
- 1[CocosCreator]封装XMLHttpRequest短连接_cocos xmlhttprequest
- 2PDF控件Spire.PDF for .NET【转换】演示:将PDF 文档另存为 tiff 图像_spire.pdf not tiff format
- 3@drawable" href="/w/从前慢现在也慢/article/detail/144679" target="_blank">Android产品研发(二)-->启动页优化_"
- @drawable
- 4深度学习中Epoch、Batch和Batch size的定义和设置_epoch的设置
- 5Kaldi的Python3库附加_kaldi python
- 6如何搭建一个自己的知识付费平台_如何部署付费知识平台
- 7机器学习入门实践——线性回归模型(波士顿房价预测)_线性回归 1. 定义问题:波士顿房价预测,用可用的工具进行统计分析,建立优化模型,基
- 8微信小程序服务器配置流程 免费开启HTTPS
- 9交换机OID说明
- 10Python3+Dlib+Opencv实现摄像头采集人脸并对表情进行实时分类判读_python opencv 表情识别 完整源码 下载
开卷翻到毒蘑菇?浅谈大模型检索增强(RAG)的鲁棒性
赞
踩

©PaperWeekly 原创 · 作者 | 陈思硕
单位 | 北京大学
研究方向 | 自然语言处理
很久没有写论文 notes 了,近期因为参与对检索增强生成(Retrieval-Augmented Generation, RAG)范式鲁棒性的研究,注意到了近两个月来社区中涌现了一小批关于这个话题的工作,简单梳理以飨读者。

何为检索增强:模型可以开卷考
纯参数化的大语言模型将其在海量语料上学习到的世界知识存储在模型参数中,虽然已经展现出来强大能力并改变整个 NLP 乃至深度学习社区的研究范式,但纯参数化的模型存在诸多不足:
1. 长尾记忆困难:不能记住所有训练语料中的所有知识,尤其是对低频的长尾知识记忆困难;
2. 容易过时:参数中的知识容易过时(ChatGPT 和 LLaMa肯定不知道周二国足的比分,硬预测的话应该会预测个比三比零更大的数 x),更新起来很困难(训练代价且容易造成灾难性遗忘);
3. 参数太多导致计算代价大:训练和推理代价高昂(虽然有 Scaling Law,但参数量上去之后就没什么人训练甚至部署得起了→_→)。
类似地,人也很难记住所有的知识(除了高考这种几乎纯比拼 memorization 的考试之前),很多长尾的冷知识和新知识需要的时候从外部的消息源现查就好了。

▲ 全都背下来就会像硬吃记忆面包一样痛苦
同样地,语言模型可以是半参数化的,也就是(参数化的)模型可以外挂一个(非参数化的)语料数据库,推理时以从语料库召回的部分数据为参考组织答案(具体的形式可以是作为额外的上文输入,也可以插在中间的 cross attention 或者输出中),这一范式被称为检索增强生成(Retrieval-Augmented Generation,RAG)。
检索增强的语言模型(Retrieval-Augmented Language Model,RALM)的正式定义是:
A language model (LM) that uses an external datastore at test time.
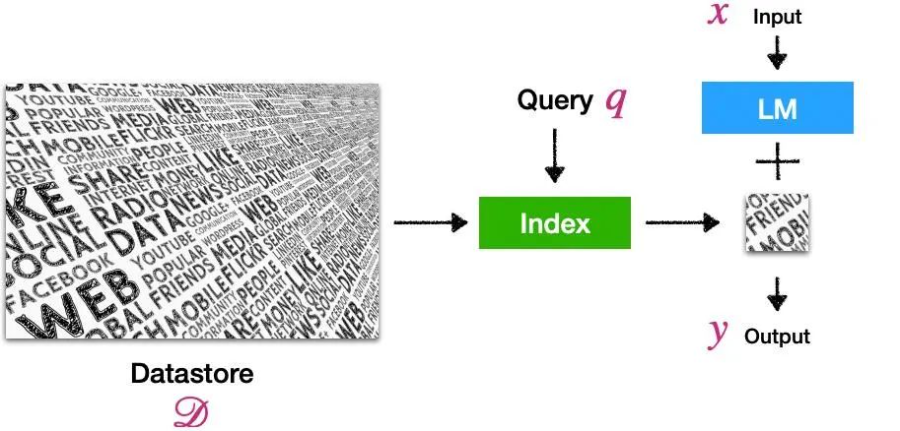
▲ 以上定义和示意图来自ACL 2023的Tutorial [1]
示意图如上,对用户输入的文本 x,我们构造记为 q 的 query ,从数据库 D 的索引中召回了小一部分相关文档(右侧的小块简报),模型以其为参考生成最后的输出 y。除了缓解以上三个问题(长尾记忆困难、容易过时、参数太多导致计算代价大)之外,还可以起到给模型的回答提供可靠的消息来源、防止模型权重泄露隐私信息等作用,具体的机制和代表性工作可以参见今年 ACL 上陈丹琦老师领衔的 Tutorial [1],此处不详细展开。

检索增强是否一定可靠:开卷翻到了毒蘑菇呢?
交代完了 RAG 这一大背景,回到今天想聊的鲁棒性的正题。我们知道,人在翻书找长尾知识或者上网冲浪吃新瓜的时候,如果不加审慎的分辨,很容易以讹传讹:

当然,语言模型也不比人高明,如果检索增强的时候召回的是和输入问题无关的内容(噪声干扰),甚至是反事实的 fake news 或者被篡改的百科,模型就会像吃了毒蘑菇一样胡言乱语。

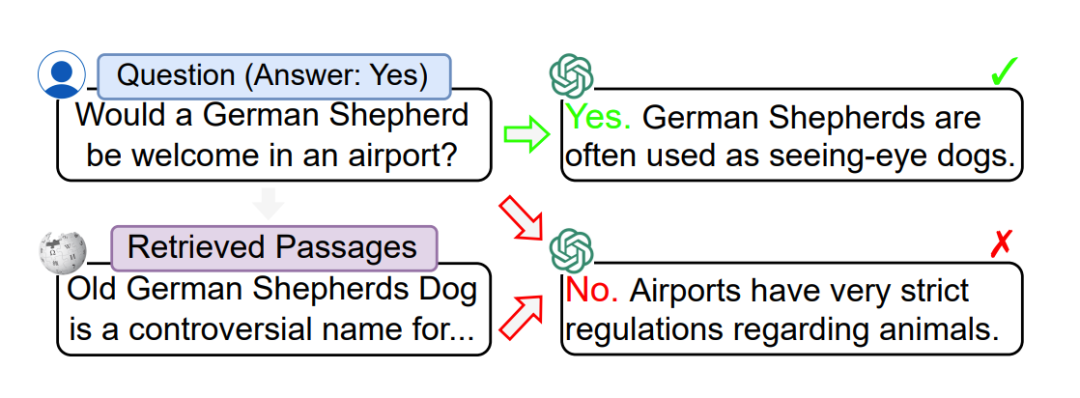
以下是来自论文 [2] 的一个检索回无关内容后输出被影响的例子,原本对“德牧能不能进机场”这样的简单的问题,ChatGPT是高度认可小狗同志作为导盲犬的价值的,果断说 yes,但是检索模块召回了一段“老德牧是一类 balabala 某种狗的争议性名称”的百科介绍作为额外上文输入后,模型突然对小狗变凶了,说出了“机场不许你入内”这样的负心话。
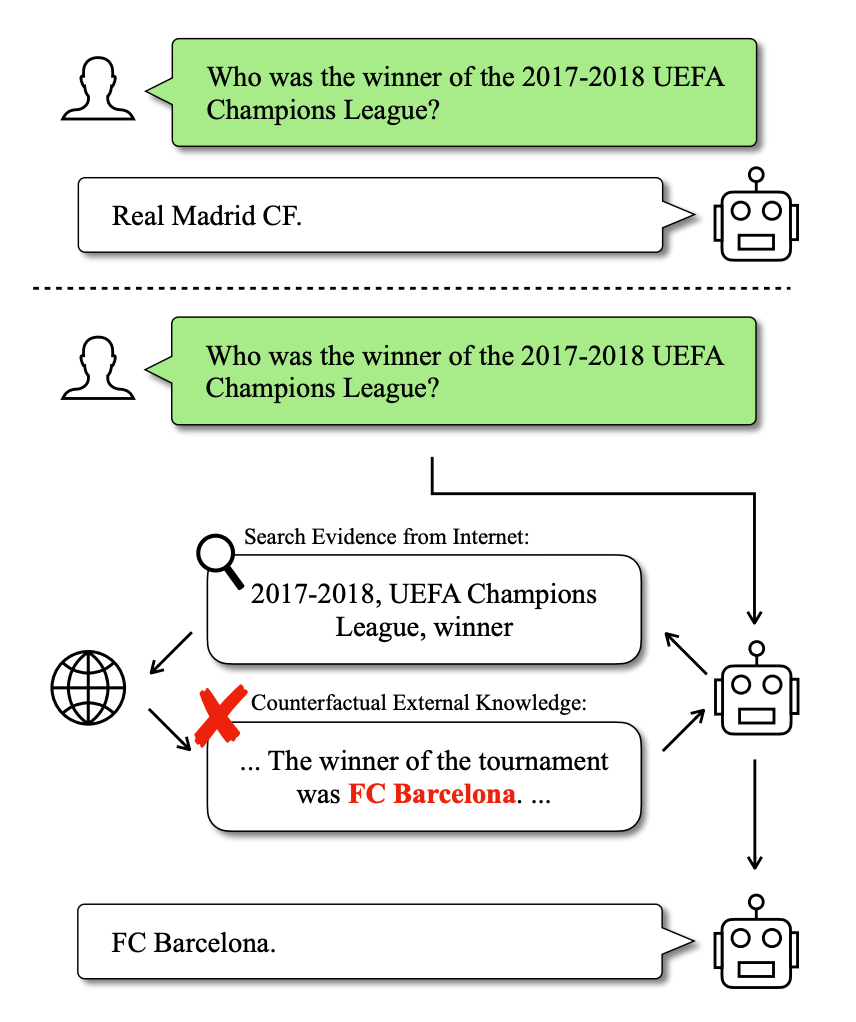
以下是来自论文 [3] 的检索到反事实信息造成模型错误输出的例子。对博闻强识的大模型来说,17-18 赛季的欧冠冠军是道简单题,不用检索增强就知道是皇马,但如果有恶意用户某一天编辑了相关的维基百科把答案改成巴萨,模型通过检索模块吃到这样与自身知识冲突的辅助输入就会被忽悠住,人云亦云,复读出错误的答案。

如何提高检索增强的可靠性:怎么应对毒蘑菇?
综上所述,RAG 范式中,语言模型有可能在翻资料的时候误食毒鸡汤里的毒蘑菇,进而见小人、躺板板,胡言乱语误了大事。还好,笔者注意近两个月来社区中涌现了一小批研究来增强模型翻小抄的时候的鲁棒性,本文接下来的部分将介绍其中的五篇新鲜论文。
SKR: 以自身知识引导检索增强

论文标题:
Self-Knowledge Guided Retrieval Augmentation for Large Language Models
论文链接:
https://arxiv.org/pdf/2310.05002.pdf
Takeaway: 发现 RAG 召回的辅助信息不总是有用,甚至可能起负作用,因此设计了名为 SKR (Self-Knowledge Guided Retrieval Augmentation)的框架,对模型本身已知的问题直接生成答案,对未知的问题才调用 RAG 模块。
解读:直接看具体方法:
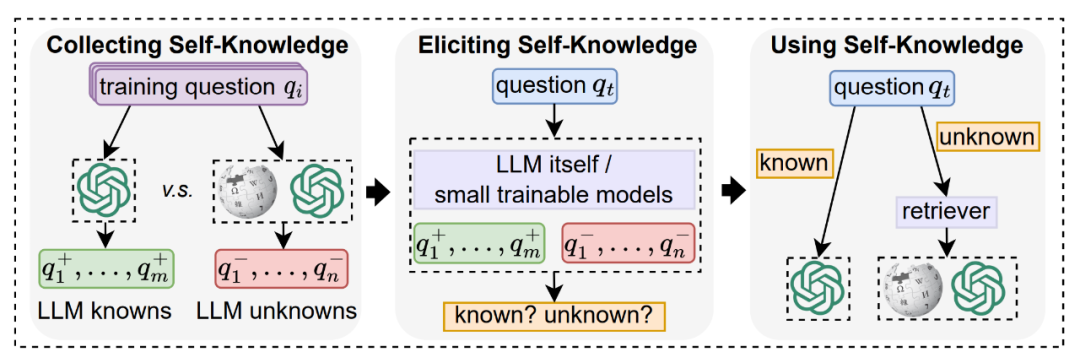
1. 自我知识收集:首先要知道自己知道什么,不知道什么(开始绕口令),因此收集一批有标注的训练集,模型可以直接答对的视为 known,检索增强后才能答对的视为 unknown;
2. 识别是否已知:对输入的测试问题,利用在训练集上构建的分类器识别其是否已知。分类器构建的方式作者试了好几种,可以用大模型本身上下文学习,可以用 RoBERTa 小模型训个分类器,也可以用 SimCSE的 embedding 为嵌入直接 KNN 分类(实验中 KNN 的性能最好);
3. 自适应式检索增强:只对第二步中识别为 unknown 的输入进行检索增强,其余输入视为 known,直接回答。
实验是在一些 QA 数据集上做的,LM 是 InstructGPT 和 ChatGPT,似乎没有详细说明预训练 retriever 是什么模型,结果显示 KNN 版本的 SKR 与不带检索增强的 CoT 以及非自适应的 RAG+CoT 类型的基线相比,能取得 3%-4% 的显著提升。
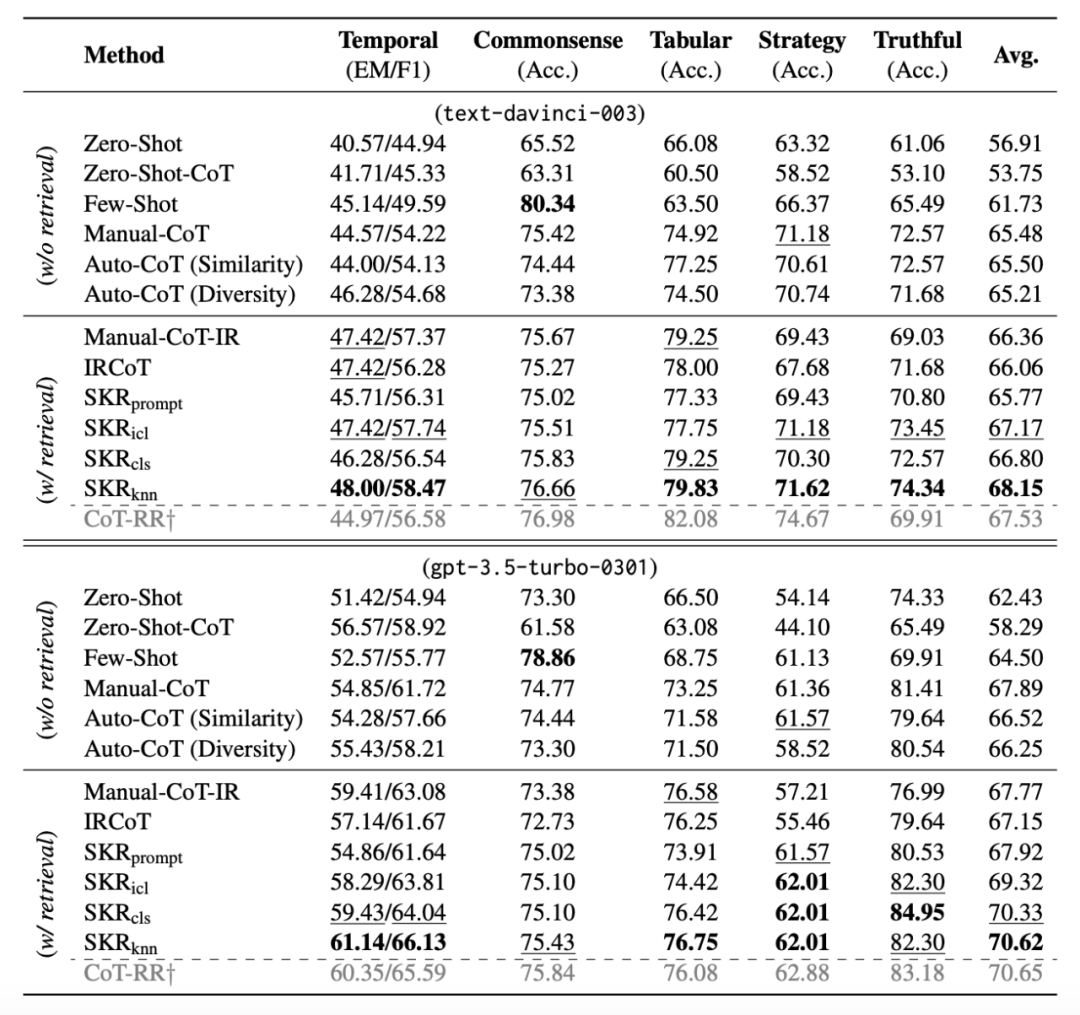
笔者有一个 concern 是,上述方法的前二步中,识别 known/unknown 的分类器是在和测试样本同分布的训练集上构建的,而且实验中似乎设定是用了完整的训练集(这样一来实际上有信息泄露,与其他的 zero-shot 和 few-shot 方法比较并不公平)。作者也讨论训练集大小的影响,但是有一点避重就轻的感觉,只表示训练集减小到 10% 会导致 2-3 个点的下降,该方法在训练集和测试集不同分布/可用的样本数很少的情况下的有效性还有待确认。
RECALL: 反事实信息危害极大,现有干预方法难以缓解其风险

论文标题:
RECALL: A Benchmark for LLMs Robustness against External Counterfactual Knowledge
论文链接:
https://arxiv.org/pdf/2311.08147.pdf
Takeaway: 构建了一套名为 RECALL 的 benchmark 来分析大模型对反事实信息输入的鲁棒性,发现现有开源大模型非常容易被反事实的输入误导,prompt engineering 和幻觉缓解领域中的现存方法难以有效解决该问题。
解读:与另外几篇工作中,non-relevant contexts 是从正常的大语料库中召回(只是可能与问题本身不太相关,对模型造成干扰)的设定不同,本文聚焦是一种更极端的干扰现象,即反事实信息(counterfactual information),也就是检索召回的内容是与事实恰好相反的假消息。理想情况下,一个明辨是非的模型对不同类输入问题和检索召回内容的处理能力应该是这样的:
1. 对自己的参数中有明确记忆的问题,即使检索模块的召回的内容与之冲突,也应该坚持原有的正确答案;
2. 对自己不知道答案的问题,有正确的召回内容时可以以其为参考正确回答,如果召回的内容是错就随缘了 x。
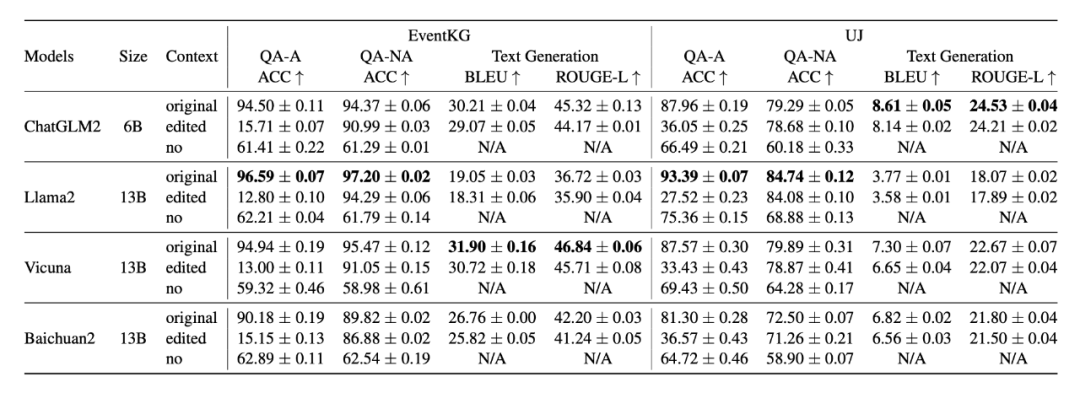
本文首先提出了量化这一能力的一套 benchmark(名为 RECALL),向 EventKG(常识性知识问答)和 UJ(科学性知识问答)这两个阅读理解数据集中注入了反事实信息,在二选一的 QA 和生成式的问答任务上测试了 ChatGLM2、LLaMa2、Vicuna、Baichuan2 等四个 6B-13B 规模的开源大模型,其中 QA 任务分为两个子集呈现指标,即扰动的时候答案部分被修改(QA-A)和未被修改(QA-NA)。
结果显示,选择题形式的 EventKG QA 任务上,一旦对 context 的反事实扰动涉及到了答案本身(即答案被篡改为错误选项),模型的 accuracy (下图中的 QA-A Acc)会从 90%+ (图中的第一行"original")下降到 20% 以下(第二行"edited"),远低于没有检索机制,模型直接回答时的 60%左右(第三行“no”)。相比之下,QA-NA 和文本生成的指标下降幅度较小。
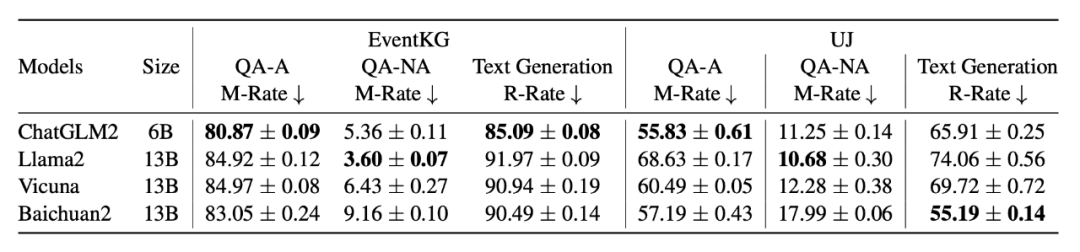
为了更精细地量化反事实信息带来的影响,作者额外定义了两个指标:
误导率 M-Rate: 选择式 QA 中,模型在无上下文输入时原本能答对的问题(即模型预训练阶段记忆住的问题),在接收反事实上下文后回答出错的比例;
错误重复率 R-Rate: 生成任务中,反事实扰动对应的 tokens 在模型的答案中出现的比例。
结果显示,EventKG 数据集上,四个大模型在 QA-A 设定下的误导率 M-Rate 高达 80% 以上,生成设定下反事实信息被复读的比例 R-Rate 也高达 85-91%,可见 RAG 模块如果召回了包含反事实信息的参考文档,将对模型的可信度造成巨大的危害。
本文比较侧重前面的 benchmark 构建与分析部分,本身没有直接提出新方法来增强模型的鲁棒性,而且测试了两种现存方法:
Prompt Engineering: 简单粗暴,直接在 prompt 中告诉模型“忽略上下文中的反事实信息”;
DOLA [7]: 最近受到关注的一种针对模型幻觉的推理时干预方法,概括地讲是用模型(最后一层)输出的分布减去浅层 hidden states 对应的输出分布做解码。
出于篇幅考虑此处不拉表格,直接搬运结论:
Prompt Engineering:虽然能提升 QA-A 设定下被扰动时的 accuracy,但对 QA-NA 设定下的 accuracy 反而有损害,有时对生成的质量也有损害;
DOLA: 虽然能小幅提升大部分指标,但会导致生成任务中错误复现率 R-Rate 显著上升。
结论:以上两类方法都不能稳定地提升模型对反事实输入的鲁棒性,亟需有可靠的新方法解决这一问题。
Training Robust RALMs:数据硬怼,端对端提升鲁棒性

论文标题:
Making Retrieval-Augmented Language Models Robust to Irrelevant Context
论文链接:
https://arxiv.org/pdf/2310.01558.pdf
解读:本文是篇偏实验分析性质的文章,测试了 NLI 过滤召回结果和直接模拟带噪声的召回内容进行训练两类方法。
首先,直接用 NLI 预训练模型判断召回的文档和问题是否相关来进行过滤,结论是 NLI 模型的过滤虽然能提升召回信息质量低时模型的鲁棒性,但也会伤及无辜(过滤掉有用的信息),在以 Google 搜索 top-1 为召回内容时总体上是掉点的。
接下来的方法非常直接暴力,既然 RAG 范式中检索来的内容 可能有噪音,大模型预训练的时候又没见过这种鱼龙混杂的上文,干脆发扬 end-to-end 的精神直接训练。坐着构建了一个 1.5k 样本的训练集,其中包含干净的 context 和扰动的 context,希望模型学习到“不论如何都能输出正确答案”的能力。
结果确实显示该数据上微调后的 LLaMa2-13B 模型在各种 QA 任务上,无论是正常的 Google 搜索召回、故意召回排名低的文档(low-rank retrieval),还是随机召回,都能比普通的 RAG 显著提升准确率,在 low-rank 和 random 的设定下基本和不带 RAG 的原模型相当。
有一点缺憾是,本文没有讨论这种微调是否影响了模型在其他领域的通用能力,未来或许可以考虑将这种为 RAG 鲁棒性设计的数据集加到模型的预训练或者 SFT 阶段中。
Chain of Note:适合检索增强的思维链蒸馏

论文标题:
Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models
论文链接:
https://arxiv.org/pdf/2311.09210.pdf
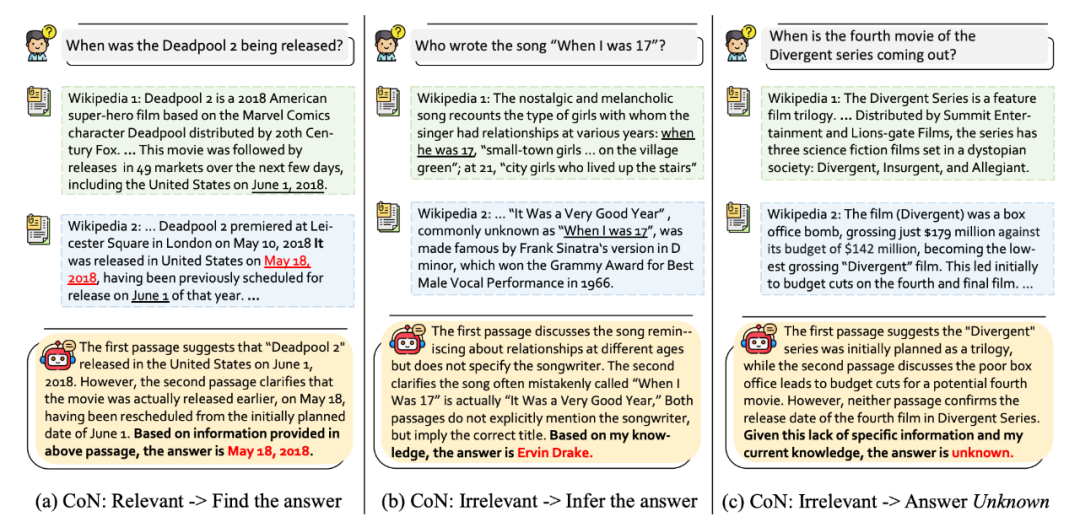
解读:将思维链(CoT)方法用于增强 RAG 的鲁棒性,在中间推理过程中输出每一篇召回文档与输入问题的相关性(即对召回内容的 note)和自身对问题的认知,最后总结输出答案。作者用 ChatGPT 构造了一个这种格式的 CoT 训练集,将此能力蒸馏到了 LLaMa2 上,显著提升了 LLaMa2 带 RAG 时的鲁棒性。
值得一提的是,另外几篇文章都没有注意 OOD detection 的问题,即当模型本身和召回文档都不掌握回答问题需要的知识时,应该回答 unknown 而不是胡编乱造,本文考虑了此问题(下图第三栏)。
Self-RAG:自我求助,自我生成,自我反思

论文标题:
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
论文链接:
https://arxiv.org/pdf/2310.11511.pdf
Takeaway: 本文提出了一个叫 Self-RAG 的框架,方法如其名,希望 LM 自主决定对当前输入是否需要召回(而不是像 SKR [2] 那样训练一个额外的分类器或像 [4] 那样借助一个 NLI 模型判断),把召回内容拼接近输入,再生成一段下文,自主判断召回文档是否与输入问题相关、自己借此生成的一段下文是否合理、是否有用,对 topk 召回内容进行排序,把 top-1 加进最后的输入以尽量生成正确答案。框架如下图右栏所示。
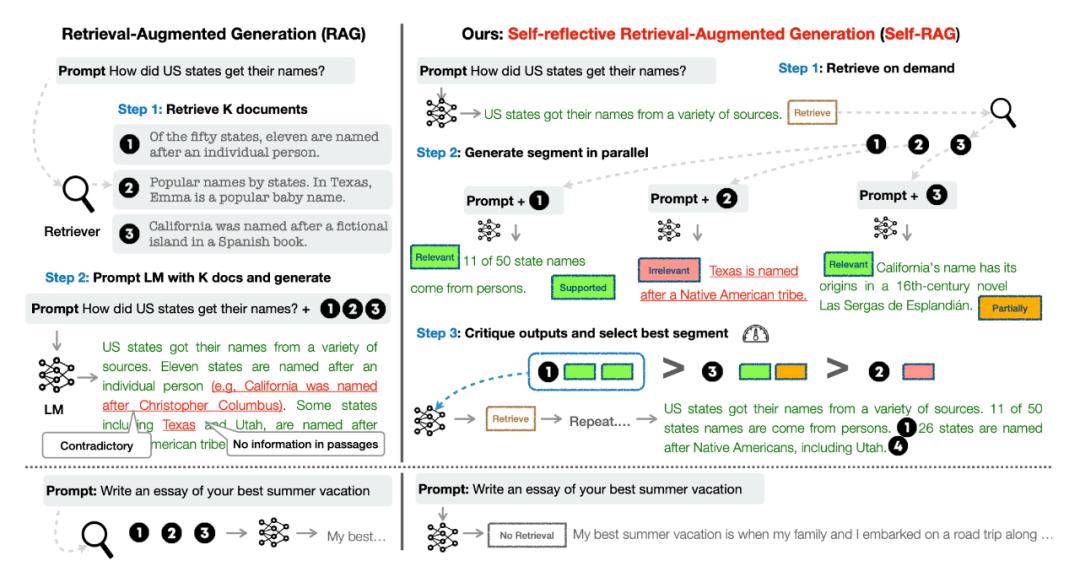
解读:如上所示,Self-RAG 把要不要进行检索的决定、判断检索召回内容是否与问题相关、检索增强后的输出是否合理有用这几个决定都转化成了 token 预测的形式,文中称为 reflection tokens,整个过程可以用如下算法概括:

第 2 行产生的 Retrieve 决定是否进行检索,如果进行检索的话,各段内容对应的相关程度 IsREL、自我支持程度 IsSUP、有用程度 IsUSE 共同组成排序的分数标准。作者把各个维度分别分了几档做离散的预测,如下表所示:

以上是方法的骨架,接下来的关键在于如何构造包含reflection tokens 的训练数据来训练 Self-RAG。数据构建的流程略复杂,文中没有给出简洁的流程图,笔者概括如下:
GPT-4 收集种子数据:对四种类型的 reflection tokens,各用 GPT-4 标注 4k-20k 个从开源的 QA 和知识问答数据中收集的样本;
知识蒸馏,训练 critric model: 在第 1 步的训练数据上微调开源大模型,如LLaMa2-7B,称为 critic model;
为生成模型生成训练数据:使用上述的 critic model联合检索模块,为最后的生成模型构造模拟整个 Self-RAG 推理过程的训练集(两个例子如下图所示),约 150k 大小;
训练生成模型:在第 3 步生成的训练数据上训练生成模型,文中为 LLaMa2-7B和 13B,最后推理时只需要该模型,不需要 critic model。
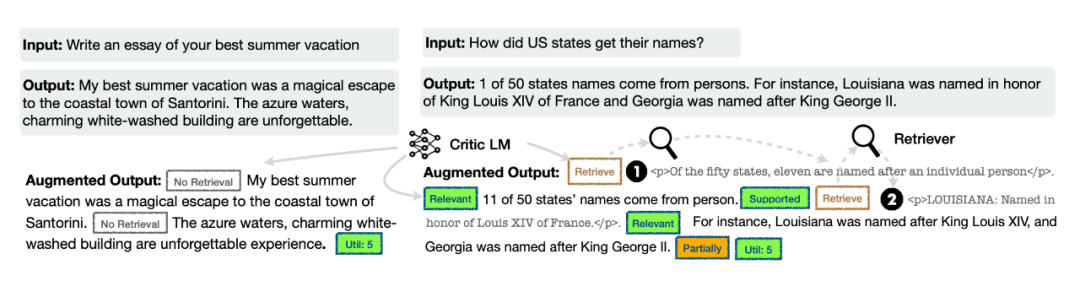
这里笔者存在一个疑问:是否相关、是否自我支持、是否有用这几个客观标准,用 GPT-4 标注是合理的,但是否需要检索增强,也就是上面的 Retreive 这个 reflection token,是和生成模型本身的能力相关的,GPT-4 不需要检索就能回答的问题,可能 LLaMa2 就需要检索,这里这样蒸馏是否合理有待讨论。
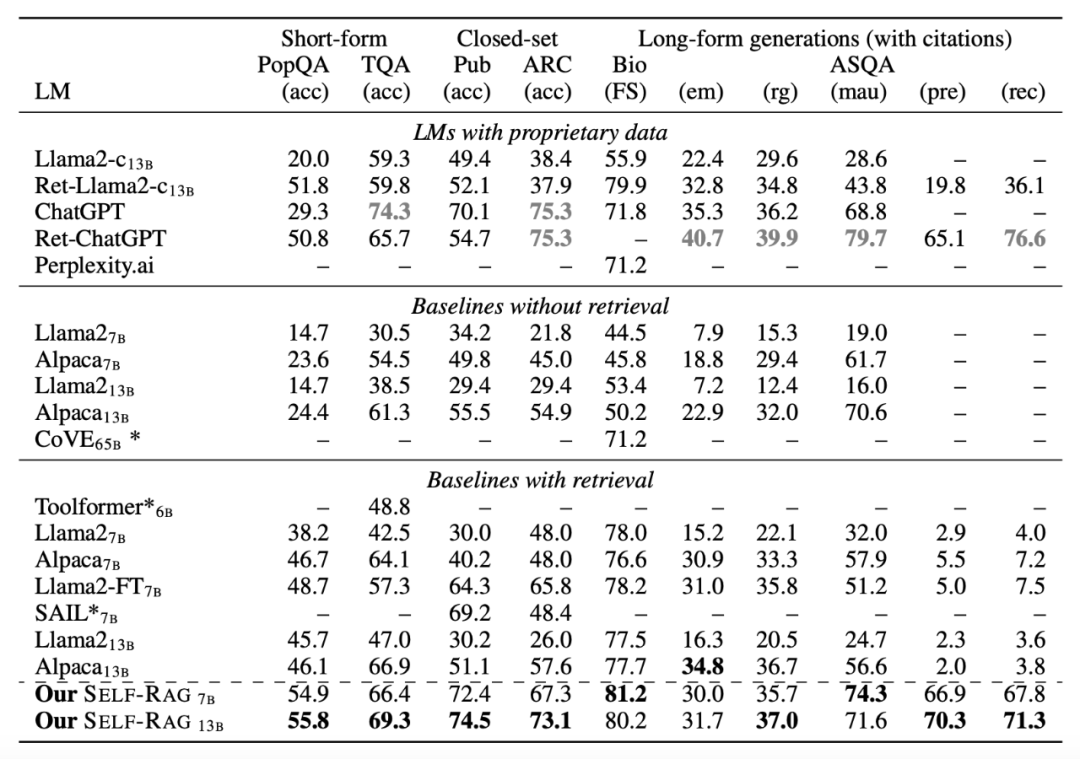
按下该疑问不表,我们来看目前实现版本的效果,可以发现 Self-RAG 在一系列开放域 QA 和生成任务上都能比普通的检索增强 LLaMa2 取得明显提升。

方法论小结
至此,我们已经阐明了大模型检索增强范式的鲁棒性问题,并检视、学习了五篇意图解决该问题的近期工作。整体来看,方法可以分为两类:
1. 自适应检索和过滤:即在检索前加一个模块判断该问题是不是需要检索增强才能回答或判断检索回的内容是否有用,以避免不必要的检索召回内容被输入模型产生干扰,如 SKR [2] 用模型自身的信号在训练数据上额外构建一个分类器,[4] 直接使用 NLI 模型,Self-RAG [6] 从 GPT-4 蒸馏能力,让语言模型自己以预测 Retrieve token 的形式判断。
实验已证实这类方法能有效地避免无用的召回内容的干扰,坏处是直接删除被判断为无用的内容,可能误伤有用的检索召回内容。
2. 生成时干预:希望即使无用甚至错误的内容被检索回来、输入模型,模型对这样的增强输入依然能凭借自身知识保持鲁棒,如 RECALL [2] 的 prompt engineering 或者 Dola 干预,[4] 的直接构造相应的训练数据进行训练,Chain of Note [5] 的思维链蒸馏,Self-RAG [6] 的让模型自身判断召回的内容是否有用。其中只有 RECALL [2] 是不需要训练的,但未取得明显收益,另外三类都需要依赖 ChatGPT 或 GPT4 这些强大的闭源模型构造训练信号。
最后,笔者想讨论的一点零碎思考是,以上的各工作基本假定检索模型是固定的(Google API 或者冻结的预训练召回模型),如果把检索模型和 index 的更新也考虑进来,是否能进一步提升整个 RAG 系统的鲁棒性?期待看到甚至参与新的相关工作。
小文写作于冬日的燕园和万柳,还有许多细节和未来可能的方向未尽讨论,望诸君不吝赐教。

参考文献
[1] Asai, Akari, et al. "Retrieval-based language models and applications." Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 6: Tutorial Abstracts). 2023.
[2] Wang, Yile, et al. "Self-Knowledge Guided Retrieval Augmentation for Large Language Models." arXiv preprint arXiv:2310.05002 (2023).
[3] Liu, Yi, et al. "RECALL: A Benchmark for LLMs Robustness against External Counterfactual Knowledge." arXiv preprint arXiv:2311.08147 (2023).
[4] Yoran, Ori, et al. "Making Retrieval-Augmented Language Models Robust to Irrelevant Context." arXiv preprint arXiv:2310.01558 (2023).
[5] Yu, Wenhao, et al. "Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models." arXiv preprint arXiv:2311.09210 (2023).
[6] Asai, Akari, et al. "Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection." arXiv preprint arXiv:2310.11511 (2023).
[7] Chuang, Yung-Sung, et al. "Dola: Decoding by contrasting layers improves factuality in large language models." arXiv preprint arXiv:2309.03883 (2023).
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

