢复结构SFM问题的。受此启发,早期的SLAM研究人意识到了BA可能有助于高精度的状态估计,但他们发现视觉SLAM实际上是一个增量的过程;累计的计算负担使得直接将BA应用于强调实时需求的视觉SLAM是不可行的。基于BA的解决方案的适用性要求是探索视觉SLAM特性的原始灵感;主要进展之一在于研究人员利用了正态方程的稀疏性。他们证明了状态变量之间的依赖关系可以很自然地用一个因子图来表示。这允许BA可以使用更快的线性求解器或增量求解器,保证其采用实时需要的视觉SLAM系统。当前的优化库(例如g2o,Ceres)使在单秒内构建求解器和处理数千个变量变得很容易,因此,这使得基于BA的图优化方法成为后端状态估计的主流工具。
开源的视觉SLAM系统 Open-Source VSLAM System。我们想回顾一下一些视觉SLAM的开源算法,因为这是非常必要的。一般来说,视觉SLAM系统可以根据相机类型进行分类,包括但不限于单目、立体和RGBD深度相机。为了进行详细的阐述,表3进一步总结了它们的特征,包括对前端、后端、重定位、闭环检测等等的描述。我们坚持认为,视觉SLAM评估的关键因素是它是否能够实现稠密建图和闭环检测,它是否支持多个传感器,以及它是否能够具有实时性的性能。重要的是,为了简化目前的语义SLAM的设计,许多研究直接参考了成熟的视觉SLAM框架。
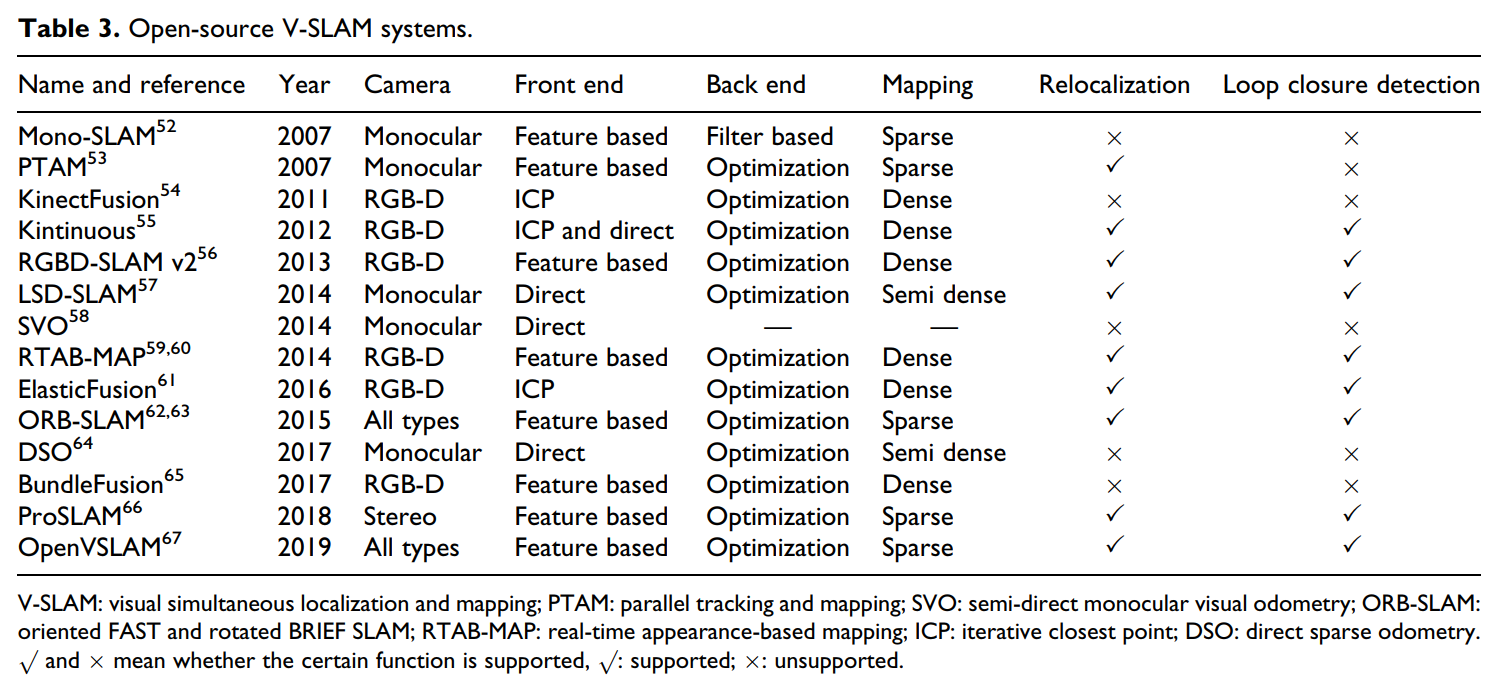
表3. 开源视觉SLAM系统
3. 人-机-环境交互:感知 Human-Robot-Environment Interaction:Perception
我们认为,在语义SLAM领域中定义的感知应该包括两个方面:对环境的理解和对人的理解。这种感知被称为人-机-环境交互。毫无疑问,一个环境模型(定义为语义地图)将在这两个理解过程中发挥作用。从技术上讲,语义地图的信息越丰富,所谓的语义级别就越高。由于语义地图在复杂自主机器人任务中的优越性(驾驶过程中避开泥泞道路),语义建图已成为目前语义SLAM研究中一个重要的、正在进行的课题。我们想总结目前的研究工作,并进一步说明我们对语义SLAM框架内的语义地图的愿景。表4总结了一些语义映射研究。
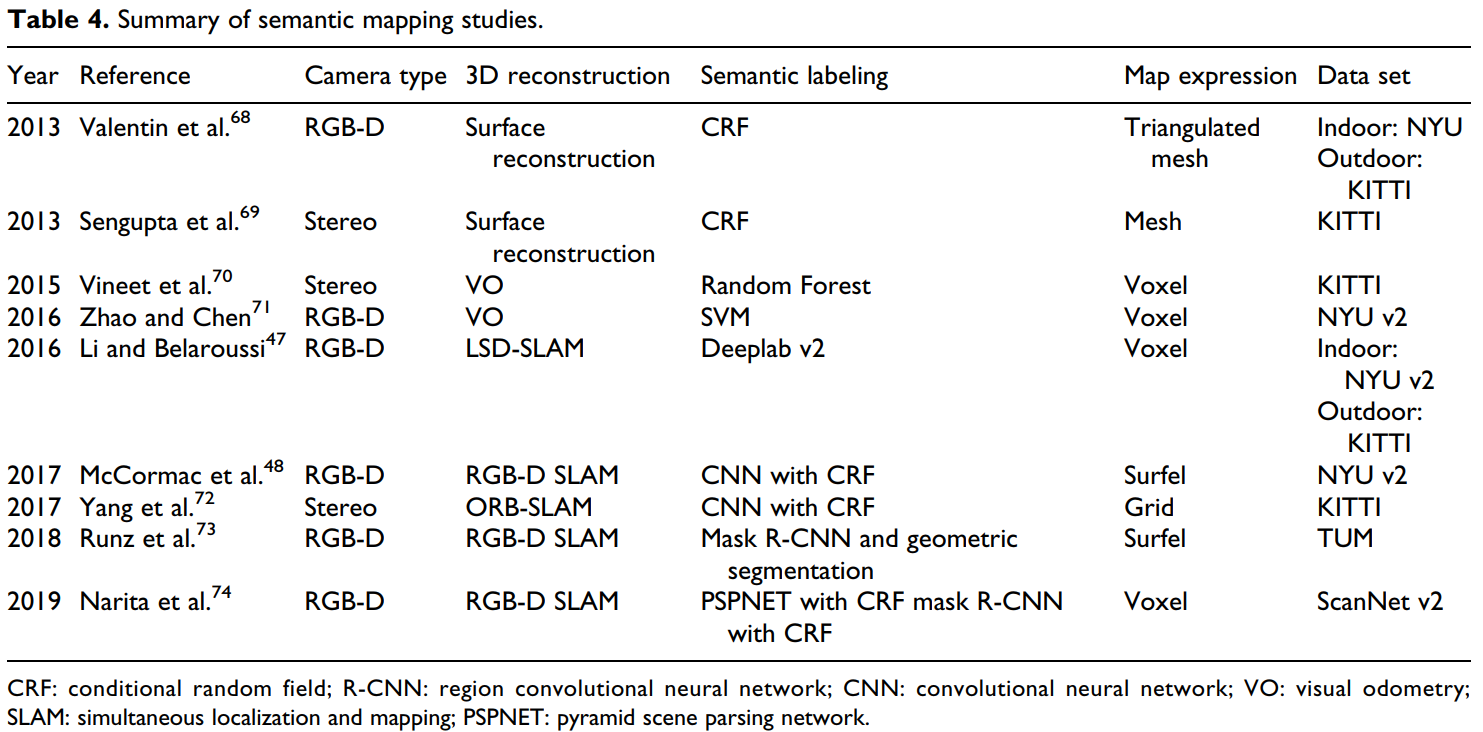
表4. 语义建图研究总结
3.1 语义地图 Semantic Map
语义地图可以在广义上分为对象级(Object-Level)和像素级(Pixel-Level)。先前的研究通过将已知对象的一些预先构建的三维模型插入到无意义的稀疏点云地图中,建立了对象级语义地图最初的概念。完全不同的是,有研究试图通过应用一些传统工具来构建优越的像素级语义地图,如SVM(尽管SVM通常用于解决预测,分类,或故障诊断等工业问题),CRF等,因为这些工具对于物体识别和场景分割是有用的。然而,在大多数情况下,有限的方法往往不能令人满意的分类精度。受深度学习进展的启发,在基于CNN的对象识别、检测和分割领域有了更多的研究。这些充分的成果为构建更准确的像素级语义地图提供了保证。
Li和Belaroussi【47】提出了将当时最先进的语义分割策略(DeepLab-v2)与视觉SLAM框架(大规模的单目直接法LSD-SLAM)进行混合。它的独特之处在于,通过多视角单目相机成功地构建了一个半密集的3D语义地图(而不是通过RGB-D相机获得一个密集的3D语义地图)。应该强调的是,这种混合的亮点还包括其反转以增强更大范围的2D单视图语义分割方法的性能。显然,SLAM本质上提高了语义分割的准确性。
3.2 开放性问题 Open Problems
时变语义地图 Time-varying Semantic Map。语义地图为高级语义理解奠定了基础,但其对长期鲁棒定位的适用性仍不理想。一个理想的解决方案是建立一个时变语义地图;如果不是因为这个事实,就不会建立一个相关场景中的对象之间时空关系的模型,以及接下来的物体的空间变化(运动)将无法被预测出来。因此,我们认为时变语义地图的引入有助于长期定位和动态定位。我们还认为,开发这种地图的基础是关于时空推理(Spatial and Temporal Reasoning)的某些AI人工智能思想。据我们所知,目前的语义SLAM很少涵盖此类研究。
全景语义地图 Panoptic Semantic Map。如前所述,基于CNN的语义分割可以得到更好的细粒度结果。尽管它们看起来足够微妙,但对于某些目的,分割的区域并不是很小(例如,无法区分不同风格的汽车),这在某种程度上限制了他们对场景感知的理解水平。实例分割网络在SLAM领域的重要贡献之一仅仅在于它在同一类别内进一步细分对象的思想;然而,它似乎不适用于不规则的背景。
全景分割(Panoptic Segmentation)充分结合了这两种分割方法的优点;作为计算机视觉领域的一个新兴方向,它有望以一种优雅的方式生成具有全局一致标签的细粒度结果。因此,全景语义建图(Panoptic Semantic Mapping)被认为是培养自主机器人的智能和增强现实的上下文信息的强大而卓越的工具。全景融合是基于全景语义三维重建的一项开创性研究【74】,然而,这却不利地忽略了对基于语义的定位思想的有用探索。由于语义定位在实际应用中经常被忽视,我们坚信同时侧重于建图和定位的语义SLAM框架仍在探索之中。
4. 环境适应:健壮性 Environment Adaptation:Robustness
如前所述,视觉SLAM现在正处于一个鲁棒感知的时代。从某种意义上说,语义SLAM的一个主要问题是“鲁棒性”增强。我们将集中讨论特征选择机制(Feature Selection Mechanism)和优化数据关联(Optimized Data Association)方面的中心问题。在详细回顾之前,我们首先总结了鲁棒性增强(Robustness Enhancements)方面的相关研究,如表5所示。更多的关于对象SLAM将在Disscussions部分中进行介绍。
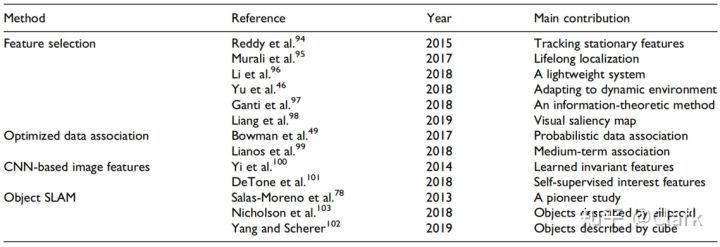
表5. 在鲁棒性增强方面语义SLAM研究的总结
4.1 特征选择机制 Feature Selection Mechanism
特征点先验语义的获取增强了视觉里程计的鲁棒性。因为我们最初评估了这些特征点是否适合于特定的任务,因此,所选择的鲁棒特征将有助于机器人更好地自我运动跟踪。特征选择机制针对不同地任务目的可以灵活改变。我们将会回顾这方面地最新研究。
感兴趣区域特征选择 Interested Region Feature Selection。Liang等人【98】提出了一种基于视觉显著性地图的特征选择视觉里程计框架(由单幅图像中每个像素的视觉显著性定义,越接近红色,视觉显著性的程度越高),其通过语义分割结果进行过滤。事实上,正是这种混合地图(集成了视觉显著性图和语义分割图)因此驱动了特征选择过程。通过这样的鲁棒特征点(由该混合地图选择),测试了视觉里程计的鲁棒性。详情请见Liang等人的研究。
在研究【95】中,由于临时物体不应该在环境地图中进行维护,来自停车车辆的特征点不再被用于建图。此外,这样没有临时对象的地图,在长期定位任务(lifelong localization tasks)中具有更好的鲁棒性。
信息性区域特征选择 Informative Region Feature Selection。在信息熵低的区域,通过特征点并不能大大提高姿态估计的精度。使用这些特征进行跟踪将因此增加错误数据关联(Faulty Data Association)的风险。Ganti和Waslander【97】提出了一种信息理论特征选择方法(information-theoretic feature selection method),通过引入语义分割的不确定性概念来计算信息熵。这立即减少了特征的数量,从而显著提高了系统的实时性和鲁棒性,而不明显地影响精度。
动态特征选择 Dynamic Feature Selection。从图像中提取的特征点可能属于动态对象(即所谓的动态特征点),这大大降低了视觉SLAM系统的鲁棒性。幸运的是,高级语义可以有效地执行平稳特征点和动态特征点的划分(即所谓的运动分割(Motion Segmentation)),从而使某些积极机制在视觉SLAM系统具有增强鲁棒性的动态场景中起作用。
Reddy等人【94】采用多层稠密CRF工具对图像进行分割。可区分的静止特征表现出静止,使得单独跟踪静止特征点成为可能。因此,一个鲁棒的视觉里程计可以适用于动态的场景。针对动态环境的SLAM寻求联合语义分割(Joint Semantic Segmentation)和运动一致性检查(Moving Consistency Check),以剔除最初存在于动态对象中的ORB特征点,它不仅在动态环境中的准确性和鲁棒性方面优于ORB-SLAM2,而且为了进一步的三维表示构建了稠密的语义八叉树地图。此外,Li和Qin【96】提出了一个轻量级的3D Box推理工具,在他们的研究中,传统的语义分割对于实时语义推理甚至不再是必要的。
4.2 优化数据关联 Optimized Data Association
在视觉SLAM框架中,在更新频率(update frequency)方面,数据关联可以分为两类:短期关联(short-term association,如特征匹配)和长期关联(long-term association,如闭环检测)。这种机制确保了最大限度数据关联的可靠性。然而,在闭环检测失败的情况下(例如无人驾驶车辆在长长的直线道路上行驶),视觉里程计将不可逆地发生漂移,从而导致导航系统的发散。对语义SLAM的研究【99】提出了基于中期关联机制(medium-term association)的图像语义。从实验角度来看,该机制在很大程度上减少了无人驾驶场景中视觉里程计的平移漂移。这种基于图像语义机制的提出面临着几个问题。Bowman等人【49】在应用中发现了这种语义关联存在的缺陷,即对象语义的无效数据关联极大地影响了定位和建图的结果。因此,他们提出了一种所谓的概率数据关联机制(Probabilistic Data Association Mechanism)充分考虑数据关联过程中的不确定性。
4.3 开放性问题 Open Problems
主流语义SLAM方法通过特征选择或优化数据关联,提高视觉里程计的鲁棒性。然而,随着算法的全面改进,通过纯特征选择或数据关联优化来增强视觉里程计鲁棒性的努力似乎并不令人满意。最近,基于CNN的特征提取器似乎在CV领域很明显,它们导致了手工解决方案从未得到的更鲁棒的视觉特征。受此启发,SLAM领域的研究人员现在正在尝试通过这样学习到的特征来重构视觉里程计,以大大提高VO的鲁棒性。按照这一思路,我们相信追求增强特征稳定性和泛化能力将会一直持续。
5. 可靠导航:准确性 Reliable Navigation:Accuracy
定位和建图的准确性可以对自主导航系统的可靠性进行评估。一般来说,如果它想要提高准确性,语义可以包含在几乎所有的经典SLAM算法框架的会话中,如初始化、后端优化、重定位、闭环检测等。在进行详细的讨论之前,请参见本节,我们想首先总结一下致力于提高准确性的相关语义SLAM研究,如表6所示。
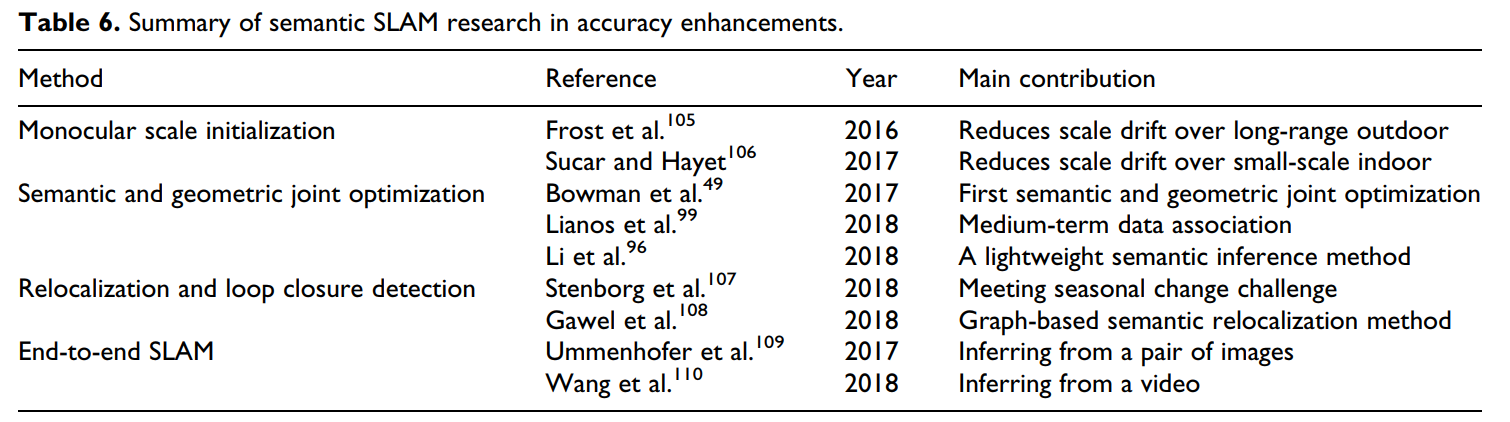
表6. 在准确率增强方面语义SLAM研究摘要
5.1 单目尺度初始化 Monocular Scale Initialization
由于图像之间没有绝对的基线长度,单目视觉SLAM系统的尺度不可避免地显得既模糊,又随着时间而漂移。因此,单目视觉SLAM初始化发展的一个关键问题将是如何纠正尺度模糊和漂移。这两项研究【105,106】的亮点在于,它们同时引入了图像语义的概念。作为图像语义的一种形式,对象的大小已被充分考虑且单目尺度初始化过程被认为是更有效的和优良的简洁。基于公共数据集的实验结果也验证了其在较大范围内的有效性,即小物体室内场景或大物体远程的室外场景。
5.2 语义和几何联合优化 Semantic and Geometric Joint Optimization
Bowman等人提出了最重要的紧耦合的语义和几何联合优化框架之一,他开创了概率数据关联模型的思想。如果连续和离散数据都已经涉及到数据关联任务,那么就不可能直接通过MLE最大似然估计方法解决。为此,作者巧妙地将他们的主要问题分解为子问题,即他们将所谓的混合关联划分为两个过程:离散的语义关联(discrete semantic association)和连续的姿态估计(continuous pose estimation)。利用典型的期望最大EM算法,可以很容易地解决这一两步迭代计算问题。此外,通过目标检测提取的语义的主要重要性是它们在后端优化中发挥了作用。
Linaos等人【99】提出了在SLAM后端加入语义(通过语义分割提取)的思想之一。鉴于2D物体的边界不能精确地表示匹配的3D物体的边界,Linaos的理论被认为在实际应用中更为有效。最新的研究利用2D物体检测结果来推断3D物体的bounding box。从工程的角度来看,这种策略甚至可以被实时语义SLAM系统所接受,因为这些系统的准确性需求可能会适度宽松。
5.3 重定位与闭环检测 Relocalization and Loop Closure Detection
重定位和闭环检测通常采用相同的技术;然而,它们处理的问题却不同。重定位的目的是恢复相机的位姿,而闭环检测的功能是推导出几何一致的地图。不管各个技术的功能有多不同,我们通常关注的是相同的理论。因此,本小节致力于描述基于语义的重定位算法,主要遵循面向应用的思路。
几何定位的主要局限性在于它长期适用于在预先构建地图内可变场景中的定位。然而,基于语义的解决方案解决这个具有挑战性的问题的答案。证据可以从最近的一项研究【107】中看到,其中提出了一种基于语义的跨季节定位算法。原则上,几何定位方法依赖于图像外观之间的相似性,这显然让研究人员面临着,即使这些图像是在相同的位置下采集的,季节的变化似乎足以使有些图像无法识别,从而使匹配的关系变得不可靠。在这种情况下,语义当然会让人想起,而跨季节定位研究的重要贡献之一是,单一图像中语义对象的拓扑结构会随着时间的推移是一致的。这种跨季节定位方法在应用于无人驾驶车辆时似乎足够可靠。Gawel等人【108】提出了一种新的基于图的语义重定位思想,在该系统中,将具有语义的关键帧转换为大量的三维图,这些三维图是用于进一步匹配周围的全局预构建的地图。
除了季节的变化外,语义的引入也有助于处理更大视点或光照的变化,甚至是由时间引起的场景部分结构变化。这种重定位和闭环检测方案验证了视觉SLAM系统的精度提升,作为一个额外的优点。
5.4 开放性问题 Open Problems
部分语义SLAM研究人员关注基于深度学习的解决方案的方案设计,从而构建一个可训练的端到端SLAM系统。近年来,人们一直试图通过CNN来估计单一图像的深度【111-113】。即使已经证明了其可行性,但限制CNN的泛化能力所造成的困难仍然是一个固有的病态问题。研究人员努力的方向是利用一些端到端的方案,从一对图像中共同估计深度和相机运动。此外,Wang和Clark【110】(2018)提供了另一种替代解决方案,可以参考进一步的研究,它直接从视频中推断出位姿和不确定性。
从他们的实验中,我们已经了解到了分层网络的设计,仔细的参数配置和充分的训练,可以对给定的数据集产生最好的准确性。与此同时,反对者仍然站在争论pipeline-formed的SLAM在实际应用中的性能不佳;他们强调“可解释性”和“泛化能力”问题。为此,研究人员现在正在研究深度学习建模方法,以获得更好的可解释性和多维可视化。
6. 讨论 Discussions
在前一节中,目前已经提到了与语义SLAM的感知、鲁棒性和准确性相关的问题。此外,在用于SLAM性能增强的技术工具中,还提出了对应的开放性问题。本综述主要关注的问题之一是从宏观的角度提出上述开放性问题的可行解决方案。因此,这整个部分是致力于一个宏观的讨论。它主要与多尺度地图表达(Multiscaled Map Expression)、Object SLAM、弱监督和无监督学习SLAM有关。
6.1 多尺度地图表达 Multiscaled Map Expression
我们相信,时间尺度的地图有助于机器人的长期自主定位。几年来,视觉SLAM的倡导者一直忽视了他们研究中存在的问题。例如,在地图表达的过程中没有考虑到图像序列中的时空上下文(Spatiotemporal Context,STC),这使得它不可能重建预期的时变语义地图。近年来,对递归神经网络(RNN)的研究有助于发展图像序列中STC时空上下文的思想【114】;从我们的角度来看,RNN同样可以被引入到需要具有强大自主性的长期定位的视觉SLAM的建图任务中。
连同时变地图(包含在一定时间段内的整个环境信息),全景语义地图构成了多尺度表达的主要形式。如果希望在视觉SLAM框架内构建一个全景语义地图,则需要从全局的角度来对关键帧进行语义分割。作为计算机视觉社区的困难之一,已经开发了几种像素级分割前景对象的方法。然而,统一前景和背景标签的问题仍然存在。越来越多的全景分割网络【93】是这类问题的解决方案。它通过融合来自语义分割和实例分割的结果来产生全局约束标签,可以更好地理解被感知的事物,因此,就达到了预期的效果。
根据以上分析,在语义SLAM领域,我们相信多尺度地图的发展前景,它在高级人-机-环境以及长期自主定位中具有相同的一般特性。
6.2 对象SLAM
从我们的角度来看,DNN是提高视觉里程计鲁棒性的新颖但不切实际的方法。在大多数情况下,由于过分强调特征点的鲁棒性,过度训练的DNN方案不仅产生意外的时间消耗,而且在全新的场景下某些SLAM任务中显示出不可用性。一个可靠的对象SLAM框架如图6所示,其中建立了对三维场景中单个对象的独立跟踪。它以二维到三维和单线程到多线程的方式实现了有效的特征选择和数据关联,从而实际提高了视觉里程计VO算法的鲁棒性和准确性。
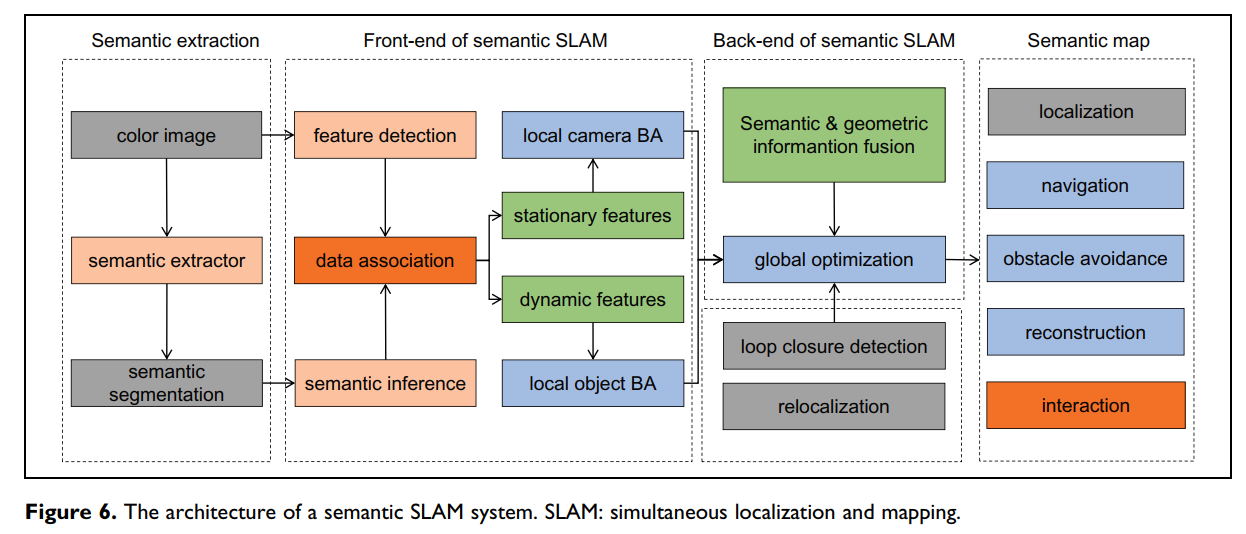
图6. 一个语义SLAM系统的架构
SLAM++【78】是Object SLAM领域最早的研究。由于需要预先构建对象数据集,因此SLAM++对于在线任务仍然无效。最近,在SLAM++上的研究可以沿两个方向发展:一个用立方体描述对象的CubeSLAM【102】,另一个用椭球体描述对象的QuadricSLAM【103】。
我们认为Object SLAM具有广阔的应用前景,整个过程的重点是直接跟踪三维场景下的动态目标。随着3D目标跟踪在CV领域快速发展(包括一个3D语义估计器),有理由相信它同时有助于构建一个更高效的目标SLAM系统。
6.3 弱监督和无监督学习SLAM
利用现有的数据集,端到端语义SLAM方案通常会产生最优的定位精度,但其可解释性和泛化能力限制了其在更广泛的应用中的适用性。以DNN为例,由于参数配置和训练过于细致,泛化能力的降低往往伴随着过拟合。基于弱监督和无监督学习的方案已被用于提高DNN的泛化能力。然而,该研究仍处于初步阶段。事实上,在端到端SLAM领域中,基于无监督学习的单目深度估计已经被认为是一个主要的研究方向,与此同时,机器学习专家的兴趣现在都集中在DNN的可解释性上。这些线索使我们相信,高级学习策略将是语义SLAM方案的强大和实用的工具。重要的是要理解语义SLAM方案可以易于集成到深度强化学习范式中,构建一个具有一般智能的机器人系统。
7. 总结 Conclusions
对于自主机器人导航任务,一种旨在更好地理解和感知来自机器人工作量的信息的语义SLAM已经引起了越来越多的关注。在本综述中,我们回顾了语义SLAM的感知、鲁棒性和准确性的发展,并讨论了与最近的进展和挑战相关的开放性问题。具体来说,我们试图从宏观的角度寻求这些开放问题可能的解决方案,并以建设性的方式进一步陈述这些建议。我们相信SLAM框架都是通过实践来建立和证明的,而语义SLAM将通过图像语义的显著融合而区分自己。基于深度学习的方法的发展显然为研究人员利用了机会,利用他们强大的图像处理能力来估计姿态,检测闭环,构建3D地图等等。从我们的角度来看,深度学习和语义SLAM现在是不可分割的联系,它们的混合在未来的研究中一定会蓬勃发展。
References
1. Smith RC and Cheeseman P. On the representation and estimation of spatial uncertainty. Int J Robot Res 1986; 5(4): 56–68.
2. Gu ZP and Liu H. A survey of monocular simultaneous localization and mapping. CAAI Trans Intell Syst 2015; 10(4): 499–507.
3. Teng ZJ, Qu ZQ, Zhang LY, et al. Research on vehicle navigation BD/DR/MM integrated navigation positioning. J North Electr Power Univ 2017; 37(4): 98–101.
4. Cadena C, Carlone L, Carrillo H, et al. Past, present, and future of simultaneous localization and mapping: toward the robust-perception age. IEEE Trans Robot 2016; 32(6): 1309–1332.
5. Durrant-Whyte H and Bailey T. Simultaneous localization and mapping: part I. IEEE Robot Autom Mag 2006; 13(2): 99–110.
6. Bailey T and Durrant-Whyte H. Simultaneous localization and mapping (slam): part II. IEEE Robot Autom Mag 2006; 13(3): 108–117.
7. Aulinas J, Petillot YR, Salvi J, et al. The slam problem: a survey. CCIA 2008; 184(1): 363–371.
8. Neira J, Davison AJ, and Leonard JJ. Guest editorial special issue on visual slam. IEEE Trans Robot 2008; 24(5): 929–931.
9. Grisetti G, Kummerle R, Stachniss C, et al. A tutorial on graph-based slam. IEEE Intell Transp Syst Mag 2010; 2(4): 31–43.
10. Dissanayake G, Huang SD, Wang Z, et al. A review of recent developments in simultaneous localization and mapping. In: 2011 6th international conference on industrial and information systems (ICIIS 2011), Kandy, Sri Lanka, 16–19 August, 2011, pp. 477–482. Piscataway, NJ, USA: IEEE.
11. Scaramuzza D and Fraundorfer F. Tutorial: visual odometry. IEEE Robot Autom Mag 2011; 18(4): 80–92.
12. Strasdat H, Montiel JM, and Davison AJ. Visual slam: why filter? Image Vision Comput 2012; 30(2): 65–77.
13. Lowry S, Su¨nderhauf N, Newman P, et al. Visual place recognition: a survey. IEEE Trans Robot 2015; 32(1): 1–19.
14. Saeedi S, Trentini M, Seto M, et al. Multiple-robot simultaneous localization and mapping: A review. J Field Robot 2016; 33(1): 3–46.
15. Huang SD and Dissanayake G. A critique of current developments in simultaneous localization and mapping. Int J Adv Robot Syst 2016; 13(5): 1–13.
16. Taketomi T, Uchiyama H, and Ikeda S. Visual slam algorithms: a survey from 2010 to 2016. IPSJ Trans Comput Vis Appl 2017; 9(1): 16.
17. Younes G, Asmar D, Shammas E, et al. Keyframe-based monocular slam: design, survey, and future directions. Robot Auton Syst 2017; 98: 67–88.
18. Saputra MRU, Markham A, and Trigoni N. Visual slam and structure from motion in dynamic environments: a survey. ACM Comput Surv (CSUR) 2018; 51(2): 37.
19. Gallego G, Delbruck T, Orchard G, et al. Event-based vision: a survey. arXiv preprint arXiv:190408405, 2019.
20. Viola P and Jones M. Robust real-time object detection. Int J Comput Vis 2001; 4(34-47): 4.
21. Dalal N and Triggs B. Histograms of oriented gradients for human detection. In: 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR 2005) (eds C Schmid, S Soatto and C Tomasi), San Diego, CA, USA, 20–25 June, 2005, pp. 886–893. Los Alamitos, CA, USA: IEEE.
22. Felzenszwalb PF, Girshick RB, McAllester D, et al. Object detection with discriminatively trained part-based models. IEEE Trans Patt Anal Mach Intell 2009; 32(9): 1627–1645.
23. Girshick RB. From rigid templates to grammars: object detection with structured models. Chicago, IL, USA: University of Chicago, Division of the Physical Sciences, Department of Computer Science, 2012.
24. Lin TY, Doll´ ar P, Girshick R, et al. Feature pyramid networks for object detection. In: 30th IEEE conference on computer vision and pattern recognition (CVPR 2017) (eds R Chellappa, Z Zhang and A Hoogs), Honolulu, HI, USA, 21–26 July, 2017, pp. 936–944. Piscataway, NJ, USA: IEEE.
25. Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation. In: 27th IEEE conference on computer vision and pattern recognition (CVPR 2014), Columbus, OH, USA,
23–28 June, 2014, pp. 580–587. Piscataway, NJ, USA: IEEE. 26. Girshick R. Fast R-CNN. In: 15th IEEE international conference on computer vision (ICCV 2015) (eds R Bajcsy, G Hager
Xia et al. 13and Y Ma), Santiago, Chile, 11–18 December, 2015, pp. 1440–1448. Piscataway, NJ, USA: IEEE.
27. Ren SQ, He KM, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans Patt Anal Mach Intell 2015; 39(6): 1137–1149.
28. He KM, Gkioxari G, Doll´ ar P, et al. Mask R-CNN. In: 2017 IEEE international conference on computer vision (ICCV 2017) (ed K Ikeuchi), Venice, Italy, 22–29 October, 2017,
pp. 2980–2988. Los Alamitos, CA, USA: IEEE.
29. Hosang J, Benenson R, Dollar P, et al. What makes for effective detection proposals? IEEE Trans Patt Anal Mach Intell 2016; 38(4): 814–830.
30. Krizhevsky A, Sutskever I, and Hinton GE. Imagenet classification with deep convolutional neural networks. In: 26th annual conference on neural information processing systems
2012 (NIPS 2012) (eds P Bartlett, FCN Pereira, CJC Burges,
L Bottou and KQ Weinberger), Lake Tahoe, NV, USA, 3–6 December, 2012, pp. 1097–1105. Red Hook, NY, USA: Curran Associates.
31. Vapnik V and Lerner AY. Recognition of patterns with help of generalized portraits. Avtomat i Telemekh 1963; 24(6): 774–780.
32. Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection. In: 29th IEEE conference on computer vision and pattern recognition (CVPR 2016) (eds R Bajcsy, L Fei-Fei and T Tinne), Las Vegas, NV, USA, 26 June–1 July, 2016, pp. 779–788.
Piscataway, NJ, USA: IEEE.
33. Redmon J and Farhadi A. Yolo9000: better, faster, stronger. In: 30th IEEE conference on computer vision and pattern recognition (CVPR 2017) (eds C Rama, Z Zhengyou and H Anthony), Honolulu, HI, USA, 21–26 July, 2017, pp. 6517–6525. Piscataway, NJ, USA: IEEE.
34. Redmon J and Farhadi A. Yolov3: an incremental improvement. arXiv preprint arXiv:180402767, 2018.
35. Duan KW, Bai S, Xie LX, et al. Centernet: keypoint triplets for object detection. In: 2019 IEEE/CVF international conference on computer vision (ICCV 2019), Seoul, Korea (South), 27 October–2 November, 2019, pp. 6568–6577. IEEE.
36. Hu JP, Li L, Xie Q, et al. A novel segmentation approach for glass insulators in aerial images. J North Electr Power Univ 2018; 38(2): 87–92.
37. Long J, Shelhamer E, and Darrell T. Fully convolutional networks for semantic segmentation. In: IEEE conference on computer vision and pattern recognition (CVPR 2015), Boston, MA, USA, 7–12 June, 2015, pp. 3431–3440. Los Alamitos, CA, USA: IEEE Computer Society.
38. Badrinarayanan V, Kendall A, and Cipolla R. Segnet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans Patt Anal Mach Intell 2017; 39(12): 2481–2495.
39. Chen LC, Papandreou G, Kokkinos I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFS. arXiv preprint arXiv:14127062, 2014.
40. Chen LC, Papandreou G, Kokkinos I, et al. Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFS. IEEE Trans Patt Anal Mach Intell 2017; 40(4): 834–848.
41. Chen LC, Papandreou G, Schroff F, et al. Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:170605587, 2017.
42. Chen LC, Zhu YK, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation. In: 15th European conference on computer vision (ECCV 2018) (eds V Ferrari, M Hebert, C Sminchisescu and Y Weiss), Munich, Germany, 8–14 September, 2018, pp. 833–851. Cham, Switzerland: Springer.
43. Paszke A, Chaurasia A, Kim S, et al. ENet: a deep neural network architecture for real-time semantic segmentation. arXiv preprint arXiv:160602147, 2016.
44. Qi CR, Su H, Mo KC, et al. PointNet: Deep learning on point sets for 3D classification and segmentation. In: 30th IEEE conference on computer vision and pattern recognition (CVPR 2017) (eds R Chellappa, Z Zhang and A Hoogs), Honolulu, HI, USA, 21–26 July, 2017, pp. 77–85. Piscataway, NJ, USA: IEEE.
45. Shelhamer E, Rakelly K, Hoffman J, et al. Clockwork convnets for video semantic segmentation. In: 14th European conference on computer vision (ECCV 2016) (eds B Leibe, J Matas, N Sebe and M Welling), Amsterdam, the Netherlands, 11–14 October, 2016, pp. 852–868. Cham, Switzerland: Springer.
46. Yu C, Liu ZX, Liu XJ, et al. DS-SLAM: a semantic visual slam towards dynamic environments. In: 2018 IEEE/RSJ international conference on intelligent robots and systems (IROS 2018) (ed NR Gakkai), Madrid, Spain, 1–5 October, 2018, pp. 1168–1174. Piscataway, NJ, USA: IEEE.
47. Li XP and Belaroussi R. Semi-dense 3D semantic mapping from monocular slam. arXiv preprint arXiv:161104144, 2016.
48. McCormac J, Handa A, Davison A, et al. SemanticFusion: dense 3D semantic mapping with convolutional neural networks. In: 2017 IEEE international conference on robotics and automation (ICRA 2017), Singapore, Singapore, 29 May–3 June, 2017, pp. 4628–4635. Piscataway, NJ, USA: IEEE.
49. Bowman SL, Atanasov N, Daniilidis K, et al. Probabilistic data association for semantic SLAM. In: 2017 IEEE international conference on robotics and automation (ICRA 2017), Singapore, Singapore, 29 May–3 June, 2017, pp. 1722–1729. Piscataway, NJ, USA: IEEE.
50. Lu F and Milios E. Globally consistent range scan alignment for environment mapping. Auton Robot 1997; 4(4): 333–349.
51. Gutmann JS and Konolige K. Incremental mapping of large cyclic environments. In: 1999 IEEE international symposium on computational intelligence in robotics and automation (CIRA’99), Monterey, CA, USA, 8–9 November, 1999, pp. 318–325. Piscataway, NJ, USA: IEEE.
52. Davison AJ, Reid ID, Molton ND, et al. MonoSLAM: realtime single camera SLAM. IEEE Trans Patt Anal Mach Intell 2007; 29(6): 1052–1067. 14 International Journal of Advanced Robotic Systems
53. Klein G and Murray D. Parallel tracking and mapping for small AR workspaces. In: 2007 6th IEEE and ACM international symposium on mixed and augmented reality (ISMAR) (eds Nihon-Ba¯charu-Riariti-Gakkai), Nara, Japan, 13–16 November, 2007, pp. 225–234. Piscataway, NJ, USA: IEEE.
54. Newcombe RA, Izadi S, Hilliges O, et al. KinectFusion: realtime dense surface mapping and tracking. In: 2011 10th IEEE
international symposium on mixed and augmented reality (ISMAR 2011), Basel, Switzerland, 26–29 October, 2011, pp. 127–136. Piscataway, NJ, USA: IEEE.
55. Whelan T, Kaess M, Fallon M, et al. Kintinuous: spatially extended kinectfusion. In: 3rd RSS workshop on RGB-D: advanced reasoning with depth cameras, Sydney, Australia, 9–13 July, 2012, pp. 5724–5731.
56. Endres F, Hess J, Sturm J, et al. 3-D mapping with an RGB-D camera. IEEE Trans Robot 2013; 30(1): 177–187.
57. Engel J, Scho¨ps T, and Cremers D. LSD-SLAM: large-scale direct monocular SLAM. In: 13th European conference on computer vision (ECCV 2014) (ed D Fleet), Zurich, Switzerland, 6–12 September, 2014, pp. 834–849. Cham, Switzerland: Springer.
58. Forster C, Pizzoli M, and Scaramuzza D. SVO: fast semidirect monocular visual odometry. In: 2014 IEEE international conference on robotics and automation (ICRA 2014), Hong Kong, China, 31 May–7 June, 2014, pp. 15–22. Piscataway, NJ, USA: IEEE.
59. Labbe M and Michaud F. Online global loop closure detection for large-scale multi-session graph-based SLAM. In: 2014 IEEE/RSJ international conference on intelligent robots and systems (IROS 2014) (ed W Burgard), Chicago, IL, USA, 14–18 September, 2014, pp. 2661–2666. Piscataway, NJ, USA: IEEE.
60. Labb´ e M and Michaud F. RTAB-MAP as an open-source lidar and visual simultaneous localization and mapping library for large-scale and long-term online operation. J Field Robot 2019; 36(2): 416–446.
61. Whelan T, Salas-Moreno RF, Glocker B, et al. Elasticfusion: real-time dense slam and light source estimation. Int J Robot Res 2016; 35(14): 1697–1716.
62. Mur-Artal R, Montiel JMM, and Tardos JD. ORB-SLAM: a versatile and accurate monocular SLAM system. IEEE Trans Robot 2015; 31(5): 1147–1163.
63. Mur-Artal R and Tard´ os JD. ORB-SLAM2: an open-source SLAM system for monocular, stereo, and RGB-D cameras. IEEE Trans Robot 2017; 33(5): 1255–1262.
64. Engel J, Koltun V, and Cremers D. Direct sparse odometry. IEEE Trans Patt Anal Mach Intell 2017; 40(3): 611–625.
65. Dai A, Nießner M, Zollho¨fer M, et al. Bundlefusion: real-time globally consistent 3D reconstruction using on-the-fly surface reintegration. ACM T Graphics (ToG) 2017; 36(3): 24.
66. Schlegel D, Colosi M, and Grisetti G. ProSLAM: Graph SLAM from a programmer’s perspective. In: 2018 IEEE international conference on robotics and automation (ICRA 2018) (ed K Lynch), Brisbane, Queensland, Australia, 21–25 May, 2018, pp. 3833–3840. Piscataway, NJ, USA: IEEE.
67. Sumikura S, Shibuya M, and Sakurada K. OpenVSLAM: a versatile visual slam framework. In: 27th ACM international conference on multimedia (MM 2019) (eds L Amsaleg, et al.), Nice, France, 21–25 October, 2019, pp. 2292–2295. New York, NY, USA: ACM.
68. Valentin JP, Sengupta S, Warrell J, et al. Mesh based semantic modelling for indoor and outdoor scenes. In: 26th IEEE conference on computer vision and pattern recognition (CVPR 2013), Portland, OR, USA, 23–28 June, 2013, pp. 2067–2074. Piscataway, NJ, USA: IEEE.
69. Sengupta S, Greveson E, Shahrokni A, et al. Urban 3D semantic modelling using stereo vision. In: 2013 IEEE international conference on robotics and automation (ICRA 2013), Karlsruhe, Germany, 6–10 May, 2013, pp. 580–585. Piscataway, NJ, USA: IEEE.
70. Vineet V, Miksik O, Lidegaard M, et al. Incremental dense semantic stereo fusion for large-scale semantic scene reconstruction. In: 2015 IEEE international conference on robotics and automation (ICRA 2015), Seattle, WA, USA, 26–30 May, 2015, pp. 75–82. Piscataway, NJ, USA: IEEE.
71. Zhao Z and Chen XP. Building 3D semantic maps for mobile robots using RGB-D camera. Intell Ser Robot 2016; 9(4): 297–309.
72. Yang SC, Huang YL, and Scherer S. Semantic 3D occupancy mapping through efficient high order CRFS. In: 2017 IEEE/ RSJ international conference on intelligent robots and systems (IROS 2017), Vancouver, BC, Canada, 24–28 September, 2017, pp. 590–597. Piscataway, NJ, USA: IEEE.
73. Runz M, Buffier M, and Agapito L. MaskFusion: real-time recognition, tracking and reconstruction of multiple moving objects. In: 17th IEEE international symposium on mixed and augmented reality (ISMAR 2018), Munich, Germany, 16–20 October, 2018, pp. 10–20. Los Alamitos, CA, USA: IEEE.
74. Narita G, Seno T, Ishikawa T, et al. Panopticfusion: online volumetric semantic mapping at the level of stuff and things. arXiv preprint arXiv:190301177, 2019.
75. Castle RO, Gawley DJ, Klein G, et al. Towards simultaneous recognition, localization and mapping for hand-held and wearable cameras. In: 2007 IEEE international conference on robotics and automation (ICRA’07), Roma, Italy, 10–14
April, 2007, pp. 4102–4107. Piscataway, NJ, USA: IEEE. 76. Castle RO, Klein G, and Murray DW. Combining MonoSLAM with object recognition for scene augmentation using a wearable camera. Image Vision Comput 2010; 28(11):
1548–1556.
77. Civera J, G´ alvez-L´ opez D, Riazuelo L, et al. Towards semantic SLAM using a monocular camera. In: 2011 IEEE/RSJ international conference on intelligent robots and systems: celebrating 50 years of robotics (IROS’11) (ed Amato NM), San Francisco, CA, USA, 25–30 September, 2011, pp.
1277–1284. Piscataway, NJ, USA: IEEE.
- Salas-Moreno RF, Newcombe RA, Strasdat H, et al. Slamþþ: simultaneous localisation and mapping at the level of objects. In: 26th IEEE conference on computer vision and pattern recognition (CVPR 2013), Portland, OR, USA, 23–28 June, 2013, pp. 1352–1359. Piscataway, NJ, USA: IEEE. Xia et al. 15
79. Xiong XH and Huber D. Using context to create semantic 3D models of indoor environments. In: 2010 21st British machine vision conference (BMVC 2010) (eds F Labrosse, R Zwiggelaar, Y Liu and B Tiddeman), Aberystwyth, UK, 31 August–3 September, 2010, pp. 1–11. Cambridge, UK: British Machine Vision Association (BMVA).
80. Koppula HS, Anand A, Joachims T, et al. Semantic labeling of 3D point clouds for indoor scenes. In: 25th annual conference on neural information processing systems 2011 (NIPS 2011) (ed JS Taylor), Granada, Spain, 12–14 December, 2011, pp. 244–252. Red Hook, NY, USA: Curran Associates.
81. Stu¨ckler J, Biresev N, and Behnke S. Semantic mapping using object-class segmentation of RGB-D images. In: 25th IEEE/RSJ International Conference on Robotics and Intelligent Systems (IROS 2012), Vilamoura, Portugal, 7–12 October, 2012, pp. 3005–3010. Piscataway, NJ, USA: IEEE.
82. Kostavelis I and Gasteratos A. Learning spatially semantic representations for cognitive robot navigation. Robot Auton Syst 2013; 61(12): 1460–1475.
83. Couprie C, Farabet C, Najman L, et al. Indoor semantic segmentation using depth information. arXiv preprint arXiv: 13013572, 2013.
84. Anand A, Koppula HS, Joachims T, et al. Contextually guided semantic labeling and search for three-dimensional point clouds. Int J Robot Res 2013; 32(1): 19–34.
85. Li GQ, Zhang Y, Zhang MJ, et al. The wind power real-time diction on the EEMD and SVM of the MRMR. J North Electr Power Univ 2017; 37(2): 39–44.
86. Yang M, Huang BY, Jiang B, et al. Real-time prediction for wind power based on Kalman filter and support vector machines. J North Electr Power Univ 2017; 37(2): 45–51.
87. Yang M, Chen XX, Zhang Q, et al. A review of short-term wind speed prediction based on support vector machine. J North Electr Power Univ 2017; 37(4): 1–7.
88. Ying H, Jiang LL, Li X, et al. Transient stability assessment in bulk power grid using v-nonparallel support vector machine. J North Electr Power Univ 2018; 38(5): 31–40.
89. Cui TX, Zhou XL, Liu WH, et al. Gear fault diagnosis based on Hilbert envelope spectrum and SVM. J North Electr Power Univ 2017; 37(6): 56–61.
90. Deng J, Dong W, Socher R, et al. Imagenet: a large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition, Miami, FL, USA, 20–25 June, 2009, pp. 248–255. Piscataway, NJ, USA: IEEE.
91. He KM, Zhang XY, Ren SQ, et al. Deep residual learning for image recognition. In: 29th IEEE conference on computer vision and pattern recognition (CVPR 2016) (eds Z Bajcsy, FF Li and T Tuytelaars), Las Vegas, NV, USA, 26 June–1 July, 2016, pp. 770–778. Piscataway, NJ, USA: IEEE.
92. Zheng S, Jayasumana S, Romera-Paredes B, et al. Conditional random fields as recurrent neural networks. In: 15th IEEE international conference on computer vision (ICCV 2015) (eds R Bajcsy, G Hager and Y Ma), Santiago, Chile, 11–18 December, 2015, pp. 1529–1537. Piscataway, NJ, USA: IEEE.
93. Gupta S, Arbel´ aez P, Girshick R, et al. Indoor scene understanding with RGB-D images: bottom-up segmentation, object detection and semantic segmentation. Int J Comput Vis 2015; 112(2): 133–149.
94. Reddy ND, Singhal P, Chari V, et al. Dynamic body VSLAM with semantic constraints. In: IEEE/RSJ international conference on intelligent robots and systems (IROS 2015) (ed W Burgard), Hamburg, Germany, 28 September– 2 October, 2015, pp. 1897–1904. Piscataway, NJ, USA:
IEEE.
95. Murali V, Chiu HP, Samarasekera S, et al. Utilizing semantic visual landmarks for precise vehicle navigation. In: 20th IEEE international conference on intelligent transportation systems (ITSC 2017) (eds E Rocklage, H Kraft, A Karatas and S Jorg), Yokohama, Japan, 16–19 October, 2017, pp. 1–8. Piscataway, NJ, USA: IEEE.
96. Li PL, Qin T, and Shen HJ. Stereo vision-based semantic 3D object and ego-motion tracking for autonomous driving. In: 15th European conference on computer vision (ECCV 2018) (eds V Ferrari, M Hebert, C Sminchisescu and Y Weiss), Munich, Germany, 8–14 September, 2018, pp. 664–679. Cham, Switzerland: Springer.
97. Ganti P and Waslander SL. Visual SLAM with network uncertainty informed feature selection. arXiv preprint arXiv:181111946, 2018.
98. Liang HJ, Sanket NJ, Fermu¨ller C, et al. SalientDSO: bringing attention to direct sparse odometry. IEEE Trans Autom Sci Eng 2019; 16(4): 1619–1626. 99. Lianos KN, Schonberger JL, Pollefeys M, et al. VSO: visual semantic odometry. In: 15th European conference on computer vision (ECCV 2018) (eds V Ferrari, M Hebert, C Sminchisescu and Y Weiss), Munich, Germany, 8–14 September, 2018, pp. 246–263. Cham, Switzerland: Springer.
100. Yi KM, Trulls E, Lepetit V, et al. Lift: learned invariant feature transform. In: 21st ACM conference on computer and communications security (CCS 2014) (ed GJ Ahn), Scottsdale, AZ, USA, 3–7 November, 2014, pp. 467–483. New York, NY, USA: ACM.
101. DeTone D, Malisiewicz T, and Rabinovich A. Superpoint: self-supervised interest point detection and description. In: 31st meeting of the IEEE/CVF conference on computer vision and pattern recognition workshops (CVPRW 2018), Salt Lake City, UT, USA, 18–22 June, 2018, pp. 337–349. Los Alamitos, CA, USA: IEEE.
102. Yang SC and Scherer S. CubeSLAM: monocular 3-D object SLAM. IEEE Trans Robot 2019; 35(4): 925–938.
103. Nicholson L, Milford M, and Su¨nderhauf N. QuadricSLAM: dual quadrics from object detections as landmarks in objectoriented SLAM. IEEE Robot Autom Lett 2018; 4(1): 1–8.
104. Xue L, Huang NT, Zhao SY, et al. Low redundancy feature selection using conditional mutual information for shortterm load forecasting. J North Electr Power Univ 2019; 39(2): 30–38.
105. Frost DP, Ka¨hler O, and Murray DW. Object-aware bundle adjustment for correcting monocular scale drift. In: 2016 IEEE international conference on robotics and automation 16 International Journal of Advanced Robotic Systems(ICRA 2016), Stockholm, Sweden, 16–21 May, 2016, pp. 4770–4776. Piscataway, NJ, USA: IEEE.
106. Sucar E and Hayet JB. Probabilistic global scale estimation for monoSLAM based on generic object detection. In: 30th IEEE conference on computer vision and pattern recognition workshops (CVPRW 2017), Honolulu, HI, USA, 21–26 July, 2017, pp. 988–992. Los Alamitos, CA, USA: IEEE.
107. Stenborg E, Toft C, and Hammarstrand L. Long-term visual localization using semantically segmented images. In: 2018 IEEE international conference on robotics and automation (ICRA 2018) (ed L Kevin), Brisbane, Queensland, Australia, 21–25 May, 2018, pp. 6484–6490. Piscataway, NJ, USA: IEEE.
108. Gawel A, Del Don C, Siegwart R, et al. X-view: graph-based semantic multi-view localization. IEEE Robot Autom Lett 2018; 3(3): 1687–1694.
109. Ummenhofer B, Zhou HZ, Uhrig J, et al. Demon: depth and motion network for learning monocular stereo. In: 30th IEEE conference on computer vision and pattern recognition (CVPR 2017) (eds R Chellappa, Z Zhang and A Hoogs), Honolulu, HI, USA, 21–26 July, 2017, pp. 5622–5631. Piscataway, NJ, USA: IEEE.
110. Wang S, Clark R, Wen HK, et al. End-to-end, sequence-tosequence probabilistic visual odometry through deep neural networks. Int J Robot Res 2018; 37(4-5): 513–542.
111. Eigen D, Puhrsch C, and Fergus R. Depth map prediction from a single image using a multi-scale deep network. In: 28th annual conference on neural information processing systems 2014 (NIPS 2014) (ed M Welling), Montreal, Canada, 8–13 December, 2014, pp. 2366–2374. New York, NY, USA: Curran Associates.
112. Eigen D and Fergus R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In: 15th IEEE international conference on computer vision (ICCV 2015) (eds R Bajcsy, G Hager and Y Ma), Santiago, Chile, 11–18 December, 2015, pp. 2650–2658. Piscataway, NJ, USA: IEEE.
113. Liu F, Shen CH, Lin GS, et al. Learning depth from single monocular images using deep convolutional neural fields. IEEE Trans Patt Anal Mach Intell 2015; 38(10): 2024–2039.
114. Sun B, Qiao C, Yang D, et al. Prediction method of thermal conductivity of nanofluids based on deep belief network. J North Electr Power Univ 2019; 39(1): 41–48.
115. Kuznietsov Y, Stuckler J, and Leibe B. Semi-supervised deep learning for monocular depth map prediction. In: 30th IEEE conference on computer vision and pattern recognition (CVPR 2017) (eds R Chellappa, Z Zhang and A Hoogs), Honolulu, HI, USA, 21–26 July, 2017, pp. 2215–2223. Piscataway, NJ, USA: IEEE.
116. Zhan HY, Garg R, Weerasekera CS, et al. Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstruction. In: 31st meeting of the IEEE/CVF conference on computer vision and pattern recognition (CVPR 2018), Salt Lake City, UT, USA, 18–22 June, 2018, pp. 340–349. Los Alamitos, CA, USA: IEEE.
117. Wang GM, Wang HS, Liu YL, et al. Unsupervised learning of monocular depth and ego-motion using multiple masks. In: 2019 international conference on robotics and automation (ICRA 2019), Montreal, Qu´ ebec, Canada, 20–24 May, 2019, pp. 4724–4730. Piscataway, NJ, USA: IEEE

