
- 1基于Java+SpringBoot+Vue前后端分离婚纱影楼管理系统设计和实现_springboot vue婚纱影楼系统
- 2保姆级教程-如何使用LLAMA2 大模型_如何调用 llama 的 api
- 3Jenkins忘记密码解决方案_jenkins忘记用户名和密码
- 4《Python编程:从入门到实践》第12章:武装飞船_python入门到实践中的 ship.bmg
- 52023美赛E题_2023美赛e题 背景 光污染是用来描述任何过度或不良的使用人工光。一些我们称之为
- 6MYSQL 8 UNDO 表空间 你了解多少
- 7vs code解决无法识别已安装python库的问题(Mac版)
- 8初始MyBatis,w字带你解MyBatis
- 9video 标签设置样式_video标签样式
- 10如何在论文中画出漂亮的插图?
Pandas 学习手册中文第二版:1~5_pandas官方手册中文版
赞
踩
译者:飞龙
一、Pandas 与数据分析
欢迎来到《Pandas 学习手册》! 在本书中,我们将进行一次探索我们学习 Pandas 的旅程,这是一种用于 Python 编程语言的开源数据分析库。 pandas 库提供了使用 Python 构建的高性能且易于使用的数据结构和分析工具。 pandas 从统计编程语言 R 中带给 Python 许多好处,特别是数据帧对象和 R 包(例如plyr和reshape2),并将它们放置在一个可在内部使用的 Python 库中。
在第一章中,我们将花一些时间来了解 Pandas 及其如何适应大数据分析的需要。 这将使对 Pandas 感兴趣的读者感受到它在更大范围的数据分析中的地位,而不必完全关注使用 Pandas 的细节。 目的是在学习 Pandas 的同时,您还将了解为什么存在这些功能以支持执行数据分析任务。
因此,让我们进入。在本章中,我们将介绍:
- Pandas 是什么,为什么被创造出来,它给您带来什么
- Pandas 与数据分析和数据科学之间的关系
- 数据分析涉及的过程以及 Pandas 如何支持
- 数据和分析的一般概念
- 数据分析和统计分析的基本概念
- 数据类型及其对 Pandas 的适用性
- 您可能会与 pandas 一起使用的 Python 生态系统中的其他库
Pandas 介绍
pandas 是一个 Python 库,其中包含高级数据结构和工具,这些数据结构和工具已创建来帮助 Python 程序员执行强大的数据分析。 Pandas 的最终目的是帮助您快速发现数据中的信息,并将信息定义为基本含义。
Wes McKinney 于 2008 年开始开发 Pandas。 它于 2009 年开源。Pandas 目前受到各种组织和贡献者的支持和积极开发。
最初设计 Pandas 时要考虑到财务问题,特别是它具有围绕时间序列数据操作和处理历史股票信息的能力。 财务信息的处理面临许多挑战,以下是一些挑战:
- 表示随着时间变化的安全数据,例如股票价格
- 在相同时间匹配多个数据流的度量
- 确定两个或多个数据流的关系(相关性)
- 将时间和日期表示为实体流
- 向上或向下转换数据采样周期
要进行此处理,需要使用一种工具,使我们能够对单维和多维数据进行检索,索引,清理和整齐,整形,合并,切片并执行各种分析,包括沿着数据自动对齐的异类数据。 一组公共索引标签。 这是 Pandas 诞生的地方,它具有许多有用而强大的功能,例如:
- 快速高效的
Series和DataFrame对象,通过集成索引进行数据处理 - 使用索引和标签进行智能数据对齐
- 整合处理缺失数据
- 将杂乱数据转换(整理)为有序数据的工具
- 内置工具,用于在内存数据结构与文件,数据库和 Web 服务之间读写数据
- 处理以许多常见格式(例如 CSV,Excel,HDF5 和 JSON)存储的数据的能力
- 灵活地重塑和透视数据集
- 大型数据集的基于智能标签的切片,花式索引和子集
- 可以从数据结构中插入和删除列,以实现大小调整
- 使用强大的数据分组工具聚合或转换数据,来对数据集执行拆分应用合并
- 数据集的高性能合并和连接
- 分层索引有助于在低维数据结构中表示高维数据
- 时间序列数据的广泛功能,包括日期范围生成和频率转换,滚动窗口统计,滚动窗口线性回归,日期平移和滞后
- 通过 Cython 或 C 编写的关键代码路径对性能进行了高度优化
强大的功能集,以及与 Python 和 Python 生态系统内其他工具的无缝集成,已使 Pandas 在许多领域得到广泛采用。 它被广泛用于学术和商业领域,包括金融,神经科学,经济学,统计学,广告和网络分析。 它已成为数据科学家表示数据进行操作和分析的最优选工具之一。
长期以来,Python 在数据处理和准备方面一直是例外,但在数据分析和建模方面则例外。 pandas 帮助填补了这一空白,使您能够在 Python 中执行整个数据分析工作流,而不必切换到更特定于领域的语言(例如 R)。这非常重要,因为熟悉 Python 的人比 R(更多的统计数据包),获得了 R 的许多数据表示和操作功能,同时完全保留在一个极其丰富的 Python 生态系统中。
与 IPython,Jupyter 笔记本和众多其他库相结合,与许多其他工具相比,用于在 Python 中执行数据分析的环境在性能,生产力和协作能力方面表现出色。 这导致许多行业的许多用户广泛采用 Pandas。
数据处理,分析,科学和 Pandas
我们生活在一个每天都会产生和存储大量数据的世界中。 这些数据来自大量的信息系统,设备和传感器。 您所做的几乎所有操作以及用于执行此操作的项目都会生成可以捕获或捕获的数据。
连接到网络的服务无处不在的性质以及数据存储设施的大量增加极大地支持了这一点。 这与不断降低的存储成本相结合,使捕获和存储甚至最琐碎的数据都变得有效。
这导致堆积了大量数据并准备好进行访问。 但是,该数据分布在整个网络空间中,实际上不能称为信息。 它往往是事件记录的集合,无论是财务记录,您与社交网络的互动,还是全天跟踪您的心跳的个人健康监控器。 这些数据以各种格式存储,位于分散的位置,并且其原始性质的确能提供很多洞察力。
从逻辑上讲,整个过程可以分为三个主要学科领域:
- 数据处理
- 数据分析
- 数据科学
这三个学科可以而且确实有很多重叠之处。 各方结束而其他各方开始的地方可以解释。 为了本书的目的,我们将在以下各节中对其进行定义。
数据处理
数据分布在整个地球上。 它以不同的格式存储。 它的质量水平差异很大。 因此,需要用于将数据收集在一起并转化为可用于决策的形式的工具和过程。 这需要操作数据以进行分析准备的工具需要执行许多不同的任务和功能。 该工具需要的功能包括:
- 重用和共享的可编程性
- 从外部来源访问数据
- 在本地存储数据
- 索引数据来高效检索
- 根据属性对齐不同集合中的数据
- 合并不同集合中的数据
- 将数据转换为其他表示形式
- 清除数据中的残留物
- 有效处理不良数据
- 将数据分组到通用篮子中
- 聚合具有相似特征的数据
- 应用函数计算含义或执行转换
- 查询和切片来探索整体
- 重组为其他形式
- 为不同类型的数据建模,例如类别,连续,离散和时间序列
- 将数据重新采样到不同的频率
存在许多数据处理工具。 每个人对此列表中的项目的支持,部署方式以及用户如何使用都各不相同。 这些工具包括关系数据库(SQL Server,Oracle),电子表格(Excel),事件处理系统(例如 Spark)以及更通用的工具(例如 R 和 Pandas)。
数据分析
数据分析是从数据创建含义的过程。 具有量化含义的数据通常称为信息。 数据分析是通过创建数据模型和数学模型来从数据中创建信息的过程。 它经常与数据操作重叠,并且两者之间的区别并不总是很清楚。 许多数据处理工具还包含分析功能,并且数据分析工具通常提供数据处理功能。
数据科学
数据科学是使用统计和数据分析过程来了解数据中现象的过程。 数据科学通常从信息开始,然后对信息进行更复杂的基于领域的分析。 这些领域涵盖许多领域,例如数学,统计学,信息科学,计算机科学,机器学习,分类,聚类分析,数据挖掘,数据库和可视化。 数据科学是多学科的。 它的域分析方法通常非常不同,并且特定于特定域。
Pandas 适合什么?
Pandas 首先在数据处理方面表现出色。 本书将使用 Pandas 满足前面列出的所有需求。 这是 Pandas 的核心,也是本书重点关注的内容。
值得注意的是,Pandas 有一个特定的设计目标:强调数据
但是 Pandas 确实提供了执行数据分析的多种功能。 这些功能通常围绕描述性统计和财务所需的功能(例如相关性)。
因此,Pandas 本身不是数据科学工具包。 它更多是具有某些分析功能的操纵工具。 Pandas 明确地将复杂的统计,财务和其他类型的分析留给了其他 Python 库,例如 SciPy,NumPy,scikit-learn,并依赖于图形库,例如 matplotlib 和 ggvis 用于数据可视化。
这种关注点实际上是 Pandas 相对于 R 等其他语言的强项,因为 Pandas 应用能够利用 Python 社区在其他地方已经构建和测试的强大的 Python 框架的广泛网络。
数据分析过程
本书的主要目的是彻底地教您如何使用 Pandas 来操纵数据。 但是,还有一个次要的,也许同样重要的目标,是显示 Pandas 如何适应数据分析师/科学家在日常生活中执行的过程。
Pandas 网站上对数据分析过程中涉及的步骤进行了描述:
- 清除和清洁数据
- 分析/建模
- 组织成适合交流的形式
这个小的清单是一个很好的初始定义,但是它无法涵盖过程的整体范围以及创建 Pandas 中实现的许多功能的原因。 以下内容将对此过程进行扩展,并为整个旅程中的过程设置框架。
过程
所建议的过程将被称为数据流程,并在下图中表示:
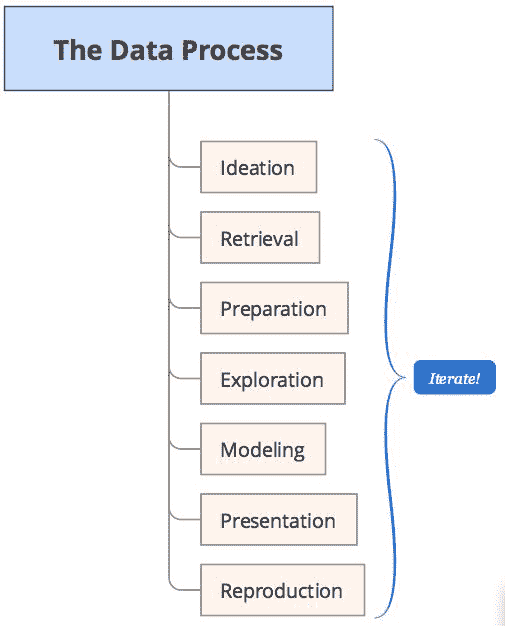
该过程建立了一个框架,用于定义处理数据时要采取的逻辑步骤。 现在,让我们快速看一下该过程中的每个步骤,以及作为使用 Pandas 的数据分析员将执行的一些任务。
重要的是要了解这不是纯粹的线性过程。 最好以高度交互和敏捷/迭代的方式完成。
构想
任何数据问题的第一步都是确定要解决的问题。 这就是构想,它提出了我们想要做和证明的事情的构想。 构想通常涉及对可用于做出明智决策的数据模式进行假设。
这些决策通常是在企业范围内,但在其他学科(例如科学和研究)中也是如此。 目前正在流行的事情是了解企业的运营,因为在理解数据时通常会赚很多钱。
但是,我们通常希望做出什么样的决定? 以下是几个常见问题的答案:
- 为什么会发生什么事?
- 我们可以使用历史数据预测未来吗?
- 将来如何优化操作?
这份清单绝非详尽无遗,但确实涵盖了任何人进行这些努力的原因的相当大的百分比。 要获得这些问题的答案,必须参与收集和理解与该问题有关的数据。 这涉及定义要研究的数据,研究的收益,如何获得数据,成功的标准是什么以及最终如何传递信息。
Pandas 本身不提供辅助构想的工具。 但是一旦您掌握了使用 Pandas 的知识和技巧,您就会自然地意识到 Pandas 将如何帮助您提出构想。 这是因为您将拥有一个强大的工具,可以用来构建许多复杂的假设。
检索
一旦有了想法,就必须找到数据来尝试并支持您的假设。 这些数据可以来自组织内部或外部数据提供者。 该数据通常以存档数据的形式提供,也可以实时提供(尽管以实时数据处理工具而闻名的 Pandas)。
即使从您创建的数据源或从组织内部获取数据,数据也通常是非常原始的。 原始数据意味着数据可能是杂乱无章的,可能是各种格式,而且是错误的; 相对于支持您的分析,它可能是不完整的,需要手动进行扩充。
世界上有很多免费数据。 许多数据不是免费的,实际上要花费大量金钱。 其中一些可通过公共 API 免费获得,其他一些则通过订阅获得。 您所支付的数据通常更干净,但这并非总是如此。
在这两种情况下,Pandas 都提供了一套强大且易于使用的工具,用于从各种来源检索数据,并且这些数据可能采用多种格式。 pandas 还使我们不仅能够检索数据,还可以通过 pandas 数据结构提供数据的初始结构,而无需手动创建其他工具或编程语言可能需要的复杂编码。
准备
在准备过程中,已准备好原始数据以供探索。 准备工作通常是一个非常有趣的过程。 通常情况下,来自数据的数据会涉及与质量相关的各种问题。 您可能会花费大量时间来处理这些质量问题,而这通常是非常短的时间。
为什么? 嗯,原因有很多:
- 数据根本不正确
- 缺少部分数据集
- 无法使用适合您分析的度量来表示数据
- 数据格式不便于您分析
- 数据的详细程度不适合您的分析
- 并非所有需要的字段都可以从一个来源获得
- 数据的表示因提供者而异
准备过程着重解决这些问题。 Pandas 为准备数据(通常称为整理数据)提供了许多便利的工具。 这些功能包括处理缺失数据,转换数据类型,使用格式转换,更改测量频率,将来自多组数据的数据连接,将符号映射/转换为共享表示以及将数据分组的智能方法。 我们将深入探讨所有这些内容。
探索
探索涉及能够交互式地对数据进行切片和切块,以尝试快速发现。 探索可以包括各种任务,例如:
- 检查变量之间的相互关系
- 确定数据的分发方式
- 查找和排除异常值
- 创建快速的可视化
- 快速创建新的数据表示形式或模型来馈入更永久和详细的建模过程
探索是 Pandas 的一大优势。 虽然可以使用大多数编程语言进行探索,但是每种语言都有其自己的仪式级别 – 在实际发现之前,必须执行多少非探索性工作。
当与 IPython 和/或 Jupyter 笔记本的读取-求值-打印-循环(REPL)性质一起使用时,Pandas 会创建一个几乎没有仪式的探索性环境。 pandas 语法的表现力使您可以简洁地描述复杂的数据操作结构,并且对数据执行的每个操作的结果都将立即呈现出来供您检查。 这使您可以快速确定刚刚执行的操作的有效性,而不必重新编译并完全重新运行程序。
建模
在建模阶段,您将探索过程中发现的发现正式化为对达到数据中包含的所需含义所需的步骤和数据结构的明确解释。 这是模型,是两种数据结构以及从原始数据到您的信息和结论的代码步骤的组合。
建模过程是迭代的,在此过程中,您可以通过浏览数据来选择支持分析所需的变量,组织变量以供输入分析过程,执行模型并确定模型对原始假设的支持程度。 它可以包括数据结构的形式化建模,但也可以结合来自各种分析领域的技术,例如(但不限于)统计,机器学习和运筹学。
为此,Pandas 提供了广泛的数据建模工具。 在此步骤中,您将需要更多的工作,从探索数据到在DataFrame对象中形式化数据模型,并确保创建这些模型的过程简洁。 此外,通过基于 Python,您可以充分利用其强大的功能来创建程序,以使流程从头到尾实现自动化。 您创建的模型是可执行的。
从分析的角度来看,pandas 提供了多种功能,其中最引人注目的是对描述性统计信息的集成支持,这些功能可以使您解决许多类型的问题。 而且由于 Pandas 是基于 Python 的,因此如果您需要更高级的分析功能,可以很容易地将其与广泛的 Python 科学环境的其他部分集成。
演示
该过程的倒数第二个步骤是通常以报告或演示文稿的形式向他人展示您的发现。 您将需要为您的解决方案创建一个有说服力的详尽说明。 通常可以使用 Python 中的各种绘图工具并手动创建演示文稿来完成此操作。
Jupyter 笔记本是一种强大的工具,可为您的 Pandas 分析创建演示文稿。 这些笔记本提供了一种执行代码的方法,并提供了丰富的 Markdown 功能来注释和描述应用中多个点的执行。 这些可用于创建非常有效的可执行演示文稿,这些演示文稿在视觉上富含代码段,样式化文本和图形。
我们将在第 2 章,“运行 Pandas”中简要介绍 Jupyter 笔记本。
复现
研究的一项重要内容是共享并使研究可重现。 人们常说,如果其他研究人员无法复制您的实验和结果,那么您就不会证明任何事情。
幸运的是,对于您来说,通过使用 Pandas 和 Python,您将可以轻松地使分析具有可重复性。 这可以通过共享驱动 Pandas 代码的 Python 代码以及数据来完成。
Jupyter 笔记本还提供了一种方便的方式来打包代码和应用程序,并且可以通过安装 Jupyter 笔记本与其他任何人轻松共享。 互联网上有许多免费且安全的共享站点,可让您创建或部署 Jupyter 笔记本进行共享。
关于迭代和敏捷的说明
关于数据操作,分析和科学的非常重要的一点是,它是一个迭代过程。 尽管在前面讨论的阶段中存在自然的前进流程,但是您最终将在此过程中前进和后退。 例如,在探索阶段,您可以识别与准备阶段中与数据纯度问题相关的数据异常,并且需要返回并纠正这些问题。
这是过程乐趣的一部分。 您正在冒险解决最初的问题,同时获得有关正在使用的数据的渐进洞察力。 这些见解可能会导致您提出新问题,更确切的问题,或者意识到您的最初问题不是需要提出的实际问题。 这个过程确实是一个旅程,不一定是目的地。
书和过程的联系
下面提供了该过程中各个步骤的快速映射,您可以在本书中学习这些步骤。 如果该过程前面的步骤在后面的章节中,请不要担心。 该书将按照逻辑顺序逐步引导您学习 Pandas,并可以从各章中回顾到过程中的相关阶段。
| 流程中的步骤 | 位置 |
|---|---|
| 构想 | 构想是数据科学中的创新过程。 您需要有个主意。 您正在阅读本文的事实符合您的资格,因为您必须要分析某些数据,并希望在将来进行分析。 |
| 检索 | 数据的检索主要在第 9 章“访问数据”中介绍。 |
| 准备 | 数据准备主要在第 10 章“整理数据”中进行介绍,但这也是贯穿本章大部分内容的常见主题。 |
| 探索 | 探索跨越这本书的第 3 章“用序列表示单变量数据”,直到第 15 章“历史股价分析”。 但是,最需要探讨的章节是第 14 章“可视化”和第 15 章“历史股价分析”, 开始看到数据分析的结果。 |
| 建模 | 建模的重点是第 3 章和“使用 Pandas 序列表示单变量数据”,第 4 章“用数据帧表示表格和多元数据”,第 11 章“组合,关联和重塑数据”,第 13 章“时间序列建模”,以及专门针对金融的第 15 章“历史股价分析”。 |
| 演示 | 演示是第 14 章“可视化”的主要目的。 |
| 复现 | 复现的内容贯穿全书,例如 Jupyter 笔记本提供的示例。 通过在笔记本上工作,默认情况下,您将使用复现工具,并且能够以各种方式共享笔记本。 |
Pandas 之旅中的数据和分析概念
在学习 Pandas 和数据分析时,您会遇到许多关于数据,建模和分析的概念。 让我们研究其中的一些概念以及它们与 Pandas 的关系。
数据类型
在野外使用数据时,您会遇到几大类数据,这些数据需要被强制转换为 Pandas 数据结构。 了解它们非常重要,因为每种类型所需的工具会有所不同。
pandas 本质上用于处理结构化数据,但提供了多种工具来促进将非结构化数据转换为我们可以操纵的手段。
结构化
结构化数据是在记录或文件中组织为固定字段的任何类型的数据,例如关系数据库和电子表格中的数据。 结构化数据取决于数据模型,数据模型是数据的定义组织和含义以及通常应如何处理数据。 这包括指定数据的类型(整数,浮点数,字符串等),以及对数据的任何限制,例如字符数,最大值和最小值或对一组特定值的限制。
结构化数据是 Pandas 设计要利用的数据类型。 正如我们将首先使用Series然后使用DataFrame所看到的那样,pandas 将结构化数据组织为一个或多个数据列,每个列都是一个特定的数据类型,然后是零个或多个数据行的序列。
非结构化
非结构化数据是没有任何已定义组织的数据,并且这些数据不会特别分解为特定类型的严格定义的列。 这可以包含许多类型的信息,例如照片和图形图像,视频,流式传感器数据,网页,PDF 文件,PowerPoint 演示文稿,电子邮件,博客条目,Wiki 和文字处理文档。
Pandas 不能直接处理非结构化数据,但它提供了许多从非结构化源中提取结构化数据的功能。 作为我们将研究的特定示例,pandas 具有检索网页并将特定内容提取到DataFrame中的工具。
半结构化
半结构化数据适合非结构化数据。 可以将其视为一种结构化数据,但是缺乏严格的数据模型结构。 JSON 是半结构化数据的一种形式。 好的 JSON 具有已定义的格式,但是没有始终严格执行的特定数据架构。 在大多数情况下,数据将处于可重复模式,可以轻松转换为结构化数据类型,例如 pandas DataFrame,但是过程可能需要您提供一些指导以指定或强制数据类型。
变量
在对 Pandas 进行数据建模时,我们将对一个或多个变量进行建模,并寻找值之间或多个变量之间的统计意义。 变量的定义不是编程语言中的变量,而是统计变量之一。
变量是可以测量或计数的任何特征,数量或数量。 变量之所以如此命名,是因为值在总体中的数据单元之间可能会有所不同,并且值可能会随时间变化。 股票价值,年龄,性别,营业收入和支出,出生国家,资本支出,班级等级,眼睛颜色和车辆类型是变量的示例。
使用 Pandas 时,我们会遇到几种广泛的统计变量类型:
- 类别
- 连续
- 离散类别
类别
类别变量是可以采用有限数量(通常是固定数量)的可能值之一的变量。 每个可能的值通常称为水平。 Pandas 中的类别变量用Categoricals表示,这是一种 Pandas 数据类型,与统计中的类别变量相对应。 类别变量的示例是性别,社会阶层,血型,国家/地区,观察时间或等级(例如李克特量表)。
连续
连续变量是一个可以接受无限多个(不可数数量)值的变量。 观察值可以取某个实数集之间的任何值。 连续变量的示例包括高度,时间和温度。 Pandas 中的连续变量用浮点或整数类型(Python 原生)表示,通常在表示特定变量多次采样的集合中表示。
离散
离散变量是一个变量,其中的值基于一组不同的整体值的计数。 离散变量不能是任何两个变量之间的分数。 离散变量的示例包括注册汽车的数量,营业地点的数量和一个家庭中的孩子数量,所有这些都测量整个单位(例如 1、2 或 3 个孩子)。 离散变量通常在 Pandas 中用整数表示(或偶尔用浮点数表示),通常也用两个或多个变量采样集合表示。
时间序列数据
时间序列数据是 Pandas 中的一等实体。 时间为 Pandas 内的变量样本增加了重要的额外维度。 通常,变量与采样时间无关。 也就是说,采样时间并不重要。 但是在很多情况下都是这样。 时间序列在特定的时间间隔形成离散变量的样本,其中观测值具有自然的时间顺序。
时间序列的随机模型通常会反映这样一个事实,即时间上接近的观察比远处的观察更紧密相关。 时间序列模型通常会利用时间的自然单向排序,以便将给定时间段的值表示为以某种方式从过去的值而不是从将来的值中得出。
Pandas 的常见情况是财务数据,其中变量代表股票的价值,因为它在一天中的固定时间间隔内发生变化。 我们通常希望确定特定时间间隔内价格变化率的变化。 我们可能还需要关联特定时间间隔内多只股票的价格。
这是 Pandas 的一项重要而强大的功能,因此我们将花费整整一章来研究这一概念。
分析和统计的一般概念
在本文中,我们将仅探讨统计学的外围和数据分析的技术过程。 但是值得注意的是一些分析概念,其中一些是在 Pandas 内部直接创建的实现。 其他人则需要依赖其他库,例如 SciPy,但是在与 Pandas 一起工作时您可能也会遇到它们,因此大声疾呼非常有价值。
定量与定性数据/分析
定性分析是对可以观察但无法测量的数据的科学研究。 它着重于对数据质量进行分类。 定性数据的示例可以是:
- 你的皮肤柔软
- 某人的跑步优雅
定量分析是研究数据中的实际值,并以数据形式对项目进行实际测量。 通常,这些值为:
- 数量
- 价格
- 高度
Pandas 主要处理定量数据,为您提供表示变量观测值的广泛工具。 Pandas 不提供定性分析,但可以让您代表定性信息。
单变量和多变量分析
从某种角度看,统计是研究变量的实践,尤其是对那些变量的观察。 许多统计信息都是基于对单个变量的分析得出的,这称为单变量分析。 单变量分析是分析数据的最简单形式。 它不处理原因或关系,通常用于描述或聚合数据以及在其中查找模式。
多元分析是一种建模技术,其中存在两个或多个影响实验结果的输出变量。 多变量分析通常与诸如相关性和回归之类的概念相关,这有助于我们理解多个变量之间的关系以及这些关系如何影响结果。
Pandas 主要提供基本的单变量分析功能。 这些功能通常是描述性统计数据,尽管对诸如关联的概念有内在的支持(因为它们在金融和其他领域非常普遍)。
可以使用 StatsModels 执行其他更复杂的统计信息。 同样,这本身并不是 Pandas 的弱点,而是一个特殊的设计决定,让这些概念由其他专用的 Python 库处理。
描述性统计
描述性统计信息是聚合给定数据集的函数,通常该数据集表示单个变量(单变量数据)的总体或样本。 他们描述了集中趋势的数据集和形式度量,以及变异性和分散性的度量。
例如,以下是描述性统计信息:
- 分布(例如,正态,泊松)
- 集中趋势(例如,均值,中位数和众数)
- 离散度(例如,方差,标准差)
正如我们将看到的,Pandas Series和DataFrame对象集成了对大量描述性统计信息的支持。
推断统计
推断统计与描述性统计的不同之处在于,推断统计试图从数据推断得出结论,而不是简单地对其进行概括。 推断统计的示例包括:
- T 检验
- 卡方
- 方差分析
- 自举
这些推理技术通常从 Pandas 推迟到其他工具,例如 SciPy 和 StatsModels。
随机模型
随机模型是一种统计建模的形式,包括一个或多个随机变量,通常包括使用时间序列数据。 随机模型的目的是估计结果在特定预测范围内的机会,以预测不同情况的条件。
随机建模的一个例子是蒙特卡洛模拟。 蒙特卡罗模拟通常用于金融投资组合评估,它是基于对市场中投资组合的重复模拟来模拟投资组合的表现,该模拟受各种因素和成分股收益的内在概率分布的影响。
Pandas 为我们提供了DataFrame中随机模型的基本数据结构,通常使用时间序列数据来建立和运行随机模型。 尽管可以使用 pandas 和 Python 编写自己的随机模型和分析代码,但在许多情况下,存在特定领域的库(例如 PyMC)可以简化此类建模。
概率与贝叶斯统计
贝叶斯统计是一种从贝叶斯定理(一种基于简单概率公理构建的数学方程式)派生出来的统计推断方法。 它使分析师可以计算任何感兴趣的条件概率。 条件概率就是事件 B 发生时事件 A 的概率。
因此,就概率而言,数据事件已经发生并已被收集(因为我们知道概率)。 通过使用贝叶斯定理,我们便可以计算已观察到的数据给定或以其为条件的各种感兴趣的事物的概率。
贝叶斯建模超出了本书的范围,但是再次使用 Pandas 很好地处理了基础数据模型,然后使用诸如 PyMC 之类的库进行了实际分析。
相关性
相关性是最常见的统计数据之一,直接建立在 Pandas DataFrame中。 相关性是一个单一数字,描述两个变量之间的关系程度,尤其是描述这些变量的两个观测序列之间的关系程度。
使用相关性的一个常见示例是确定随着时间的推移,两只股票的价格彼此密切相关的程度。 如果变化密切,则两个股票之间的相关性很高,如果没有可辨别的格局,则它们之间是不相关的。 这是有价值的信息,可以在许多投资策略中使用。
两只股票的相关程度也可能随整个数据集的时间范围以及间隔而略有变化。 幸运的是,Pandas 具有强大的功能,可让我们轻松更改这些参数并重新运行关联。 本书稍后将在几个地方介绍相关性。
回归
回归是一种统计量度,用于估计因变量和一些其他变量之间的关系强度。 它可以用来了解变量之间的关系。 财务方面的一个例子是理解商品价格与从事这些商品交易的企业股票之间的关系。
最初有一个直接建立在 Pandas 中的回归模型,但是已经移到 StatsModels 库中。 这显示了 Pandas 常见的模式。 Pandas 通常会内置一些概念,但是随着它们的成熟,它们被认为最有效地适合其他 Python 库。 这是好是坏。 最初直接在 pandas 中使用它是很棒的,但是当您升级到新版本的 pandas 时,它可能会破坏您的代码!
其他兼容 Pandas 的 Python 库
Pandas 是 Python 内数据分析和数据科学生态系统的一个很小但重要的组成部分。 作为参考,这里还有一些其他值得注意的重要 Python 库。 该列表并不详尽,但概述了您可能会遇到的几个问题。
数值和科学计算 – NumPy 和 SciPy
NumPy 是使用 Python 进行科学计算的基础工具箱,并且包含在大多数现代 Python 发行版中 。 实际上,它是构建 Pandas 的基础工具箱,使用 Pandas 时,您几乎肯定会经常使用它。 NumPy 提供了对多维数组的支持,这些数组具有基本的运算和有用的线性代数函数。
NumPy 的数组功能的使用与 Pandas 特别是 Pandas Series对象紧密相关。 我们的大多数示例都将引用 NumPy,但是 pandas Series函数是 NumPy 数组的紧密超集,因此除少数简要情况外,我们将不深入研究 NumPy 的细节。
SciPy 提供了数值算法和特定领域工具箱的集合,包括信号处理,优化,统计, 以及更多。
统计分析 – StatsModels
StatsModels 是一个 Python 模块,允许用户浏览数据,估计统计模型和执行统计测试 。 描述性统计信息,统计检验,绘图函数和结果统计信息的广泛列表适用于不同类型的数据和每个估计量。 跨领域的研究人员可能会发现 StatsModels 完全满足了他们在 Python 中进行统计计算和数据分析的需求。
功能包括:
- 线性回归模型
- 广义线性模型
- 离散选择模型
- 稳健的线性模型
- 时间序列分析的许多模型和功能
- 非参数估计
- 作为示例得数据集的集合
- 广泛的统计检验
- 输入输出工具,用于生成多种格式的表格(文本,LaTex,HTML)以及将 Stata 文件读入 NumPy 和 Pandas
- 绘图功能
- 广泛的单元测试,来确保结果的正确性
机器学习 – scikit-learn
scikit-learn 是一种由 NumPy,SciPy 和 matplotlib 构建的机器学习库。 它为数据分析中的常见任务提供了简单有效的工具,例如分类,回归,聚类,降维,模型选择和预处理。
PyMC – 随机贝叶斯建模
PyMC 是一个 Python 模块,实现了贝叶斯统计模型和拟合算法,包括马尔可夫链蒙特卡洛。 它的灵活性和可扩展性使其适用于许多问题。 除核心采样功能外,PyMC 还包括用于聚合输出,绘图,拟合优度和收敛性诊断的方法。
数据可视化 – Matplotlib 和 Seaborn
Python 有一套丰富的数据可视化框架。 最受欢迎的两个是 matplotlib 和更新的 seaborn 。
Matplotlib
Matplotlib 是一个 Python 2D 绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版物质量的图形。 Matplotlib 可以在 Python 脚本,Python 和 IPython shell,Jupyter 笔记本,Web 应用服务器以及四个图形用户界面工具包中使用。
pandas 包含与 matplotlib 的紧密集成,包括作为Series和DataFrame对象的一部分的功能,这些功能会自动调用 matplotlib。 这并不意味着 Pandas 只限于 matplotlib。 正如我们将看到的,可以很容易地将其更改为 ggplot2 和 seaborn 等其他名称。
Seaborn
Seaborn 是一个用于在 Python 中制作引人入胜且内容丰富的统计图形的库。 它基于 matplotlib 构建,并与 PyData 栈紧密集成,包括对 NumPy 和 pandas 数据结构的支持以及 SciPy 和 StatsModels 的统计例程。 它提供了超越 matplotlib 的其他功能,并且默认情况下还展示了比 matplotlib 更丰富,更现代的视觉样式。
总结
在本章中,我们浏览了 Pandas 的工作方式和原因,数据处理/分析和科学。 首先概述了 Pandas 的存在,Pandas 所包含的功能以及它与数据处理,分析和数据科学的概念之间的关系。
然后,我们介绍了数据分析过程,以建立一个框架,说明为什么 Pandas 中存在某些功能。 其中包括检索数据,组织和清理数据,进行探索,然后建立正式模型,展示您的发现以及能够共享和重现分析。
接下来,我们介绍了数据和统计建模中涉及的几个概念。 其中包括涵盖许多常见的分析技术和概念,以便向您介绍这些技术和概念,并在后续各章中对其进行更详细的探讨时使您更加熟悉。
Pandas 还是较大的 Python 库生态系统的一部分,可用于数据分析和科学。 虽然本书仅着眼于 Pandas,但您会遇到其他图书馆,并且已经介绍了它们,因此在它们长大时会很熟悉它们。
我们准备开始使用 Pandas 了。 在下一章中,我们将开始学习 Pandas,从获取 Python 和 Pandas 环境开始,对 Jupyter 笔记本进行概述,然后在深入研究 Pandas Series和DataFrame对象之前对其进行快速介绍。 Pandas 后续元素的深度更大。
二、启动和运行 Pandas
在本章中,我们将介绍如何安装 Pandas 并开始使用其基本功能。 本书的内容以 IPython 和 Jupyter 笔记本的形式提供,因此,我们还将快速使用这两种工具。
本书将利用 Continuum 的 Anaconda 科学 Python 发行版。 Anaconda 是流行的 Python 发行版,其中包含免费和付费组件。 Anaconda 提供了跨平台支持,包括 Windows,Mac 和 Linux。 Anaconda 的基本发行版安装了 Pandas,IPython 和 Jupyter 笔记本,因此入门非常简单。
本章将涵盖以下主题:
- 安装 Anaconda,Pandas 和 IPython/Jupyter 笔记本
- 使用 IPython 和 Jupyter 笔记本
- Jupyter 及其笔记本
- 设置您的 Pandas 环境
- Pandas
Series和DataFrame快速入门 - 从 CSV 文件加载数据
- 生成 Pandas 数据的可视化
Anaconda 的安装
本书将使用 Anaconda Python 版本 3,特别是 3.6.1。 在撰写本文时,Pandas 的版本为 0.20.2。 默认情况下,Anaconda 安装程序将安装 Python,IPython,Jupyter 笔记本和 pandas。
可以从 Continuum Analytics 网站下载 Anaconda Python。 Web 服务器将识别您的浏览器的操作系统,并为您提供该平台的相应软件下载文件。
在浏览器中打开此 URL 时,将看到一个类似于以下内容的页面:

单击适合您平台的安装程序的链接。 这将为您提供类似于以下内容的下载页面:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-27cyNlu7-1681365384091)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00007.jpeg)]
下载 3.x 安装程序。 本书将使用的当前版本的 Anaconda 是 4.3.1,带有 Python 3.6.1:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BPyvSL8c-1681365384092)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00008.jpeg)]
这种情况经常发生变化,到您阅读本文时,它可能已经发生变化。
执行适合您平台的安装程序,完成后,打开命令行或终端并执行python命令。 您应该看到类似于以下内容(在 Mac 上是这样):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OdwG9uMR-1681365384092)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00009.jpeg)]
您可以通过发出exit()语句退出 Python 解释器:

在终端或命令行中,您可以使用pip show pandas命令验证 Pandas 的安装版本:

已安装的当前版本被验证为 0.20.2。 请确保您使用的是 0.20.2 或更高版本,因为将使用此版本特定于 Pandas 的更改。
现在,我们已经安装了所需的一切,让我们继续使用 IPython 和 Jupyter 笔记本。
IPython 和 Jupyter 笔记本
到目前为止,我们已经从命令行或终端执行了 Python。 这是 Python 随附的默认读取-求值-打印-循环(REPL)。 这可以用来运行本书中的所有示例,但是本书将使用 IPython 编写文本和代码包 Jupyter 笔记本中的语句。 让我们简要地看一下两者。
IPython
IPython 是用于与 Python 交互工作的备用 Shell。 它对 Python 提供的默认 REPL 进行了一些增强。
如果您想更详细地了解 IPython,请查看文档。
要启动 IPython,只需从命令行/终端执行ipython命令。 启动时,您将看到类似以下内容:

输入提示显示In [1]:。 每次在 IPython REPL 中输入一条语句时,提示中的数字都会增加。
同样,您输入的任何特定条目的输出都将以Out [x]:开头,其中x与相应的In [x]:的编号匹配。 以下屏幕截图演示了这一点:

in和out语句的编号对于示例很重要,因为所有示例都将以In [x]:和Out [x]:开头,以便您可以继续学习。
请注意,这些数字纯粹是连续的。 如果您遵循文本中的代码,并且输入中发生错误,或者输入其他语句,则编号可能会不正确(可以通过退出并重新启动 IPython 来重新设置编号)。 请纯粹将它们用作参考。
Jupyter 笔记本
Jupyter 笔记本是 IPython 笔记本的演变。 它是一个开源 Web 应用,使您可以创建和共享包含实时代码,方程式,可视化和减价的文档。
最初的 IPython 笔记本仅限于 Python。 Jupyter 笔记本已发展为允许使用多种编程语言,包括 Python,R,Julia,Scala 和 F#。
如果您想更深入地了解 Jupyter 笔记本,请访问该页面,在该页面上将显示类似于以下内容的页面:

Jupyter 笔记本可以独立于 Python 下载和使用。 Anaconda 默认安装。 要启动 Jupyter 笔记本,请在命令行或终端上发出以下命令:
$ Jupyter 笔记本
- 1
- 2
为了演示,让我们看一下如何运行文本附带的示例代码。 从 Packt 网站下载代码,然后将文件解压缩到您选择的目录中。 在目录中,您将看到类似于以下内容的以下内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Kd4PQj6l-1681365384094)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00015.jpeg)]
现在发出jupyter notebook命令。 您应该看到类似于以下内容:

将打开一个浏览器页面,显示 Jupyter 笔记本主页,即http://localhost:8888/tree。 这将打开一个显示该页面的 Web 浏览器窗口,该窗口将是类似于以下内容的目录列表:
单击.ipynb链接可打开笔记本页面。 如果打开本章的笔记本,您将看到类似于以下内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Co5cCa9C-1681365384095)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00018.jpeg)]
显示的笔记本是 Jupyter 和 IPython 生成的 HTML。 它由许多单元格组成,可以是四种类型之一:代码,Markdown,原始 nbconvert 或标题。 本书中的所有示例均使用代码或减价单元。
Jupyter 为每个笔记本运行一个 IPython 内核。 包含 Python 代码的单元在该内核中执行,结果作为 HTML 添加到笔记本中。
双击任何单元格将使该单元格可编辑。 编辑完单元格的内容后,按Shift + Enter,此时 Jupyter/IPython 将求值内容并显示结果。
如果您想进一步了解构成页面基础的笔记本格式,请参阅这里。
笔记本顶部的工具栏为您提供了许多操作笔记本的功能。 其中包括在笔记本中上下移动,增加和删除单元格。 还提供用于运行单元,重新运行单元以及重新启动基础 IPython 内核的命令。
要创建一个新笔记本,请转到“新笔记本 -> Python3”:
将在新的浏览器选项卡中创建一个新的笔记本页面。 其名称将为无标题:

笔记本包含一个准备好输入 Python 的代码单元。 在单元格中输入1 + 1并按Shift + Enter执行。

该单元已执行,结果显示为Out [1]:。 Jupyter 还打开了一个新单元,供您输入更多代码或减价。
Jupyter 笔记本会每分钟自动保存您的更改,但是偶尔一次手动保存仍然是一件好事。
Pandas 序列和数据帧简介
让我们开始使用一些 Pandas,并简要介绍一下 Pandas 的两个主要数据结构Series和DataFrame。 我们将检查以下内容:
- 将 Pandas 导入您的应用
- 创建和操纵 Pandas
Series - 创建和操纵 Pandas
DataFrame - 将数据从文件加载到
DataFrame
导入 Pandas
我们将使用的每个笔记本都首先导入 Pandas 和其他几个有用的 Python 库。 它还将设置几个选项来控制 Pandas 如何在 Jupyter 笔记本中渲染输出。 该代码包含以下内容:
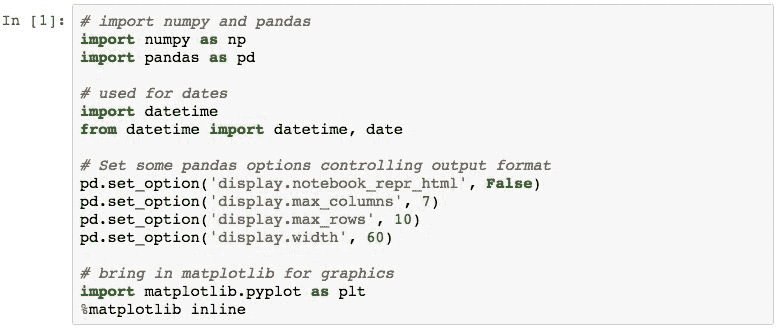
第一条语句导入 NumPy 并将库中的项目引用为np.。 在本书中,我们不会对 NumPy 进行详细介绍,但有时需要使用。
第二次导入使 Pandas 可用于笔记本。 我们将使用pd.前缀引用库中的项目。 from pandas import Series, DataFrame语句将Series和DataFrame对象显式导入到全局名称空间中。 这使我们可以在没有pd的情况下引用Series和DataFrame。 字首。 这很方便,因为我们会经常使用它们,这样可以节省很多键入时间。
import datetime语句引入了datetime库,该库通常在 Pandas 中用于时间序列数据。 它将包括在每个笔记本的导入中。
pd.set_option()函数调用设置选项,这些选项通知笔记本如何显示 Pandas 的输出。 第一个告诉状态将Series和DataFrame输出呈现为文本而不是 HTML。 接下来的两行指定要输出的最大列数和行数。 final 选项设置每行中输出的最大字符数。
敏锐的眼睛可能会注意到此单元格没有Out [x]:。 并非所有单元(或 IPython 语句)都会生成输出。
如果您希望使用 IPython 代替 Jupyter 笔记本进行后续操作,则还可以在 IPython Shell 中执行此代码。 例如,您可以简单地从笔记本单元中剪切并粘贴代码。 这样做可能如下所示:

IPython shell 足够聪明,可以知道您要插入多行并且会适当缩进。 并且请注意,在 IPython shell 中也没有Out [x]:。 pd.set_option不返回任何内容,因此没有注释。
Pandas 序列
Pandas Series是 Pandas 的基本数据结构。 序列与 NumPy 数组相似,但是它的不同之处在于具有索引,该索引允许对项目进行更丰富的查找,而不仅仅是从零开始的数组索引值。
以下从 Python 列表创建一个序列。:
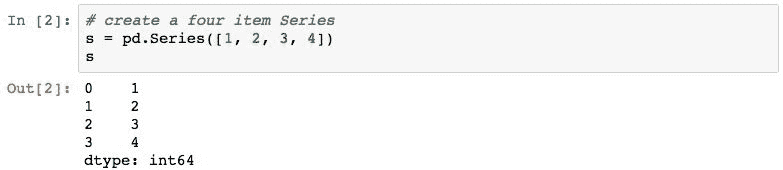
输出包括两列信息。 第一个是索引,第二个是Series中的数据。 输出的每一行代表索引标签(在第一列中),然后代表与该标签关联的值。
由于创建此Series时未指定索引(接下来将要执行的操作),因此 pandas 自动创建一个整数索引,该索引的标签从 0 开始,对于每个数据项加 1。
然后,可以使用[]运算符访问Series对象的值,并传递所需值的标签。 以下内容获取标签1的值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HG0BAi21-1681365384097)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00025.jpeg)]
这看起来很像许多编程语言中的常规数组访问。 但是,正如我们将看到的那样,索引不必从 0 开始,也不必递增 1,并且可以是许多数据类型,而不仅仅是整数。 以这种方式关联灵活索引的能力是 Pandas 的巨大超级能力之一。
通过在 Python 列表中指定它们的标签,可以检索多个项目。 以下内容检索标签1和3上的值:

通过使用index参数并指定索引标签,可以使用用户定义的索引创建Series对象。 下面的代码创建一个Series,其值相同,但索引由字符串值组成:

现在,那些字母数字索引标签可以访问Series对象中的数据。 以下内容检索索引标签'a'和'd'上的值:

仍然可以通过基于[0]的数字位置引用此Series对象的元素。 :
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HG6awP3G-1681365384098)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00029.jpeg)]
我们可以使用.index属性检查Series的索引:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oOZrR0x4-1681365384099)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00030.jpeg)]
索引实际上是一个 Pandas 对象,此输出向我们显示了索引的值和用于索引的数据类型。 在这种情况下,请注意索引中的数据类型(称为dtype)是对象而不是字符串。 我们将在本书的后面部分研究如何更改此设置。
Series在 Pandas 中的常见用法是表示将日期/时间索引标签与值相关联的时间序列。 下面通过使用pd.date_range() pandas 函数创建日期范围来说明这一点:

这在 Pandas 中创建了一个称为DatetimeIndex的特殊索引,这是一种特殊的 Pandas 索引,经过优化可对带有日期和时间的数据进行索引。
现在,让我们使用该索引创建一个Series。 数据值表示特定日期的高温:

这种带有DateTimeIndex的序列称为时间序列。
我们可以使用日期作为字符串来查询特定数据的温度:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NAXvU2VK-1681365384100)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00033.jpeg)]
两个Series对象可以通过算术运算相互应用。 以下代码创建第二个Series并计算两者之间的温度差:

对两个非标量值的Series对象进行算术运算(+,-,/,*,…)的结果将返回另一个Series对象。
由于索引不是整数,因此我们还可以通过从 0 开始的值来查找值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ADSr7tHN-1681365384100)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00035.jpeg)]
最后,Pandas 提供了许多描述性的统计方法。 例如,以下内容返回温度差的平均值:

Pandas 数据帧
Pandas Series只能与每个索引标签关联一个值。 要使每个索引标签具有多个值,我们可以使用一个数据帧。 一个数据帧代表一个或多个按索引标签对齐的Series对象。 每个序列将是数据帧中的一列,并且每个列都可以具有关联的名称。
从某种意义上讲,数据帧类似于关系数据库表,因为它包含一个或多个异构类型的数据列(但对于每个相应列中的所有项目而言都是单一类型)。
以下创建带有两列的DataFrame对象,并使用温度Series对象:
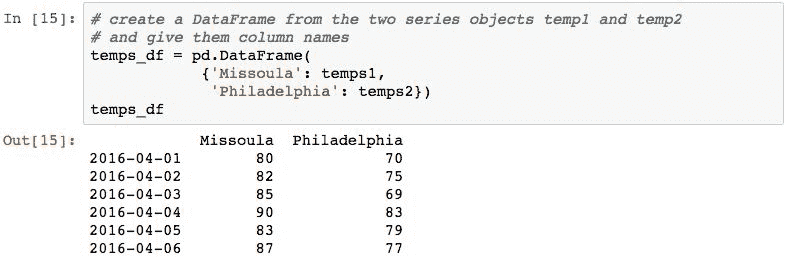
产生的数据帧有两列,分别为Missoula和Philadelphia。 这些列是数据帧中包含的新Series对象,具有从原始Series对象复制的值。
可以使用带有列名或列名列表的数组索引器[]访问DataFrame对象中的列。 以下代码检索Missoula列:

下面的代码检索Philadelphia列:

列名称的 Python 列表也可以用于返回多个列:

与Series对象相比,DataFrame对象存在细微的差异。 将列表传递给DataFrame的[]运算符将检索指定的列,而Series将返回行。
如果列名没有空格,则可以使用属性样式进行访问:

数据帧中各列之间的算术运算与多个Series上的算术运算相同。 为了演示,以下代码使用属性表示法计算温度之间的差异:

只需通过使用数组索引器[]表示法将另一Series分配给一列即可将新列添加到DataFrame。 以下内容在DataFrame中添加了带有温度差的新列:

可通过.columns属性访问DataFrame中的列名:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F9ms9LNW-1681365384103)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00044.jpeg)]
可以切片DataFrame和Series对象以检索特定的行。 以下是第二到第四行温度差值的切片:

可以使用.loc和.iloc属性检索数据帧的整个行。 .loc确保按索引标签查找,其中.iloc使用从 0 开始的位置。
以下内容检索数据帧的第二行:

请注意,此结果已将行转换为Series,数据帧的列名称已透视到结果Series的索引标签中。 下面显示了结果的结果索引:

可以使用.loc属性通过索引标签显式访问行。 以下代码通过索引标签检索一行:

可以使用整数位置列表选择DataFrame对象中的特定行。 以下从Difference列的整数位置1,3和5的行中选择值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bKuuTASK-1681365384104)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00049.jpeg)]
可以基于应用于每行中数据的逻辑表达式来选择数据帧的行。 以下显示Missoula列中大于82度的值:

然后可以将表达式的结果应用于数据帧(和序列)的[]运算符,这仅导致返回求值为True的表达式的行:

该技术在 pandas 术语中称为布尔选择,它将构成基于特定列中的值选择行的基础(例如在 SQL 中使用WHERE子句的查询 – 但我们将看到它更强大)。
将文件中的数据加载到数据帧中
Pandas 库提供了方便地从各种数据源中检索数据作为 Pandas 对象的工具。 作为一个简单的例子,让我们研究一下 Pandas 以 CSV 格式加载数据的能力。
本示例将使用随本书的代码data/goog.csv提供的文件,该文件的内容表示 Google 股票的时间序列财务信息。
以下语句使用操作系统(从 Jupyter 笔记本或 IPython 内部)显示此文件的内容。 您将需要使用哪个命令取决于您的操作系统:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kFCoIdmx-1681365384105)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00052.jpeg)]
可以使用pd.read_csv()函数将这些信息轻松导入DataFrame:
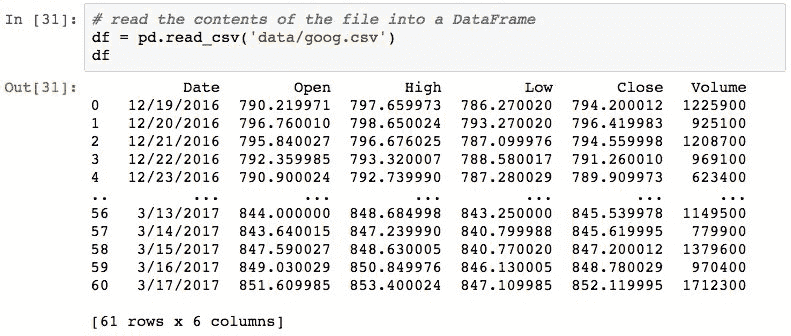
pandas 不知道文件中的第一列是日期,并且已将Date字段的内容视为字符串。 可以使用以下 pandas 语句对此进行验证,该语句以字符串形式显示Date列的类型:
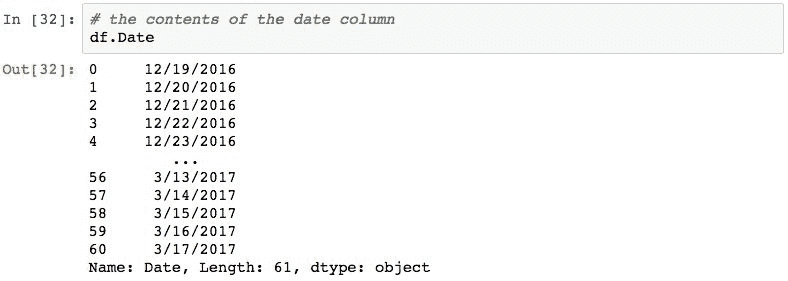 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mk7MyUHK-1681365384105)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00055.jpeg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mk7MyUHK-1681365384105)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00055.jpeg)] 
the pd.read_csv()函数的parse_dates参数可指导 Pandas 如何将数据直接转换为 Pandas 日期对象。 以下通知 Pandas 将Date列的内容转换为实际的TimeStamp对象:

如果我们检查它是否有效,我们会看到日期为Timestamp:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FfC9bUS0-1681365384106)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00058.jpeg)]
不幸的是,这没有使用日期字段作为数据帧的索引。 而是使用默认的从零开始的整数索引标签:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ga8FnoUt-1681365384106)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00059.jpeg)]
请注意,这现在是RangeIndex,在以前的 Pandas 版本中,它应该是整数索引。 我们将在本书的后面部分探讨这种差异。
可以使用pd.read_csv()函数的index_col参数将其固定,以指定应将文件中的哪一列用作索引:
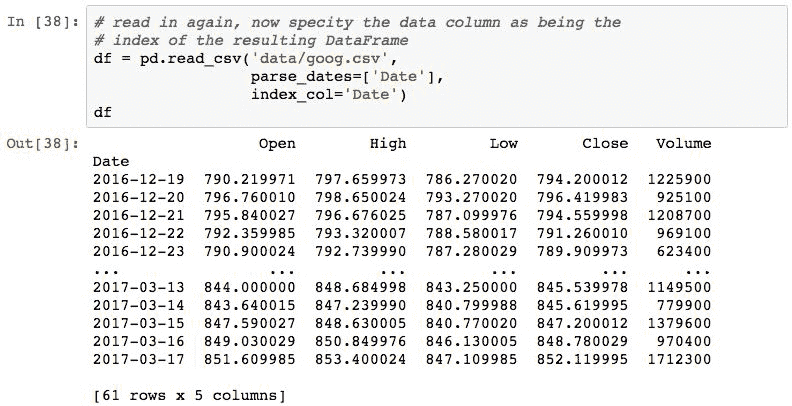
现在索引是DateTimeIndex,它使我们可以使用日期查找行。

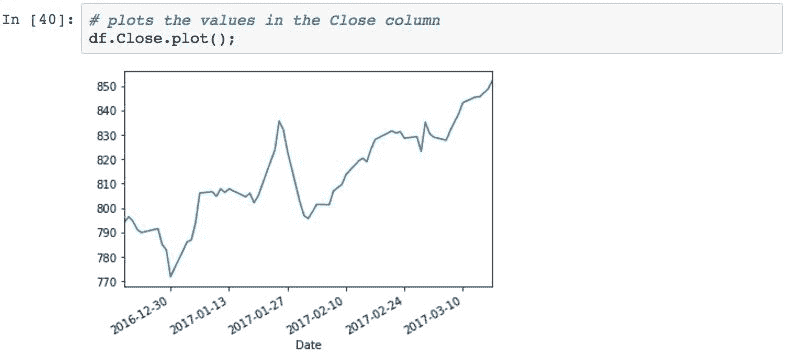
可视化
我们将在第 14 章“可视化”中深入研究可视化,但是在此之前,我们偶尔会对 Pandas 中的数据进行快速可视化。 使用 Pandas 创建数据可视化非常简单。 所有需要做的就是调用.plot()方法。 下面通过绘制股票数据的Close值进行演示:
总结
在本章中,我们安装了 Python 的 Anaconda Scientific 版本。 这还将安装 pandas 和 Jupyter 笔记本,为您设置执行数据处理和分析的环境,并创建用于可视化,呈现和共享分析的笔记本。
我们还对 Pandas Series和DataFrame对象进行了介绍,展示了一些基本功能。 该博览会向您展示了如何执行一些基本操作,以便在深入学习所有细节之前可以用来启动和运行 Pandas。
在接下来的几章中,我们将深入研究Series和DataFrame的操作,下一章将重点介绍Series。
三、用序列表示单变量数据
Series是 Pandas 的主要构建基块。 它表示单个数据类型的一维类似于数组的值集。 它通常用于为单个变量的零个或多个测量建模。 尽管它看起来像数组,但Series具有关联的索引,该索引可用于基于标签执行非常有效的值检索。
Series还会自动执行自身与其他 Pandas 对象之间的数据对齐。 对齐是 Pandas 的一项核心功能,其中数据是在执行任何操作之前按标签值匹配的多个 Pandas 对象。 这允许简单地应用操作,而无需显式地编码连接。
在本章中,我们将研究如何使用Series为变量的测量建模,包括使用索引来检索样本。 这项检查将概述与索引标签,切片和查询数据,对齐和重新索引数据有关的几种模式。
具体而言,在本章中,我们将涵盖以下主题:
- 使用 Python 列表,字典,NumPy 函数和标量值创建序列
- 访问
Series的索引和值属性 - 确定
Series对象的大小和形状 - 在创建
Series时指定索引 - 使用
head,tail和take访问值 - 通过索引标签和位置查找值
- 切片和常用切片模式
- 通过索引标签来对齐
- 执行布尔选择
- 重新索引
Series - 原地修改值
配置 Pandas
我们使用以下导入和配置语句开始本章中的示例:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AdkSyCZA-1681365384108)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00063.jpeg)]
创建序列
可以使用多种技术创建Series。 我们将研究以下三个:
- 使用 Python 列表或字典
- 使用 NumPy 数组
- 使用标量值
使用 Python 列表和字典创建序列
可以从 Python 列表中创建Series:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8R8GnSwO-1681365384108)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00064.jpeg)]
数字的第一列表示Series索引中的标签。 第二列包含值。 dtype: int64表示Series中值的数据类型为int64。
默认情况下,Pandas 会创建一个索引,该索引由0开始的连续整数组成。 这使该序列看起来像许多其他编程语言中的数组。 例如,我们可以在label 3处查找值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N1jBqtiL-1681365384108)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00065.jpeg)]
该查找是通过标签值而不是从 0 开始的位置进行的。 我们将在本章后面详细研究。
可以使用非整数的数据类型。 以下创建字符串值的序列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8615Z3i0-1681365384108)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00066.jpeg)]
要创建由n个相同值v的序列组成的序列,请使用 Python 速记表创建[v]*n。 以下创建2的五个值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yC25BEPu-1681365384109)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00067.jpeg)]
下面是一种类似的速记类型,它使用 Python 速记来将每个字符用作列表项:

可以从 Python 字典直接初始化Series。 使用字典时,字典的键用作索引标签:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0bsHvsKk-1681365384109)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00069.jpeg)]
使用 NumPy 函数创建
初始化Series对象的各种 NumPy 函数是一种常见的做法。 例如,以下示例使用 NumPy np.arange函数在4和8之间创建一个整数值序列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B7FJO9Hp-1681365384110)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00070.jpeg)]
np.linspace()方法的功能类似,但是允许我们指定要在两个指定值之间(包括两个值)创建的值的数量,并具有指定的步骤数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FFeiWB01-1681365384110)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00071.jpeg)]
使用np.random.normal()生成一组随机数也是很常见的。 以下从正态分布生成五个随机数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QfgED5yr-1681365384110)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00072.jpeg)]
使用标量值创建
也可以使用标量值创建Series:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7Ddbyoy3-1681365384111)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00073.jpeg)]
Series仅具有单个值,这似乎是简并的情况。 但是,在某些情况下,这很重要,例如,将序列乘以标量值时,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dxY66vpy-1681365384111)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00074.jpeg)]
在封面下,Pandas 取值2并从该标量值创建一个Series,其索引与s中的索引匹配,然后通过对齐两个Series进行乘法。 在本章的后面,我们将再次更详细地查看此示例。
.index和.values属性
每个Series对象均由一些值和一个索引组成。 可以通过.values属性访问这些值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tg8QH9c3-1681365384111)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00075.jpeg)]
结果是一个 NumPy 数组对象,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6DCSvq4L-1681365384112)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00076.jpeg)]
出于信息目的将其称为。 我们不会在本书中研究 NumPy 数组。 从历史上看,Pandas 的确在幕后使用 NumPy 数组,因此 NumPy 数组在过去更为重要,但这种依赖在最近的版本中已被删除。 但为方便起见,即使基础表示形式不是 NumPy 数组,.values也会返回 NumPy 数组。
另外,可以使用.index检索该序列的索引:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pNh7zPdO-1681365384112)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00077.jpeg)]
Pandas 创建的索引类型为RangeIndex。 当不存在这种类型的索引时,这是与本书先前版本相比的 Pandas 更改。 RangeIndex对象代表具有指定step的从start到stop值的值范围。 与以前使用的Int64Index相比,这对 Pandas 是有效的。
RangeIndex只是我们将要探索的一种索引类型(第 6 章“索引数据”中的大部分细节)。
序列的大小和形状
Series对象中的项目数可以通过多种技术来确定,其中第一种是使用 Python len()函数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e6PZKIjU-1681365384112)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00078.jpeg)]
通过使用.size属性可以获得相同的结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KfRMSjkW-1681365384112)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00079.jpeg)]
获取Series大小的另一种形式是使用.shape属性。 这将返回一个二值元组,但仅指定第一个值并表示大小:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dkCQEWsZ-1681365384112)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00080.jpeg)]
在创建时指定索引
可以使用构造器的index参数在创建Series时指定索引中的标签。 下面创建一个Series并将字符串分配给索引的每个标签:

检查.index属性,我们发现创建了以下索引:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-svm7okkz-1681365384113)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00082.jpeg)]
使用这个索引,我们可以问一个类似who is the Dad?的问题:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2ncsktyq-1681365384113)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00083.jpeg)]
.head(),.tail()和.take()
Pandas 提供了.head()和.tail()方法来检查Series中前导(头)或后随(尾)行。 默认情况下,它们返回前五行或后五行,但是可以使用n参数进行更改。
让我们检查以下Series的用法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-89JIhqtp-1681365384113)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00084.jpeg)]
以下内容检索前五行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lzZiHdTt-1681365384114)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00085.jpeg)]
可以使用n参数(或仅通过指定数字)来更改项目数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1ws7nOxa-1681365384114)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00086.jpeg)]
.tail()返回最后五行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NyG2VxdB-1681365384114)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00087.jpeg)]
指定5以外的数字时,其工作原理类似:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ntTbOoEM-1681365384114)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00088.jpeg)]
.take()方法返回指定整数位置的行的序列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cTrb4YNV-1681365384115)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00089.jpeg)]
通过标签或位置检索序列中的值
Series中的值可以通过两种常规方法检索:通过索引标签或从 0 开始的位置。 Pandas 为您提供了多种方法来执行这两种查找。 让我们研究一些常见的技术。
使用[]运算符和.ix[]属性按标签查找
使用[]运算符执行隐式标签查找。 该运算符通常根据给定的索引标签查找值。
让我们从使用以下Series开始:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YwJqJYFg-1681365384115)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00090.jpeg)]
仅使用所需项目的索引标签即可查找单个值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V4f8vx0O-1681365384115)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00091.jpeg)]
使用索引标签列表可以一次检索多个项目:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vZybvmLT-1681365384115)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00092.jpeg)]
我们还可以使用代表位置的整数来查找值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vt09K9kQ-1681365384115)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00093.jpeg)]
这纯粹是因为索引未使用整数标签。 如果将整数传递给[],并且索引具有整数值,则通过将传入的值与整数标签的值进行匹配来执行查找。
这可以使用以下Series进行演示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dYxsRF2V-1681365384116)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00094.jpeg)]
以下内容在标签13和10而非位置13和10处查找值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UJzMeV4H-1681365384116)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00095.jpeg)]
使用[]运算符进行的查找与使用.ix[]属性相同。 但是,自 Pandas 0.20.1 版以来,.ix[]已被弃用。 弃用的原因是由于整数传递给运算符而造成的混乱,以及取决于索引中标签类型的运算差异。
其后果是[]或.ix[]均不可用于查找。 而是使用.loc[]和.iloc[]属性,它们仅按标签或位置明确查找。
使用.iloc[]按位置显式查找
可以使用.iloc[]来按位置查找值。 下面演示使用整数作为参数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s4gJlrhU-1681365384116)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00096.jpeg)]
即使索引具有整数标签,也会按位置查找以下内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vzfSgVbc-1681365384116)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00097.jpeg)]
请注意,如果您指定一个不存在的位置(小于零或大于项目数-一个),则将引发异常。
通过.loc[]通过标签进行显式查找
也可以通过使用.loc[]属性来实现按标签查找:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-24tHAGha-1681365384117)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00098.jpeg)]
使用整数标签没有问题:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8qQOBq8N-1681365384117)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00099.jpeg)]
请注意,当传递不在索引中的索引标签时,.loc[]与.iloc[]具有不同的行为。 在这种情况下,Pandas 将返回NaN值,而不是引发异常:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iZJao7x2-1681365384117)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00100.jpeg)]
什么是NaN? 我们将在本章的后面部分更详细地介绍这一点,但是 pandas 使用它来表示无法通过索引查找找到的缺失数据或数字。 它还对各种统计方法产生了影响,我们还将在本章后面进行研究。
将序列切成子集
Pandas Series支持称为切片的功能。 切片是从 Pandas 对象中检索数据子集的强大方法。 通过切片,我们可以根据位置或索引标签选择数据,并更好地控制产生的项目(正向或反向)和间隔(每一项,彼此)的顺序。
切片会使普通数组[]运算符(以及.loc[],.iloc[]和.ix[])过载,以接受切片对象。 切片对象是使用start:end:step语法创建的,表示第一项,最后一项的组件以及要作为step的各项之间的增量。
切片的每个组件都是可选的,并且通过省略切片说明符的组件,提供了一种方便的方法来选择整个行。
要开始演示切片,我们将使用以下Series:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UQsgJyGs-1681365384118)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00101.jpeg)]
我们可以使用start:end作为切片选择连续的项目。 以下选择Series中位置1至5的五个项目。 由于我们未指定step组件,因此默认为1。 另请注意,结果中不包含end标签:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Pv6YrBCv-1681365384118)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00102.jpeg)]
此结果大致等于以下内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QRTafMEE-1681365384118)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00103.jpeg)]
大致等效,因为对.iloc[]的使用返回源中数据的副本。 切片是对源中数据的引用。 修改所得切片的内容将影响源Series。 我们将在后面的部分中就位修改Series数据,以进一步研究此过程。
通过指定2步骤,切片可以返回所有其他项:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rFnQsQTw-1681365384118)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00104.jpeg)]
如前所述,切片的每个组件都是可选的。 如果省略start组件,则结果将从第一项开始。 例如,以下是.head()的简写:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lmCpTxuv-1681365384119)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00105.jpeg)]
通过指定start组件并省略end,可以选择特定位置及其后的所有项目。 以下选择从4th开始的所有项目:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1cfRiiiC-1681365384119)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00106.jpeg)]
step也可以在之前的两种情况下使用,以跳过项目:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-43hGC12l-1681365384119)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00107.jpeg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vD2e5EGF-1681365384120)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00108.jpeg)]
使用step负值将反转结果。 以下演示了如何反转Series:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JZFw48De-1681365384120)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00109.jpeg)]
值-2将从开始位置返回所有其他项目,并以相反的顺序向Series的开始工作。 下面的示例返回所有其他项目,包括位置4处的行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MVltgwk0-1681365384120)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00110.jpeg)]
切片的start和end的负值具有特殊含义。 -n的start负值表示最后n行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WEVvwgXy-1681365384121)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00111.jpeg)]
-n的end负值将返回除最后n行之外的所有行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k6pYHIhl-1681365384121)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00112.jpeg)]
负start和end分量可以组合使用。 以下内容首先检索最后四行,然后从中检索除最后一行(即前三行)之外的所有行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VkomK3jv-1681365384121)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00113.jpeg)]
也可以对具有非整数索引的序列进行切片。 为了演示,让我们使用以下Series:

使用此Series,对整数值进行切片将根据位置提取项目(如前所述):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oP8AmQO7-1681365384122)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00115.jpeg)]
但是,当使用非整数值作为切片的组件时,Pandas 将尝试理解数据类型并从序列中选择适当的项目。 例如,从'b'到'd'的以下片段:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lcnJMUmD-1681365384122)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00116.jpeg)]
通过索引标签对齐
通过索引标签对Series数据进行对齐是 Pandas 的基本概念,也是其最强大的概念之一。 对齐基于索引标签提供多个序列对象中相关值的自动关联。 使用标准的过程技术,可以在多个集合中节省很多容易出错的工作量匹配数据。
为了演示对齐,让我们举一个在两个Series对象中添加值的示例。 让我们从以下两个Series对象开始,它们代表一组变量(a和b)的两个不同样本:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ayKPr5a1-1681365384123)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00117.jpeg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ApFHFyxc-1681365384123)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00118.jpeg)]
现在假设我们想对每个变量的值求和。 我们可以简单地表示为s1 + s2:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u7lkM1B5-1681365384123)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00119.jpeg)]
Pandas 已经对每个序列中每个变量的测量值进行了匹配,将这些值相加,然后在一个简洁的语句中将每个变量的总和返回给我们。
也可以将标量值应用于Series。 结果将是使用指定的操作将标量应用于Series中的每个值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Q1RJmp7l-1681365384124)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00120.jpeg)]
还记得前面提到的,我们将返回创建具有标量值的Series吗? 在执行此类操作时,Pandas 实际上会执行以下操作:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j8ZH2pao-1681365384124)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00121.jpeg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JH0PSv74-1681365384124)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00122.jpeg)]
第一步是从标量值创建一个Series,但带有目标Series的索引。 然后将乘法应用于两个Series对象的对齐值,由于索引相同,它们完美对齐。
索引中的标签不需要对齐。 如果未对齐,则 Pandas 将返回NaN作为结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bwe1RPZ1-1681365384124)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00123.jpeg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-68o9D6Uu-1681365384125)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00124.jpeg)]
默认情况下,NaN值是任何 Pandas 对齐的结果,其中索引标签与另一个Series不对齐。 与 NumPy 相比,这是 Pandas 的重要特征。 如果标签未对齐,则不应引发异常。 当某些数据丢失但可以接受时,这会有所帮助。 处理仍在继续,但是 Pandas 通过返回NaN可以让您知道存在问题(但不一定是问题)。
Pandas 索引中的标签不必唯一。 对齐操作实际上在两个Series中形成标签的笛卡尔积。 如果1序列中有n个标签,而2序列中有m个标签,则结果总计为n * m结果中的行。
为了演示这一点,让我们使用以下两个Series对象:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bDONsXyw-1681365384125)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00125.jpeg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wm0P3lXf-1681365384125)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00126.jpeg)]
这将产生 6 个'a'索引标签,以及'b'和'c'的NaN:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ddz8aAqR-1681365384126)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00127.jpeg)]
执行布尔选择
索引为我们提供了一种基于其标签在Series中查找值的非常有效的手段。 但是,如果您想基于这些值在Series中查找条目,该怎么办?
为了处理这种情况,Pandas 为我们提供了布尔选择。 布尔选择将逻辑表达式应用于Series的值,并在每个值上返回新的布尔值序列,这些布尔值表示该表达式的结果。 然后,该结果可用于仅提取结果为True的值。
为了演示布尔选择,让我们从下面的Series开始并应用大于大于运算符来确定大于或等于3的值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nhtrwrqi-1681365384126)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00128.jpeg)]
这将导致Series具有匹配的索引标签,并且表达式的结果将应用于每个标签的值。 值的dtype为bool。
然后可以使用该序列从原始序列中选择值。 通过将布尔结果传递到源的[]运算符来执行此选择。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SLQR08zK-1681365384126)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00129.jpeg)]
可以通过在[]运算符中执行逻辑运算来简化语法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gBt3R7OL-1681365384127)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00130.jpeg)]
不幸的是,普通的 Python 语法不能使用多个逻辑运算符。 例如,以下导致引发异常:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GSMqnsp7-1681365384127)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00131.jpeg)]
导致上述代码无法正常工作的原因有技术原因。 解决方案是用不同的方式表达方程式,在每个逻辑条件前后加上括号,并为和/或(|和&)使用不同的运算符:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KSRnuuLY-1681365384127)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00132.jpeg)]
使用.all()方法可以确定Series中的所有值是否与给定表达式匹配。 下面的内容询问该序列中的所有元素是否都大于或等于0:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UFI7jMoY-1681365384127)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00133.jpeg)]
如果任何值满足表达式,则.any()方法将返回True。 下面的内容询问是否有任何元素小于2:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xoxYzRaN-1681365384128)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00134.jpeg)]
您可以对结果选择使用.sum()方法来确定有多少项目满足表达式。 这是因为当给定布尔值序列,该序列的.sum()方法会将True视为1和False视为0:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kDKuordw-1681365384128)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00135.jpeg)]
重新索引序列
在 Pandas 中重新索引是使Series中的数据符合一组标签的过程。 Pandas 使用它来执行大部分对齐过程,因此是一项基本操作。
重新索引实现了以下几项功能:
- 重新排序现有数据来匹配一组标签
- 在没有标签数据的地方插入
NaN标记 - 可以使用某种逻辑填充标签的缺失数据(默认为添加
NaN值)
重新索引可以很简单,只需为Series的.index属性分配一个新索引即可。 下面演示了以这种方式更改Series的索引:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jsp7803V-1681365384128)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00136.jpeg)] [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IWrPwxZh-1681365384129)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00137.jpeg)]
分配给.index属性的列表中的元素数必须与行数匹配,否则将引发异常。 重新索引还就地修改了Series。
通过使用.reindex()方法,可以灵活地创建新索引。 一种情况是分配一个新索引,其中标签数与值数不匹配:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YKiJUHpy-1681365384129)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00138.jpeg)]
以下代码使用一组具有新值,丢失值和重叠值的标签为Series重新编制索引:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YKVaypJu-1681365384129)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00139.jpeg)]
关于.reindex(),有几点需要指出。 首先是.reindex()方法的结果是新的Series,而不是就地修改。 新的Series具有带有标签的索引,如传递给函数时所指定。 将为原始Series中存在的每个标签复制数据。 如果在原始Series中找不到标签,则将NaN分配为该值。 最后,将删除Series中带有不在新索引中的标签的行。
当您要对齐两个Series以对两个Series中的值执行操作但Series对象没有由于某种原因对齐的标签时,重新索引也很有用。 一种常见的情况是,一个Series具有整数类型的标签,另一个是字符串,但是值的基本含义是相同的(从远程源获取数据时,这很常见)。 以以下Series对象为例:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7MEMoVKY-1681365384129)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00140.jpeg)]
尽管两个Series中标签的含义相同,但是由于它们的数据类型不同,它们将对齐。 一旦发现问题,即可轻松解决:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TD4MS2dc-1681365384130)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00141.jpeg)]
.reindex()方法具有默认操作,即在源Series中找不到标签时,将NaN作为缺少的值插入。 可以使用fill_value参数更改此值。 下面的示例演示使用0代替NaN:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pjg8pgY0-1681365384130)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00142.jpeg)]
当对有序数据(例如时间序列)执行重新索引时,可以执行插值或值填充。 在第 10 章“时间序列数据”中,将对插值和填充进行更详细的讨论,但是以下示例介绍了这一概念。 让我们从以下Series开始:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DdHT6E0x-1681365384130)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00143.jpeg)]
以下示例演示了前向填充的概念,通常称为最近已知值。 重新索引Series以创建连续的整数索引,并通过使用method='ffill'参数,为任何新的索引标签分配先前已知的非 NaN 值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SpiMv3Bu-1681365384130)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00144.jpeg)]
索引标签1和2与标签0的红色,4和5从标签3的green以及红色6到5的blue匹配。
以下示例使用method='bfill'向后填充:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5Uk9wz6z-1681365384130)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00145.jpeg)]
标签6没有先前的值,因此将其设置为NaN; 4设置为5(blue)的值; 2和1设置为标签3(green)的值。
原地修改序列
Series的就地修改是一个有争议的话题。 如果可能,最好执行返回带有新Series中表示的修改的新Series的操作。 但是,如果需要,可以更改值并就地添加/删除行。
通过为尚不存在的index标签分配值,可以在序列中添加一行。 以下代码创建一个Series对象,并向该序列添加一个附加项:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4BXrn289-1681365384131)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00146.jpeg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xub6CtWy-1681365384131)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00147.jpeg)]
可以通过分配在特定索引标签上的值来更改它:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QlqYp1qG-1681365384131)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00148.jpeg)]
可以通过将index标签传递给del()函数从Series中删除行。 下面演示了如何删除带有索引标签'a'的行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8HB5wE14-1681365384131)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00149.jpeg)]
要添加和删除不适当的项目,请使用pd.concat()使用布尔选择来添加和删除。
使用切片时要牢记的重要一点是,切片的结果是原始Series的视图。 通过切片操作结果修改值将修改原始的Series。
考虑以下示例,该示例选择Series中的前两个元素并将其存储在新变量中:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pUw1oO5L-1681365384131)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00150.jpeg)]
将值分配给切片元素的以下操作将更改原始Series中的值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yeW09KrQ-1681365384132)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00151.jpeg)]
总结
在本章中,您学习了 Pandas Series对象以及如何将其用于表示变量测量值的索引表示。 我们从如何创建和初始化Series及其关联索引开始,然后研究了如何在一个或多个Series对象中操纵数据。 我们研究了如何通过索引标签对齐Series对象以及如何在对齐的值上应用数学运算。 然后,我们检查了如何按索引查找数据,以及如何根据数据(布尔表达式)执行查询。 然后,我们结束了对如何使用重新索引来更改索引和对齐数据的研究。
在下一章中,您将学习如何使用DataFrame以统一的表格结构表示多个Series数据。
四、用数据帧表示表格和多元数据
Pandas DataFrame对象将Series对象的功能扩展为二维。 代替单个值序列,数据帧的每一行可以具有多个值,每个值都表示为一列。 然后,数据帧的每一行都可以对观察对象的多个相关属性进行建模,并且每一列都可以表示不同类型的数据。
数据帧的每一列都是 Pandas Series,并且数据帧可以视为一种数据形式,例如电子表格或数据库表。 但是这些比较并不符合DataFrame的要求,因为数据帧具有 Pandas 特有的非常不同的质量,例如代表列的Series对象的自动数据对齐。
这种自动对齐方式使数据帧比电子表格或数据库更有能力进行探索性数据分析。 结合在行和列上同时切片数据的功能,这种与数据帧中的数据进行交互和浏览的功能对于查找所需信息非常有效。
在本章中,我们将深入研究 Pandas DataFrame。 Series会熟悉许多概念,但是会添加一些数据和工具来支持其操作。 具体而言,在本章中,我们将涵盖以下主题:
- 根据 Python 对象,NumPy 函数,Python 字典,Pandas
Series对象和 CSV 文件创建DataFrame - 确定数据帧大小
- 指定和操作数据帧中的列名
- 创建数据帧期间的行对齐
- 选择数据帧的特定列和行
- 将切片应用于数据帧
- 通过位置和标签选择数据帧的行和列
- 标量值查找
- 应用于数据帧的布尔选择
配置 Pandas
我们使用以下导入和配置语句开始本章中的示例:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-htdjQzXM-1681365384132)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00152.jpeg)]
创建数据帧对象
有多种创建数据帧的方法。 可以从一个或一组多维数据集创建一个数据帧。 我们将研究的技术如下:
- 使用 NumPy 函数的结果
- 使用包含列表或 Pandas
Series对象的 Python 字典中的数据 - 使用 CSV 文件中的数据
在检查所有这些内容时,我们还将检查如何指定列名,演示初始化期间如何执行对齐以及查看如何确定数据帧的尺寸。
使用 NumPy 函数结果创建一个数据帧
数据帧可以由一维 NumPy 整数数组(范围从 1 到 5)创建:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pZesLpEH-1681365384132)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00153.jpeg)]
输出的第一列显示已创建索引的标签。 由于在创建时未指定索引,因此 Pandas 创建了一个基于RangeIndex的标签,标签的开头为 0。
数据在第二列中,由值1至5组成。 数据列上方的0是该列的名称。 在创建数据帧时未指定列名称时,pandas 使用从 0 开始的增量整数来命名列。
也可以使用多维 NumPy 数组,并创建多个列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TcuGLIj5-1681365384132)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00154.jpeg)]
可以使用.columns属性访问DataFrame的列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WV5pIjqr-1681365384133)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00155.jpeg)]
这表明,当未指定列名时,Pandas 将创建一个RangeIndex来表示列。
可以使用columns参数指定列名。 下面创建了一个两列DataFrame,代表两个城市的两个温度样本:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MF6Na12I-1681365384133)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00156.jpeg)]
可以使用len()函数找到DataFrame中的行数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nvsmOXRN-1681365384133)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00157.jpeg)]
可以使用.shape属性找到DataFrame的尺寸:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eII9N9qD-1681365384133)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00158.jpeg)]
使用 Python 字典和 pandas 序列对象创建数据帧
Python 字典可用于初始化DataFrame。 使用 Python 字典时,pandas 将把键用作列名,并将每个键的值用作列中的数据:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KkvivW8g-1681365384134)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00159.jpeg)]
创建DataFrame的常用技术是使用将用作行的 Pandas Series对象的列表:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oaScfzAk-1681365384134)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00160.jpeg)]
在这种情况下,每个Series代表每个城市在特定测量间隔处的单个测量。
要命名列,我们可以尝试使用columns参数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bT5yG15z-1681365384134)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00161.jpeg)]
此结果与我们可能期望的结果不同,因为这些值已用NaN填充。 这可以通过两种方式纠正。 第一种是将列名称分配给.columns属性:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IqtwvKD5-1681365384134)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00162.jpeg)]
另一种技术是使用 Python 字典,其中键是列名,每个键的值是Series,代表该特定列中的度量:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ykx5Ce1Q-1681365384134)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00163.jpeg)]
请注意,在构建DataFrame时,将对齐提供的Series。 下面通过添加索引值不同的第三个城市来说明这一点:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5xFBqLdJ-1681365384135)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00164.jpeg)]
从 CSV 文件创建数据帧
可以通过使用pd.read_csv()函数从 CSV 文件读取数据来创建数据帧。
pd.read_csv()将在第 9 章“访问数据”中进行更广泛的研究。
为了演示该过程,我们将从一个包含 S&P 500 快照的文件中加载数据。该文件名为sp500.csv,位于代码包的data目录中。
文件的第一行包含每个变量/列的名称,其余 500 行代表 500 种不同股票的值。
以下代码加载数据,同时指定文件中的哪一列用于索引,并且我们只需要四个特定的列(0、2、3 和 7):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QqloEvNX-1681365384135)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00165.jpeg)]
使用.head()检查前五行,向我们显示以下结构和所得数据帧的内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SxxLEIHR-1681365384135)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00166.jpeg)]
让我们检查一下该数据帧的一些属性。 它应该具有 500 行数据。 可以通过检查数据帧的长度来检查:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FWeBHrJr-1681365384135)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00167.jpeg)]
我们希望它具有 500 行和三列的形状:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dCpsBsmU-1681365384136)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00168.jpeg)]
可以使用.size属性找到数据帧的大小。 此属性返回数据帧中数据值的数量。 我们预计 500 * 3 = 1,500:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oI1S6Hnn-1681365384136)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00169.jpeg)]
数据帧的索引由 500 种股票的符号组成:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YnZHtP5G-1681365384136)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00170.jpeg)]
这些列由以下三个名称组成:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2DEJZUpw-1681365384136)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00171.jpeg)]
请注意,尽管我们在加载时指定了四列,但结果仅包含三列,因为源文件中四列之一用于索引。
访问数据帧内的数据
数据帧由行和列组成,并具有从特定行和列中选择数据的结构。 这些选择使用与Series相同的运算符,包括[],.loc[]和.iloc[]。
由于存在多个维度,因此应用这些维度的过程略有不同。 我们将通过首先学习选择列,然后选择行,在单个语句中选择行和列的组合以及使用布尔选择来检查这些内容。
此外,pandas 提供了一种构造,用于在我们将要研究的特定行和列上选择单个标量值。 该技术很重要,并且存在,因为它是访问这些值的一种非常高性能的方法。
选择数据帧的列
使用[]运算符选择DataFrame特定列中的数据。 这与Series不同,在Series中,[]指定了行。 可以将[]操作符传递给单个对象或代表要检索的列的对象列表。
以下内容检索名称为'Sector'的列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZGjKBNEw-1681365384136)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00172.jpeg)]
当从DataFrame中检索单个列时,结果为Series:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nU9SmwQi-1681365384137)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00173.jpeg)]
通过指定列名列表可以检索多个列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i7eJidkf-1681365384137)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00174.jpeg)]
由于它具有多个列,因此结果是DataFrame而不是Series:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lveKt5HD-1681365384137)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00175.jpeg)]
列也可以通过属性访问来检索。 只要名称不包含空格,DataFrame将添加代表每列名称的属性。 下面以这种方式检索Price列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LxOPIoSp-1681365384137)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00176.jpeg)]
请注意,此名称不适用于Book Value列,因为名称带有空格。
选择数据帧的行
可以使用.loc[]通过索引标签值检索行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1hbs7lcR-1681365384137)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00177.jpeg)]
此外,可以使用标签列表检索多行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sUmQJRyU-1681365384138)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00178.jpeg)]
可以使用.iloc[]按位置检索行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jALCqBst-1681365384138)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00179.jpeg)]
可以在特定标签值的索引中查找位置,然后使用该值按位置检索行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WU48ypO5-1681365384138)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00180.jpeg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-exX6iwKj-1681365384138)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00181.jpeg)]
作为本节的最后注解,也可以使用.ix[]进行这些操作。 但是,此方法已被弃用。 有关更多详细信息,请参见这里。
使用.at[]和.iat[]按标签或位置进行标量查找
可以使用.at[]通过标签查找各个标量值,并同时向其传递行标签和列名称:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KSoEpqOw-1681365384139)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00182.jpeg)]
也可以使用.iat[]按位置查找标量值,同时传递行位置和列位置。 这是访问单个值的首选方法,并且可以提供最高的性能:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZlrtwYs3-1681365384139)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00183.jpeg)]
使用[]运算符进行切片
在其索引上切片DataFrame在语法上与使用Series执行相同操作相同。 因此,我们将在本节中不介绍切片的各种排列的细节,而仅查看应用于DataFrame的几个代表性示例。
使用[]运算符进行切片时,将在索引而非列上执行切片。 以下内容检索前五行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7Z1kEtde-1681365384139)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00184.jpeg)]
并且以下返回从ABT标签到ACN标签开始的行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P9kQREki-1681365384139)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00185.jpeg)]
切片DataFrame也适用于.iloc[]和.loc[]属性。 使用这些属性被认为是最佳实践。
使用布尔选择来选择行
可以使用布尔选择来选择行。 当应用于数据帧时,布尔选择可以利用多列中的数据。 考虑以下查询,该查询标识价格低于100的所有股票:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hAS6enid-1681365384139)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00186.jpeg)]
然后可以使用[]运算符将此结果应用于DataFrame,以仅返回结果为True的行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BYnhYCUA-1681365384140)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00187.jpeg)]
可以使用括号将多个条件放在一起。 以下内容检索价格在6和10之间的所有股票的代码和价格:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-whu8bRxJ-1681365384140)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00188.jpeg)]
通常使用多个变量执行选择。 下面通过查找Sector为Health Care且Price大于或等于100.00的所有行来证明这一点:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5zCFrDXI-1681365384140)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00189.jpeg)]
在行和列中进行选择
通常的做法是选择由一组行和列组成的数据子集。 下面通过首先选择一部分行然后选择所需的列来说明这一点:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ziPYKx69-1681365384140)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00190.jpeg)]
总结
在本章中,您学习了如何创建 Pandas DataFrame对象以及基于各种列中的索引和值选择数据的各种方法。 这些示例与Series的示例相似,但是证明,由于DataFrame具有列和关联的列索引,因此语法与Series有所不同。
在下一章中,我们将进一步使用DataFrame深入研究数据操作,并着重于对DataFrame结构和内容进行修改。
五、数据帧的结构操作
Pandas 提供了一个强大的操纵引擎,供您用来浏览数据。 这种探索通常涉及对DataFrame对象的结构进行修改,以删除不必要的数据,更改现有数据的格式或从其他行或列中的数据创建派生数据。 这些章节将演示如何执行这些强大而重要的操作。
具体而言,在本章中,我们将介绍:
- 重命名列
- 使用
[]和.insert()添加新列 - 通过扩展添加列
- 使用连接添加列
- 重新排序列
- 替换列的内容
- 删除列
- 添加新行
- 连接行
- 通过扩展添加和替换行
- 使用
.drop()删除行 - 使用布尔选择删除行
- 使用切片删除行
配置 Pandas
以下代码将为以下示例配置 Pandas 环境。 这还将加载 S&P 500 数据集,以便可以在示例中使用它:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qf5t8IUN-1681365384140)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00191.jpeg)]
重命名列
可以使用适当命名的.rename()方法重命名列。 可以向此方法传递一个字典对象,其中的键表示要重命名的列的标签,并且每个键的值是新名称。
下面的操作会将'Book Value'列的名称更改为'BookValue',删除空格并允许使用属性符号访问该列的数据。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l1VpuxAy-1681365384141)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00192.jpeg)]
以这种方式使用.rename()将返回一个新的数据帧,其中的列已重命名,并且数据是从原始数据中复制的。 以下内容验证了原始文件没有被修改。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-forHycic-1681365384141)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00193.jpeg)]
要在不进行复制的情况下就地修改数据帧,可以使用inplace=True参数。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-irpOY6qa-1681365384141)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00194.jpeg)]
现在可以使用.BookValue属性访问数据。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-07jiuO23-1681365384141)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00195.jpeg)]
使用[]和.insert()添加新列
可以使用[]运算符将新列添加到数据帧。 让我们添加一个名为RoundedPrice的新列,该列将表示Price列中值的舍入。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Cd5lGgBF-1681365384142)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00196.jpeg)]
Pandas 执行此操作的方式是,首先从sp500中选择Price列的数据,然后将Series中的所有值四舍五入。 然后,pandas 将新的Series与副本DataFrame对齐,并将其添加为名为RoundedPrice的新列。 新列将添加到列索引的末尾。
.insert()方法可用于在特定位置添加新列。 下面在Sector和Price之间插入RoundedPrice列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9tl0qzRd-1681365384142)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00197.jpeg)]
通过扩展来添加列
可以使用.loc[]属性和切片添加列。 下面通过向名为PER的sp500的子集添加新列,并将所有值初始化为0来演示这一点。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fx8Vn5HT-1681365384142)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00198.jpeg)]
具有现有数据的Series也可以通过这种方式添加。 下面将PER列与随机数据的序列相加。 由于这使用对齐方式,因此有必要使用与目标数据帧相同的索引。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wB6jcUZ8-1681365384142)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00199.jpeg)]
使用连接来添加列
[]运算符和.insert()方法都就地修改目标数据帧。 如果需要一个带有附加列的新数据帧(保持原来的不变),则可以使用pd.concat()函数。 此函数创建一个新的数据帧,其中所有指定的DataFrame对象均按规范顺序连接在一起。
下面的代码创建了一个新的DataFrame,其中的一列包含了四舍五入的价格。 然后,它使用pd.concat()和axis=1来表示给定的DataFrame对象应沿着列轴连接(与使用axis=0的行相比)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qGy55C62-1681365384142)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00200.jpeg)]
在第 11 章(合并,关联和重塑数据)中将更详细地介绍连接。
连接可能会导致重复的列名。 为了演示这种情况,让我们重新创建rounded_price,但将其命名为Price列。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FGvuNhTv-1681365384143)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00201.jpeg)]
现在,连接将导致重复的列。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZBTWisM4-1681365384143)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00202.jpeg)]
有趣的是,您可以使用.Price属性检索这两列。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SyNkXx9Y-1681365384143)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00203.jpeg)]
如果要在场景中获取特定的Price列,则需要按位置而不是名称进行检索。
对列重新排序
通过按所需顺序选择列,可以重新排列列的顺序。 下面通过反转列进行演示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wlSdU7Uv-1681365384143)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00204.jpeg)]
实际上,没有一种方法可以就地更改列的顺序。 参见这里。
替换列的内容
通过使用[]运算符将新的Series分配给现有列,可以替换DataFrame的内容。 以下演示了用rounded_price中的Price列替换Price列。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rWNsCISS-1681365384144)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00205.jpeg)]
列的数据也可以使用切片替换(就地)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yO9384TQ-1681365384144)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00206.jpeg)]
删除列
可以使用数据帧的del关键字或.pop()或.drop()方法从DataFrame中删除列。 这些行为的差异略有不同:
del将从DataFrame中删除Series(原地)pop()将同时删除Series并返回Series(也是原地)drop(labels, axis=1)将返回一个已删除列的新数据帧(原始DataFrame对象未修改)
下面演示了如何使用del从sp500数据的副本中删除BookValue列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HH9R9BSF-1681365384144)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00207.jpeg)]
以下使用.pop()方法删除Sector列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aMyqzT4r-1681365384144)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00208.jpeg)]
.pop()方法的优势在于它为我们提供了弹出的列。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E1o9K99Y-1681365384145)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00209.jpeg)]
.drop()方法可用于删除行和列。 要使用它删除列,请指定axis=1:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uj36kGEG-1681365384145)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00210.jpeg)]
追加新行
使用DataFrame的.append()方法执行行的追加。 附加过程将返回一个新的DataFrame,并首先添加来自原始DataFrame的数据,然后再添加第二行的数据。 追加不会执行对齐,并且可能导致索引标签重复。
以下代码演示了附加两个从sp500数据中提取的DataFrame对象。 第一个DataFrame由行(按位置)0,1和2组成,第二个DataFrame由行(按位置)10,11和2组成。 两者中都包含位置2处的行(带有标签ABBV),以演示重复索引标签的创建。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N51f6EY6-1681365384145)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00211.jpeg)]
追加中使用的DataFrame对象的列集不必相同。 结果数据帧将由两个列的并集组成,缺少的列数据填充有NaN。 以下内容通过使用与df1相同的索引创建第三个数据帧,但只有一个列的名称不在df1中来说明这一点。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ngtcuWms-1681365384146)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00212.jpeg)]
现在,我们附加df3和df1。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XH6ZFlfk-1681365384146)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00213.jpeg)]
ignore_index=True参数可用于附加,而无需强制从DataFrame保留索引。 当索引值的意义不大并且您只希望将具有顺序递增的整数的级联数据用作索引时,这很有用:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lFEXN2Dm-1681365384146)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00214.jpeg)]
请注意,结果DataFrame具有默认的RangeIndex,并且索引(Symbol))中的数据已从结果中完全排除。
连接行
可以使用pd.concat()函数并通过指定axis=0将来自多个DataFrame对象的行彼此连接。 沿行轴在两个DataFrame对象上进行pd.concat()的默认操作的方式与.append()方法相同。
通过重建前面的附加示例中的两个数据集并将其连接起来,可以证明这一点。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CPS8evYu-1681365384147)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00215.jpeg)]
如果所有DataFrame对象中的列集都不相同,则 Pandas 将用NaN填充这些值。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wpco8mJV-1681365384147)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00216.jpeg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TvLBpYK7-1681365384147)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00217.jpeg)]
从源对象中逐行复制行会导致重复的索引标签。 keys参数可用于帮助区分一组行源自哪个数据帧。 下面通过使用keys向表示源对象的索引添加一个级别进行演示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xCXV7HCv-1681365384148)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00218.jpeg)]
我们将在第 6 章“处理索引”中更详细地研究层次结构索引。
通过扩展来添加和替换行
也可以使用.loc属性将行添加到DataFrame。 .loc的参数指定要放置行的索引标签。 如果标签不存在,则使用给定的索引标签将值附加到数据帧。 如果标签确实存在,则将替换指定行中的值。
以下示例获取sp500的子集,并添加带有标签FOO的行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CiGcZUL9-1681365384148)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00219.jpeg)]
请注意,无论是添加还是替换行,都会进行此更改。
使用.drop()删除行
DataFrame的.drop()方法可用于删除行。 .drop()方法获取要删除的索引标签列表,并返回DataFrame的副本,其中删除了指定的行。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nBvqVzuN-1681365384148)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00220.jpeg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fPNYfmVm-1681365384148)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00221.jpeg)]
使用布尔选择删除行
布尔选择也可以用于从DataFrame中删除行。 布尔选择的结果将返回表达式为 True 的行的副本。 要删除行,只需构造一个表达式,为要删除的行返回False,然后将该表达式应用于数据帧。
下面的示例演示删除Price大于300的行。 首先,构造表达式。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UTFAMXOB-1681365384148)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00222.jpeg)]
根据此结果,我们现在知道有 10 行的价格大于 300。要获得删除了这些行的数据帧,请选择选择的补码。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iDafyi1r-1681365384149)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00223.jpeg)]
使用切片删除行
切片可用于从数据帧中删除记录。 这是一个与布尔选择类似的过程,在该过程中,我们选择了除要删除的行以外的所有行。
假设我们要从sp500中除去除前三个记录以外的所有记录。 执行此任务的片是[:3],它返回前三行。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qvMiYgd8-1681365384149)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00224.jpeg)]
请记住,由于这是切片,因此结果是原始数据帧的视图。 这些行尚未从sp500数据中删除,对这三行的更改将更改sp500中的数据。 防止这种情况的正确措施是制作切片的副本,这会导致复制指定行的数据的新数据帧。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KVM9REvG-1681365384149)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/learning-pandas-2e/img/00225.jpeg)]
总结
在本章中,您学习了如何使用 Pandas DataFrame对象执行几种常见的数据操作,特别是通过添加或删除行和列来更改DataFrame结构的操作。 此外,我们看到了如何替换特定行和列中的数据。
在下一章中,我们将更详细地研究索引的使用,以便能够有效地从 pandas 对象内检索数据。

