
热门标签
热门文章
- 1ODFM详解(原理+调制解调)_ofdm调制解调原理
- 2Windows环境下使用Nexus-3.16x版本构建Maven私有仓库_nexus nexus-context-path
- 3【网站项目】python009基于推荐算法的电影推荐系统_基于推荐算法的毕业设计
- 4主动攻击与被动攻击和网络安全_主动攻击主要是收集信息而不是进行访问数据的合法用户对这种活动难以察觉
- 5基于Python爬虫吉林长春美食商家数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 6【瑞萨RA_FSP】GPT—— 通用PWM定时器_瑞萨gpt的几种模式
- 7LeetCode题解_653 unique trees found with 2035 total matches
- 8微服务springcloud 01 sts环境,maven管理,和springcloud简介,通用模块commons_springcloud common 模块
- 9ggplot2【1】:全解析_ggplot详解
- 10Typora 开始收费,程序员还能用什么记笔记?
当前位置: article > 正文
LangChain学习:memory_使用conversationbuffermemory无返回
作者:小小林熬夜学编程 | 2024-02-22 10:28:15
赞
踩
使用conversationbuffermemory无返回
learn from https://learn.deeplearning.ai/langchain/lesson/3/memory
1. ConversationBufferMemory
from config import api_type, api_key, api_base, api_version, model_name from langchain.chat_models import AzureChatOpenAI from langchain.chains import ConversationChain from langchain.memory import ConversationBufferMemory model = AzureChatOpenAI( openai_api_base=api_base, openai_api_version=api_version, deployment_name=model_name, openai_api_key=api_key, openai_api_type=api_type, temperature=0.5, ) memory = ConversationBufferMemory() conversation = ConversationChain( llm=model, memory=memory, verbose=True, ) # class ConversationChain(LLMChain)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
开始对话
print(conversation.predict(input="你好,我叫michael"))
print(conversation.predict(input="5.1乘以6等于多少呀"))
print(conversation.predict(input="哦,我忘记我叫什么名字了,你可以告诉我吗?"))
- 1
- 2
- 3
输出
> Entering new chain... Prompt after formatting: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know. Current conversation: Human: 你好,我叫michael AI: > Finished chain. 你好,Michael!很高兴认识你。我是一名AI,可以为你提供帮助和答案。你有什么问题或需求吗? > Entering new chain... Prompt after formatting: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know. Current conversation: Human: 你好,我叫michael AI: 你好,Michael!很高兴认识你。我是一名AI,可以为你提供帮助和答案。你有什么问题或需求吗? Human: 5.1乘以6等于多少呀 AI: > Finished chain. 5.1乘以6等于30.6。 > Entering new chain... Prompt after formatting: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know. Current conversation: Human: 你好,我叫michael AI: 你好,Michael!很高兴认识你。我是一名AI,可以为你提供帮助和答案。你有什么问题或需求吗? Human: 5.1乘以6等于多少呀 AI: 5.1乘以6等于30.6。 Human: 哦,我忘记我叫什么名字了,你可以告诉我吗? AI: > Finished chain. 当然,你刚才告诉我你的名字是Michael。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
print(memory.buffer)
- 1
打印对话的历史缓存
Human: 你好,我叫michael
AI: 你好,Michael!很高兴认识你。我是一名AI,可以为你提供帮助和答案。你有什么问题或需求吗?
Human: 5.1乘以6等于多少呀
AI: 5.1乘以6等于30.6。
Human: 哦,我忘记我叫什么名字了,你可以告诉我吗?
AI: 当然,你刚才告诉我你的名字是Michael。
- 1
- 2
- 3
- 4
- 5
- 6
print(memory.load_memory_variables({}))
- 1
{'history': 'Human: 你好,我叫michael\nAI: 你好,Michael!很高兴认识你。我是一名AI,可以为你提供帮助和答案。你有什么问题或需求吗?\nHuman: 5.1乘以6等于多少呀\nAI: 5.1乘以6等于30.6。\nHuman: 哦,我忘记我叫什么名字了,你可以告诉我吗?\nAI: 当然,你刚才告诉我你的名字是Michael。'}
- 1
手动加载对话历史
memory = ConversationBufferMemory()
memory.save_context({'input': '你好,我叫小明'},
{'output': '你好,我可以帮助你吗?'})
print(memory.buffer)
print(memory.load_memory_variables({}))
memory.save_context({'input': '恩,我忘记回家的路了,你能帮助我吗?'},
{'output': '好的,你的家在哪里呀?'})
print(memory.buffer)
print(memory.load_memory_variables({}))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出
Human: 你好,我叫小明
AI: 你好,我可以帮助你吗?
{'history': 'Human: 你好,我叫小明\nAI: 你好,我可以帮助你吗?'}
Human: 你好,我叫小明
AI: 你好,我可以帮助你吗?
Human: 恩,我忘记回家的路了,你能帮助我吗?
AI: 好的,你的家在哪里呀?
{'history': 'Human: 你好,我叫小明\nAI: 你好,我可以帮助你吗?\nHuman: 恩,我忘记回家的路了,你能帮助我吗?\nAI: 好的,你的家在哪里呀?'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
然后我们接着这个对话继续
conversation = ConversationChain(
llm=model,
memory=memory,
verbose=True,
)
print(conversation.predict(input="我的家在北京市海淀区ABC小区"))
- 1
- 2
- 3
- 4
- 5
- 6
输出
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好,我叫小明
AI: 你好,我可以帮助你吗?
Human: 恩,我忘记回家的路了,你能帮助我吗?
AI: 好的,你的家在哪里呀?
Human: 我的家在北京市海淀区ABC小区
AI:
> Finished chain.
好的,北京市海淀区ABC小区是一个住宅区,位于北京市的西北部。这个小区有很多居民楼和商店,周围也有很多公园和景点。你可以选择步行、骑自行车或者坐公交车前往你的家。如果你需要更具体的路线指导,我可以为你提供导航服务。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
可以看到模型在试图回答上文中的导航需求
2. ConversationBufferWindowMemory
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(k=1)
- 1
- 2
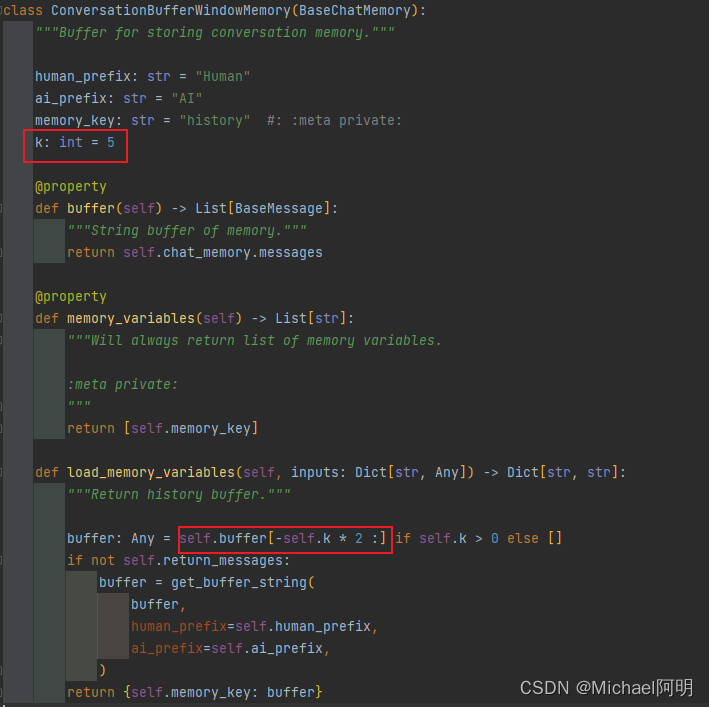
聊天历史只会保存,人类和AI 各自最近的 k 条记录,如下源码所示
memory.save_context({'input': '你好,我叫小明'},
{'output': '你好,我可以帮助你吗?'})
print(memory.buffer)
print(memory.load_memory_variables({}))
memory.save_context({'input': '恩,我忘记回家的路了,你能帮助我吗?'},
{'output': '好的,你的家在哪里呀?'})
print(memory.buffer)
print(memory.load_memory_variables({}))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出
[HumanMessage(content='你好,我叫小明', additional_kwargs={}, example=False), AIMessage(content='你好,我可以帮助你吗?', additional_kwargs={}, example=False)]
{'history': 'Human: 你好,我叫小明\nAI: 你好,我可以帮助你吗?'}
[HumanMessage(content='你好,我叫小明', additional_kwargs={}, example=False), AIMessage(content='你好,我可以帮助你吗?', additional_kwargs={}, example=False), HumanMessage(content='恩,我忘记回家的路了,你能帮助我吗?', additional_kwargs={}, example=False), AIMessage(content='好的,你的家在哪里呀?', additional_kwargs={}, example=False)]
{'history': 'Human: 恩,我忘记回家的路了,你能帮助我吗?\nAI: 好的,你的家在哪里呀?'}
- 1
- 2
- 3
- 4
- 5
- 6
可以看到 history 中只保存了最近的1轮对话记录
继续对话
conversation = ConversationChain(
llm=model,
memory=memory,
verbose=True,
)
print(conversation.predict(input="我叫什么名字呀?"))
print(conversation.predict(input="我的家在北京市海淀区ABC小区"))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出
> Entering new chain... Prompt after formatting: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know. Current conversation: Human: 恩,我忘记回家的路了,你能帮助我吗? AI: 好的,你的家在哪里呀? Human: 我叫什么名字呀? AI: > Finished chain. 很抱歉,我没有记录你的名字。 > Entering new chain... Prompt after formatting: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know. Current conversation: Human: 我叫什么名字呀? AI: 很抱歉,我没有记录你的名字。 Human: 我的家在北京市海淀区ABC小区 AI: > Finished chain. 北京市海淀区ABC小区是一个位于北京市海淀区的小区,它周围有许多商店和公共设施,如超市、公园和学校。该小区建于1990年代,由多座高层建筑和低层建筑组成,共有数千户居民。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
从输出可以看出,模型没有回答姓名,也没有 回答导航的问题
3. ConversationTokenBufferMemory
只能记住一定数量的 token
from langchain.memory import ConversationTokenBufferMemory
memory = ConversationTokenBufferMemory(llm=model, max_token_limit=30)
memory.save_context({'input': '你好,我叫小明'},
{'output': '你好,我可以帮助你吗?'})
memory.save_context({'input': '恩,我忘记回家的路了,你能帮助我吗?'},
{'output': '好的,你的家在哪里呀?'})
print(memory.load_memory_variables({}))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出
{'history': 'AI: 好的,你的家在哪里呀?'}
- 1
对话历史只有 AI 说的最后一句
4. ConversationSummaryBufferMemory
会使用模型对聊天记录作总结
rom langchain.memory import ConversationSummaryBufferMemory
schedule = '上午8点有一个与您的产品团队的会议,\
您需要准备好您的PPT演示文稿。\
上午9点至下午12点有时间处理您的LangChain项目,因为Langchain是一个如此强大的工具。\
中午,在汉堡王与一位顾客共进午餐,讨论人工智能的最新进展,\
一定要带上你的笔记本电脑来展示最新的LLM demo。'
memory = ConversationSummaryBufferMemory(llm=model, max_token_limit=100)
memory.save_context({'input': '你好,我叫小明'},
{'output': '你好,我可以帮助你吗?'})
memory.save_context({'input': '恩,我忘记回家的路了,你能帮助我吗?'},
{'output': '好的,你的家在哪里呀?'})
memory.save_context({'input': '今天的安排有哪些啊?'},
{'output': f'{schedule}'})
print(memory.load_memory_variables({}))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
输出
{'history': "System: The human introduces themselves as Xiao Ming and asks for help finding their way home. The AI agrees to help and asks for the location of their home. The conversation shifts to the day's schedule, which includes a meeting with the product team, working on the LangChain project, and having lunch with a customer to discuss the latest developments in artificial intelligence. The AI advises bringing a laptop to showcase the latest LLM demo."}
- 1
由于 langchain 的内置附加 提示词 都是英文的,这个输出的对话总结不是预期的中文
继续对话
conversation = ConversationChain(
llm=model,
memory=memory,
verbose=True,
)
print(conversation.predict(input="有什么比较好的demo可以展示呢?"))
print(memory.load_memory_variables({}))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
System: The human introduces themselves as Xiao Ming and asks for help finding their way home. The AI agrees to help and asks for the location of their home. The conversation shifts to the day's schedule, which includes a meeting with the product team, working on the LangChain project, and having lunch with a customer to discuss the latest developments in artificial intelligence. The AI advises bringing a laptop to showcase the latest LLM demo.
Human: 有什么比较好的demo可以展示呢?
AI:
> Finished chain.
我们最新的LLM demo非常出色,可以展示我们在自然语言处理方面的最新技术。此外,我们还有一些其他的demo,包括图像识别、语音识别和机器翻译等。你想看哪个呢?
{'history': 'System: Xiao Ming asks if there are any good demos to showcase.\nAI: 我们最新的LLM demo非常出色,可以展示我们在自然语言处理方面的最新技术。此外,我们还有一些其他的demo,包括图像识别、语音识别和机器翻译等。你想看哪个呢?'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
预测后,memory 总结了 max_token_limit 限制内的对话内容
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/129711
推荐阅读
相关标签

