
R语言深度学习-4-识别异常数据(无监督学习/自动编码器)
赞
踩
本教程参考《RDeepLearningEssential》
本篇将关注自动编码器,用于学习数据集的特征。
4.1 无监督学习简述
无监督学习和有监督学习是机器学习中两种主要的学习类型。
(1)有监督学习是一种机器学习范式,其中模型的训练是基于带有标签的数据集进行的。这意味着每个训练样本都包含一个输入向量和一个对应的输出值(或标签)。在有监督学习中,算法的目的是学会如何根据给定的输入预测正确的输出。例如,在分类任务中,模型将尝试识别不同类别的对象;而在回归任务中,模型则试图预测连续的数值结果。常见的有监督学习算法包括决策树、支持向量机(SVM)、神经网络等。
(2)无监督学习涉及在没有预先定义的标签的情况下分析数据。这种类型的机器学习旨在发现数据中的模式或结构,而不是通过预测输出来评估模型的性能。在无监督学习中,算法会尝试理解数据的内在分布,并将其组织成不同的组或聚类。典型的无监督学习任务包括聚类分析和降维。聚类是将数据点分组到相似的集合中,而降维则是减少数据的特征数量以简化数据表示。常用的无监督学习算法有K-means聚类、主成分分析(PCA)等。是一个降维的方法。
总结起来,有监督学习和无监督学习的核心区别在于是否有预定义的标签用于指导学习过程。
4.2自动编码器
4.2.1简介
自动编码器(Autoencoder)是一种无监督学习算法,属于神经网络的一种形式。它的基本原理是通过编码器(Encoder)将输入数据压缩成一个低维度的特征表示,然后通过解码器(Decoder)将这些特征表示还原回原始数据的空间,以此来学习数据的内在结构和特征。
在自动编码器中,编码器和解码器通常由多层感知机组成,中间层(也称为隐藏层)的节点数通常少于输入层和输出层的节点数,这样可以实现数据的降维。自动编码器的目标是最小化输入数据和重构数据之间的差异,这一般通过损失函数来实现,比如均方误差(MSE)或其他相似度量。
自动编码器在许多领域都有广泛的应用,比如在图像处理中用于去噪和特征提取,在自然语言处理中用于文本数据的降维和表示学习,以及在异常检测中识别与正常模式显著不同的数据点。
4.2.2正则化的自动编码器
(1)惩罚的自动编码器通常指的是稀疏自动编码器(Sparse Autoencoder, SAE),它是一种正则化的自动编码器,旨在通过对隐藏层神经元施加稀疏性惩罚来提高网络的泛化能力和特征提取性能。这种稀疏性惩罚会使得隐藏层的激活值大部分接近于零,从而实现稀疏表示,这有助于减少过拟合的风险,并在一定程度上提升模型的泛化能力。
(2)去噪自动编码器(Denoising Autoencoder, DAE)则是另一种类型的正则化自动编码器,它的主要目的是通过学习从添加噪声的数据中恢复原始数据的能力来进行特征学习和数据去噪。DAE通过在训练过程中向输入数据添加随机噪声,然后让网络学习从噪声数据中重建干净的数据。这个过程增强了网络的鲁棒性,使其在面对噪声数据时也能保持较好的恢复性能。
4.2.3R语言训练自动编码器
我们还是使用我在第一篇教程中用到的数字识别数据进行学习,我们这里用到了H2O包,包的安装及数据的获取都参照之前的博客:R语言深度学习-1-深度学习入门(H2O包安装报错解决及接入/H2O包连接数据集)-CSDN博客
我们加载data.table库,这是一个增强的数据框(data frame)实现,提供了更快的数据处理速度和更简洁的语法。width用于控制打印输出时的最大宽度,而digits则决定了数值输出的小数点位数。我们选取数据的前20000行作为训练,后20000作为测试集。
- library('data.table')
- library('h2o')
- options(width = 70, digits = 2)
-
- dig_train <- read.csv("C:\\Users\\Huzhuocheng\\Desktop\\digit-recognizer\\train.csv")
- dim(dig_train) #数据维度查看
- dig_train$label <- factor(dig_train$label, levels = 0:9)
-
- cl <- h2o.init(
- max_mem_size = "20G",
- nthreads = 10,
- ip = "127.0.0.1", port = 54321)
- h2odigits <- as.h2o(
- dig_train,
- destination_frame = "h2odigits")
- i <- 1:20000
- h2odigits.train <- h2odigits[i, -1]
- itest <- 20001:30000
- h2odigits.test <- h2odigits[itest, -1]
- xnames <- colnames(h2odigits.train)

m1 我们用一个浅层神经网络,进行20次迭代(epoch),设置50个神经元,并不进行正则化:
- m1 <- h2o.deeplearning(
- x = xnames,
- training_frame = h2odigits.train,
- validation_frame = h2odigits.test,
- activation = "Tanh",
- autoencoder = TRUE,
- hidden = c(50),
- epochs = 20,
- sparsity_beta = 0,
- input_dropout_ratio = 0,
- l1 = 0,
- l2 = 0
- )
接着我们分别对m2a:将隐藏神经元数目增加到100,m2b:使用100个隐藏神经元及0.5的稀疏β值,m2c:使用100个隐藏神经元并丢弃20%的x输入(去噪自动编码器)
- m2a <- h2o.deeplearning(
- x = xnames,
- training_frame = h2odigits.train,
- validation_frame = h2odigits.test,
- activation = "Tanh",
- autoencoder = TRUE,
- hidden = c(100),
- epochs = 20,
- sparsity_beta = 0,
- input_dropout_ratio = 0,
- l1 = 0,
- l2 = 0
- )
- m2b <- h2o.deeplearning(
- x = xnames,
- training_frame = h2odigits.train,
- validation_frame = h2odigits.test,
- activation = "Tanh",
- autoencoder = TRUE,
- hidden = c(100),
- epochs = 20,
- sparsity_beta = .5,
- input_dropout_ratio = 0,
- l1 = 0,
- l2 = 0
- )
- m2c <- h2o.deeplearning(
- x = xnames,
- training_frame = h2odigits.train,
- validation_frame = h2odigits.test,
- activation = "Tanh",
- autoencoder = TRUE,
- hidden = c(100),
- epochs = 20,
- sparsity_beta = 0,
- input_dropout_ratio = .2,
- l1 = 0,
- l2 = 0
- )
我们可以直接去看每种方式的均方误差(mean squared error,MSE)
- >m1
- >m2a
- >m2b
- >m2c
![]()
![]()
![]()
![]()
我们发现对于比较简单的模型,考虑太多的正则化是没有必要的,反而丢失了正确性。
我们可以再通过h2o.anomaly()函数进行四分位数等指标的计算:
- error1 <- as.data.frame(h2o.anomaly(m1, h2odigits.train))
- error2a <- as.data.frame(h2o.anomaly(m2a, h2odigits.train))
- error2b <- as.data.frame(h2o.anomaly(m2b, h2odigits.train))
- error2c <- as.data.frame(h2o.anomaly(m2c, h2odigits.train))
- error <- as.data.table(rbind(
- cbind.data.frame(Model = 1, error1),
- cbind.data.frame(Model = "2a", error2a),
- cbind.data.frame(Model = "2b", error2b),
- cbind.data.frame(Model = "2c", error2c)))
-
- percentile <- error[, .(
- Percentile = quantile(Reconstruction.MSE, probs = .99)
- ), by = Model]
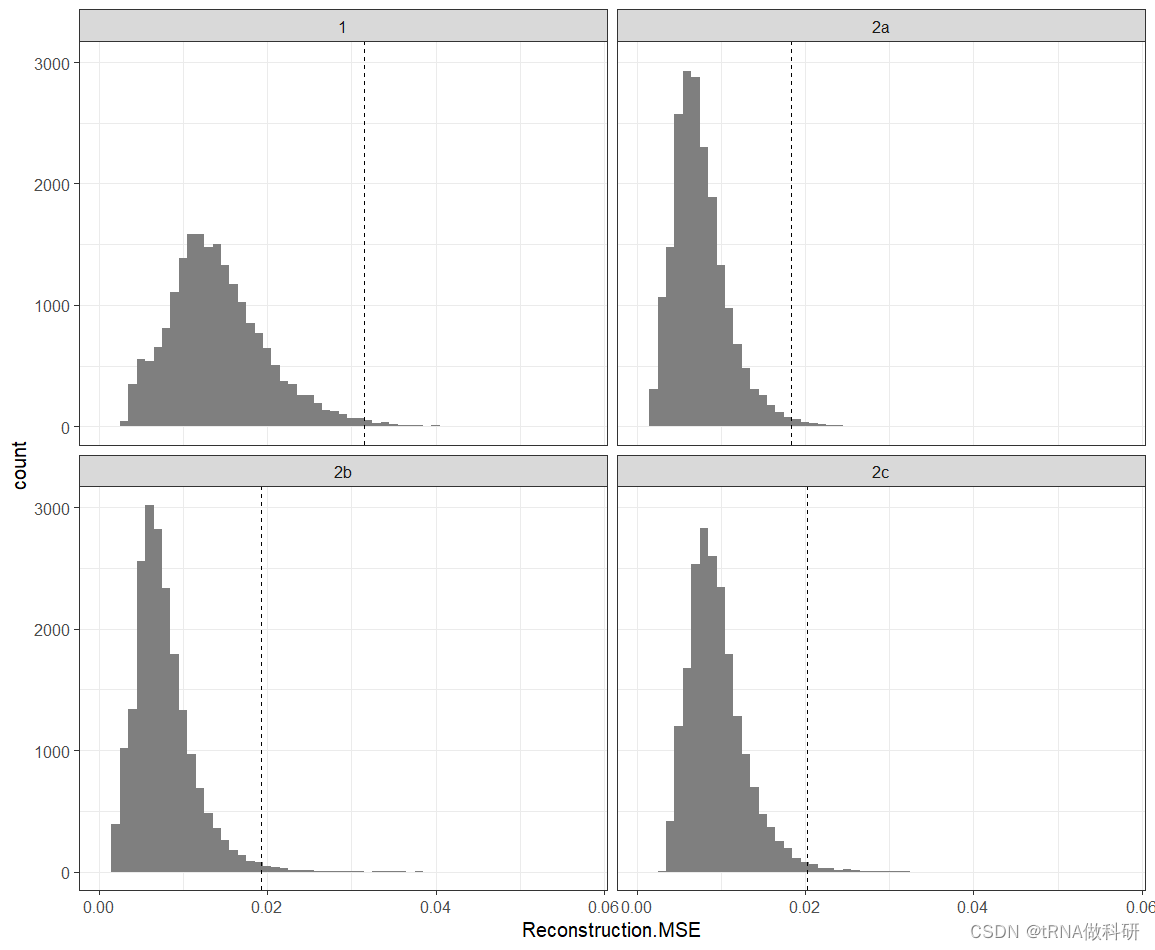
然后我们用ggplot可视化一下,虚线是99%分位数,超过这个值的都是比较极端:
- library('ggplot2')
- p <- ggplot(error, aes(Reconstruction.MSE)) +
- geom_histogram(binwidth = .001, fill = "grey50") +
- geom_vline(aes(xintercept = Percentile), data = percentile,
- linetype =2) + theme_bw() + facet_wrap(~Model)
- print(p)
- error.tmp <- cbind(error1, error2a, error2b, error2c)
- colnames(error.tmp) <- c("M1", "M2a", "M2b", "M2c")
- plot(error.tmp)

到这里我们已经学习了如何用R语言构建简单的自动编码器,大家可以增加网络的复杂程度或者使用多层神经网络并调试正则参数来更进一步学习一下。

