
- 1QML笔记整理——在Qt/C++应用中使用QML_qt c++中设置qml中控件初始化设置
- 2RabbitMq 集群模式_rabbitmq集群模式
- 3Cassandra 安装_cassandra 4.0 yum安装
- 4大数据毕业设计:基于python车牌识别系统 车牌实时检测 OpenCV(源码) ✅_python车牌实时定位
- 5论文阅读--EFFICIENT OFFLINE POLICY OPTIMIZATION WITH A LEARNED MODEL
- 6Vue中el-table实现点击某行高亮_el-table加高亮
- 7通用后台管理系统前端界面Ⅵ——首页、登录页、404页面_后台管理系统首页
- 8Unity摄像机抖动效果_unity镜头抖动效果
- 9kafka 出现多次rebalance故障
- 10python----Numpy知识总结(linalg、三种乘法、argmax)_np.linalg.det含义
AI芯片的基础_npu指令集
赞
踩
前置基础
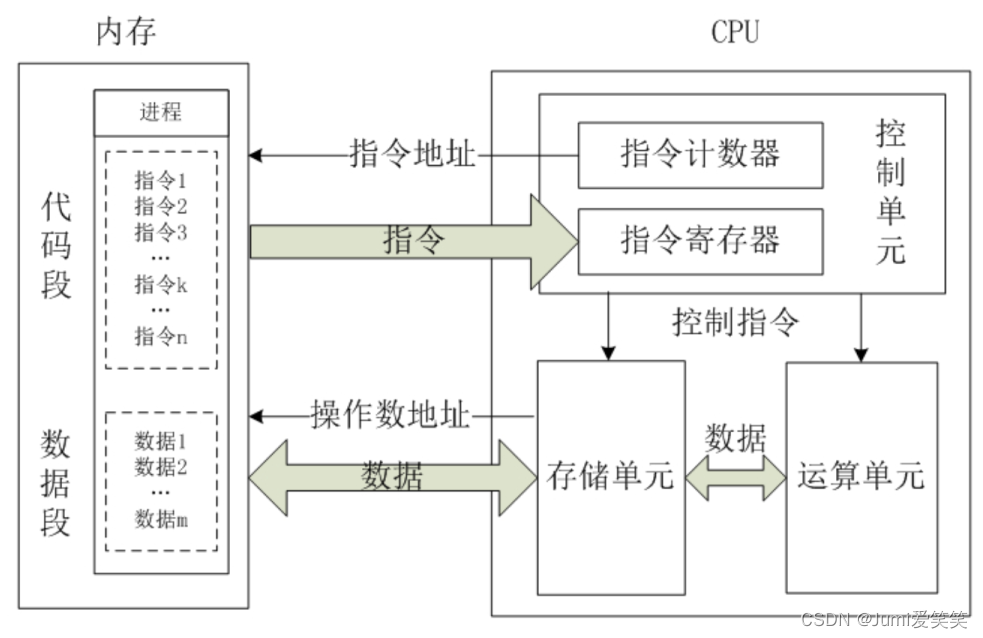
AI芯片其实就是AI算法的专用处理器,像CPU的话是一个通用处理器,CPU按照逻辑可以分为三个模块:控制模块,运算模块,存储模块;其中控制单元有指令寄存器和指令译码器,根据用户预先编译好的程序,把指令集存储起来,再从指令寄存器取出来,用译码器解码后,按照确定的时序,向对应的不见发出控制信号;
什么是AI芯片
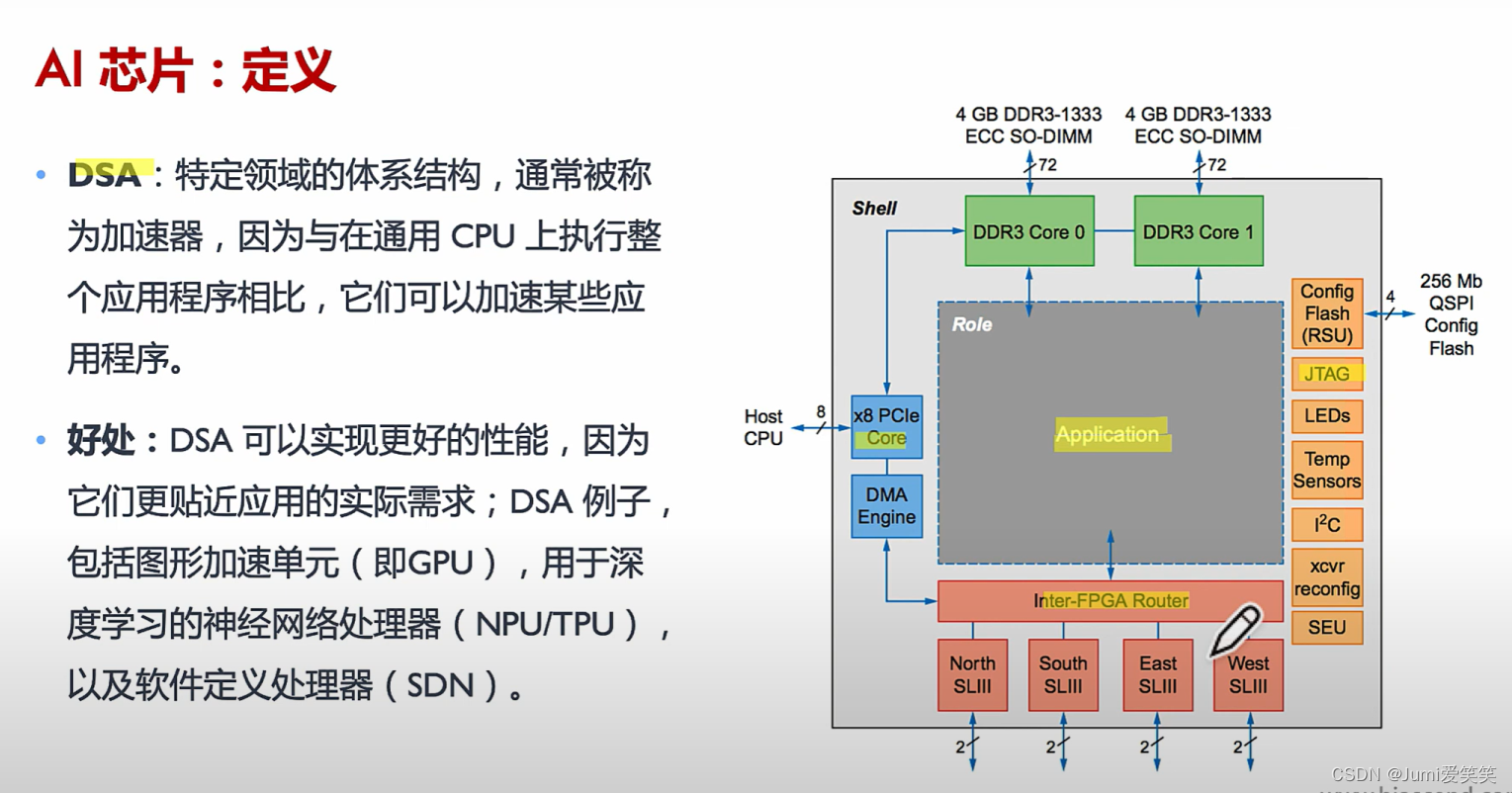
简言之,就是为了AI算法的运行而专门设计的芯片;
CPU&GPU&NPU&TPU之间的区别
从下图可以看出CPU有很多控制单元,但是计算单元的个数却比较少,CPU的核数指的就是计算单元的个数。每个CPU核心都是独立的处理单元,可以执行指令集的一部分并进行计算操作。每个核心通常包含一组算术逻辑单元(ALU)、浮点单元(FPU)和寄存器等。
GPU的话计算单元个数非常多,却没有什么控制单元;
NPU的话,是专门为了神经网络而设计的,在矩阵乘法、激活函数、向量运算上做了优化;
传统的中央处理器(CPU)和图形处理器(GPU)在执行神经网络计算时可能会遇到瓶颈,因为神经网络的计算需求非常高。NPU通过专门的硬件架构和指令集,能够高效地执行神经网络的计算操作,包括矩阵乘法、向量运算和激活函数等。
以下是GPU和NPU之间的区别:
NPU(神经处理单元)和GPU(图形处理单元)都是用于加速计算的硬件加速器,但它们在设计和应用方面存在一些区别:
设计目标:NPU的设计目标是专门用于加速神经网络计算,而GPU则主要用于图形渲染和通用计算。NPU在硬件架构和指令集上进行了优化,以高效执行神经网络的计算操作,如矩阵乘法和激活函数。GPU则更加通用,适用于各种计算任务。
并行性:GPU在设计上注重大规模并行计算,拥有大量的计算核心(CUDA核心)和高带宽的内存,适用于大规模数据并行计算,包括图形处理和通用计算。NPU也具有高度的并行性,但其设计更专注于神经网络的特定操作和数据流。
功耗效率:NPU通常在功耗效率方面进行了优化,以在提供高性能的同时保持较低的功耗水平。它们在设计上注重能源效率,适用于移动设备和边缘计算等功耗敏感的场景。相比之下,GPU在功耗方面通常较高,更适合在电源供应充足的设备中使用。
程序开发:GPU通常使用通用的编程模型和API(如CUDA、OpenCL),可以进行通用计算任务的编程。而NPU通常使用特定的软件框架和库,如TensorFlow Lite、PyTorch等,以便利用其特定的神经网络加速能力。
总的来说,NPU更专注于加速神经网络计算,具有高性能和低功耗的特点,适用于移动设备和边缘计算等场景。而GPU更通用,适用于广泛的并行计算任务,包括图形渲染和通用计算。根据具体的应用需求,选择适合的硬件加速器可以提供最佳的性能和功耗平衡。

AI芯片的部署方式
从下图可以看出,根据应用需求会有不同的部署方式,其中也包括了云、边、端的协同部署,云端负责在线训练,端侧负责推理,边端负责执行;

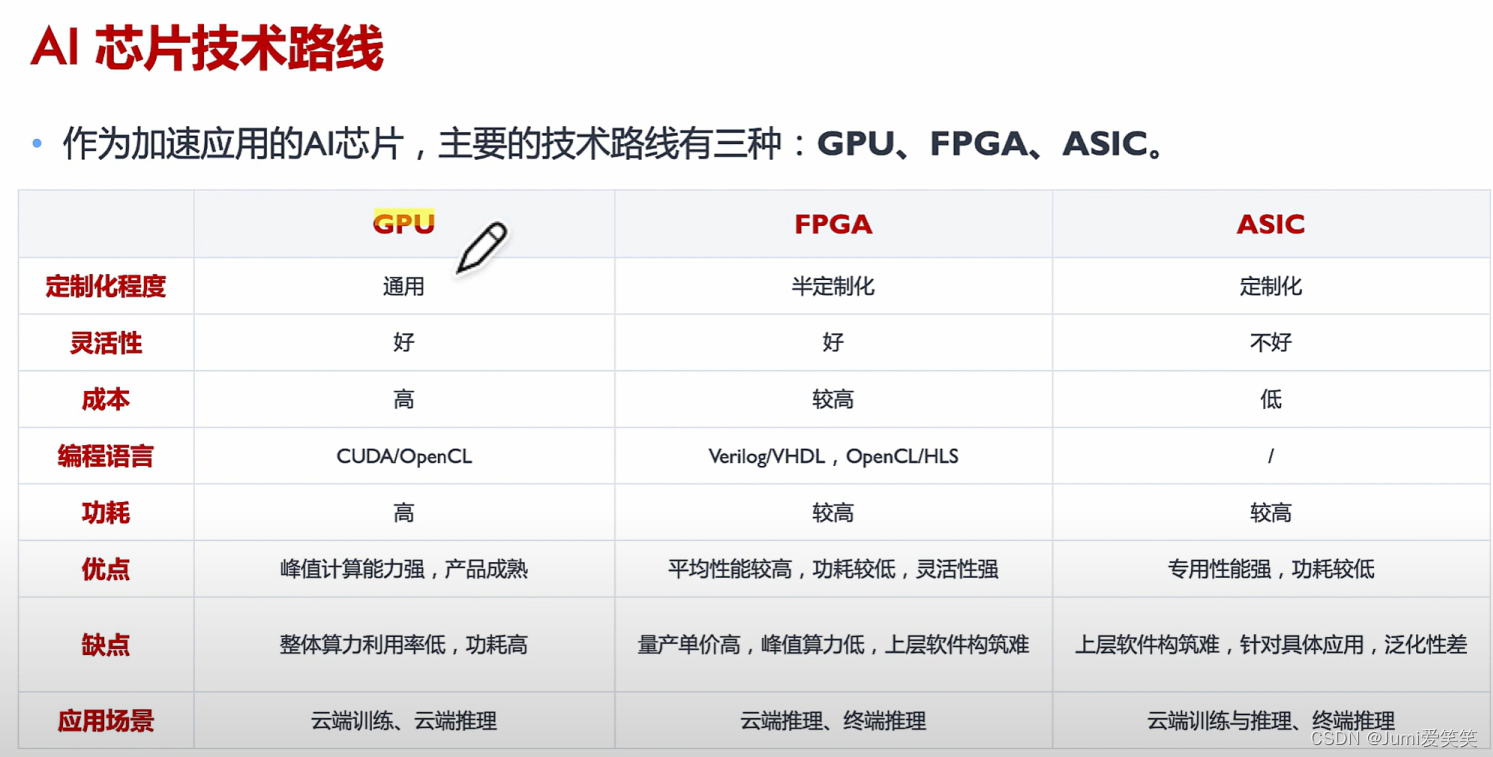
AI芯片的技术路线
包括了GPU,FPGA,ASIC
目前做AI芯片的品牌和厂商

AI芯片的落地场景


