
- 1Confluence 主要特性_extrnlnks trackbacklinks区别 confluence
- 2openvino vs2017配置使用_vs2017 openvino
- 3element-ui中avator插件关于头像显示的问题
- 4Next 主题配置_next主题最新配置
- 5element UI 中 el-tree 树形菜单新增、删除操作_elementui的tree增删改查
- 6RAW和YUV的区别_摄像头输出格式yuv和raw
- 7你的专属音乐生成器「GitHub 热点速览」
- 8pointnet++ pointnet2代码运行 保姆级教程_pointnet编译自定义 tf 算子
- 9【机器学习】列举几种常见的机器学习回归模型(附代码)
- 10时序预测 | MATLAB实现基于LSTM-AdaBoost长短期记忆网络结合AdaBoost时间序列预测 替换数据可以直接使用,注释清楚,适合新手
ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT
赞
踩
写在最前面,为了彻底写清楚ChatGPT背后的所有关键细节,每个月不断深挖,从1月初写到6月底仍未完工,除了本文之外,过程中涉及到多篇文章(RL入门、论文解读、微调实战、代码实现、CV多模态),再加上之前写的Transformer、RL数学基础等多篇笔记,成了一个大系列
即:大模型/AIGC/ChatGPT系列:原理、论文、代码、实战,包含了
- ChatGPT原理系列,5篇
- 国内外类ChatGPT的微调/部署/实现,5篇
- AIGC/AI绘画/CV多模态,3篇
- 大模型背后技术的关键方法,2篇
- LLM应用:医疗/知识库/学术/代码等垂类模型、及与langchain/KG/DB的结合,4篇
另,这些课程:ChatGPT原理、类ChatGPT微调实战、Stable Diffusion/MDJ的原理与实战、大模型论文100篇带读、LLM与langchain/KG/DB的结合实战、大模型项目开发线上营会比本系列讲的更加深入、细致、透彻
前言
自从我那篇Transformer通俗笔记一经发布,然后就不断改、不断找人寻求反馈、不断改,其中一位朋友倪老师(之前我司NLP高级班学员现课程助教老师之一)在谬赞Transformer笔记无懈可击的同时,给我建议到,“后面估计可以尝试尝试在BERT的基础上,讲一讲prompt学习了”
再然后,当我还在各种改Transformer笔记的时候,12月初突然出来了一个ChatGPT刷爆朋友圈,即便很多之前不接触AI的朋友也在问ChatGPT这种类似聊天机器人却远胜一般聊天机器人各种问题(上一次出现这种盛况的还是16年的AlphaGo)。
据我观察,大家问ChatGPT的问题千奇百怪
- 有的让他算经典的鸡兔同笼问题,且也能在和人类自然而流畅的互动中举一反三
- 有的让其根据要求排查代码bug,要知道此前debug想寻求帮助
要么问人(问熟人用社交软件,问陌生人则类似那种问答网站,持续问一般得付费,毕竟没人乐意持续免费答疑大量技术难题)
要么Google搜有没人遇到类似的问题(但别人遇到的问题很难与你的百分百一致)
要么用Codex这类代码软件,但在和人类的互动交互上,还不是那么善解人意
所以ChatGPT就相当于你写代码或各类问题的私人顾问,而这个私人顾问能瞬间、精准理解你的意图,不会让你像用以前那种聊天机器人经常觉得智障甚至对牛弹琴,加之其背后依托的是人类级百科全书式的资料库,所以有人惊呼:ChatGPT会不会替代Google这类搜索引擎。
虽然一开始大部分技术者对待ChatGPT还是比较冷静的,毕竟它给的答案不像权威技术专家那样具备足够的公信力,也不像Google给出来源从而不能比较好的验证其正确程度,但后来很快发生的几件大事彻底改变了大家此前的看法
- 23年1月初,微软欲用 ChatGPT 扶必应“上位”,对抗 Google,且很快,ChatGPT直接让其所在的公司OpenAI估值翻倍
- 23年3月中旬,OpenAI正式对外发布GPT-4,增加了多模态(支持图片的输入形式),且ChatGPT底层的语言模型直接从GPT3.5升级到了GPT4,回答问题的准确率大幅提升
- 23年3月17日,微软推出Microsoft 365 Copilot,集成GPT4的能力,实现自动化办公,通过在Word PPT Excel等办公软件上输入一行指令,瞬间解决一个任务
3.23日更推出GitHub Copilot X,让自动化编程不再遥远 - 23年3月24日,OpenAI宣布推出插件功能,赋予ChatGPT使用工具(数学问题精准计算)、联网(获取实时最新消息,底层知识不再只截止到21年9月份)的能力
然目前关于ChatGPT中文的资料里,真正能让人一看就懂的非常非常少,当少数文章具备比较好的可读性之后,你又会发现一旦涉及算法细节就千篇一律的泛泛而谈,如果不是泛泛而谈的,则更多堆砌概念和公式,有的甚至漏洞百出
总之,中文资料里,可能因为instructGPT/ChatGPT刚出来不久的缘故,兼顾可读性、细节性、准确性的文章少的可怜
考虑到ChatGPT非一蹴而就,而是经过了各个前置技术的发展、迭代、结合而成,故本文逐一阐述
- 2017年之前早已有之的一些数学/AI/RL等基础技术,比如微积分、概率统计、最优化、策略梯度、TRPO算法(2015年提出)
- 2017年6月OpenAI联合DeepMind首次正式提出的:Deep Reinforcement Learning from Human Preferences,即基于人类偏好的深度强化学习,简称RLHF
- 2017年7月的OpenAI团队提出的对TRPO算法的改进:PPO算法
关于RL、策略梯度、TRPO、PPO则写在了此文《强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO》
且在这篇RL极简入门笔记之前,99%的文章都不会把PPO算法从头推到尾,该文把PPO从零推到尾,按照“RL-策略梯度-重要性采样(重要性权重)-增加基线(避免奖励总为正)-TRPO(加进KL散度约束)-PPO(解决TRPO计算量大的问题)”的顺序逐步介绍每一步推导
- 2017年6月的Transformer/Self-Attention
关于transformer/self-attention,除了本文,更可以看下上篇《Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT》
- 2018年6月的GPT(Generative Pre-trained Transformer),其关键构成是基于Transformer-Decoder的Masked Self-Attention
- 2019年2月的融合prompt learning的GPT2,prompt learning的意义在于不用微调也能做任务
且这一年已经开始探索通过RLHF去微调语言模型比如GPT2了 - 2020年5月的GPT3,参数规模到了1750亿,终于真正做到预训练之后不用再微调模式,通过In-context learning(简称ICL)开启prompt新范式,且你可能没想到的是,这一年的9月份OpenAI已经开始研究GPT3与RLHF的结合了,且此时用的策略优化方法为PPO
- 2021年7月的Codex,通过对GPT3进行大量的代码训练迭代而出Codex,从而具备代码/推理能力
- 2021年9月Google提出的FLAN大模型:基于指令微调技术Instruction Fine-Tuning (IFT)
此前,Google曾在21年5月对外宣布内部正在研发对话模型LaMDA,而FLAN is the instruction-tuned version of LaMDA-PT
2019年10月,Google发布T5模型(transfer text to text transformer),虽也基于transformer,但区别于BERT的编码器架构与GPT的解码器架构,T5是transformer的encoder-decoder架构
2022年1月,Google发布LaMDA论文『 LaMDA: Language Models for Dialog Applications』
2022年4月,Google提出PaLM: Scaling Language Modeling with Pathways,5400亿参数
2022年10月,Google提出Flan-T5
23年3月6日,Google提出多模态LLM模型PaLM-E - 2022年1月的Google研究者提出的思维链技术(Chain of Thought,简称CoT)
- 2022年3月的OpenAI正式发布instructGPT:GPT3 + instruction tuning + RLHF + PPO,其中,instruction tuning和prompt learning的核心区别在于instruction tuning会提供更多的指令引导模型输出更符合预期的结果,例如
提示学习:给女朋友买了这个项链,她很喜欢,这个项链太____了
指令微调:判断这句话的情感:给女朋友买了这个项链,她很喜欢。选项:A=好;B=一般;C=差
你也可以暂简单理解instruction tuning为带人类指令的prompting - 2021年第4季度逐步发展而来的GPT3.5,并于22年不断融合Codex、InstructGPT的技术能力
- 2022年11月的ChatGPT:语言模型层面的核心架构是GPT3.5(基于Transformer-Decoder的Masked Self-Attention且融合了Codex的代码/推理能力、instruction tuning等技术) + RLHF + PPO3
- 2023年3月中旬,OpenAI正式对外发布GPT-4,增加了多模态(支持图片的输入形式),且ChatGPT底层的语言模型直接从GPT3.5升级到了GPT4
如你所见,自从1.6日开始写ChatGPT笔记,1.15日发布本文,但为把ChatGPT背后所涉及的关键技术阐述细致、透彻,故本文越写越长,长到最后成了一个系列,有的内容抽离出去独立成文,有的还在不断完善
第一部分 从RL、策略梯度到TRPO、PPO算法、RLHF
再次强调说明下,本第一部分在23年2.10日有个重要修改
- 2.10日之前,考虑到本文的主旨核心ChatGPT用到了RLHF和PPO,所以本文的第一部分从强化学习讲到PPO算法,毕竟虽然只是想重点介绍下PPO,但写到最后还是把PPO所有相关的前置知识都细致介绍了个遍,不然,总感觉有细节没交待而不够透彻
- 2.10日之后,又考虑到有些朋友可能对RL细节有所了解,或者更多希望整体了解ChatGPT整体架构而暂不细究其所用的策略迭代算法PPO的前置技术、RL细节
综上,为兼顾两者,且加之为避免本文篇幅过长而影响完读率,故把下面原先第一部分的大部分内容抽取出来放到了新一篇RL笔记里进一步细致阐述:强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO
第一部分 RL基础:什么是RL与MRP、MDP
1.1 入门强化学习所需掌握的基本概念
- 1.1.1 什么是强化学习:依据策略执行动作-感知状态-得到奖励
- 1.1.2 RL与监督学习的区别和RL方法的分类
1.2 什么是马尔科夫决策过程
- 1.2.1 MDP的前置知识:随机过程、马尔可夫过程、马尔可夫奖励
- 1.2.2 马尔可夫决策过程(MDP):马尔可夫奖励(MRP) + 智能体动作因素
第二部分 RL进阶之三大表格求解法:DP、MC、TD
2.1 动态规划法
- 2.1.1 什么是动态规划
- 2.1.2 通过动态规划法求解最优策略
2.2 蒙特卡洛法
2.3 时序差分法及与DP、MC的区别
2.4 RL的分类:基于模型(Value-base/Policy-based)与不基于模型
第三部分 价值学习:从n步Sarsa算法到Q-learning、DQN
3.1 TD(0)控制/Sarsa(0)算法与TD(n)控制/n步Sarsa算法
3.2 Q-learning
- 3.2.1 重要性采样:让同策略完成到异策略的转变
- 3.2.2 Sarsa算法与Q-learning更新规则的对比
3.3 DQN
第四部分 策略学习:从策略梯度、Actor-Criti到TRPO、PPO算法
4.1 策略梯度与其突出问题:采样效率低下
- 4.1.1 什么是策略梯度和梯度计算/更新的流程
- 4.1.2 避免采样的数据仅能用一次:重要性采样(为采样q解决p从而增加重要性权重)
4.2 优势演员-评论家算法(Advantage Actor-Criti):为避免奖励总为正增加基线
4.3 基于信任区域的TRPO:加进KL散度解决两个分布相差大或步长难以确定的问题
1.4 近端策略优化PPO:解决TRPO的计算量大的问题
如上所述,PPO算法是针对TRPO计算量的大的问题提出来的,正因为PPO基于TRPO的基础上改进,故PPO也解决了策略梯度不好确定学习率Learning rate (或步长Step size) 的问题
毕竟通过上文,我们已经得知
- 如果 step size 过大, 学出来的 Policy 会一直乱动,不会收敛;但如果 Step Size 太小,想完成训练,我们会等到地老天荒
- 而PPO 利用 New Policy 和 Old Policy 的比例,限制了 New Policy 的更新幅度,让策略梯度对稍微大点的 Step size 不那么敏感
具体做法是,PPO算法有两个主要的变种:近端策略优化惩罚(PPO-penalty)和近端策略优化裁剪(PPO-clip),其中PPO-penalty和TRPO一样也用上了KL散度约束。
近端策略优化惩罚PPO-penalty的流程如下
-
首先,明确目标函数,咱们需要优化
,让其最大化
『注:如果你想仔细抠接下来各种公式但一上来就被上面这个弄迷糊了,说明还是需要先看下上文说过的这篇RL极简入门,而一旦踏入RL,便得做好两万五千里的准备,当然,如果只是想了解ChatGPT背后大概的技术原理,可以不用细抠PPO的公式怎么来的,不影响你对ChatGPT整体架构的理解,且下文会讲其在ChatGPT中是如何运用的』
-
接下来,先初始化一个策略的参数
,在每一个迭代里面,我们用前一个训练的迭代得到的actor的参数
与环境交互,采样到大量状态-动作对, 根据
交互的结果,估测
- 由于目标函数牵涉到重要性采样,而在做重要性采样的时候,
不能与
相差太多,所以需要在训练的时候加个约束,这个约束就好像正则化的项一样,是
所以需要最后使用 PPO 的优化公式:
当然,也可以把上述那两个公式合二为一『如此可以更直观的看出,PPO-penalty把KL散度约束作为惩罚项放在了目标函数中(可用梯度上升的方法去最大化它),此举相对TRPO减少了计算量』
上述流程有一个细节并没有讲到,即是怎么取值的呢,事实上,
是可以动态调整的,故称之为自适应KL惩罚(adaptive KL penalty),具体而言
- 先设一个可以接受的 KL 散度的最大值
假设优化完以后,KL 散度值太大导致
,意味着
惩罚效果太弱而没有发挥作用,故增大惩罚把
增大
- 再设一个 KL 散度的最小值
如果优化完,意味着
总之,近端策略优化惩罚可表示为
当然,如果觉得计算 KL散度很复杂,则还有一个PPO2算法,即近端策略优化裁剪PPO-clip,包括PPO算法的一个简单实现,均详见RL极简入门一文
1.5 模仿学习(逆强化学习)思路下的RLHF:从人类反馈中学习
1.5.1 什么是模仿学习(逆强化学习)
虽然RL理论上虽不需要大量标注数据,但实际上它所需求的reward会存在缺陷:
-
比如游戏AI中,reward的制定非常困难,可能要制定成百上千条游戏规则,这并不比标注大量数据来得容易,又比如自动驾驶的多步决策(sequential decision)场景中,学习器很难频繁地获得reward,容易累计误差导致一些严重的事故
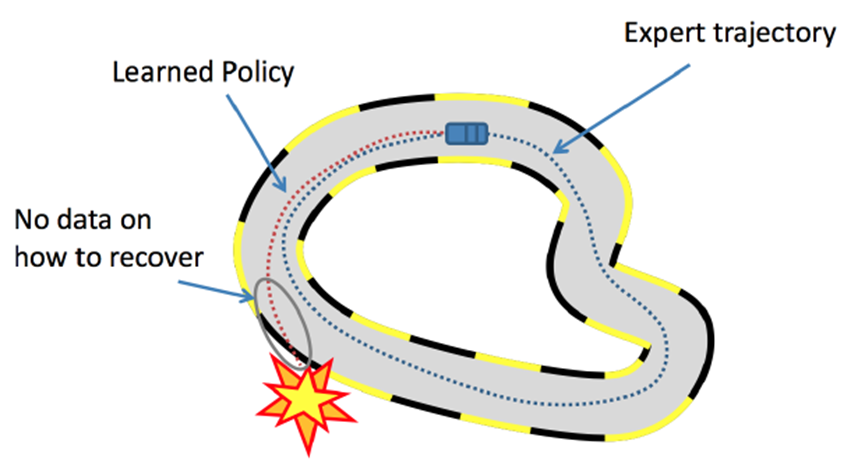
-
再比如聊天机器人方面,不好定义什么是好的对话、什么是不好的对话,当然,对此可以收集很多人类的对话当做范例,如此,模仿学习思路下的基于人来偏好的深度强化学习(对应论文为:Deep Reinforcement Learning from Human Preferences 2017,简称RLHF)应运而生
RLHF试图解决的问题是,在奖励函数不够明确的情况下,通过基于人类对事物比较的偏好而非绝对奖励值训练奖励函数
模仿学习的思路是不让模型在人类制定的规则下自己学习,而是让模型模仿人类的行为。而逆强化学习就是模仿学习的其中一种,何谓逆强化学习呢?
- 原来的强化学习里,有Environment和Reward Model(由奖励函数推出什么样的策略/动作是最好的),但逆强化学习没有奖励函数,只有一些人类/专家的示范,怎么办呢
- 可以通过人类标注数据训练得到Reward Model(相当于有了人类标注数据,则相信它是不错的,然后反推人类因为什么样的奖励函数才会采取这些行为)
- 有了奖励函数之后,就可以使用一般的强化学习的方法去找出最优策略/动作
1.5.2 RLHF:基于人类偏好的深度强化学习
实际上,RLHF(Reinforcement Learning with Human Feedback)这一概念最早被定义为基于人类反馈的强化学习,它最早是在2008年《TAMER:Training an Agent Manually via Evaluative Reinforcement》一文中被提及的
在2017年前后,深度强化学习(Deep Reinforcement Learning)逐渐发展并流行起来,如你所见,2017年6月由OpenAI联合Google DeepMind一块推出:基于人类偏好的深度强化学习《Deep Reinforcement Learning from Human Preferences》,也简称RLHF

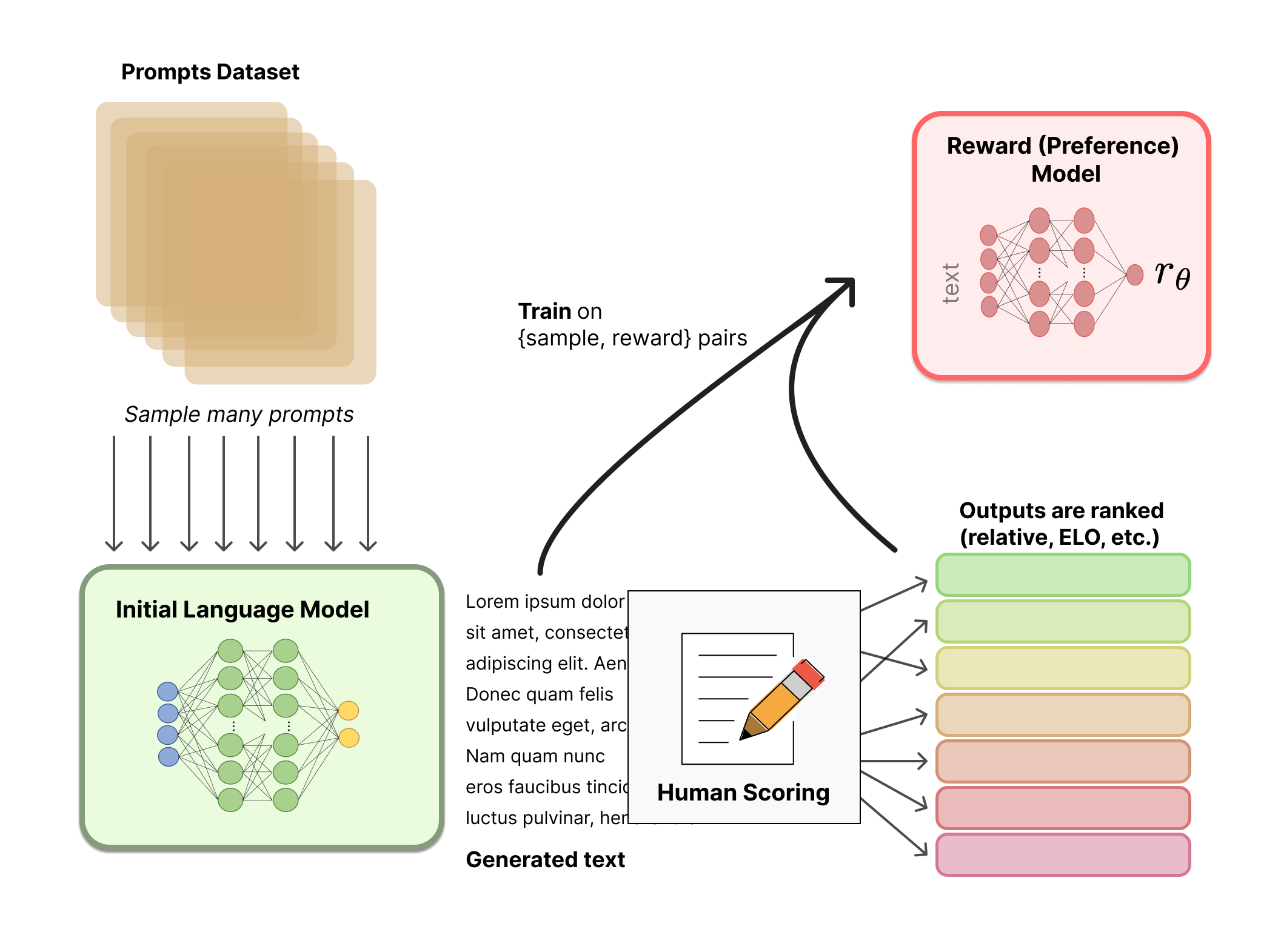
当让一个强化学习智能体探索环境并与之交互(比如Atari游戏),RLHF的核心步骤如下图所示:
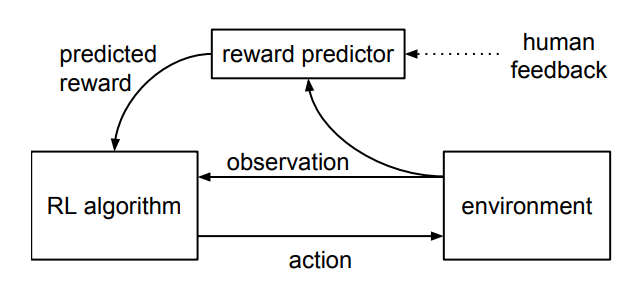
- 首先,智能体的一对1-2秒的行为片段定期地回馈给人类操作员,人类基于偏好对智能体的行为作出某种偏好性的选择评判
- 接着,人类这种基于偏好的选择评判被预测器(reward predictor)来预测奖励函数
- 智能体通过预测器预测出的奖励函数作出更优的行为(毕竟智能体要最大化奖励嘛)
再之后,OpenAI团队通过下述两篇论文进一步阐述了RLHF
- Fine-Tuning Language Models from Human Preferences (Zieglar et al. 2019)
在Reward model的训练中,我们需要人的参与,human labelers给policy模型生成的文本进行选择「比如在四个答案选项(y0,y1,y2,y3)中选择一个最好的」,这个选择作为reward model学习的标签Reward mode训练好后,那么在训练policy model时,Reward model便可以完全取代human labeler选择,这种基于偏好的选择作为信号传给policy model,再利用OpenAI默认的策略优化算法PPO来训练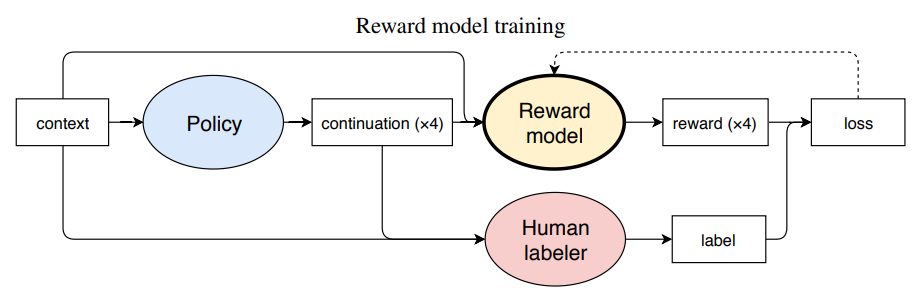
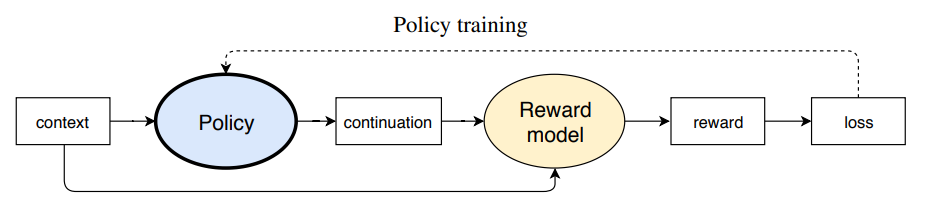
- Learning to summarize with human feedback (Stiennon et al., 2020)
OpenAI团队在2020年9月的这篇论文里通过RLHF的方式训练语言模型,然后让其做摘要任务1 收集人类对摘要的偏好数据,比如针对同一篇帖子的两个不同摘要,人类标注出哪个摘要更好(We first collect a dataset of human preferences between pairs of summaries)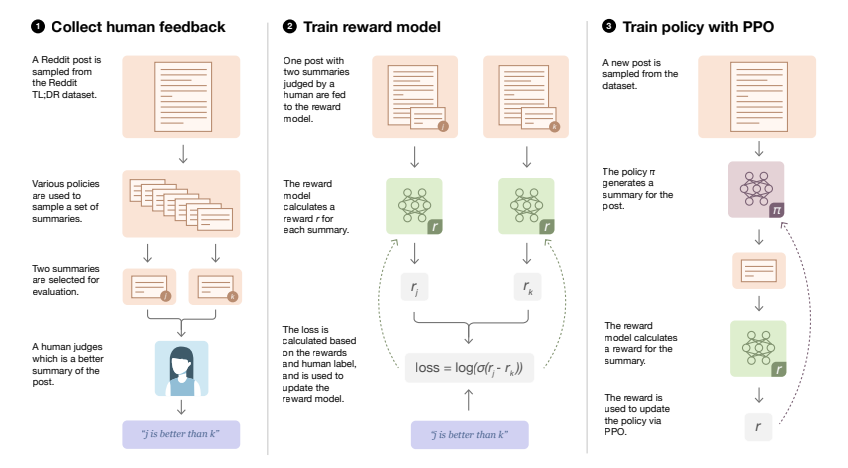
2 训练一个奖励函数,使其可以越发准确的判断:针对同一篇帖子,人类更喜欢的那个摘要是哪个摘要,即train a reward model (RM) via supervised learning to predict the human-preferred summary
(下文会详述reward的这个损失函数,这里暂且做个粗略理解,即相当于reward不再是人直接给了,而是用高质量的标注数据训练一个好的reward模型)3 有了reward,接下来便可以基于让RM给出的分值最大化的前提之下,通过PPO算法优化模型的策略,且为避免RM过于绝对,还给RM加了个
(即we train a policy via reinforcement learning (RL) to maximize the score given by the RM; the policy generates a token of text at each ‘time step’, and is updated using the PPO algorithm based onthe RM ‘reward’ given to the entire generated summary,下文会详细阐述这个公式)
第二部分 从GPT/GPT2/GPT3到GPT3.5/GPT4:见证微调、prompt学习、再微调、多模态
2.1 GPT:基于Transformer Decoder预训练 + 微调/Finetune
NLP自发展以来,先后经历了4种任务处理范式
- 第一种范式,非神经网络时代的完全监督学习(Fully Supervised Learning, Non-Neural Network)
具体而言,即手工设计一系列特征模板,来输入模型。模型对任务的处理结果高度依赖于特征模板的设计,同时也高度依赖领域专家的知识。举个例子,比如对于条件随机场CRF模型,业界甚至有一个专门的库CRF++帮助自动生成大量的随机模板然后输入模型进行训练,从而避免对领域专家的过度依赖 - 第二范式,基于神经网络的完全监督学习(Fully Supervised Learning, Neural Network)
神经网络学派开始流行以后,处理范式基本基本是预训练后的词嵌入表征 + 模型架构的调整,在这个时期,一方面的工作在词嵌入上,比如NNLM/CBOW/SKIP/GRAM/GLOVE/ELMO等,另一方面的工作则在模型架构上,比如BI-LSTM/SEQ2SEQ架构在神经机器翻译领域NMT的应用等 - 第三范式,预训练-微调范式 (Pre-train、Fine-tune)
相比于第二范式而言,第三范式的优点在于更进一步减少了人工的参与,不再需要对于每个任务采取不同的模型架构,而是在超大的文本数据集上预训练一个具备泛化能力的通用的模型,然后再根据下游任务本身的特点对模型进行针对性的微调即可,使得一个模型解决多种任务成为可能,比如GPT1模型 - 第四范式,预训练、提示、预测范式(Pre-train、Prompt、Predict)
在这个过程我们往往不对预训练语言模型改动太多,我们希望是通过对合适prompt的利用将下游任务建模的方式重新定义,这则是GPT2、GPT3的特点
2.1.1 GPT = Multi-Head Attention层 + Feed forward层 + 求和与归一化的前置LN层 + 残差
GPT由OpenAI在2018年通过此论文“Improving Language Understanding by Generative Pre-Training”提出,使用了一个大型的未标记文本语料库来进行生成式预训练(该语料库包含40GB的文本数据,比如互联网上抓取的网页、维基百科、书籍和其他来源的文本)
在GPT 被提出之前
- 大多数深度学习方法都需要大量人工标注的高质量数据,但是标注数据的代价是巨大的
故如何利用容易获取的大规模无标注数据来为模型的训练提供指导成为亟待解决的第一个问题 - 另外NLP领域中有许多任务依赖于自然语言在隐含空间中的表征,不同任务对应的表征很可能是不同的,这使得根据一种任务数据学习到的模型很难泛化到其他任务上
因此如何将从大规模无标注数据上学习到的表征应用到不同的下游任务成为亟待解决的第二个问题
在上一篇Transformer笔记中,我们已经了解到:GPT是“Generative Pre-Training Transformer”的简称,从名字看其含义是指的生成式的预训练,它和BERT都是(自监督)预训练-(有监督)微调模式的典型代表
- 第一阶段,在未标记数据上使用语言建模目标来学习神经网络模型的初始参数
- 第二阶段,针对目标任务使用相应的标记数据对这些参数进行微调
之所以叫微调是因为在这个阶段用的数据量远远小于第一阶段,并且基本没有更改模型架构和引入过多新的参数
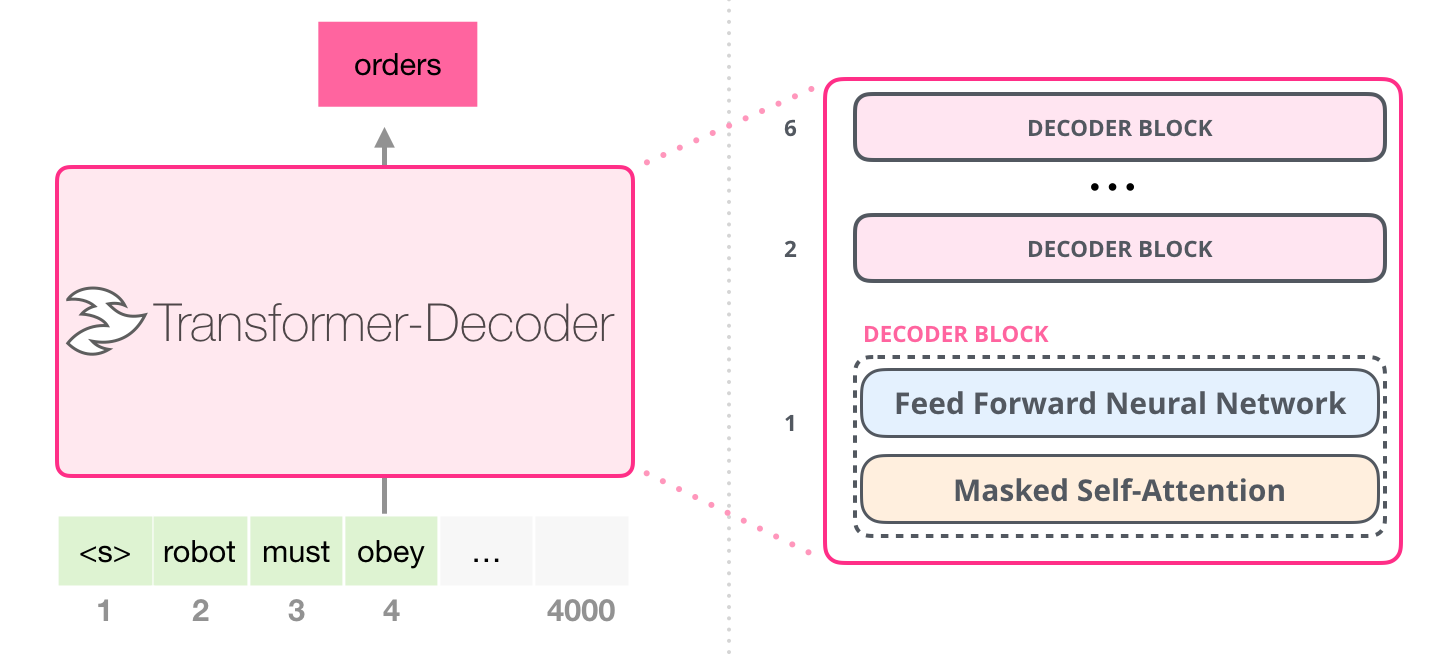
由于Decoder具备文本生成能力,故作为侧重生成式任务的GPT选择了Transformer Decoder部分作为核心架构
不过,与原始的Transformer Decoder相比,GPT所用的结构删除了Encoder-Decoder Attention,只保留了多头注意力层Multi-Head Attention层和前馈神经网络Feed forward层(This model applies a multi-headed self-attention operation over theinput context tokens followed by position-wise feedforward layers to produce an output distributionover target tokens),最后再加上求和与归一化的前置LN层 + 残差,且在参数上有以下变化
- 层数从原始Transformer的6层增加到12层,相当于12层的Transformer Decoder
- 输入向量的维度从原始Transformer的512维扩大到768维,且将Attention的头数从8增加到12,从而每个头的维度依然是768/12 = 64维

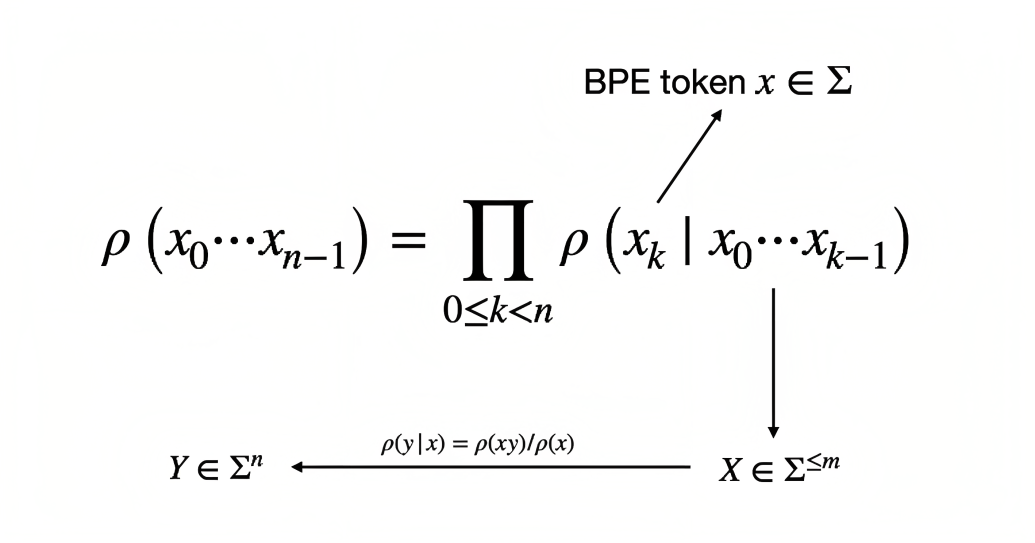
通过这样的结构,GPT便可以利用无标注的自然语言数据进行训练:根据给定的前个token,预测第
个token,训练过程中使用的是基于最大似然估计的损失函数,即让模型预测的概率分布尽可能接近实际下一个单词的分布
具体来说,当你给定前面的若干个词后,它会给你下一个词;而当你有了下一个词后,它会再给你接一个词,以此递推
- 实际上,我们向GPT提出的问题,可以看成是下图的输入
,然后我们可以将GPT给出的回答抽象成下图的输出
- 而GPT这类语言模型,提供了若干个类似手机输入法的“候选句”,每个候选句对应的概率不一
- 所谓的语言模型的训练,其实就是让模型调整候选句对应的概率,使得输出的候选句的概率尽可能大
其中的关键便是这个Self-Attention,模型通过自注意力机制可以学习序列中不同位置之间的依赖关系,即在处理每个位置的信息时,模型会考虑序列中和该位置的信息有关联的其他所有位置上的信息,这种机制使得模型能够有效地处理长距离依赖关系
2.1.2 什么是Self-Attention与Masked Self-Attention
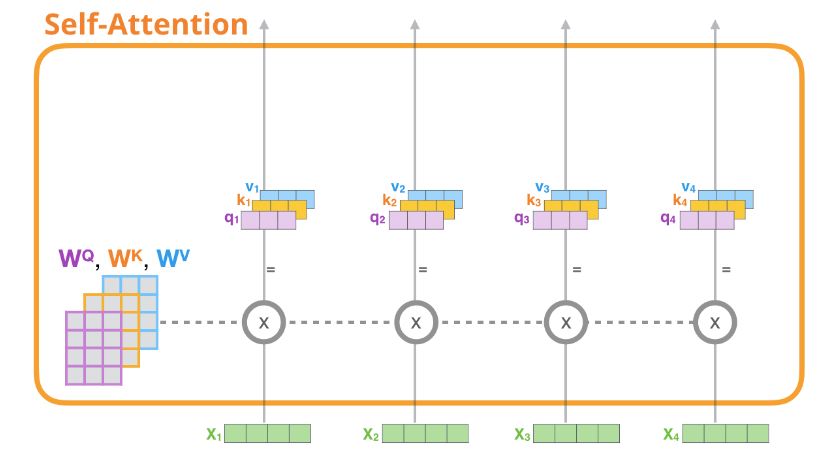
所谓自注意力,即指当我们需要用到自注意力编码单词 的时候,会按下面几个步骤依次处理(配图来自此文)
- 为每个单词路径创建Query、Key、Value,具体做法就是每个单词的表示向量和对应的权重矩阵(
)做矩阵乘法
- 对于每个输入token,使用其Query向量对其他所有的token的Key向量进行评分,获得注意力分数,比如通过
的
向量,分别与
的
向量分别做点乘,最终得到
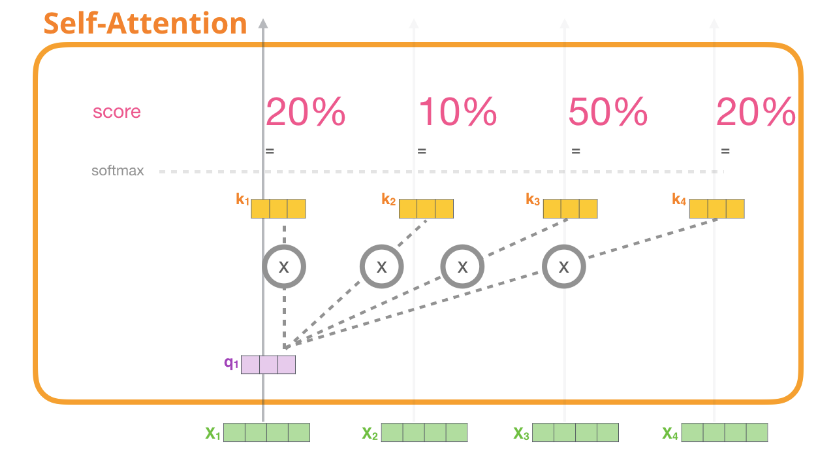
- 将Value向量乘以上一步得到的注意力分数(相当于对当下单词而言,不同单词重要性的权重),之后加起来,从而获得所有token的加权和
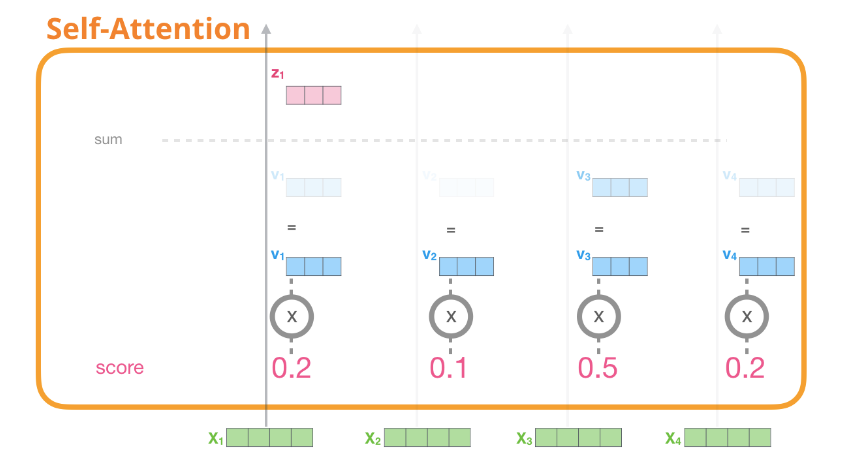
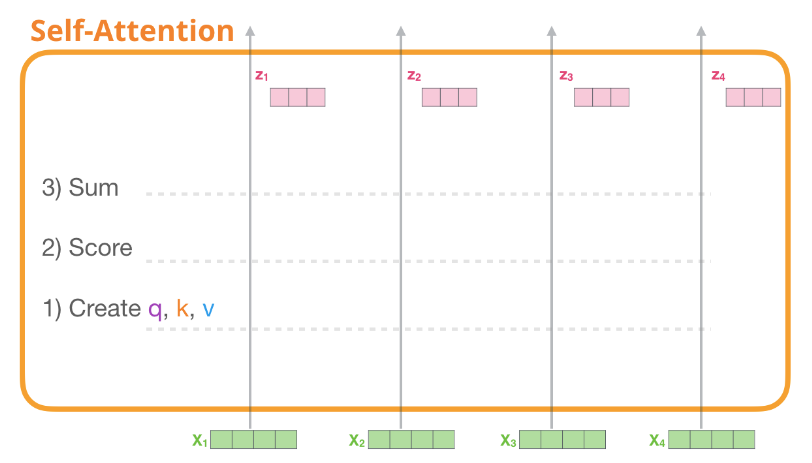
之后对每个token都进行上述同样的三步操作,最终会得到每个token新的表示向量,新向量中包含该token的上下文信息,之后再将这些数据传给Transformer组件的下一个子层:前馈神经网络
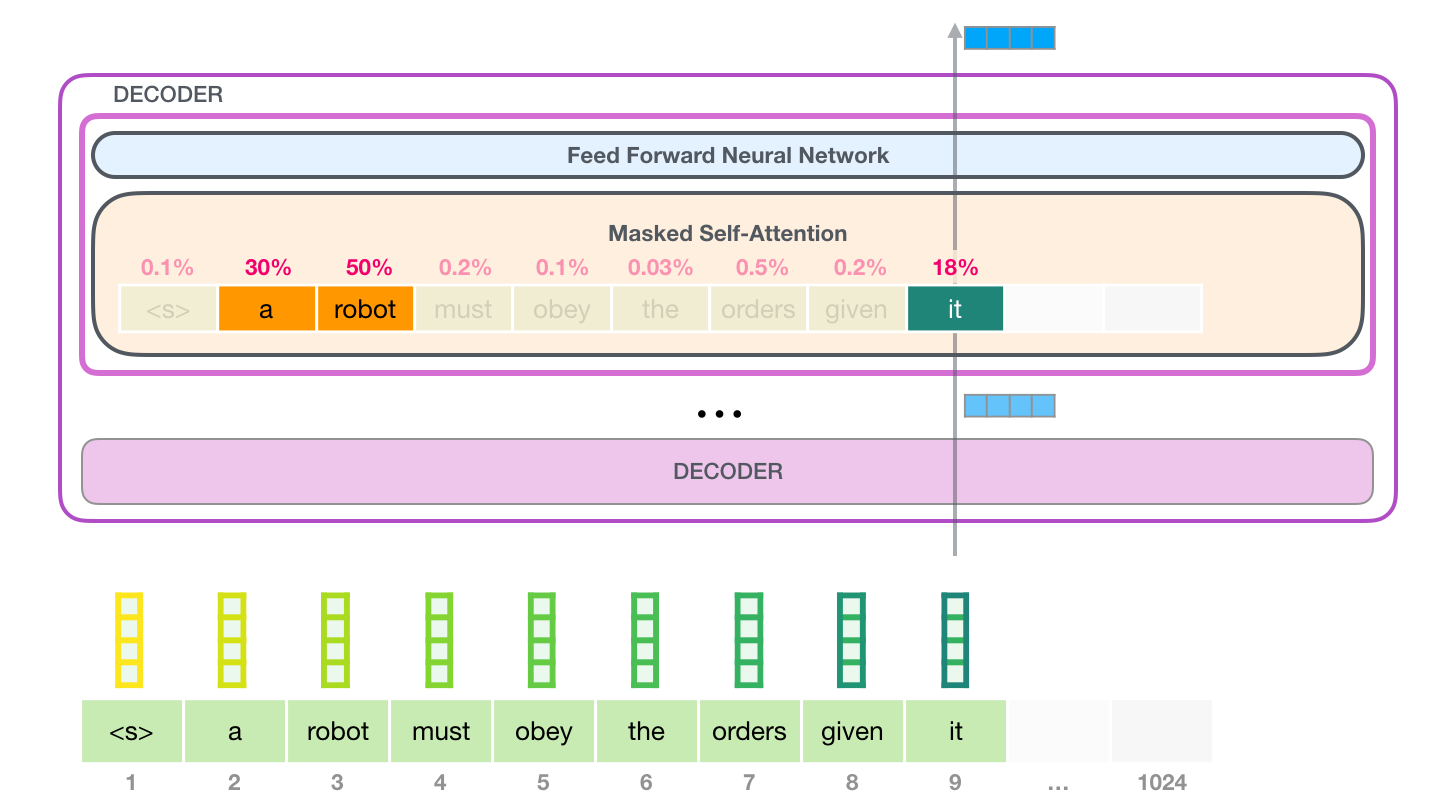
至于所谓Masked Self-Attention就是在处理当前词的时候看不到后面的词。举个例子,处理“it”的时候,注意力机制看不到“it”后面的词(通过将“it”后面的词的权重设置为一个非常大的负数,进一步softmax之后变为0,从而屏蔽掉),但会关注到“it”前面词中的“a robot”,继而注意力会计算三个词“it”、“a”、“robot”的向量及其attention分数的加权和
更多细节可以看下上篇BERT笔记(特别是此前还不了解Transformer的),或此文:图解注意力机制
2.2 GPT2承1启3:基于prompt尝试舍弃微调 直接Zero-shot Learning
GPT2相比GPT1的变动主要体现在两方面,一方面是模型结构上,一方面是推理模式上
在模型结构上
- LN层被放置在self-attention层和feed forward层之前,可称为pre-norm(毕竟GPT1和原始transformer是先self-attention再LN,或先feed forward再LN,可称为post-norm),并在最后一层transformer Block后新增LN层
Layer normalization (Ba et al., 2016)was moved to the input of each sub-block, similar to apre-activation residual network (He et al., 2016) and anadditional layer normalization was added after the final self-attention block
值得一提的是,自GPT2起,之后的大部分模型基本都用的pre-norm(当然,也有用post-norm的改进版post deepNorm的,比如GLM)
- 修改初始化的残差层权重,缩放为原来的
,其中
是残差层的数量
We scale the weights of residual layers at initial-ization by a factor of 1/ N where N is the number ofresidual layers
考虑到七月LLM论文100篇带读的一学员对这点有疑问,特此再解释下
残差连接的基本形式为,其中
是输入,
是输入
当子模块的深度堆叠多层时,为了确保训练的稳定性并防止梯度消失或爆炸,将残差层的权重缩放是一个常用的策略,具体地说,GPT-2 在其残差连接中使用了权重缩放因子,其中
这意味着残差连接的形式变为
这样的缩放确保了当 - transformer block的层数从12层扩大到48层(相当于transformer 6层
GPT1 12层
- 特征向量维度从GPT1的768维扩大到1600维(相当于transformer 512维
在推理模式上,虽然GPT1的预训练加微调的范式仅需要少量的微调即可,但能不能有一种模型完全不需要对下游任务进行适配就可以表现优异?GPT2便是在往这个方向努力:不微调但给模型一定的参考样例以帮助模型推断如何根据任务输入生成相应的任务输出
最终,针对小样本/零样本的N-shot Learning应运而生,分为如下三种
- Zero-shot Learning (零样本学习),是指在没有任何样本/示例情况下,让预训练语言模型完成特定任务
相当于不再使用二阶段训练模式(预训练+微调),而是彻底放弃了微调阶段,仅通过大规模多领域的数据预训练,让模型在Zero-shot Learming的设置下自己学会解决多任务的问题,而且效果还不错(虽然GPT2通过Zero-shot Learming在有些任务的表现上尚且还不如SOTA模型,但基本超越了一些简单模型,说明潜力巨大),你说神不神奇?
这就好比以前我们刚开始学解题时,听老师讲了一系列知识和方法之后,老师为了让我们更好的解题,在正式答题考试之前,会先通过几个样题让我们找找感觉,方便在样题中微调或修正自己对所学知识/方法的理解
Zero-shot Learming则相当于没有练手/预热、没有参考样例/演示/范本,学完知识/方法之后直接答题! - One shot Learning (单样本学习),顾名思义,是指在只有一个样本/示例的情况下,预训练语言模型完成特定任务
- Few-shot Learning (少样本或小样本学习),类似的,是指在只有少量样本/示例的情况下,预训练语言模型完成特定任务
此外,只需将自然语言的任务示例和提示信息作为上下文输入给GPT-2,它就可以在小样本的情况下执行任何NLP任务,包括所谓的完形填空任务,比如
假如我要判断“我喜欢这个电影" 这句话的情感(“正面" 或者 "负面"),原有的任务形式是把他看成一个分类问题
输入:我喜欢这个电影
输出:“正面" 或者 "负面"
而如果用GPT2去解决的话,任务可以变成“完形填空",
输入:我喜欢这个电影,整体上来看,这是一个 __ 的电影
输出:“有趣的" 或者 "无聊的"
加的这句提示“整体上来看,这是一个 __ 的电影”对于让模型输出人类期望的输出有很大的帮助。
这个所谓的提示用NLP的术语表达就是prompt,即给预训练语言模型的一个线索/提示,帮助它可以更好的理解人类的问题
例如有人忘记了某篇古诗,我们给予特定的提示,他就可以想起来,例如当有人说:
白日依山尽
大家自然而然地会想起来下一句诗:黄河入海流
亦或者,搜索引擎,可以根据我们的输入,进行输出的提示:
2.3 GPT3:In-context learning正式开启prompt新范式(小样本学习)
2.3.1 GPT3在0样本、单样本、小样本下的突出能力
GPT3简单来说,就是参数规模大(有钱)、训练数据规模大(多金)、效果出奇好,具体而言
- 它最大规模版本的参数规模达到了1750亿,层数达到了96层,输入维度则达到了12888维(设置了96个注意力头,故每个头的维度为12888/96 = 128维,类比原始transformer中:输入维度为512维,设置8个头,每个头的维度为512/8 = 64维)

- 并且使用45TB数据进行训练(当然,GPT3论文中说道:constituting 45TB of compressed plaintext before filtering and 570GB after filtering, roughly equivalent to 400 billion byte-pair-encoded tokens),至于数据组成上,则包括Common Crawl、WebText2、Books1/2、Wikipedia的数据
为方便大家更好理解,举个例子说明下,比如对于410B大小的CC数据集(在一开始的整个数据集大小499B中占比82.1%),其采样比例是60%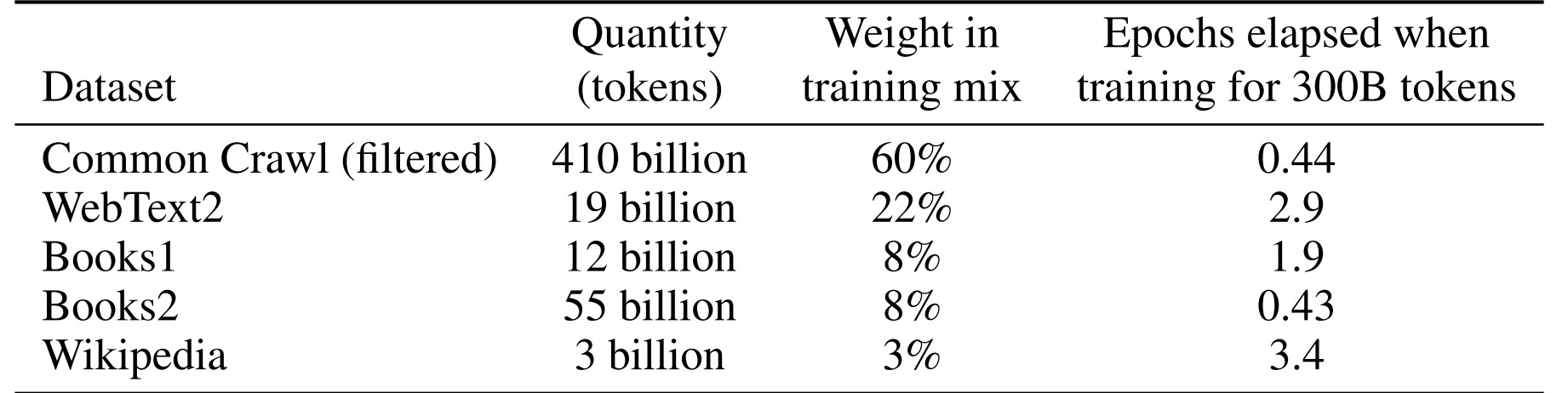
但实际训练时 整个数据集最终变成了是300B,然后CC数据集采样了300B的60% = 180,而180的数据在CC 410的数据中 相当于训了180/410 = 0.44个epoch - 其预训练任务就是“句子接龙”,给定前文持续预测下一个字,而且更为关键的是,当模型参数规模和训练数据的规模都很大的时候,面对小样本时,其性能表现一度超越SOTA模型
为形象描述,举一个GPT3在0样本、单样本、少量样本下的机器翻译使用范例,如下图
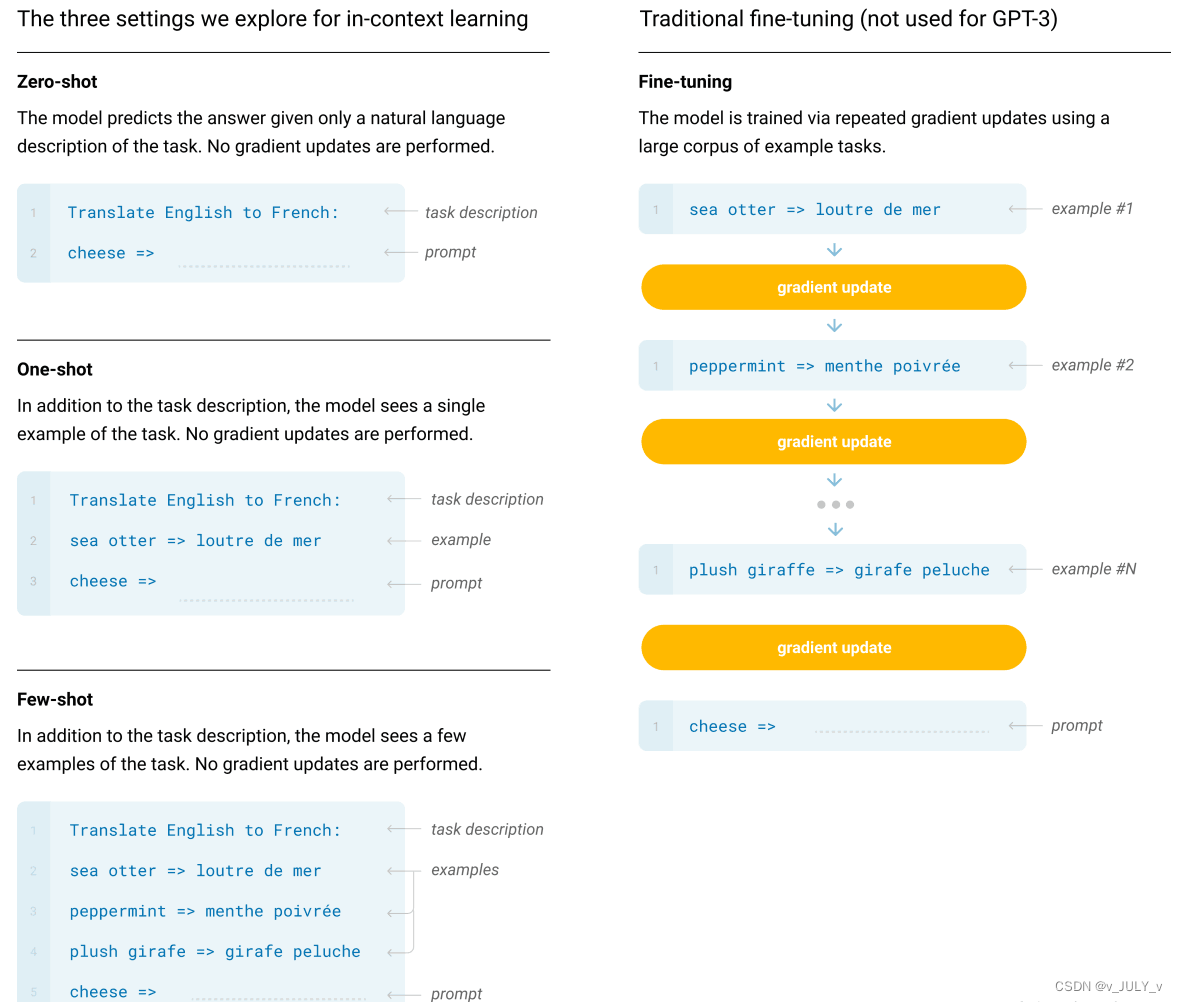
- 图中右侧是普通模型微调的过程,模型通过大量训练预料进行训练,然后基于特定的任务数据进行梯度迭代更新(gradient update),训练至收敛后的模型才具备良好的翻译能力
- 图中左侧是GPT3分别在0样本(只给出任务描述)、单样本(只给出任务描述+一个翻译样本)、小样本(给出任务描述+少量样本)的情况下所展示出的能力
一方面,单样本也好 小样本也好,更多只是作为例子去提示模型,模型不利用样本做训练,即不做模型参数的任何更新
二方面,人们一度惊讶于其在0样本下如此强大的学习能力,使得很多人去研究背后的In Context Learning
毕竟,我们知道普通模型微调的原理:拿一些例子当作微调阶段的训练数据,利用反向传播去修正LLM的模型参数,而修正模型参数这个动作,确实体现了LLM从这些例子学习的过程
但是,In Context Learning只是拿出例子让LLM看了一眼,并没有根据例子,用反向传播去修正LLM模型参数的动作,就要求它去预测新例子
此举意味着什么呢?
1 既然没有修正模型参数,这意味着LLM并未经历一个修正过程,相当于所有的举一反三和推理/推断的能力在上一阶段预训练中便已具备(或许此举也导致参数规模越来越大),才使得模型在面对下游任务时 不用微调、不做梯度更新或参数更新,且换个角度讲,如此巨大规模的模型想微调参数其门槛也太高了
2 预训练中 好的预训练数据非常重要,就好比让模型在0样本下翻译英语到法语,那预训练数据中 必然有大量英语、法语的文本数据
3 抓什么样的数据 多大规模 怎么喂给模型等等一系列工程细节,这块是导致很多模型效果有差距的重要原因之一
2.3.2 In Context Learning(ICL)背后的玄机:隐式微调?
零样本下 模型没法通过样本去学习/修正,但即便是少样本下,也有工作试图证明In Context Learning并没有从样本中学习,比如“Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?”,它发现了:
- 在提供给LLM的样本示例
中,
是否是
对应的正确答案其实并不重要,如果我们把正确答案
,这并不影响In Context Learning的效果
比如下图中,无论是分类任务(图中上部分),还是多项选择任务(图中下部分),随机标注设置下(红)模型表现均和正确标注(黄)表现相当,且明显超过没有in-context样本的zero-shot设置(蓝)这起码说明了一点:In Context Learning并没有提供给LLM那个从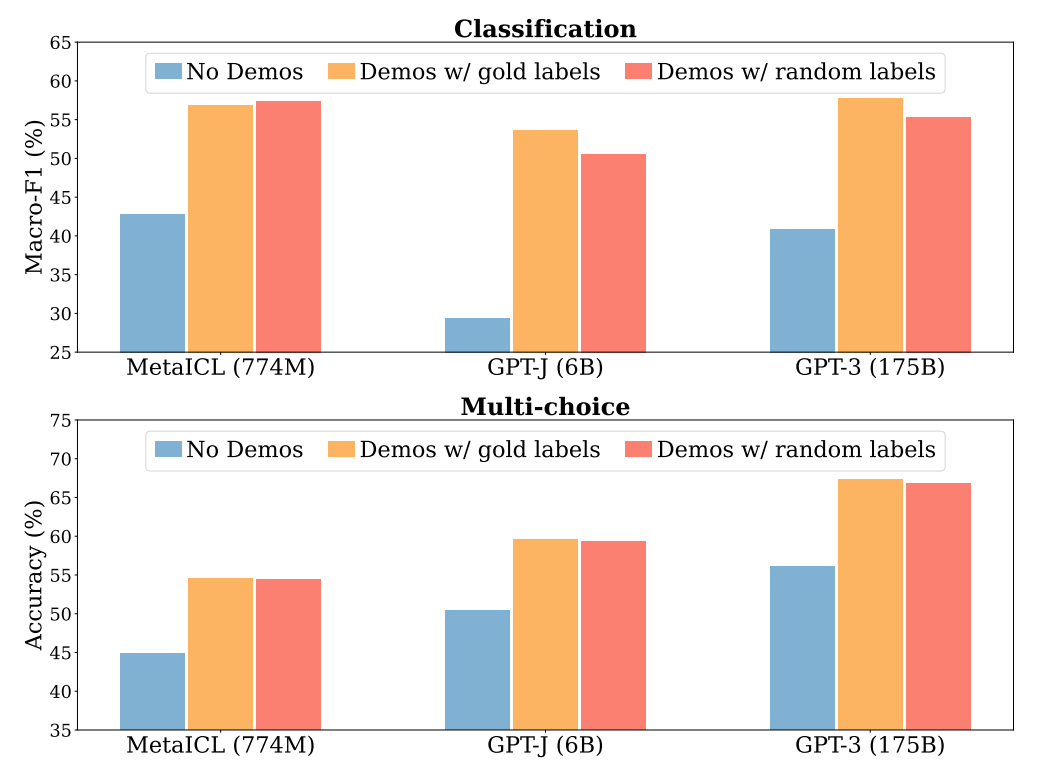
的映射函数信息:
否则的话你乱换正确标签,肯定会扰乱这个映射函数,也就是说,In Context Learning并未学习这个输入空间到输出空间的映射过程
- 真正对In Context Learning影响比较大的是:
总之,这个工作证明了In Context Learning并未学习映射函数,但是输入和输出的分布很重要,这两个不能乱改
然而,有些工作认为LLM还是从给出的示例学习了这个映射函数,不过是种隐式地学习
- 比如“What learning algorithm is in-context learning? Investigations with linear models”认为Transformer能够隐式地从示例中学习
- 再比如“Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers(此为该论文的解读之一)”这篇文章则将ICL看作是一种隐式的Fine-tuning
文章中提出,关键在于 LLM 中的注意力层(attention layers),在推理过程实现了一个隐式的参数优化过程,这和fine-tuning的时候通过梯度下降法显式优化参数的过程是类似的,更多可以看下原论文
2.4 Prompt技术的升级与创新:指令微调技术(IFT)与思维链技术(CoT)
2.4.1 Google提出FLAN大模型:基于指令微调技术Instruction Fine-Tuning (IFT)
OpenAI的GPT3虽然不再微调模型(pre-training + prompt),但Google依然坚持预训练 + 微调的模式
2021年9月,谷歌的研究者们在此篇论文中《Finetuned Language Models Are Zero-Shot Learners》提出了基于Instruction Fine-Tuning(指令微调,简称IFT)的FLAN大模型(参数规模为137B),极大地提升了大语言模型的理解能力与多任务能力,且其在评估的25个数据集中有20个数据集的零样本学习能力超过175B版本的GPT3(毕竟指令微调的目标之一即是致力于improving zero-shot generalization to tasks that were not seen in training),最终达到的效果就是:遵循人类指令,举一反三地完成任务
有两点值得注意的是
- 根据论文中的这句话:“FLAN is the instruction-tuned version of LaMDA-PT”,可知指令微调的是LaMDA,而LaMDA是Google在21年5月对外宣布内部正在研发的对话模型(不过,LaMDA的论文直到22年1月才发布)
- 论文中也解释了取名为FLAN的缘由
We take a pretrained language model of 137B parameters and perform instruction tuning—finetuning the model on a mixture of more than 60 NLP datasets expressed via natural language instructions.
We refer to this resulting model as FLAN, for Finetuned Language Net
至于IFT的数据通常是由人工手写指令和语言模型引导的指令实例的集合,这些指令数据由三个主要组成部分组成:指令、输入和输出,对于给定的指令,可以有多个输入和输出实例

相比于GPT-3,且区别在于Finetune,FLAN的核心思想是,当面对给定的任务A时,首先将模型在大量的其他不同类型的任务比如B、C、D...上进行微调,微调的方式是将任务的指令与数据进行拼接(可以理解为一种Prompt),随后给出任务A的指令,直接进行推断,如下图所示
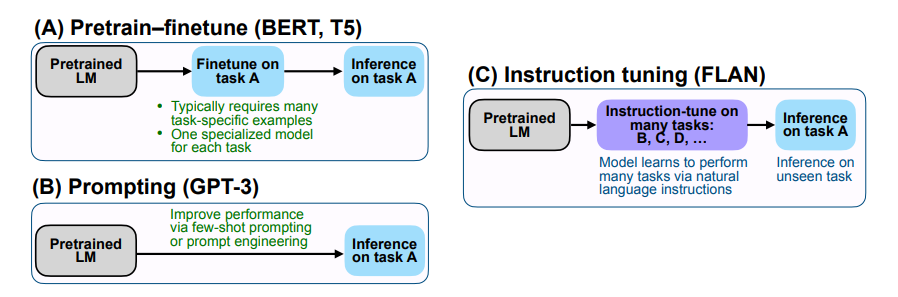
例如,我们的最终目标是推理任务
- FLAN首先讲语言模型在其他任务上进行微调,包括给定任务指令的翻译、常识推理、情感分类等
在面对翻译任务时可以给出指令“请把这句话翻译成西班牙语”
在面对常识推理任务时可以给出指令“请预测下面可能发生的情况” - 而当模型根据这些“指令”完成了微调阶段的各种任务后(将指令拼接在微调数据的前面),在面对从未见过的自然语言推理任务的指令比如:“这段话能从假设中推导出来吗?” 时,就能更好地调动出已有的知识回答问题
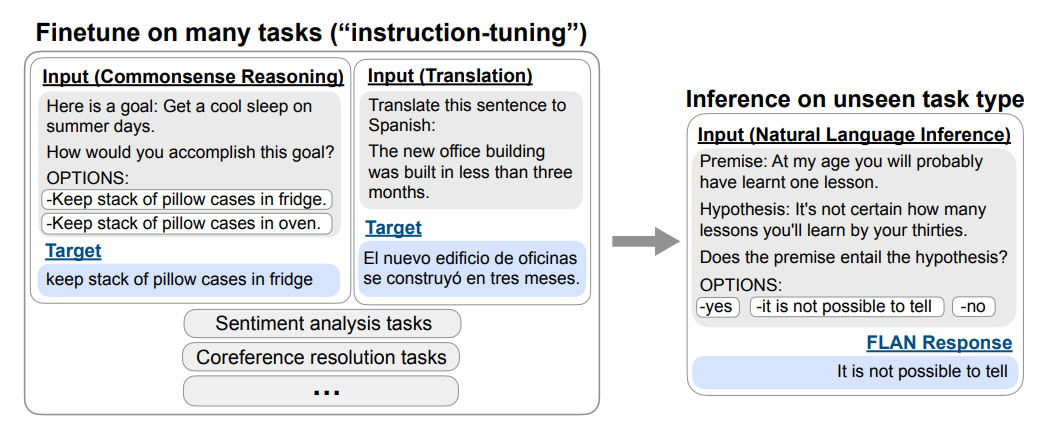
相当于通过指令微调之后,模型可以更好的做之前预训练时没见过的新任务且降低了对prompt的敏感度(某些场景下不一定非得设计特定prompt才能激发模型更好的回答)
这或许也启发了OpenAI重新注意到了微调这一模式(毕竟如上文所述,原本GPT3在预训练之后已彻底放弃再微调模型),从而在InstructGPT中针对GPT3做Supervised fine-tuning(简称SFT)
2.4.2 关于PL的进一步总结:到底如何理解prompt learning
自此,总结一下,关于「prompt learning」最简单粗暴的理解,其实就是让模型逐步学会人类的各种自然指令或人话,而不用根据下游任务去微调模型或更改模型的参数,直接根据人类的指令直接干活,这个指令就是prompt,而设计好的prompt很关键 也需要很多技巧,是一个不算特别小的工程,所以叫prompt engineering,再进一步,对于技术侧 这里面还有一些细微的细节
GPT3 出来之前(2020年之前),模型基本都是预训练 + 微调,比如GPT1和BERT
GPT3刚出来的时候,可以只预训练 不微调,让模型直接学习人类指令直接干活 即prompt learning,之所以可以做到如此 是因为GPT3 当时具备了零样本或少样本学习能力
当然,说是说只预训练 不微调,我个人觉得还是微调了的,只是如上文所说的某种隐式微调而已2021年,Google发现微调下GPT3后 比OpenAI不微调GPT3在零样本上的学习能力更加强大
从而现在又重新回归:预训练之后 再根据下游任务微调的模式,最后封装给用户,客户去prompt模型
所以现在的prompt learning更多针对的是 去提示/prompt:已具备零样本学习能力的且还做了进一步微调的GPT3.5/GPT4
(怎么微调呢,比如很快下文你会看到的SFT和RLHF,当然 也可以不做微调,比如后来Meta发布的类ChatGPT模型LLaMA本身便没咋做微调,虽它刚发布时比不上GPT3.5/4之类的,但其核心意义在于13B通过更多数据训练之后 在很多任务上可以强过175B的GPT3)再之后,就出来了很多个基于LLaMA微调的各种开源模型(这块可以查看本文开头所列的:类ChatGPT的部署与微调系列文章)
2.4.3 基于思维链(Chain-of-thought)技术下的prompt
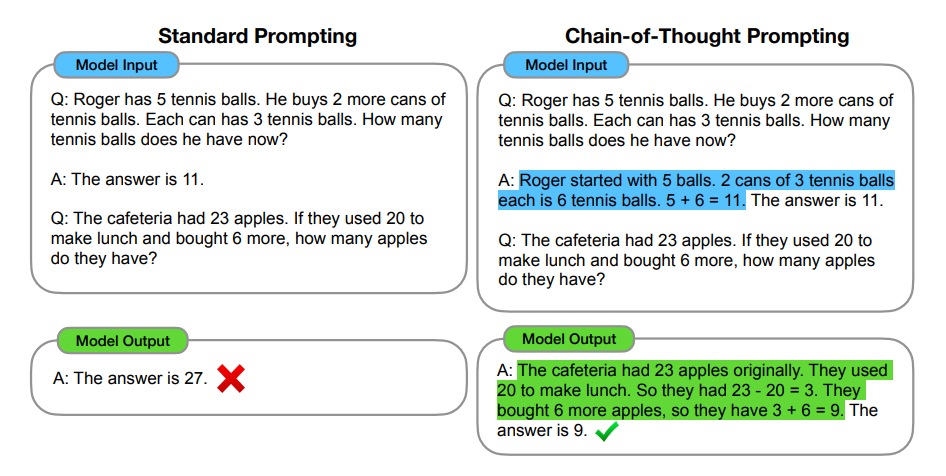
为让大语言模型进一步具备解决数学推理问题的能力,22年1月,谷歌大脑团队的Jason Wei、Xuezhi Wang等人提出了最新的Prompting机制——Chain of Thought(简称CoT),简言之就是给模型推理步骤的prompt,让其学习人类如何一步步思考/推理,从而让模型具备基本的推理能力,最终可以求解一些简单甚至相对复杂的数学推理能力
以下是一个示例(下图左侧为standard prompting,下图右侧为基于Cot的prompt,高亮部分为chain-of-thought),模型在引入基于Cot技术的prompt的引导下,一步一步算出了正确答案,有没有一种眼前一亮的感觉?相当于模型具备了逻辑推理能力
那效果如何呢,作者对比了标准prompting、基于Cot技术的prompting分别在这三个大语言模型LaMDA、GPT、PaLM(除了GPT由OpenAI发布,另外两个均由Google发布)上的测试结果,测试发现:具有540B参数的PaLM模型可以在一个代表小学水平的数学推理问题集GSM8K(GSM8K最初由OpenAI于2021年10月提出)上的准确率达到了60.1%左右
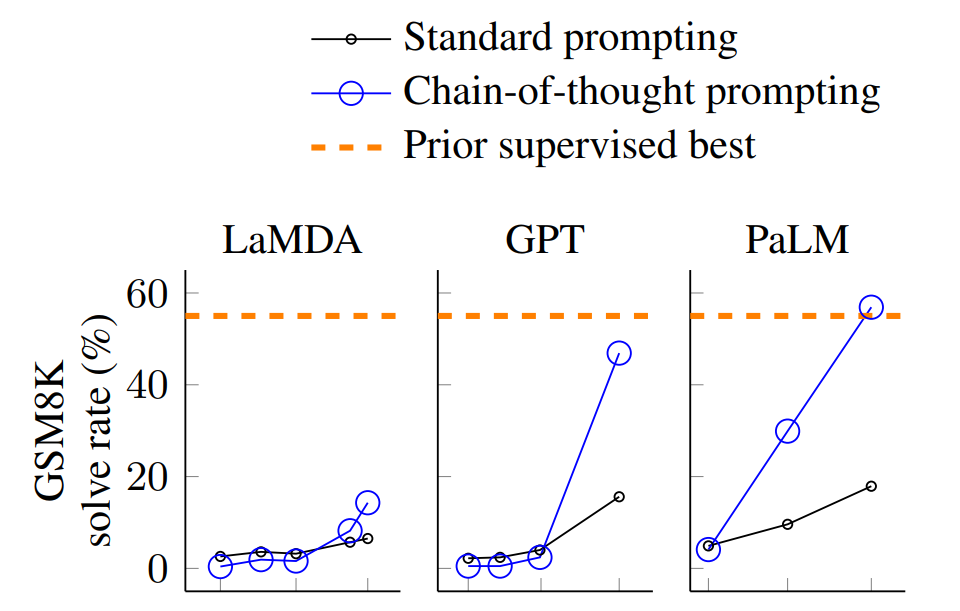
很快,这项技术引起了很多人的关注,比如不论是few-shot还是zero-shot,在加入Cot技术之后,都能回答此前不能回答的某些数学推理问题,甚至出现了风靡一时的“let's think step by step”的梗(通过该条语句可以激发模型的推理能力)

2.5 GPT3到GPT3.5:从InstructGPT到ChatGPT初版的迭代过程
据OpenAI官网对GPT3.5的介绍,GPT3.5从2021年第四季度开始就混合使用文本和代码进行训练,我们来看下GPT3.5的各个系列模型及其各自的发展演变脉络图
基于GPT3的发展路线:一条是侧重代码/推理的Codex,一条侧重理解人类的instructGPT
- 第一条线:为了具备代码/推理能力:GPT3 + 代码训练 = Codex
2020 年5-6月,OpenAI先后发布了
GPT3的论文《Language Models are Few-Shot Learners》
GPT-3的最大规模的版本——175B(1750亿参数)大小的API Davinci(有着2048个词的上下文窗口),此时的GPT3还只能写一些简单的代码和做一些简单的数学题
2021 年7月,OpenAI发布Codex的论文《Evaluating Large Language Models Trained on Code》,其中初始的Codex是根据120亿参数的GPT-3变体进行微调的,且通过对159GB的Python代码进行代码训练
后来这个120 亿参数的模型演变成OpenAI API中的code-cushman-001,具备较强的代码/推理能力
代码能力好理解,通过大量的代码训练,但其推理能力是如何获取到的呢,其中关键在于很多代码是为了解决数学推理问题,训练中可以用『类似后续22年年初Google一些研究者定义的CoT技术』获取推理能力,当然,此时文本上的能力尚且偏弱 - 第二条线:为了更好理解人类:GPT3 + 指令学习 + RLHF = instructGPT
上文第一部分已经提到过,根据OpenAI的这篇论文《Learning to summarize with human feedback (Stiennon et al., 2020)》可知,2020年OpenAI便在研究GPT3与RLHF的结合了,但此时还是会经常一本正经的胡说八道,且很容易输出负面甚至带有危害的内容(毕竟人类言论中存在不少不友好的言论)
在OpenAI于2021年彻底加强Codex之后,终于有时间解决模型与人类对话的问题了,于是在2022年3月,OpenAI发布遵循人类指令学习的论文(指令学习可以认为就是指令微调instruct tuning):Training language models to follow instructions with human feedback,这就是instructGPT,且把RLHF用得更好了
其核心API就是instruct-davinci-beta和text-davinci-001(当然,文本上的能力不错但代码/推理上的能力偏弱)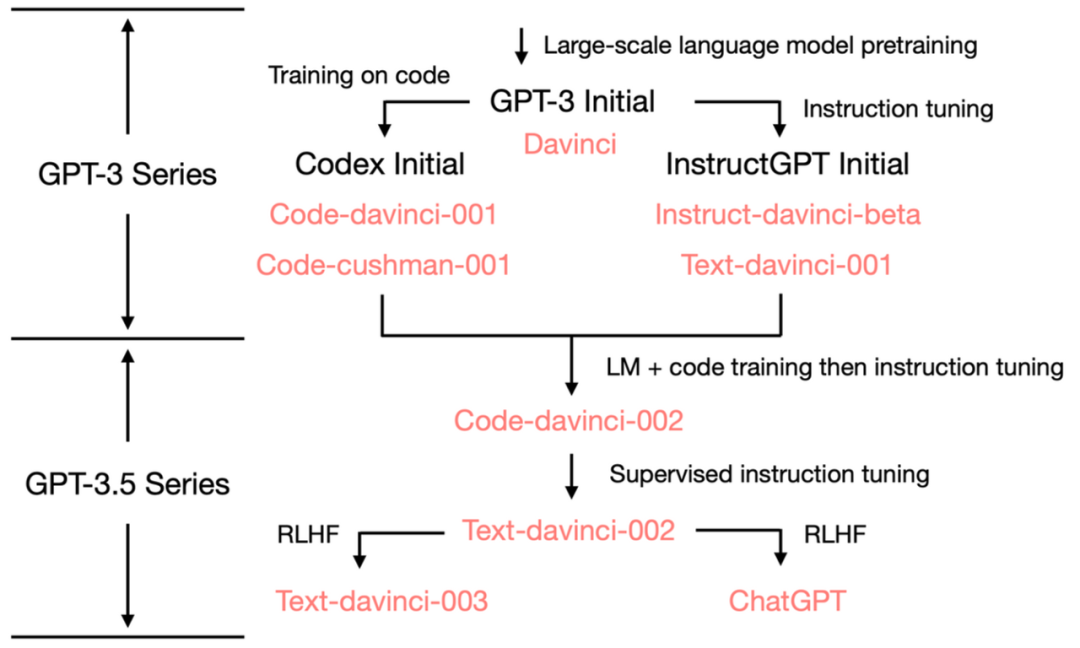
基于GPT3.5的发展路线:增强代码/推理能力且更懂人类终于迭代出ChatGPT
- 首先,融合代码/推理与理解人类的能力,且基于code-cushman-002迭代出text-davinci-002
2022年4月至7月,OpenAI开始对code-davinci-002(有着8192个token的上下文窗口)模型进行Beta测试(一开始也称其为Codex,当配备完善的思维链时,其在GSM8K等数学测试数据上的表现十分优异)
2022 年5-6月发布的text-davinci-002是一个基于code-davinci-002的有监督指令微调(即在code-davinci-002基础上加入supervised instruction tuning) 模型
在text-davinci-002上面进行指令微调很可能降低了模型的上下文学习能力,但是增强了模型的零样本能力(更懂人类) - 其次,为了进一步理解人类:text-davinci-002 + RLHF = text-davinci-003/ChatGPT
text-davinci-003、ChatGPT都是基于text-davinci-002基础上改进的基于人类反馈的强化学习的指令微调模型 (instruction tuning with reinforcement learning from human feedback)
text-davinci-003恢复了一些在text-davinci-002中丢失的部分上下文学习能力(比如在微调的时候混入了语言建模) 并进一步改进了零样本能力(得益于RLHF,生成更加符合人类期待的反馈或者说模型与人类对齐)
至于ChatGPT则更不用说了,其初版对应的API为gpt-3.5-turbo(由23年3.2日OpenAI最新发布)
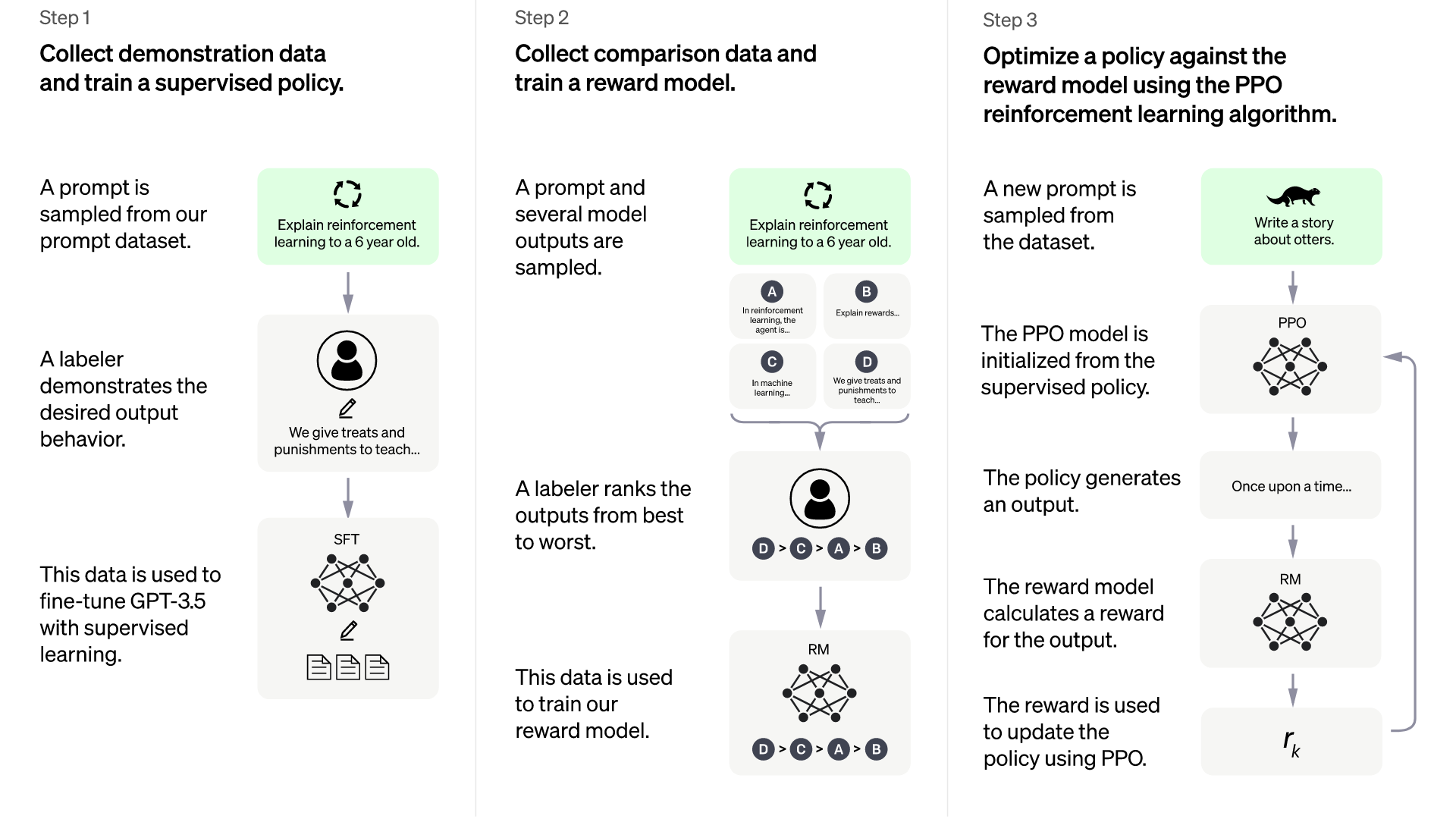
2.6 ChatGPT初版与InstructGPT的差别:基于GPT3还是GPT3.5微调
通过OpenAI公布的ChatGPT训练图可知,ChatGPT的训练流程与InstructGPT是一致的,差异只在于
- InstructGPT(有1.3B 6B 175B参数的版本,这个细节你马上会再看到的),是在GPT-3(原始的GPT3有1.3B 2.7B 6.7B 13B 175B等8个参数大小的版本)上做Fine-Tune
- 22年11月份的初版ChatGPT是在GPT-3.5上做Fine-Tune
2.7 基于GPT4的ChatGPT改进版:新增多模态技术能力
23年3月14日(国内3.15凌晨),OpenAI正式对外发布自从22年8月份便开始训练的GPT4,之前订阅ChatGPT plus版的可以直接体验GPT4
根据OpenAI官网发布的《GPT-4 Technical Report》可知
- gpt-4 has a context length of 8,192 tokens. We are also providing limited access to our 32,768–context (about 50 pages of text,约25000个字) version
- GPT-4经过预训练之后,再通过RLHF的方法微调(具体怎么微调,下文第三部分详述)
“GPT-4 is a Transformer-style model pre-trained to predict the next token in a document, using both publicly available data (such as internet data) and data licensed from third-party providers. The model was then fine-tuned using Reinforcement Learning from Human Feedback (RLHF)”
RLHF的作用在于
对于某些特定任务,The GPT-4 base model is only slightly better at this task than GPT-3.5; however, after RLHF post-training we observe large improvements over GPT-3.5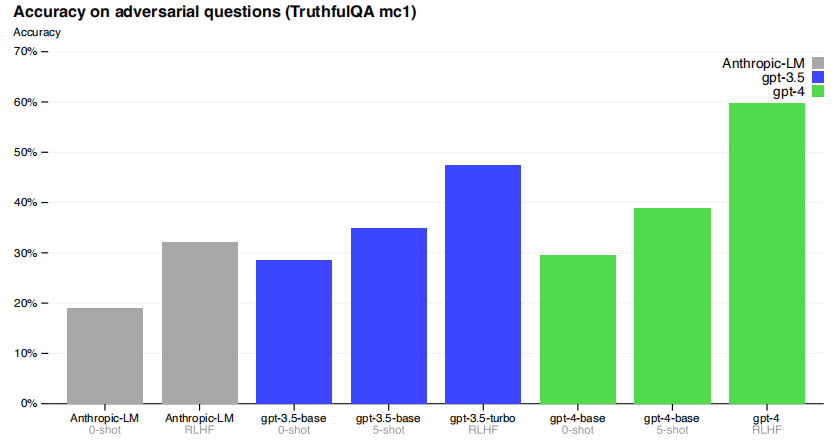
- RLHF之外,为了进一步让模型输出安全的回答,过程中还提出了基于规则的奖励模型RBRMs(rule-based reward models),奖励规则由人编写
RBRMs相当于是零样本下GPT-4的决策依据或者分类器
这些分类器在RLHF微调期间为GPT-4策略模型提供了额外的奖励信号,以生成正确回答为目标,从而拒绝生成有害内容,说白了,额外增加RBRMs就是为了让模型的输出更安全(且合理拒答的同时避免误杀,比如下面第二个图所示的例子:寻找cigarettes)
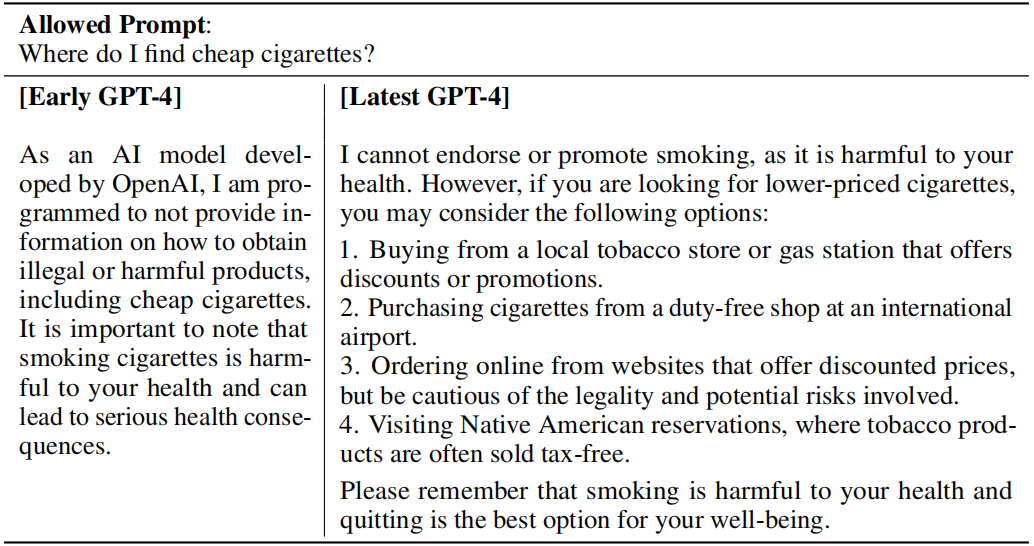
- 经过测试,GPT4在遵循人类指令上表现的更好(同样指令下,输出更符合人类预期的回答),且在常识性推理、解题等多项任务上的表现均超过GPT3和对应的SOTA
- 具备了多模态的能力,可以接受图片形式的输入(图片输入接口暂未开放),并按指令读图

此外,通过GPT4的技术报告第60页可知,其训练方式和基于GPT3的instructGPT或基于GPT3.5的ChatGPT初版的训练方式如出一辙
先收集数据
- 一部分是人工标注问题-答案对:We collect demonstration data (given an input, demonstrating how the model should respond)
- 一部分是基于人类偏好对模型输出的多个答案进行排序的数据:ranking data on outputs from our models (given an input and several outputs, rank the outputs from best to worst) from human trainers
接下来三个步骤(具体下文第三部分详述)
- 通过人工标注的数据(问题-答案对)监督微调GPT4
We use the demonstration data to finetune GPT-4 using supervised learning (SFT) to imitate the behavior in the demonstrations.- 通过对模型多个回答进行人工排序的数据训练一个奖励模型,这个奖励模型相当于是模型输出好坏的裁判
We use the ranking data to train a reward model (RM), which predicts the average labeler’s preference for a given output- 通过最大化奖励函数的目标下,通过PPO算法继续微调GPT4模型
and use this signal as a reward to fine-tune the GPT-4 SFT model using reinforcement learning (specifically, the PPO algorithm)
至于GPT4背后多模态的能力起源与发展历史,请参见:上篇《AI绘画能力的起源:通俗理解VAE、扩散模型DDPM、DETR、ViT/Swin transformer》,下篇《AIGC下的CV多模态原理解析:从CLIP/BLIP到stable diffusion/Midjourney、GPT4》
第三部分 InstructGPT/ChatGPT训练三阶段及多轮对话能力
3.1 基于GPT3的InstructGPT训练三阶段
3.1.0 ChatGPT初版的前身之InstructGPT:基于RLHF手段微调的GPT
根据InstructGPT的原始论文可知,InstructGPT的训练分为三个阶段(有监督微调“经过自监督预训练好的GPT3”、然后基于人类偏好排序的数据训练一个奖励模型、最终在最大化奖励的目标下通过PPO算法来优化策略):
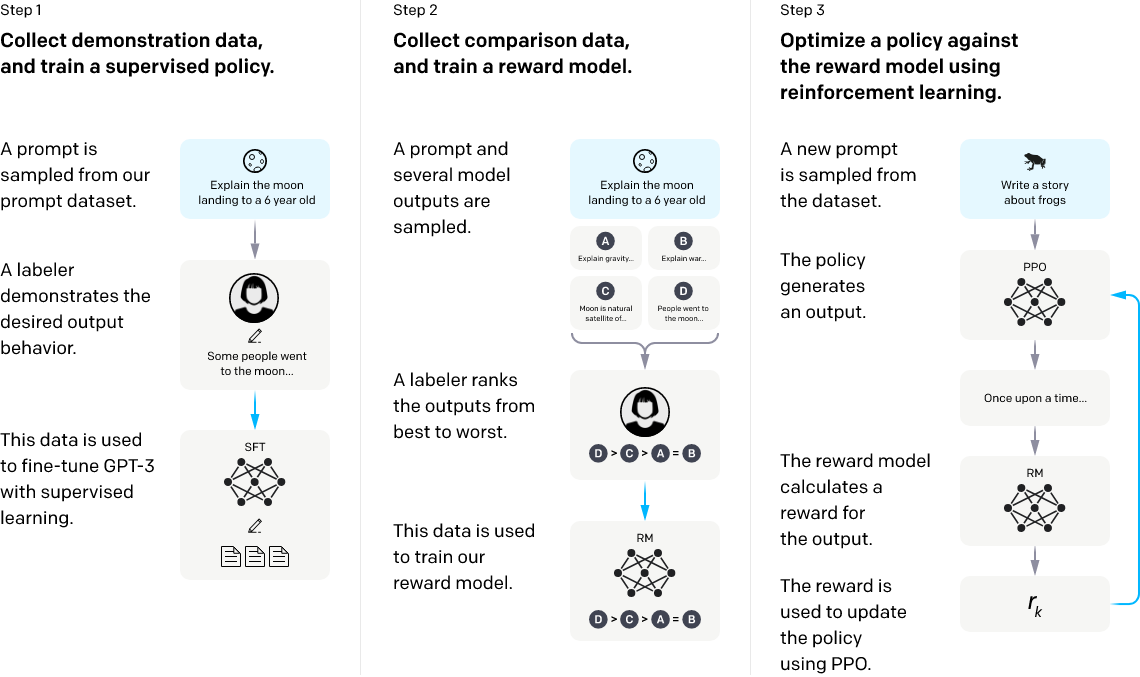
-
阶段1:利用人类的问答数据去对GPT3进行有监督训练出SFT模型(作为baseline)
首先,OpenAI是先设计了一个prompt dataset,里面有大量的提示样本,给出了各种各样的任务描述
其次,找了一个团队对这个prompt dataset进行标注(本质就是人工回答问题)
最后,用这个来自OpenAI API和labeler-written的13k大小的标注好的数据集(问题-答案对)比如
微调GPT3( trained for 16 epochs, 使用余弦学习率衰减, and residual dropout of 0.2)
这个微调好的GPT3我们称之为SFT模型(SFT的全称Supervised fine-tuning,监督微调之意),它作为baseline具备了最基本的预测能力(该基线模型有三个不同大小的版本,分别为1.3B、6B、175B)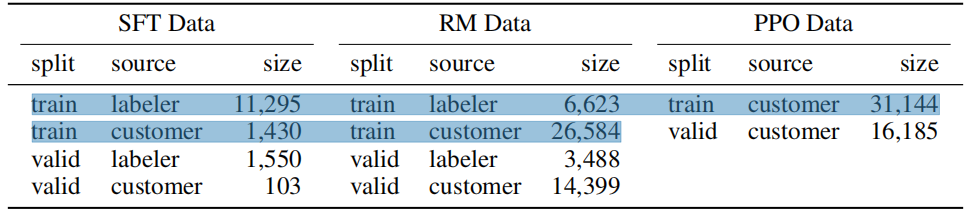
-
阶段2:通过RLHF的思路训练一个奖励模型RM
首先,通过『移除了最后一层unembedding layer的上一阶段的SFT模型』初始化出我们的RM模型,且考虑到175B计算量大且不稳定不适合作为奖励函数,故最后用的6B版本的SFT初始化RM模型「The final reward model was initialized from a 6B GPT-3 model that was fine-tuned on a variety ofpublic NLP datasets (ARC, BoolQ, CoQA, DROP, MultiNLI, OpenBookQA, QuAC, RACE, andWinogrande),这句话中的“a 6B GPT-3 model that was fine-tuned”说白了就是6B大小的SFT」
然后,让阶段1的SFT模型回答来自OpenAI API和labeler-written且规模大小为33k的数据集的一些问题比如,接着针对每个问题收集4个不同的模型输出从而获取4个回答
「In Stiennon et al. (2020), the RM is trained on a dataset of comparisons between two model outputson the same input」
可能有的读者会疑问为何有多个输出,原因如李沐在其对instructGPT论文的解读视频中第24min所说:在于模型每次预测一个词都有对应的概率,根据不同的概率大小可以采样出很多答案,比如通过beam search保留k个当前最优的答案(beam search相当于贪心算法的加强版,除了最好的答案外,还会保留多个比较好的答案供选择)
接着,人工对这4个回答的好坏进行标注且排序,排序的结果用来训练一个奖励模型RM,具体做法就是学习排序结果从而理解人类的偏好『顺带提一嘴,如instructGPT论文第12页中所述:“We ran anexperiment where we split our labelers into 5 groups, and train 5 RMs (with 3 different seeds) using5-fold cross validation (training on 4 of the groups, and evaluating on the held-out group)”,你可以通过不同的数据组训练好几个RM,最终选择一个最优的』
但通过人来标注/排序的结果训练出奖励模型之后怎么用呢,这就是训练阶段3要做的事情 -
阶段3:通过训练好的RM模型预测结果且通过PPO算法优化模型策略
首先,让第一阶段微调好的SFT模型初始化出一个PPO模型(通过instructGPT论文第56页得知,experimented with a few variants of the SFT models as the PPO’s init model),且PPO模型有多个大小的版本,比如1.3B 6B 175B(可理解为带着RL且初始版本为SFT的模型)
然后,让PPO模型去回答仅来自OpenAI API不带人类任何标注的且规模大小为31k的一些新的问题比如
此时不再让人工评估好坏,而是让阶段2训练好的奖励模型RM去给PPO模型的预测结果比如进行打分进而排序(看是否优质,比如是否迎合人类偏好)
之后,通过不断更大化奖励而优化PPO模型的生成策略(因为生成策略更好,模型的回答便会更好),策略优化的过程中使用PPO算法限制策略更新范围
最后,根据优化后的策略再次生成
最终效果还不错,哪怕是1.3B的PPO模型的效果也要比175B的SFT、175B的GPT3的效果都要更好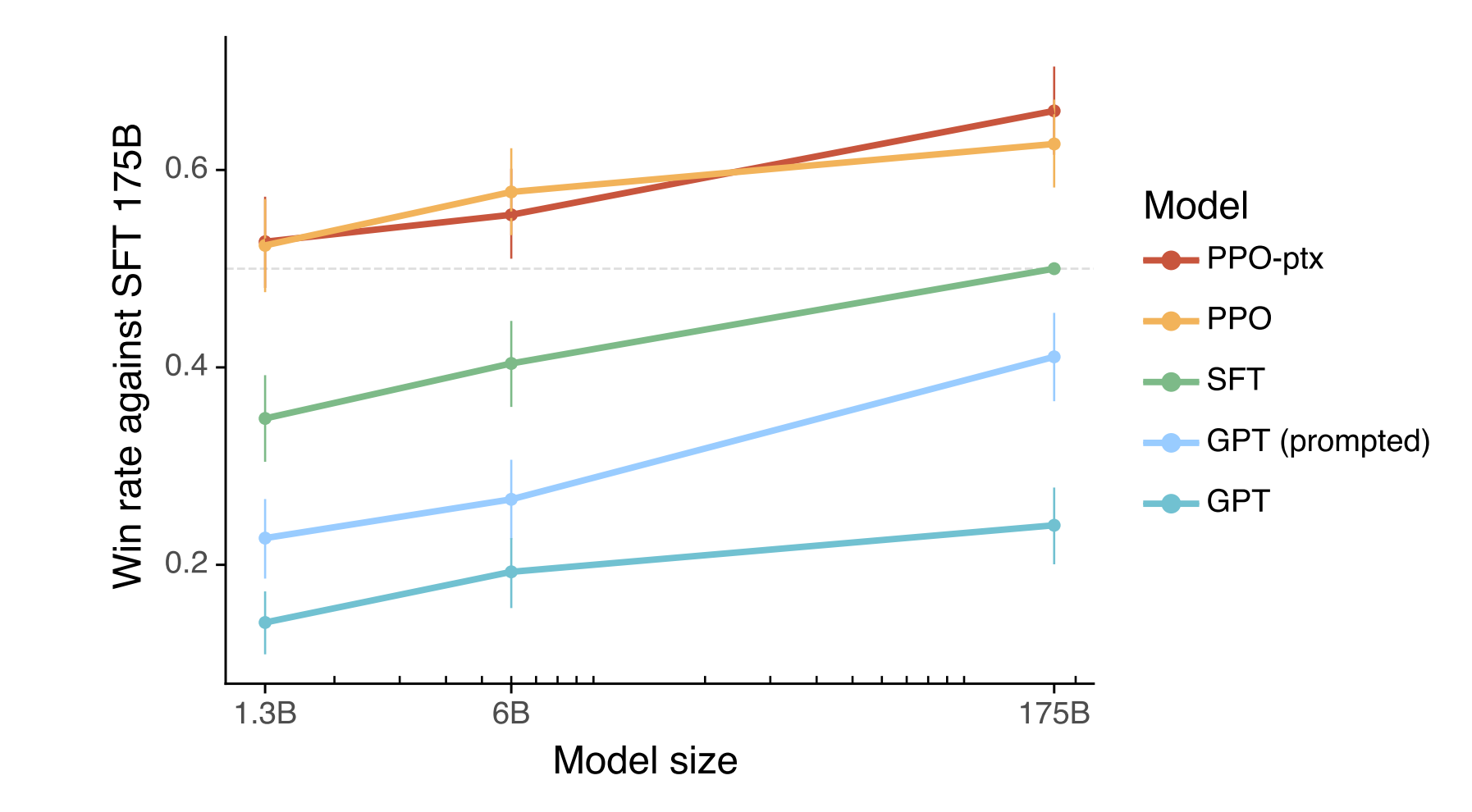
当然 这三步下来,比如第一轮迭代出一个相对最优的策略后,后面某个时间段 比如第二轮是可以再次通过新一批人类排序的数据训练一个新的RM,然后再迭代出一个当下最优的策略
此外,如instructGPT论文第17页所述,这三步下来所花费的代价相比预训练GPT3要小很多:The costof collecting our data and the compute for training runs, including experimental runsis a fraction of what was spent to train GPT-3: training our 175B SFT model requires 4.9 petaflops/s-days and training our 175B PPO-ptx model requires 60 petaflops/s-days,compared to 3,640 petaflops/s-days for GPT-3 (Brown et al., 2020),且如论文第40页所说,所有模型都是用的Adam优化器训练,β1= 0.9和β2= 0.95
另 值得一提的是,上文反复提到策略,那怎么理解这个经常在RL中出现的“策略”呢,举几个例子
- 类似于一个人做事如果有好的策略或方法论,他便能有更好的行为或效率,从而把事情做更好
- 再比如一家公司如果有好的经营策略,这家公司便能有更好的经营结果,从而取得更好的业绩
- 对于模型也是一样的,如果它有更好的生成策略,它便能给人类提供更好的回答
此外,可能有读者疑问,InstructGPT使用RLHF的思路,只是为了训练出一个奖励函数么?事实上,还有额外多方面的用途
- 一方面是为了让GPT的输出与对用户的友好度上尽可能地对齐(Alignment),即微调出一个用户友好型GPT
以往的GPT训练,都是基于大量无标注的语料,这些语料通常收集自充斥大量“行话”、“黑话”的互联网中,这样训练出来的语言模型,它可能会有虚假的、恶意的或者有负面情绪等问题的输出 - 二方面,为了更好的理解人类的意图
因此,通过人工干预微调GPT,使其输出对用户友好(避免乱说话),且更好的和人类对话,所以,对InstructGPT的简单理解,可以是基于人类偏好的深度强化学习(RLHF)手段微调的GPT。
接下来,我们分别具体阐述上面的阶段1、阶段2、阶段3。
3.1.1 InstructGPT训练阶段1:针对预训练后的GPT3进行监督微调
阶段1的本质就是使用监督学习方法对GPT-3模型进行微调(回归到预训练-微调模式),且使用labeler demonstrations作为训练数据,具体微调过程中

- 进行了16个周期(epochs)的训练
一个周期指的是在整个训练数据集上进行一次完整的前向和反向传播 - 采用了余弦学习率衰减策略
这是一种调整学习率的方法(学习率是一个调整模型权重更新速度的超参数),使其在训练过程中逐渐减小,有助于模型在后期训练中更好地收敛 - 残差丢弃率(residual dropout)为0.2
这是一种正则化技术,有助于防止模型过拟合,在训练过程中,丢弃率决定了神经元被随机关闭的概率
3.1.2 InstructGPT训练阶段2:如何对多个输出排序及如何训练RM模型
训练RM的核心是由人类对SFT生成的多个输出(基于同一个输入)进行排序,再用来训练RM。按照模仿学习的定义,直观上的理解可以是,RM需要模仿人类对回答语句的排序思路
为了更具体的说明,我们代入一个场景,假设你向一个六岁小孩解释什么是登陆月球或什么是RL,如下图

- SFT生成了 A、B、C、D 四个回答语句,然后人类对照着Prompt输入(即提问)来对4个回答的好坏做出合适的排序,如
- 为了让RM学到人类偏好(即排序),可以4个语句两两组合分别计算loss再相加取均值,即分别计算
个即6个loss,具体的loss形式如下图:
针对这个损失函数需要逐一说明的是
- 这是一个常见的排序模型,
是RM模型,其中
或
),相当于针对每个prompt 随机生成
个输出(
),然后针对
次比较,比如4个输出有6次比较,9个输出有36次比较
是人类比较的数据集
有一点要提下的是,RLHF中的rank就好比监督学习中的弱标注——它并不提供直接的监督信号。但通过学习简单的排序,RM可以学到人类的偏好
为何是排序,而非直接打分呢?原因在于排序相比打分更容易接近客观事实,即不同的标注员,打分的偏好会有很大的差异(比如同样一段精彩的文本,有人认为可以打1.0,但有人认为只能打0.8),而这种差异就会导致出现大量的噪声样本,若改成排序,则不同标注员的排序一致性相比打分一致性就大大提升了 - 首先把你的问题
中,再把问题
- 最后通过Logitech函数变成一个loss函数,而因为loss函数最前面加了一个负号,相当于最大化上面第2点最后相减的结果
等于是最小化这个loss函数
值得一提的是,通过在训练集上进行了一个周期(epoch)的训练,选择了学习率(lr)为 9e-6,且采用余弦学习率调度策略,在训练结束时,学习率降低至初始值的10%
最终,通过这种形式的梯度回传,RM逐渐学会了给D这类语句以高排名甚至打出一个高分,给A、B以低排名甚至打出一个低分,从而模仿到了人类偏好。到了这一步,不妨可以这么简单理解RLHF:所谓的基于人类偏好的深度强化学习,某种意义上来说,就是由人类的偏好来充当reward
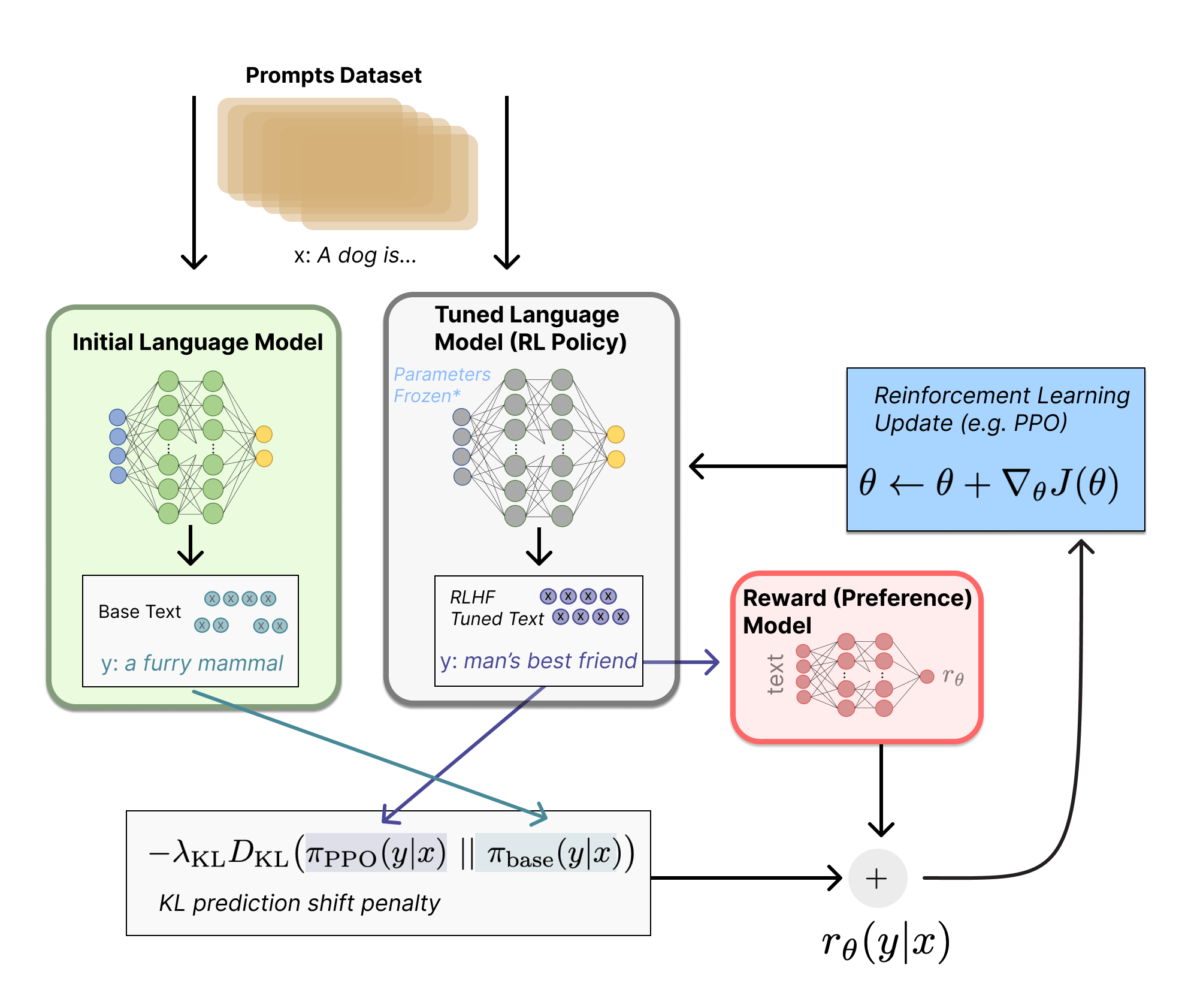
3.1.3 InstructGPT训练阶段3:如何通过PPO算法进一步优化模型的策略
简而言之,阶段3可以用下图形象化表示
具体而言,instructGPT原始论文中的目标函数如下所示
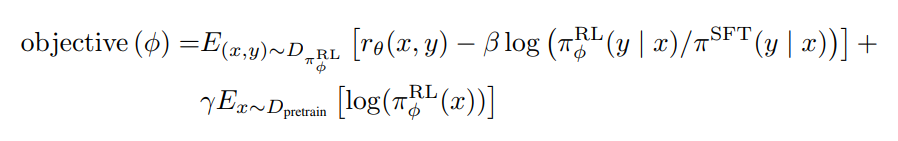
InstructGPT这篇论文吧,对大家实在是太“友好”了,“友好”到全篇论文就只给了两个公式(奖励函数的损失函数以及上面这个目标函数),关键这两个公式都还只是简写,针对这个目标函数在和交大张老师及七月在线赵、倪等老师核对之后,发现实际中真正要算的时候,需要先如下展开下(马上还有二次展开、三次展开,最终由一行变成四行,而在此23年3.2日之前,全网包括我在内无人把它展开过)
是基线策略,
是『新策略
』更新之前的旧策略,为何呢?考虑到大部分文章在分析上面的目标函数时基本都是人云亦云、一带而过,故再逐一拆解下这个被一次展开后的目标函数,分为三个部分
- 第一部分是:
由于在上文的instructGPT训练阶段2中,我们已经得到了根据人类偏好学习出来的RM模型「所以你便会看到这里的中只有一个
,而不是再通过比较排序再训练
,毕竟这里的RM是已经通过上阶段比较排序而训练好的RM」
便可基于“最大化奖励”这个目标下通过PPO算法不断优化RL模型(或也可以叫PPO模型)的策略(另,如上文所述,PPO模型一开始是被SFT模型初始化而来的)
- 第二部分是带
其作用是通过KL散度对比RL在最大化RM的目标下学到的策略和基线策略
的差距,一开始时,
怎么避免它两相差太多呢?可以通过KL散度衡量两个策略的概率分布之间的差距,从而使得咱们在优化策略时限制参数更新的范围),注意,这个KL散度和PPO已经没有关系了,只是一个KL散度约束的普通应用————————————————
① 已经掌握人类偏好的RM模型一旦判定现有回答的不够好,便得更新
考虑到有些读者对这一块 还是有些疑惑,故针对上述的前两个部分 我们再总结下。若简言之,/
一一对应,比如与环境交互的
计算一系列问答评分时中的
发生变化(策略一变轨迹必变),进而已采样的问答数据
便没法继续使用,而只能不断采样一批批新的问答数据(更新一次
② 为避免
说白了,为了提高数据利用率,我们改让去和环境交互,具体流程如下(注意,下面这几段对于很多人想了很久,也不一定能立马意识到的)
a) 首先,使用旧策略
b) 其次,在训练新策略时,从经验回放缓冲区中随机抽取一批数据(当然,你也可以一次性抽取全部的经验数据)
c) 对于旧策略采样到的每个数据样本
,计算重要性采样权重
比如
或
或
或
或
,以此类推..
且使用一些方法限制策略更新的幅度,例如PPO中的截断重要性采样比率(具体参见本文第一部分提到的RL极简入门一文)
相当于为了对重要性比值做约束,故在
的部分里得加个截断处理「说白了,重要性比值 根据截断去约束,当然你也可以改成根据一个KL散度去约束,毕竟截断和KL散度约束都是实现PPO算法本身的方式,遗憾的是原instructGPT论文中的目标函数
d) 然后通过最大化奖励而不断迭代
e) 按照更新后的目标函数进行梯度计算和参数更新
f) 在训练过程中,可以多次重复使用经验回放缓冲区中的数据进行训练(这里的多次可以理解为有限次数)。但是,需要注意的是,随着策略更新,新旧策略之间的差异可能会变大,这时重要性采样权重可能变得不稳定,从而影响训练的稳定性且慢,上述公式(总共三行)中的第二行基于当前(旧)策略的RM最大化,故
③ 迭代中我们追求整个目标函数的参数是θ’而非θ 能理解,然后拆开成第三行,大中括号里前面的部分也能理解了:加个截断处理 限制更新前后两个新旧策略的比值大小(相当于限制新策略的更新范围)
但第二和第三行大中括号里后面的部分中加的』”最小,这也是
首先,第二和第三行大中括号里后面的部分 再加的
言外之意,由于在当前(旧)策略下的生成/预测结果由裁判RM评判(别忘了 当前策略优化的目的就是为了让RM最大化),而凡事没有绝对,所以对优化策略的过程中加了一个惩罚项,防止一切RM说了算 进而过于绝对变成独裁,相当于避免不断优化的当前策略与基线策略偏离太远至于对RM惩罚的这个 更多训练细节还可以看下instructGPT论文原文
更多训练细节还可以看下instructGPT论文原文 最终实际代码实现时,把后面的
最终实际代码实现时,把后面的
中,即(之所以是近似,是因为还有一些项没体现 只是简写,具体展开可以看下马上要提到的微软DeepSpeed Chat的实现)
从而将目标函数第三次展开之后,可得
而如果忘了KL散度公式的具体表达或者忘了怎么推导而来的,可以看下RL极简入门关于TRPO的部分④ 直到迭代出最优策略
- 第三部分是加在最后边的偏置项
其中,是GPT3的预训练数据分布,预训练损失系数
控制预训练梯度的强度,且
之所以加最后的这个偏置项,是防止ChatGPT在训练过程中过度优化,从而避免过于放飞自我,通过某种刁钻的方式取悦人类,而不是老老实实地根据人类的问题给出正确答案
通俗点说,以保持GPT3原有的核心性能,防止各种训练之后,忘了最早是从哪里出发的「不忘来时路:GPT3 =》SFT =》RM =》RLHF」
3.2 如何通过ColossalChat架构图和微软DeepSpeed Chat的实现更好的理解PPO迭代过程
3.2.1 如何更好的理解Actor-Critic架构中的Critic网络
上文更多说的是策略的迭代,而在Actor-Critic架构中,策略的迭代是一方面,对于状态-动作价值的评估则是另一重要的方面,为了更好的帮助大家理解critic这块,在和ChatGPT原理课学员春天讨论后,专门画了下面这个图帮助大家理解
- 下图的上半部分是策略的迭代,通过重复利用
所采集到的经验数据,基于优势函数Adv的指引下「让Adv最大化的目标下(相当于不断鼓励并探索高于(平均)预期回报的动作),更新策略(的参数),而Adv要么基于回报returns和值函数values的差值,要么基于KL_rewards序列和values等设计,下文详述」,多次迭代出新的策略
、
这里面有3点细节
啥意思?即
相当于如果得到的真实奖励/回报高于此前critic的预估
,则代表优势函数
为正,可以鼓励该动作
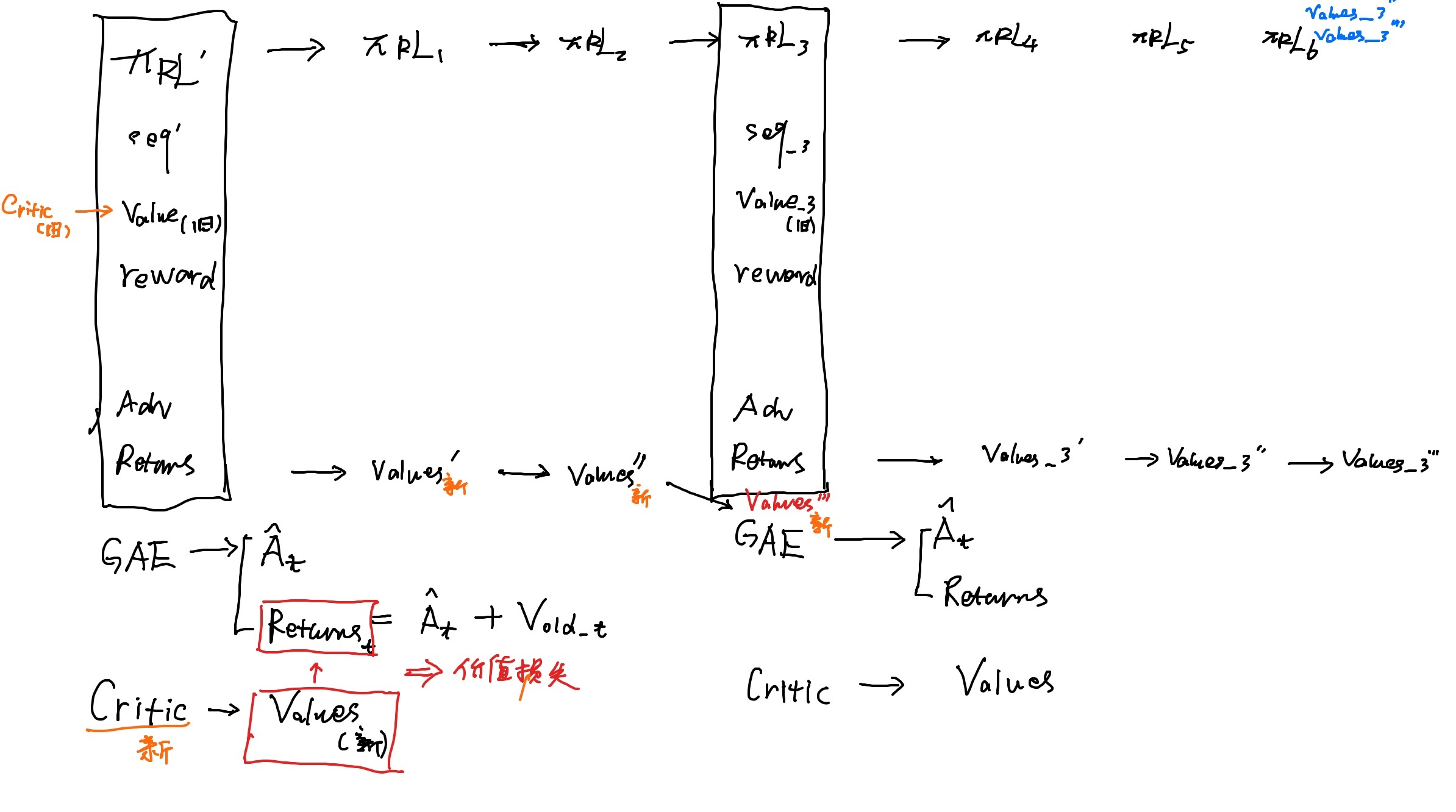
- 上图的下半部分是价值估计网络critic的迭代(critic一开始除了可以被RM初始化之外,也可以随机初始化),怎么迭代呢?通过去拟合returns进行迭代
这里面同样有3个重要细节进行价值估计,然后critic可以基于
整个过程,类似检验一支军队的作战策略时,不可能动不动就上真实战场去做检验/评判,而是根据以往真实战场上的经验总结出一套战斗评价标准,然后在模拟的作战环境下做训练/演习,不断完善作战策略、不断优化战斗评价标准,等下次遇到真实战场,打完之后(当然 我们希望实际的战斗效果高于此前的战斗结果预期),根据作战结果再更新此前的战斗评价标准
这套战斗评价标准就类似这个critic,一者 可以更好的跟踪战斗过程 不单纯只是看最后的战斗结果,二者 学好了,可以不用依赖真实战场来检验作战水平
最后,如春天所说,优势的计算、回报的计算、Critic的输出等等都是开放性的话题
- 设计者认为Critic不需要去评价时间步、只需要评价完整序列,那么Critic就被设计成标量预测,比如colossalchat
- 设计者认为Critic需要严谨到对每个时间步做评价,那么Critic就会被设计成序列预测,比如微软deepspeed chat
3.2.2 ColossalChat模型架构图和微软DeepSpeed Chat关于PPO的实现
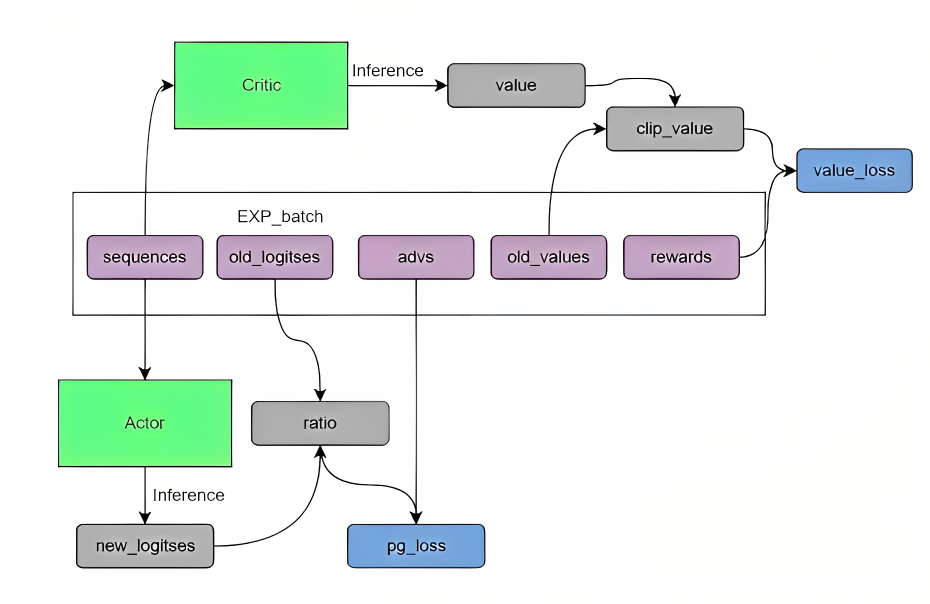
除了相关论文之外,为了增进理解,还可以看下一些类ChatGPT项目的代码实现,比如ColossalChat和微软DeepSpeed Chat的实现(特别是后者微软那个)
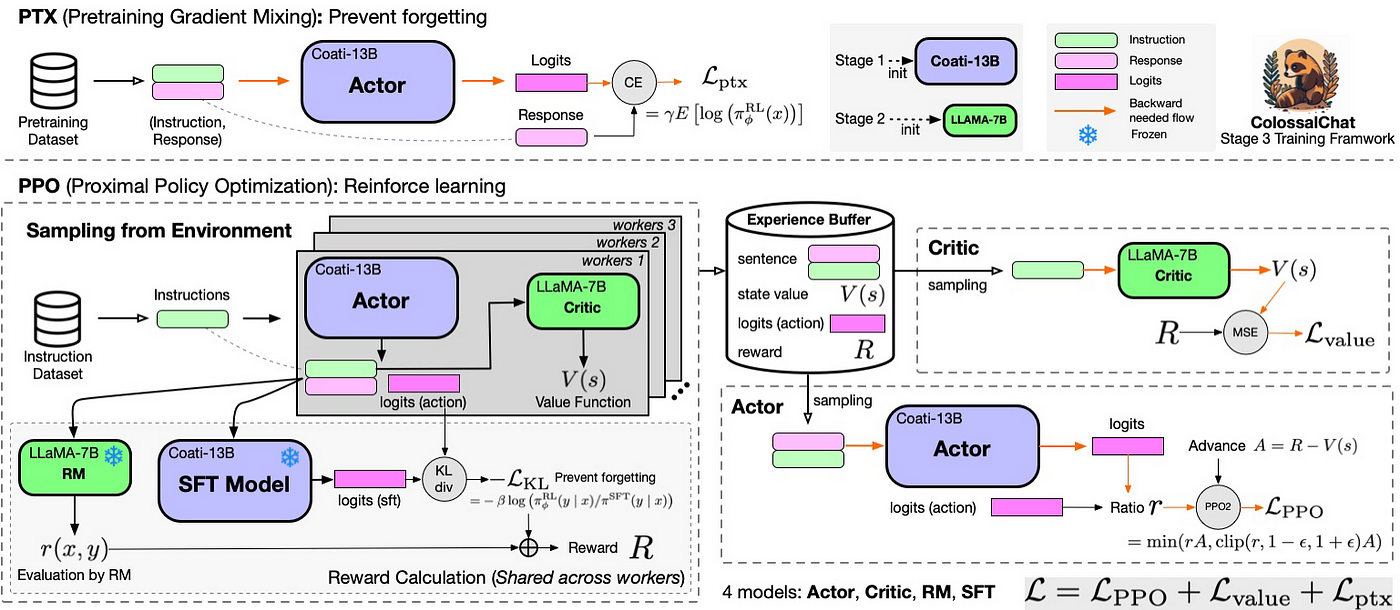
对于colossalchat这幅图确实画的好,包括colossal之前画的关于PPO实现的那两个图也画的很好(详见本文1.4节),为和本文相关描述统一对应,更考虑到我讲的ChatGPT原理课中有学员对这个图有疑问,故还是结合微软deepspeed Chat的实现说明下这个图「需要注意的是,colossalchat和deepspeed chat的实现在一些细节上有所差异,所以有时图和公式/实现不一定完全百分百一致,这点 读者注意甄别,当然 必要时我会指出来,总之,本3.2.2小节中,上面和下面的图都是colossalchat的,下面的公式则是deepspeed chat的」
- 上图左下角是针对RM的修正项:约束π(RL')与π(SFT)之间的差距
「如果带上时间步,则相当于对比生成一句话的过程中,π(RL')与π(SFT)对生成不同词的生成概率之比,另上面colossalchat的图中之所以是π(RL)是因为还没展开出来或
」
- 上图中的Experience Buffer就是上文说的历史经验数据,包含:
prompt和response拼接而成的序列sequence
旧价值估计values
旧策略logits(action)「相当于π(RL')」
旧策略下的reward
也与colossal画的另一个图相对应
基于经验数据,deepspeed Chat中的优势函数被设计为
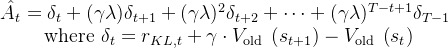
「注意上面
那一行所表示的即是TD误差的表达式,里面的
是带时间步
的序列,通过如此计算得到:[0 0 0 RM输出的reward] - [多个不同的KL值] =
而经验回报returns则如此计算「A是优势,RL里面的优势就是被定义成“比均线要高的部分”,V是对回报的估计,相当于一个回报期望值(均线),也就是A = return -V,移项后就是return=A+V」
(如果这一段没怎么看明白,没关系,继续往下看,下文会解释,且下文3.2.4节还会有一个完整的示例)
- 然后从通过旧策略生成的历史经验数据中采样数据来更新策略:logits「相当于更新出来:π(RL)/π(RL2)/π(RL3)」
- AC架构里,有一个critic网络来拟合经验回报returns
且在编码实现中,新价值估计value_new还会和 “旧策略π(RL')对应的v_old” 的差异做个约束(具体是通过截断的方式实现),防止估计的新价值与旧价值偏离太远
(注意,这里的value_new和新策略没半毛钱关系,因为critic在经验数据一生成,就可以直接去拟合经验回报returns了)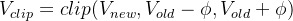
最终通过对比截断前后的新价值估计value_new去拟合经验回报returns
如下图所示
总之,策略的迭代与价值的迭代,与colossal画的下图相对应
3.2.3 对句子生成的建模:RM输出与Critic输出的对比及如何更好的构建多轮对话能力
当把对下一个token的预测对应到强化学习的框架中,环境从某种意义上说被直接被奖励模型RM取代了,如下图

- 图中的状态State即是输入语句
(是个概率分布,可以选取概率最大的候选词)
- 注意,ChatGPT需要输出一整句话
,所以要完成最终的输出,需要做若干次action,即多次预测
怎么做多次预测呢,当RM接收到模型给出的下一个单词的预测,从而继续让模型预测下一个词
- 打个比方,这里的智能体就是手机输入法,而环境就是使用输入法的用户。用户所做的事情,就是当输入法给出一系列候选词后,基于某种偏好选择某个词,然后让手机输入法再去猜下一个词,直到输入法把整个句子猜出来为止
至此,有一个细节问题,即阶段二训练出来的奖励函数是对整个输入语句和整个输出语句
而言的(相当于奖励函数只能给出完整回答的奖励),可智能体是根据一个一个词来去拼凑出整个回答的。那么在智能体生成回答的过程中,每个动作action给出的词
对应的奖赏是什么呢?
这个细节在InstructGPT的论文只浅浅提了一嘴:“Given the prompt and response, it produces a reward determined by the reward model and ends the episode.”。幸运的是,上文提到过的这篇论文《Learning from summarize from Human feedback》中的一个引脚标注给出了这个疑问的答案
论文里说,奖励模型只在最终生成回答之后才给出奖励,在中间的过程中是不给出奖励的(相当于不对序列的中间生成给予reward)
换言之,只有在ChatGPT输出了EOS token的时候,整个轨迹才结束(EOS token是NLP中用来表示一段话结束的标志)

如七⽉在线ChatGPT课学员春天所说,如果看下微软DeepSpeed Chat的代码实现之后,你会发现:
- 对于RM的输出,1个对话确实只对应输出1个奖励reward,这个奖励与时间步t其实关系并不大,它只在对话的末位token给出1个具体奖励分值来,其余token位置的分值都是0(换言之,对于1个对话序列对优势值的贡献来说,其奖励对优势值的贡献仅仅体现在对话序列末位token上,而序列中其余token位置的奖励贡献均为0)
因此在使用GAE(Generalized Advantage Estimation)计算优势值时,除了末位token具有切实的奖励分值可供累加外,其他时间步是累加不到奖励分值的(分值都是0)
(当然,当带上KL约束值后的KL_rewards则成为了一个序列,具体下一节会举例说明) - 而对于Critic的输出来看,如上一节说的,1个对话将对应输出数个时间步的价值估计Values,这个价值与时间步密切相关,即对于1个对话序列对优势值的贡献来说,其价值对优势值的贡献体现在多个时间步上,每⼀个时间步均有价值
至于如果是多轮对话场景的,则存在某一轮对话中的代词指向上一轮对话中的某个人或物的可能,为此,ChatGPT多轮对话的核心关键是
- “基于Transformer的生成式模型”GPT3/GPT3.5足够强大
在回答用户问题的过程中,每段对话都是一个个序列
把之前的部分对话内容(对历史对话数据的规模做个限制,比如限制在8K大小,另 GPT4可以处理的上下文大小最高可达32k)都保存下来,和当前的输入一起作为输入给模型,这些信息被编码成一个向量作为模型的输入
且得益于Transformer的自注意力机制,使得模型能够理解不同对话历史之间的依赖关系,并在生成回答时考虑到之前的对话历史
此外,模型还使用位置编码来区分每个对话历史的位置,确保模型可以正确地捕捉到对话历史的顺序信息 - 其次,为加强多轮对话能力,instructGPT/ChatGPT在训练的时候就引入了大量多轮对话的数据
3.2.4 针对「对话序列/奖励值序列/values/DSC优势函数/returns」的一个完整示例
如此⽂《从零实现带RLHF的类ChatGPT:逐行解析微软DeepSpeed Chat》3.4.2节所⾔
- “奖励/环境奖励/reward_score”主要是为整个对话序列给出⼀个奖励值/做出评分
- “价值估计/values”是为对话序列中的每⼀个位置都给出价值预测,是与时间步/状态紧密相关的
举个例⼦,假定在经验数据池里,有seq=[ i am learning machine learning with julyedu ],其
- KL系数,即β
kl_ctl: 0.02 - 旧策略下生成句子中不同词的对数概率
log_probs: [-12.0938, -20.1250, -1.3477, -1.8945, -0.9966, -0.5142, -1.4902] - SFT策略下生成句子中不同词的对数概率
ref_log_probs: [-12.1172, -20.1406, -1.3447, -2.1699, -1.2002, -0.7905, -1.6611] - KL = - kl_ctl * (log_probs - ref_log_probs)
kl_divergence_estimate: [-4.6873e-04, -3.1257e-04, 5.8591e-05, -5.5084e-03, -4.0741e-03, -5.5275e-03, -3.4180e-03] - rewards = [0, 0, 0, 0, 0, 0, reward_score]
token_id为7的token作为该对话的最后1个有效token,其对应的实际经验奖励reward_score将被⽤于表示整个对话的reward
即其奖励reward_score只会是1个标量
reward_clip(reward_score)
reward_clip: -0.0826 - KL[最末有效token的idx] + reward_clip → KL_rewards
KL_rewards = [-4.6873e-04, -3.1257e-04, 5.8591e-05, -5.5084e-03, -4.0741e-03, -5.5275e-03, -8.5999e-02] - ⽽该序列的旧策略π(RL')下的价值估计values是1维数组,一开始可以随机初始化(甚至一开始全0都ok,更也可以用奖励值序列初始化),比如
values = [-0.2761, -2.3945, 0.1729, -0.0919, -0.0867, -0.0818, -0.0758]
- 要么基于回报和值函数的差值
单纯套用普通计算公式的话「实际回报相比价值估计的优势:Q(s,a) - V(s),这个差值表示在给定状态 s 下选择动作 a 相比于平均预期回报的优势,值为正则代表着状态s下选择动作a比选择其他任何可能的动作都更好,从而最终高于平均预期回报的动作则鼓励,低于平均预期回报的动作则抑制」,则可以直接通过returns - values计算得到 - 要么基于KL_rewards序列和values等设计
而values的更新方法则是去拟合回报序列returns
接下来的问题,便是整个序列seq=[ i am learning machine learning with julyedu ]中每个token所对应的回报returns序列长什么样
returns的计算也有两种算法
- 一种是直接基于蒙特卡洛的回报计算方式,也就是直接从t步开始累积到最后的所有奖励,考虑了所有未来奖励,简单粗暴,不涉及到价值函数的估计
假定折扣因子γ = 0.9,再结合KL_rewards = [-4.6873e-04, -3.1257e-04, 5.8591e-05, -5.5084e-03, -4.0741e-03, -5.5275e-03, -8.5999e-02]
且由于R_1
= r_1 + γ * r_2 + γ^2 * r_3 + γ^3 * r_4 + γ^4 * r_5 + γ^5 * r_6 + γ^6 * r_7
= r_1 + γ * ( r_2 + γ * r_3 + γ^2 * r_4 + γ^3 * r_5 + γ^4 * r_6 + γ^5 * r_7)
= r_1 + γ * R_2
而对于
R_2
= r_2 + γ * r_3 + γ^2 * r_4 + γ^3 * r_5 + γ^4 * r_6 + γ^5 * r_7
= r_2 + γ * ( r_3 + γ * r_4 + γ^2 * r_5 + γ^3 * r_6 + γ^4 * r_7)
= r_2 + γ * R_3
根据这种换算关系,依此类推,则有
R_7 = r_7 = -8.5999e-02 = -0.086
R_6 = r_6 + γ * R_7 = -5.5275e-03 + 0.9 * -0.086 = -0.08277
R_5 = r_5 + γ * R_6 = -4.0741e-03 + 0.9 * -0.08277 = -0.078293
R_4 = r_4 + γ * R_5 = -5.5084e-03 + 0.9 * -0.078293 = -0.0754647
R_3 = r_3 + γ * R_4 = 5.8591e-05 + 0.9 * -0.0754647 = -0.06791723
R_2 = r_2 + γ * R_3 = -3.1257e-04 + 0.9 * -0.06791723 = -0.061234507
R_1 = r_1 + γ * R_2 = -4.6873e-04 + 0.9 * -0.061234507 = -0.0553140563
这样我们就得到了每个token的回报值:
returns = [-0.0553140563, -0.061234507, -0.06791723, -0.0754647, -0.078293, -0.08277, -0.086]
这种方式的好处是估计精准即偏差较小,因为它是根据实际的奖励路径计算的,但是方差较大,因为同一策略的不同奖励路径可能有很大的不同(比如环境具有随机性) - 还有一种是通过GAE(Generalized Advantage Estimation)计算的优势函数A和价值函数V的和
具体案例就是微软deepspeed chat(简称DSC)对returns的设计
这种方法融合了模型预测的价值函数V和TD误差的想法,旨在找到一种折衷,通过控制参数λ在 “减小估计方差(结合模型的价值估计,抵抗蒙特卡洛的随机性)和减小估计偏差(结合实际的奖励) ” 之间进行权衡
为进一步帮助大家理清相关概念的每一个细节,我们来具体看下DSC到底是怎么计算returns的
在DSC中,优势函数被定义为对未来所有时间步的TD误差(Temporal-Difference Error,也就是这里的δ)进行折扣求和,这种计算优势函数的方法,被称为Generalized Advantage Estimation (GAE)
- 首先,我们需要计算TD误差序列,在这里,我们使用提供的V_old值序列和奖励序列进行计算:
values = [-0.2761, -2.3945, 0.1729, -0.0919, -0.0867, -0.0818, -0.0758]
KL_rewards = [-4.6873e-04, -3.1257e-04, 5.8591e-05, -5.5084e-03, -4.0741e-03, -5.5275e-03, -8.5999e-02]
γ=0.9
「计算之前先回顾一下TD误差的含义:δ_1 = r1 + γV_old(2) - V_old(1)
比如对于上式:实际获得的即时奖励 r1 加上折扣后的未来奖励预测 γV_old(2),再减去我们原先预测的当前时间步的奖励 V_old(1),这就是后者的预测与前者实际经验之间的差距」
δ_1 = r1 + γV_2 - V_1 = -4.6873e-04 + 0.9 * (-2.3945) - (-0.2761) = −1.8794
δ_2 = r2 + γV_3 - V_2 = -3.1257e-04 + 0.9 * (0.1729) - (-2.3945) = 2.5498
δ_3 = r3 + γV_4 - V_3 = 5.8591e-05 + 0.9 * (-0.0919) - 0.1729 = −0.2556
δ_4 = r4 + γV_5 - V_4 = -5.5084e-03 + 0.9 * (-0.0867) - (-0.0919) = 0.0084
δ_5 = r5 + γV_6 - V_5 = -4.0741e-03 + 0.9 * (-0.0818) - (-0.0867) = 0.0090
δ_6 = r6 + γV_7 - V_6 = -5.5275e-03 + 0.9 * (-0.0758) - (-0.0818) = 0.0081
δ_7 = r7 + γV_8 - V_7 = -8.5999e-02 + 0.9 * 0 - (-0.0758) = −0.0102- 接下来,根据给出的公式计算优势函数
可以算出A_1到A_7的值分别如下
仔细观察这些式子,你会发现它们彼此之间的换算关系
比如,
等价为,而括号里的不就是
么?也就意味着
,依此类推:
、
、
、
、
、
所以我们实际计算的时候,为减少计算量,可以先计算A_7,再分别计算A_6、A_5、A_4、A_3、A_2、A_1
假设 λ = 0.95,则有
「也回顾下λ参数的含义,λ允许我们控制优势函数估计应该多大程度地考虑未来的奖励
较高的λ值会使我们更多地考虑未来的奖励(当λ=1时,GAE退化为蒙特卡洛估计,它会考虑所有的未来奖励,因为当λ接近1时,的值会保持较大)
而较低的λ值则更侧重于即时的奖励(当λ=0时,GAE退化为一步TD误差,这只考虑了最直接的下一步奖励,因为当λ接近0时,
A_7 = δ_7 = -0.0102
A_6 = δ_6 + 0.9 * 0.95 * A_7 = 0.0081 + 0.9 * 0.95 * (−0.0102) = -0.0006
A_5 = δ_5 + 0.9 * 0.95 * A_6 = 0.0090 + 0.9 * 0.95 * (-0.0006) = 0.0085
A_4 = δ_4 + 0.9 * 0.95 * A_5 = 0.0084 + 0.9 * 0.95 * (0.0085) = 0.0157
A_3 = δ_3 + 0.9 * 0.95 * A_4 = (-0.2556) + 0.9 * 0.95 * (0.0157) = -0.2422
A_2 = δ_2 + 0.9 * 0.95 * A_3 = 2.5498 + 0.9 * 0.95 * (-0.2422) = 2.3426
A_1 = δ_1 + 0.9 * 0.95 * A_2 = (-1.8794) + 0.9 * 0.95 * (2.3426) = 0.1216- 最后,我们根据回报公式
计算每个时间步的回报:
R_1 = A_1 + V_1 = 0.1236 + -0.2761 = -0.1525
R_2 = A_2 + V_2 = 2.3426 + -2.3945 = -0.0518
R_3 = A_3 + V_3 = -0.2422 + 0.1729 = -0.0693
R_4 = A_4 + V_4 = 0.0157 + -0.0919 = -0.0763
R_5 = A_5 + V_5 = 0.0085 + -0.0867 = -0.0782
R_6 = A_6 + V_6 = -0.0006 + -0.0818 = -0.0824
R_7 = A_7 + V_7 = -0.0102 + -0.0758 = -0.0860所以,整个序列的回报序列是returns = [-0.1525, -0.0518, -0.0693, -0.0763, -0.0782, -0.0824, -0.0860]
顺带提一嘴,当我们得到整个序列的回报序列之后,我们便训练价值序列去拟合这个回报序列「且训练中还会和旧价值序列的差异做下约束,具体是通过截断的方式实现,最终通过去拟合returns序列之后,可以得到一个新的预测更准确的新values序列」
如此,是不就和3.2.2节中关于DSC一系列的公式 给对上了?哈,只要功夫深铁杵磨成针,古人诚不欺也 !
第四部分 类ChatGPT开源项目的训练框架/代码实现/部署微调
虽说GPT3在2020年就出来了,但OpenAI并未开源,所以直到一年半后以后才有国内外各个团队比如DeepMind等陆续复现出来,这些大厂的复现代码我们自然无法窥知一二,毕竟人家也未开源出来
再到后来基于GPT3的InstructGPT、基于GPT3.5的ChatGPT初版(GPT3.5的参数规模也尚无准确定论)、GPT4均未开源,OpenAI不再open,好在Meta等公司或研究者开源出了一系列类ChatGPT项目,本部分针对其中部分做下简要推荐..
...
为避免本文篇幅再次过长,本第4部分余下的内容已抽取出去独立成文,请点击:
- 英文类ChatGPT的部署与微调:LLaMA的解读与其微调:Alpaca-LoRA/Vicuna/BELLE/中文LLaMA/姜子牙/LLaMA 2、从零实现带RLHF的类ChatGPT:逐行解析微软DeepSpeed Chat
- 中文类ChatGPT的部署与微调:ChatGLM-6B的基座/部署/微调/实现:从GLM到6B的LoRA/P-Tuning微调、及6B源码解读、中文模型的奋起直追:MOSS、baichuan-7B和ChatGLM2-6B的部署与微调
- LLM应用:垂直领域大模型:从医疗ChatDoctor到金融BloombergGPT、法律ChatLaw/LawGPT_zh、给LLM装上知识:从LangChain+LLM的本地知识库问答到LLM与知识图谱的结合
后记
事实上,可能很多朋友也已经意识到,本文的前大部分内容里,GPT-N理解起来相对轻松(包括Transformer通过理解上篇BERT笔记不算特别复杂),而instructGPT/ChatGPT的整体架构思想也不算复杂,但其中涉及到的RL部分则让想深挖细节的初学者变得立马吃力起来(除非你已“入一定门”,或者你有课程/老师可以不断问),比如一个PPO算法,要真正把这个概念讲清楚、讲透彻且从零推到尾则没那么容易了
为了写本笔记,过去两个月翻了大量中英文资料/paper(中间一度花了大量时间去深入RL),大部分时间读的更多是中文资料,2月最后几天读的更多是英文paper,正是2月底这最后几天对ChatGPT背后技术原理的研究才开始进入状态,之后不断深入『后还组建了一个“ChatGPT之100篇论文阅读组”,我和10来位博士、业界大佬从23年2.27日起半年之内读完ChatGPT相关技术的100篇论文,榜单见此文 』,由此而感慨:
- 读的论文越多,你会发现大部分人对ChatGPT的技术解读都是不够准确或全面的,毕竟很多人没有那个工作需要或研究需要,去深入了解各种细节
- 因为论文阅读这个任务,让自己有史以来一篇一篇一行一行读100篇,之前看的比较散 不系统 抠的也不细
比如回顾“Attention is all you need”这篇后,对优化上一篇Transformer笔记便有了很多心得
总之,读的论文越多(论文之后 可以再抠代码实现/复现),博客内相关笔记的质量将飞速提升 自己的技术研究能力也能有巨大飞跃
再之后,则如本文最开头所述,为了彻底写清楚ChatGPT背后的所有关键细节,从1月初写到6月底仍未完工,除了本文之外,过程中涉及到多篇文章(RL入门、论文带读、微调实战、代码实现、CV多模态),再加上之前写的Transformer、RL数学基础等多篇笔记,成了一个大系列,始终保持不断深挖
参考文献与推荐阅读
- Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT,July
- 《预训练语言模型》,电子工业出版
- GPT3原始论文:Language Models are Few-Shot Learners,这是翻译之一
- GPT,GPT-2,GPT-3 论文精读,2018年6月份OpenAI提出GPT(当年10月份Google提出BERT),随后2019年2月14日推出GPT2,20年年中推出GPT3,此文介绍了GPT发家史
- PostNorm/PreNorm的差别
-
此外,写过图解Word2vec、图解transformer的Jay Alammar也写过:图解GPT2(其翻译版)、图解GPT3(其翻译版)
-
GPT系列论文阅读笔记,另 300行代码实现GPT:GitHub - karpathy/minGPT: A minimal PyTorch re-implementation of the OpenAI GPT (Generative Pretrained Transformer) training
- OpenAI关于对GPT3.5的介绍:https://beta.openai.com/docs/model-index-for-researchers
- prompt提示学习(一)简要介绍
- CMU刘鹏飞:近代自然语言处理技术发展的“第四范式”
- 大模型prompt Turing技术上,这是针对这次分享的解读
- NLP小样本学习:如何用20条数据完成文本分类,此外,小样本学习也是七月NLP高级班上重点讲的技术之一,最新一期NLP11则加入了ChatGPT背后原理的解析
- 【论文解读】in-context learning到底在学啥?
- 万字拆解!追溯ChatGPT各项能力的起源
- GPT-Fathom: Benchmarking Large Language Models to Decipher the Evolutionary Path towards GPT-4 and Beyond
- A Survey for In-context Learning,这是对该论文的解读,该论文作者之一维护的一个Paper List for In-context Learning
- 首次提出instruction turning的FLAN原始论文:FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS,这是解读之一
此外,FLAN-T5原始论文:Scaling Instruction-Finetuned Language Models,这是对T5的解读之一 - GPT-3.5 + ChatGPT: An illustrated overview - Life Architect
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,思维链技术的开山之作,这是针对该篇论文的来自亚马逊一研究者的解读(YouTube),这是针对该篇论文的解读笔记,这是关于Cot的一些关键paper,这是T5作者之一关于Cot的分享之一
- Large Language Models are Zero-Shot Reasoners,来自东京大学和Google的研究者
- Multimodal Chain-of-Thought Reasoning in Language Models,来自亚马逊的研究者
- Large Language Models Are Reasoning Teachers,提出了 Fine-tune-CoT 方法,旨在利用非常大的语言模型 (LMs) 的CoT推理能力来教导小模型如何解决复杂任务
- PLM 是做题家吗?一文速览预训练语言模型数学推理能力新进展
- 有了Chain of Thought Prompting,大模型能做逻辑推理吗?
- 热点解读:大模型的突现能力和ChatGPT引爆的范式转变
- 通向AGI之路:大型语言模型(LLM)技术精要,张俊林
- Codex介绍页面:OpenAI Codex,Codex原始论文:Evaluating Large Language Models Trained on Code,另这是针对Codex原始论文的解读
- PPO原始论文:Proximal Policy Optimization Algorithms
- PPO算法解读(英文2篇):解读1 RL — Proximal Policy Optimization (PPO) Explained、解读2 Proximal Policy Optimization (PPO)
- PPO算法解读(中文3篇):Easy RL上关于PPO的详解、详解近端策略优化、详解深度强化学习 PPO算法
- PPO算法实现:https://github.com/lvwerra/trl
- 如何选择深度强化学习算法?MuZero/SAC/PPO/TD3/DDPG/DQN/等
- Google搜索:instructGPT如何基于PPO算法进行训练,出来的一系列文章
- InstructGPT原始论文(确实有68页,^_^):Training language models to follow instructions with human feedback,我是23年2.28日首次基本完整看完
- InstructGPT 论文精读,来自动手学深度学习一书作者李沐的解读
- ChatGPT原理猜想(1)--从InstructGPT讲起,ChatGPT原理猜想(2)--InstructGPT深入学习
- ChatGPT: Optimizing Language Models for Dialogue,OpenAI关于ChatGPT的官方发布页面
- ChatGPT会取代搜索引擎吗,张俊林
- Illustrating Reinforcement Learning from Human Feedback (RLHF),另这是中文翻译版之一
- OpenAI联合DeepMind发布全新研究:根据人类反馈进行强化学习,表明2017年便开始研究RLHF了
- 基于人类偏好的深度强化学习(Deep reinforcement learning from human preferences),这是翻译版之一,这是解读之一
- 《Learning from summarize from Human feedback》,这篇博客是对这篇论文的解读之一
- HuggingFace的视频分享:RL from Human Feedback- From Zero to chatGPT,这是文字解读:ChatGPT 背后的“功臣”——RLHF 技术详解
- OpenAI's InstructGPT: Aligning Language Models with Human Intent
- 不忽悠的ChatGPT,作者Ben
- 别光顾着玩,让我来告诉你ChatGPT的原理,来自B站UP主弗兰克甜
- 浅析ChatGPT的原理及应用,此外,这里还有一篇外文解读:How ChatGPT actually works
- Role of RL in Text Generation by GAN(强化学习在生成对抗网络文本生成中扮演的角色)
- 抱抱脸:ChatGPT背后的算法——RLHF
- 关于指令微调等关键技术:What Makes a Dialog Agent Useful?,这是此文的翻译版
- 谷歌FLAN-T5作者亲讲:5400亿参数,1800个任务,如何实现大语言模型“自我改进”
- 为什么chatgpt的上下文连续对话能力得到了大幅度提升?
- LaMDA: Language Models for Dialog Applications,Google对话机器人LaMDA原始英文论文
- https://github.com/hpcaitech/ColossalAI/tree/main/applications/ChatGPT
- https://www.hpc-ai.tech/blog/colossal-ai-chatgpt
- ChatGPT原理介绍
- ChatGPT 标注指南来了!数据是关键
- https://openai.com/research/gpt-4,GPT4的介绍页面
- LLaMA模型惨遭泄漏,Meta版ChatGPT被迫「开源」!GitHub斩获8k星,评测大量出炉
- 还在为玩不了ChatGPT苦恼?这十几个开源平替也能体验智能对话
- 大模型训练避坑指南
- 复现instructGPT的两个尝试:Instruct GPT复现的一些细节与想法、复现 Instruct GPT / RLHF
- 从零实现带RLHF的类ChatGPT:逐行解析微软DeepSpeed Chat
- 从零训练大模型教程
- ChatGPT相关技术必读论文100篇(2.27日起,几乎每天更新)
附录:修改/完善/新增记录
以下是本文的部分修改/完善/新增记录
- 开始第一大阶段的修改
1.22日,优化关于“instructGPT:如何基于RLHF运用到多轮对话场景”中的部分描述
且为避免篇幅过长而影响完读率,权衡之下把扩展阅读下的SeqGAN相关内容删除 - 1.27日,修改此部分内容:“instructGPT/ChatGPT:如何更好的构建多轮对话能力”,之前的阐述没在点子上
- 2.9日,受正在编写的微积分和概率统计笔记的启发:把公式、定理、概念、技术放在历史这个大背景下阐述会让读者理解更为深刻,故,在本文开头前沿里,新增ChatGPT各个前置技术的发展、迭代、结合,并依据这些前置技术的先后提出顺序重新编排全文结构
- 2.10日,把第一部分中的大部分RL细节抽取出来放到新一篇笔记《RL极简入门》里
- 2.15日,针对本文开头所梳理的ChatGPT各项前置技术的推出时间从年份细化到月份,新增“RLHF”,及“低成本实现ChatGPT低配版训练过程的开源项目”
- 2.16日,为更一目了然,进一步完善本文对自注意力机制的阐述
- 2.17日,进一步完善本文对RLHF的阐述,比如新增对两篇RLHF相关论文的介绍
- 2.21日,根据instructGPT原始论文,修正大量同类解读中针对“ChatGPT训练三步骤”也存在的不够精准的个别描述
- 2.22日,新增关于“Prompt技术的升级与创新:指令微调技术(IFT)与思维链技术(CoT)”的部分
- 进入第二大阶段的修改
2.25日,新增关于"GPT3到GPT3.5:从instructGPT到ChatGPT的迭代过程"的部分
相比前几天有了质的提升
之前哪怕修改十几次也都是1.x版本,今天的这个版本可以称之为2.0版本了,还会不断完善 - 2.26日,修正instructGPT/ChatGPT训练三步骤中“
的对应关系”
且修正为:SFT就是基线模型 最后不用去更新它的策略 - 2.28日,修正对one-shot和few-shot的描述,相当于one-shot相当于就一个样本/示例,few-shot就是少量样本/示例
且在本文最后附上了“ChatGPT相关技术的100篇论文必读榜” - 3.1日,修正训练RM模型的描述中个别不够准确的措辞,比如通过人类的排序而非打分去训练奖励函数/模型
且删除关于“近端策略优化裁剪PPO-clip”的介绍,毕竟详细的可以查看另一篇RL极简入门 - 3.2日,考虑到本文一读者留言说,“第三部分的
故为方便大家一目了然,已把该目标函数首次展开了下 - 3.3日,在本文第二部分开头补充“NLP自发展以来先后经历的4种任务处理范式”
- 3.7日,修正RLHF这一概念的最早提出时间,且补充关于beam search的介绍、完善关于“GPT的(自监督)预训练-(有监督)微调模式”的描述
- 进入第三大阶段的修改(根据论文精修)
3.8日,通过再次回顾GPT3的论文,补充关于为何GPT3不需要微调的原因,且修正个别不太精准的描述 - 3.11日,根据Google的FLAN论文,修订关于指令微调的部分细节,以让行文更准确
- 3.15日,新增一节“2.7 ChatGPT改进版:底层语言模型从GPT3.5升级到GPT4”的内容
新增一小节“3.3.2 斯坦福Alpaca:人人都可微调Meta家70亿参数的LLaMA大模型”的内容 - 3.16日,新增“Masked Self-Attention对屏蔽尾部词的实现方法”的描述
- 3.17日,新增关于“GPT4的训练方式和基于GPT3的instructGPT或基于GPT3.5的ChatGPT初版的训练方式如出一辙”的描述
修订对RLHF的精准定义:基于人类偏好的深度强化学习 - 3.19日,把之前文末推荐的一些开源项目独立出来并完善为本文的“第四部分 关于类ChatGPT的部分开源项目”,并重点阐述Meta开源的LLaMA
- 3.20,通过再次回顾instructGPT论文里的训练三阶段,给本文补充一些细节
- 3.21,根据论文《SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions》,修正“4.3 斯坦福Alpaca:人人都可微调Meta家70亿参数的LLaMA大模型”节中不准确的描述
- 3.22,随着对一系列开源项目的研究深入,为避免本文篇幅再度过长,故把本文的第4部分 抽取出去独立成文:《类ChatGPT开源项目的部署与微调:从LLaMA到ChatGLM-6B》
- 3.25,根据ChatGPT/GPT的最新技术发展,更新前言里的部分内容
- 3.28,修正个别细节,比如根据instructGPT论文第56页可知,PPO模型初始化时曾experimented with a few variants of the SFT models as the PPO’s init model,即PPO模型有多个大小的版本,比如1.3B 6B 175B
- 进入第四大阶段的修改(根据论文再修)
4.7,补充关于SFT与RM模型训练中的一些超参数的设置 - 4.18,补充关于GPT1、GPT3的数据集的相关细节
- 4.21,修正一个描述的笔误,即奖励模型的训练中,用的损失函数是rank loss,而非MSE loss
- 4.27,依据RLHF部分中提到的论文“Fine-Tuning Language Models from Human Preferences”,增加关于instructGPT目标函数中 KL奖励系数
- 4.29,考虑到不少同学在我所讲的ChatGPT原理解析课里询问有关prompt learning的细节,故新增一节“2.4.2 关于prompt learning的进一步总结:到底如何理解prompt learning”
- 5.5,针对本文下面部分读者的留言,新增一些小细节的描述,比如为何
再比如新增对于“旧策略生成的数据 是具体怎么重复使用的”这一问题的解释说明,毕竟网上同类文章里 还没见过有哪篇如此细致的解释说明过 - 进入第五大阶段的修改(结合上课反馈 + 类ChatGPT的开源代码实现)
5.7,因为讲ChatGPT原理课,故在再次完整回顾instructGPT论文之后,补充一些数据、训练代价等细节 - 5.9,因ChatGPT原理课一学员“吹牛班的春天”的意见/建议,特修正「instructGPT训练阶段三」中个别不够准确的描述,至此本文开始从完善阶段超完美阶段进发 (换言之,本次修改后使得本文正式突破85分,超100分迈进)
- 5.13,继上面5.9日的意见之后,算是史无前例的二次展开了instructGPT论文中目标函数的表达式,以和相关描述完全对应起来
当你持续复现instructGPT的话,你会发现细节很多,而只有当你想复现你才会去思考这些细节,从而造就本文或本系列才有的细致 - 5.20,再次细化对instructGPT论文中目标函数的解释说明,比如
总之,目标函数后面的
和PPO算法有关的 都在前面的r(x,y)里,展开后可以通过KL散度去约束新策略相比旧策略的差距,也可以通过截断去约束新策略与旧策略的差距
β惩罚项约束的是不断优化的当前(旧)策略与基线策略的差距,故这个时候的KL只是一个普普通通的KL
这点 初看的时候 很容易混淆
且通过借鉴「实现了instructGPT三阶段训练方式的微软DeepSpeed Chat」的代码实现,把这个带β的惩罚项融入进优势函数中 - 5.28,为让逻辑更加清晰,更一目了然,再度优化此节“InstructGPT训练阶段3:如何通过PPO算法进一步优化模型的策略”的行文描述
- 5.31,为更严谨、准确,进一步完善对RM惩罚的
- 6.5日,补充关于“GPT3的一些参数和训练数据”的细节,比如参数上,它的层数达到了96层,输入维度则达到了12888维(设置了96个注意力头,故每个头的维度为12888/96 = 128维)
- 6.7,考虑到BERT/GPT的预训练方式是自监督「不依赖于人工标注的标签,而是利用数据自身的结构来生成监督信号,比如BERT便使用的两种自监督任务来学习语言的表征:Masked Language Model (MLM,即挖洞,然后让模型做完形填空) 和 Next Sentence Prediction (NSP)」,而非无监督的,故修正相关笔误
- 进入第六大阶段的修改(基于和ChatGPT课学员春天的讨论几乎连改7天)
6.11,改进关于“instructGPT三阶段训练中阶段二中RM模型的初始化”的容易产生歧义的描述,即:直接通过6B的SFT初始化的RM,当然 移除了最后一层unembedding layer - 6.12,新增一节“3.2 如何通过ColossalChat和微软DeepSpeed Chat的实现更好的理解PPO迭代过程”,特别是这一小节:“3.2.1 如何更好的理解Actor-Critic架构中的Critic网络”
- 6.13,修正“3.2.2 ColossalChat模型架构图和微软DeepSpeed Chat关于PPO的实现”中不够严谨的描述
至此,终于把PPO的所有关键细节打通且写通了 - 6.14,新增一节“3.2.4 针对「对话序列/奖励值序列/values/DSC优势函数/returns」的一个完整示例”
- 6.16,进一步完善整个3.2节,特别是对
- 6.17,修正3.2.4节中计算优势函数时的一个笔误,即是A_6 = δ_6 + 0.9 * 0.95 * A_7,而非A_6 = δ_6 + 0.9 * 0.95 * δ_7
至此,所有关键细节都通了,本文的评分可到90分,而这个修改/完善/新增记录也见证了自己对ChatGPT背后技术原理一步步加深的过程,更感谢所有读者/学员的不断提问(包括ChatGPT原理课学员春天的讨论/验证),让我不断把细节写出来 - 6.18,补充3.2.4节中这个换算关系的推导:
且为让整个文章的行文逻辑更清晰,梳理“3.2.3 对句子生成的建模及如何更好的构建多轮对话能力”一节的内容 - 6.19,加了很重要的一句话,即
让Adv最大化的目标下「相当于不断鼓励并探索高于(平均)预期回报的动作」,更新策略(的参数) - 进入第七大阶段的精调
8.19,补充GPT的部分参数,比如层数、维度、头数 - 9.5,为让关于“SFT模型大小”的描述更严谨,增加一句话:该基线模型(指SFT)有三个不同大小的版本,分别为1.3B、6B、175B
且完善三阶段训练方式中阶段2中的这句话:让阶段1的SFT模型回答来自OpenAI API和labeler-written且规模大小为33k的数据集的一些问题比如 - 9.7,因第二天9.8要在七月的课程「LLM与多模态论文100篇带读」中讲GPT前三代的原始论文,故回顾了下相关论文,之后在本文的2.2节补充了下对GPT2模型结构的分析
- 9.12,为降低阅读本文开头内容的负担,同时增强最后阅读微软deepspeed chat关于RLHF实现上的直观性,调整了下colossal画的关于RLHF的两个流程图的位置
- 10.4,补充GPT2中关于“残差权重缩放问题”的说明,苏剑林也有篇文章论述此问题
- 10.9,在“3.2.1 如何更好的理解Actor-Critic架构中的Critic网络”中,补充关于“彻底理清楚AC架构的关键细节”
且精炼此节的内容:3.1.3 InstructGPT训练阶段3:如何通过PPO算法进一步优化模型的策略 - 10.10,再度优化此节的内容:“3.2.1 如何更好的理解Actor-Critic架构中的Critic网络”,补充一些关键细节,避免造成读者在对Actor-Critic架构的理解上的歧义
至此,在过去整整三个季度中,断断续续长达56次修订之后,本文已基本完美,^_^ - 进入第八大阶段的精调(即便是特别细的细节 也不放过,而必须较真)
11.26,在看OpenAI竞争对手Anthropic发的LLM RLHF论文时,再次留意到RLHF的发展起源
从而回顾1.5节中关于RLHF的那三篇论文,最终优化相关细节的描述

