
- 1用Powerpoint (PPT)制作并导出矢量图、高分辨率图_ppt导出矢量图
- 2【Oracle报错处理】ORA-01652:无法通过128(在表空间xxx中)扩展temp段
- 3Python3-sklearn_split the data into 2 groups r
- 4XSS 攻击的检测和修复方法_xss修复过滤掉字符
- 5HTML期末学生大作业-最新QQ音乐、网易云音乐、酷狗音乐、虾米音乐、咪咕音乐网站html+css+javascript_html,css,mysql音乐管理系统
- 6人工智能、机器学习和深度学习有什么区别?_深度学习不等同于ai吧
- 7【华为机试】2024年真题C卷(c++)-5G网络建设
- 8【Ajax】笔记-POST请求(原生)_原生ajax post
- 9TCP Keepalive 和 HTTP Keep-Alive
- 10前端实现word导出(之前插件的一个原理解析)_filesaver基于什么原理
sql知识——08全文本搜索_sql 匹配 字典 分词
赞
踩
支持全文本搜索的引擎
MySQL支持的几种基本的数据库引拳中并非所有的都支持本书所描述的全文本搜索。最常用的引擎为MyISAM和InnoDB,前者支持全文本搜索,而后者不支持。
比较通配符、正则表达式搜索文本和全文本搜索
通配符、正则表达式等搜索机制非常有用,但在搜索的时候存在几个重要的限制:
1、性能差耗时多——通配符和正则表达式匹配通常要求MySQL尝试匹配表中所有行(而且这些搜索极少使用表索引)。因此,由于被搜索行数不断增加,这些搜索可能非常耗时。
2、难以明确控制——使用通配符和正则表达式匹配,很难(而且并不总是能)明确地控制匹配什么和不匹配什么。例如,指定一个词必须匹配,一个词必须不匹配,而一个词仅在第一个词确实匹配得情况下才可以匹配或者才可以不匹配。
3、搜索结果不够智能——虽然基于通配符和正则表达式的搜索提供了非常灵活的搜索,但它们都不能提供一种智能化的选择结果的方法。例如,一个特殊词的匹配将会返回包含该词的所有行,而不区分包含单个匹配的行和包含多个匹配的行。
全文本搜索不同于通配符和正则表达式搜索,它使用索引进行搜索,相比于前两者更高效,结果更加智能。
match函数和against函数进行全文本搜索
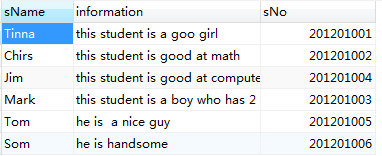
如上述的学生信息表,在信息一览有对学生的简短评价。
传统的正则方法进行搜索和全文本搜索
SELECT information
FROM studentinformation
where information LIKE '%is%';
[SQL]SELECT information
FROM studentinformation
WHERE MATCH(information) AGAINST('good' IN NATURAL LANGUAGE MODE)
- 1
- 2
- 3
- 4
- 5
- 6
match()表示需要进行检索的列
against()表示需要检索的词
注意:当使用InnoDB等引擎进行全文搜索的时候会报错不支持[Err] 1214 - The used table type doesn’t support FULLTEXT indexes
全文本搜索使用说明
1、在索引全文本数据时,短词被忽略且从索引中排除。短词定义为那血具有3个或3个以下字符的词。(如果需要,这个数目可以更改)MySQL自带了一个内建的非用词(stopword)列表,这些词在索引全文本数据时总是被忽略。如果需要,可以覆盖整个列表。
2、许多词出现的频率很高,搜索它们没有用处(返回太多结果)。因此,MySQL归定如果一个词出现在50%以上的行中,则将它作为一个非用词忽略。50%规则不用于IN BOOLEAN MODE。如果表中的行数少于3行,则全文本搜索不返回结果(因为每个词或者不出现,或者出现在50%的行中)。
3、忽略词中的单引号。例如,don’t索引为dont不具有分隔符(脑阔日语和汉语)的语言不能恰当的返回全文搜索的结果仅在MyISAM数据库引擎中支持全文本搜索。
分词器、停用词表、
词干抽取器和同义词词典
全文索引主要包含三种分析器:分词器(Word Breaker)、词干分析器(stemmer)和同义词分析器。全文索引中存储的数据是分词及其位置等信息,分词是基于特定语言的语法规则,按照特定的符号寻找词语的边界,把文本分解为“单词”,每一个单词叫做一个分词(term);全文索引有时会提取分词的词干,把词干的多种派生形式存储为单一词干,这个过程叫做提取词干;根据用户提供的自定义同义词列表,把相关的单词转换为同义词,这个过程叫做提取同义词。
生成全文索引是把用户表中的文本数据进行分词(Word breaker)和提取词干(Stemmer),并转换同义词(Thesaurus),过滤掉分词中的停用词(Stopword),最后把处理之后的数据存储到全文索引中。把数据存储到全文数据的过程叫做填充(Populate)或爬虫(Crawl)进程,全文索引的更新方式可以手动填充,自动填充,或增量填充。
分词器
用于分词,它根据特定语言的语法规则,分割文本中的单词,分词器在拆分单词时,还会记录每个分词在字符串中的位置,分词器把分词,分词的位置,文档ID,全文索引列的序号等信息的组合,称作标记(Token)。例如,对于语句"Kitty is a white pig",在全文索引填充时,分词器把该语句拆分成5个单词:Kitty,is,a,white,pig。 如果使用默认的停用词列表,那么“is”,“a”都是停用词,全文索引会把停用词丢失,只存储分词:Kitty,white,pig。
停用词
停用字词列表(StopList)是非索引字词的列表,每个StopList中存储的分词都是不会用于搜索的分词,叫做停用词(StopWords),全文索引不会存储停用词,但是停用词所占的位置会被记录,如果对停用词进行contians查询,即使基础表(underly table)中的字段中存在该停用词,全文索引也不会返回任何数据行。通常情况下,停用词(Stopword)都是常用的单词,在语句中出现的频率十分高,过滤掉停用词,能够减少全文索引的size,提高全文查询的性能。
词干抽取器
用于把同源单词转换为其根形式,能够转换为相同根形式的单词是同源的。比如sleep、sleeping等会被归结于同源
同义词词典
是一个XML文件,用于定义特定语言的同义词列表,例如,我们可以设置“Author” , “Writer” ,“journalist”是同义词。
https://www.cnblogs.com/ljhdo/p/5041605.html
http://www.360doc.com/content/19/0704/17/12906439_846699165.shtml

