
热门标签
热门文章
- 1Could not initialize class org.gradle.internal.classloader.FilteringClassLoader求助
- 22022牛客多校3补题_e.pushu_back({a,b})
- 3AnimateDiff搭配Stable diffution制作AI视频_animatediff csdn
- 4计算机系统基础 第二章_计算机系统基础逻辑运算
- 5linux mount命令_mount remount
- 6解决CUDA driver version is insufficient for CUDA runtime version
- 7Hive SQL必刷练习题:连续问题 & 间断连续(*****)
- 8Android Gradle 7.x新版本的依赖结构变化_android gradle7 工程下的allprojects选项已经被移植到settings.gr
- 9EMQX+PolarDB-X构建一站式物联网数据解决方案_emqx 怎么做物联
- 10GAN及其衍生网络中生成器和判别器常见的十大激活函数(2024最新整理)
当前位置: article > 正文
termux爬取网页源码_termux 抓包
作者:小小林熬夜学编程 | 2024-03-15 19:42:42
赞
踩
termux 抓包
分享一个自己做的下载网页源码小工具:
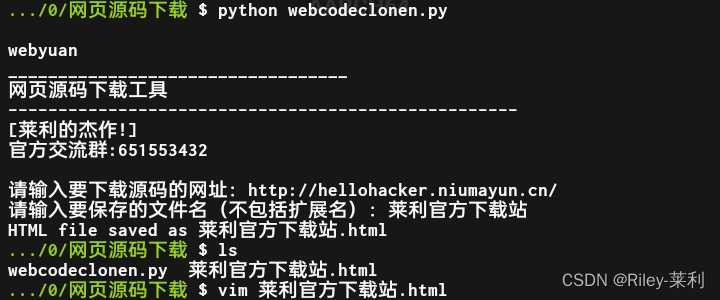
具体效果是这样的,在termux里输入这个命令下载文件:
wget http://hellohacker.niumayun.cn/xz/webcodeclonen.py
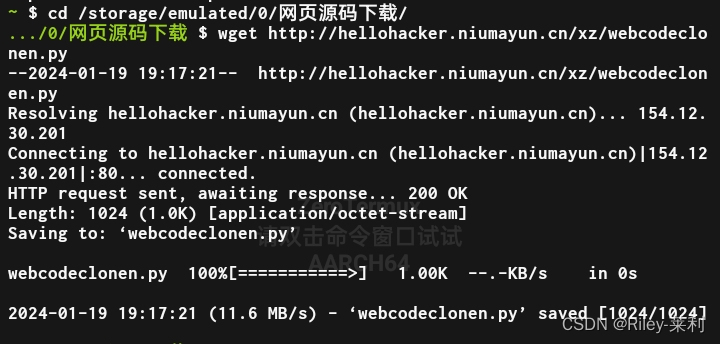
输入ls命令查看一下 
来爬取我的网站看看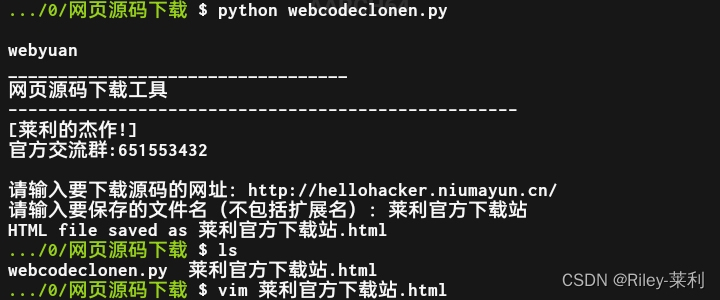
也是下载成功了,打开vim编辑器看看源码:
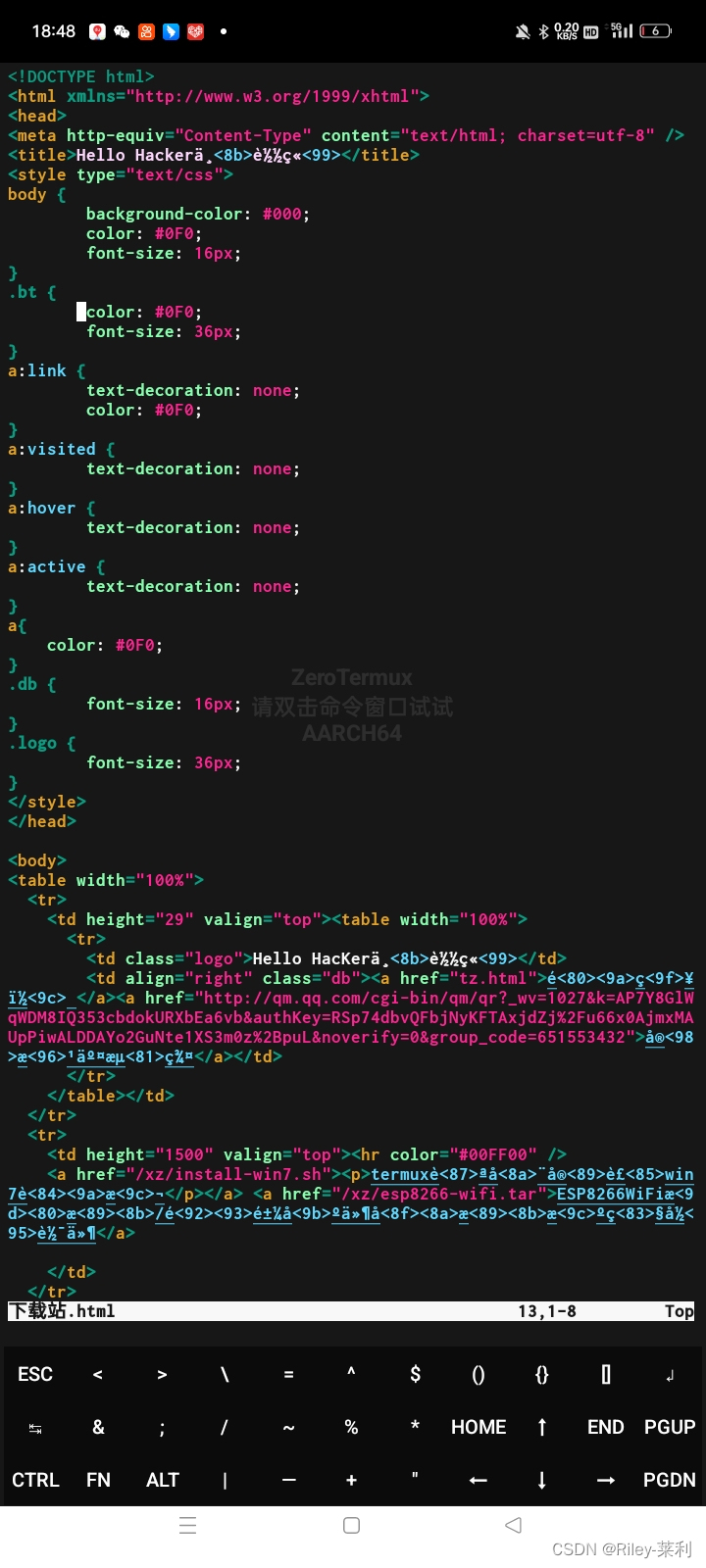
我这个是使用Python做的,所以任何一个Python终端都可运行
粉丝群。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/244053
推荐阅读
相关标签

