
- 1[Linux] Samba服务器配置 安全级别为share_security = share
- 2Ubuntu 18.04 LTS安装vncserver虚拟网络控制台_vncserver ubuntu vm
- 3二维大地电磁有限元数值模拟矩形+线性插值_如何学习matlab
- 4C++Primer_课后习题第九章_对于下面的程序任务,vector、deque 和 list 哪种容器最为合适?解释你 的选择的理
- 5Java多线程 - 线程安全和线程同步解决线程安全问题_java模拟线程安全
- 6毕业设计-基于机器视觉的木材表面缺陷检测-OpenCV_基于机器学习的木材缺陷检测
- 7Excel简单宏定义(Microsoft 版)(快速合并多个表格,合并多个工作表,合并特定工作表)_sub 合并当前工作簿下的所有工作表()on error resume nextapplicatio
- 8samba服务器配置及常见错误解决(fedora)_fedora14 samba连不上
- 9VS2019 编译 paho-mqtt-cpp 遇到的问题_private: static struct mqttasync_createoptions con
- 10史上最全Java面试题大汇总「百题附答案」
零基础如何入门Python爬虫!_零基础如何使用pyshon写一个爬虫
赞
踩
一、爬虫准备(在安装好Python的前提下)
1、爬虫首先需要做的事情就是要确定好你想要爬取数据的对象,这里我将以百度主页logo图片的地址为例进行讲解。
2、首先,是打开百度主页界面,然后把鼠标移动到主页界面的百度logo图标上面,点击鼠标右键,然后点击审查元素,即可打开开发者界面。
3、然后再下面的界面里面,可以看到该logo图标在HTML里面的排版模式

这里百度我用字替换了。
二、开始爬虫
1、爬虫主要分为两个部分,第一个是网页界面的获取,第二个是网页界面的解析;爬虫的原理是利用代码模拟浏览器访问网站,与浏览器不同的是,爬虫获取到的是网页的源代码,没有了浏览器的翻译效果。
2、首先,我们进行页面获取,python爬虫的话很多模块包提供给开发者直接抓取网页,urllib,urllib2,requests(urllib3)等等,这里我们使用urllib2进行网站页面的获取;首先导入urllib2模块包(该包是默认安装的):import urllib2
3、导入模块包之后,然后调用urllib2中的urlopen方法链接网站,代码如下repr = urllib2.urlopen(“XXXXXX”),XXXXXX代表的是网站名称。
4.得到网站的响应之后,然后就是将页面的源代码读取出来,调用read方法,html = repr.read()
5、获取到页面的源代码之后,然后接下来的工作就是将自己想要的数据从html界面源代码中解析出来,解析界面的模块包有很多,原始的re,好用的BeautifulSoup,以及高大上的lxml等等,这里我就简单的用re介绍介绍,首先导入re模块包:import re
6、然后进行利用re进行搜索,这里我有使用正则表达式,看不懂的同学需去补充点正则表达式方面的知识。
7、然后,我这里就实现了一个简单的爬虫流程,打印url,可以看见刚好就是之前我们看见的百度主页logo的地址。
8、源代码:
import urllib2
repr = urllib2.urlopen("URL")
html = repr.read()
import re
省略一行代码
- 1
- 2
- 3
- 4
- 5
最后免费分享给大家一份Python全套学习资料,包含视频、源码,课件,希望能帮到那些不满现状,想提升自己却又没有方向的朋友。
三、关于学习Python的一些资料分享
下面的所有资料已经打包好了,需要的朋友可以到文末扫码免费领取~
1、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
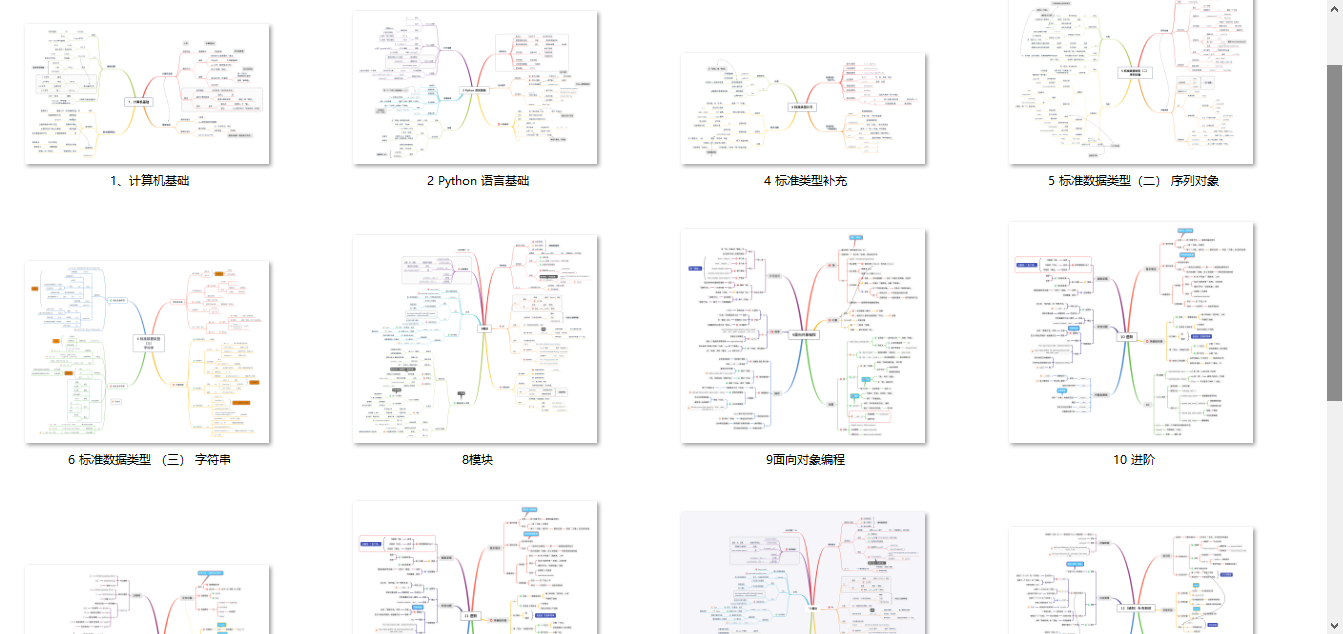
2、Python课程视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
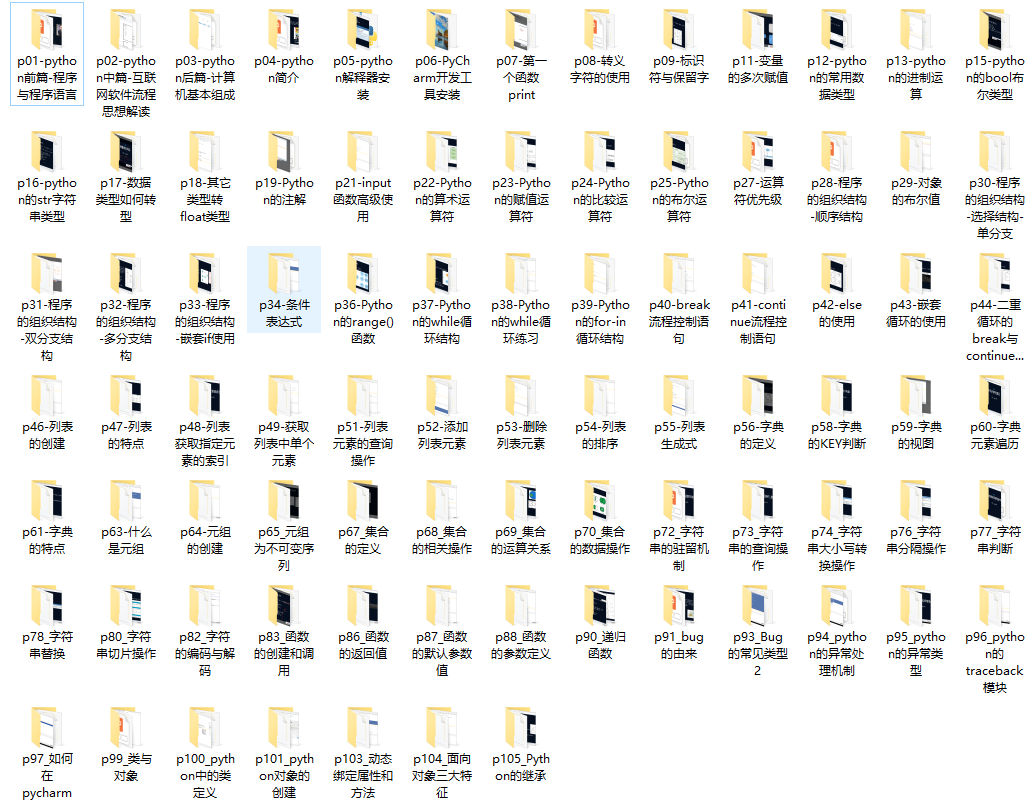
3、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
4、清华编程大佬出品《漫画看学Python》
用通俗易懂的漫画,来教你学习Python,让你更容易记住,并且不会枯燥乏味。
5、Python实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

6、互联网企业面试真题
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
这份完整版的Python全套学习资料已经上传至CSDN官方,朋友们如果需要可以扫描下方二维码免费获取【保证100%免费】

以上全套资料已经为大家打包准备好了,希望对正在学习Python的你有所帮助!
如果你觉得这篇文章有帮助,可以点个赞呀~
我会坚持每天更新Python相关干货,分享自己的学习经验帮助想学习Python的朋友们少走弯路!

