
热门标签
热门文章
- 1用Python模拟识别图片验证码并发送手机验证码
- 2Eclipse表示:“正在使用或无法创建的工作区,请选择其他工作区。”如何解锁工作区?_workspace cannot be locked
- 3项目经验-王红波_2006年中国首届杰出数据库工程师 王红波
- 4c++ ShellExecute 执行cmd命令_c++ shellexecute cmd
- 5Android开发中三个绘图工具(Paint,Canvas,Path)的基本用法(总结)_android.graphics.paint是什么
- 6【探索Linux】—— 强大的命令行工具 P.28(网络编程套接字 —— 简单的UDP网络程序模拟实现)
- 7FFmpeg在win10上编译安装(配置libx264)_windows上安装libx264
- 8Apache POI处理EXCEL中的图片_poi 图片
- 9select 中where 条件的技巧写法(where 1=1 and ....)_select where (条件and条件) and (条件and条件) and (条件and条件)
- 10org.apache.commons.logging.LogFactory_orgapachecommonslogging
当前位置: article > 正文
Faster R-CNN实验记录总结_faster-rcnn 训练结果
作者:小小林熬夜学编程 | 2024-03-16 14:25:53
赞
踩
faster-rcnn 训练结果
刚开始接触到深度学习的时候,做实验的一些记录。
现在看来有些简单的,权当写日志了。
收集数据样本训练,对于样本的选取的总结。
现象:
1、第一次训练车牌图片,车牌是已经被“归一化”过,使得所有的车牌图片都是相同的尺寸,就是说将原图的比例改变了。强行的变成了固定比例的车牌图片。当这样的图片经过训练之后,对正常的车牌图片识别效果很差,对同样经过归一化的车牌的识别效果很好。


上面的图是经过归一化处理之后的车牌,下面是车牌原始图像。
结论:
faster RCNN在训练过程中将训练样本的某些人眼不能直接感觉到的特征提取出来了,写进了网络模型中,导致最后测试图片中没有这些特征的图片都被认为不是图片类。这个实验也说明了我没有掌握到faster rcnn的泛化能力或者抽象能力。
现象:
残缺信息补全实验。在车牌数据集制作过程中,将每个字符都单独分割为四个部分(左上,右上,左下,右下),然后把这四个部分和字符整体全部标注为这个字符。
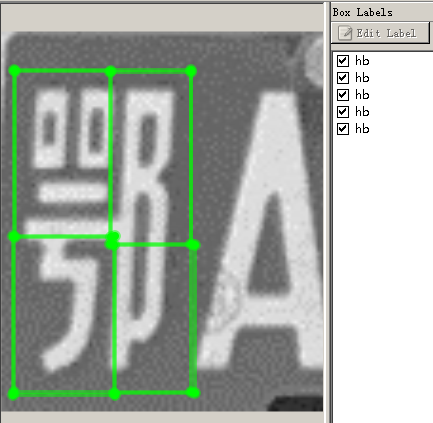
如上图这样,分别将四个部分和整体全部标注为 hb 。训练之后其AP值很低,最后的测试效果很差,在能够识别到的图片中,局部得分要比整体得分高。
结论:
通过简单地对局部标注来训练,并不能提高识别效果反而会影响最后的识别效果。将字符分割之后,每个局部都没有共同点,但是他们又被强制地分为一类,所以最后识别网络迷茫了,提取不到共同特征。这个实验仅仅是将整体和局部的样本数1:1的进行训练,也许更改整体数量和局部数量的比例之后可以完成残缺信息识别,但是具体的比例是多少现在还不知道。
现象:
为了提高倾斜车牌,斜拍车牌图片的识别率,将样本中正常的车牌图片,人为进行旋转,亮度,尺寸,模糊处理,仿射变换。每一次进行拓展都是与原样本1:1增加。
初步证明,增加亮度变化,尺寸变化,相较于未拓展时识别率有少许提高,由于两个样本数量不同,没有将原始样本直接复制使数量相同作对比,所以最后的少许提高并没有量化去记录。
对于仿射变换,确实对于斜拍的车牌图片识别率有一定提高。
倾斜车牌:共210个字符,原始数据集模型识别88个字符,增加仿射变换之后模型识别118个字符。仿射变换之后有比较明显的提升。
增加处理过的图片然后训练,最后的识别效果中,会发现在正常车牌识别结果数量比不加处理过照片的结果数量少一两个。
结论:
可以通过基础样本数据集来进行一定的变换来提升样本的丰富性,亮度,旋转,尺寸的变化提升并不明显。(cnn网络具有旋转、平移不变性)。
拓展的样本与原样本数量1:1训练,会对原来的识别效果产生少许的影响。
现象:
2、行李箱实验。
用手机对着行李箱进行360度的旋转拍摄,然后分别截取每一帧的图像进行训练。


第一次按照这样的标注方法对行李箱进行标注,在最后测试图片中检测的时候,检测框总是很大,给人的感觉就是必须要把地板包围进去。甚至用一张纯地板的图片进行检测居然会有目标对象。然后意识到是样本制作时候把地板的部分包围进去太多,导致地板的信息过多的提取出来。最后将样本标注框尽量的缩小包围检测物体,最后效果还可以。
结论:
标注框过大并不是导致最后结果出错的唯一原因。还有另外一个原因是目标背景太过于单一,当所有的样本都存在一个相同的背景,这样在制作数据集训练过程中,他们本来就是属于同一类,还具有相同的背景,所以识别网络会将标注进来的背景部分认为是目标的一部分,在最后测试图片中如果换了背景,反而检测物品得分较低。
现象:
在X光水果识别实验中,分别有 苹果,枣子,桔子 三种水果分别通过X光机,采集他们的样本。

这是一张桔子的x光照片,制作数据集的图片如下图:
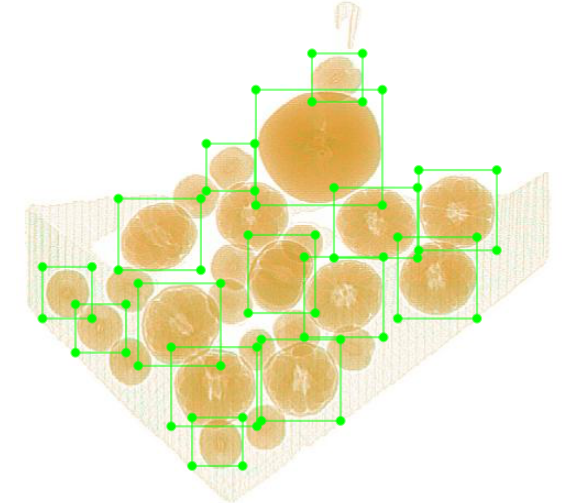
在制作数据集的过程中,很难将目标完全地框在方框里面,所以不可避免的有背景存在包围框里面,由于实验的时候背景都是单一的颜色,所以在最后测试的结果中,把水果放在行李箱中和手机等其他东西混合在一起进行测试,

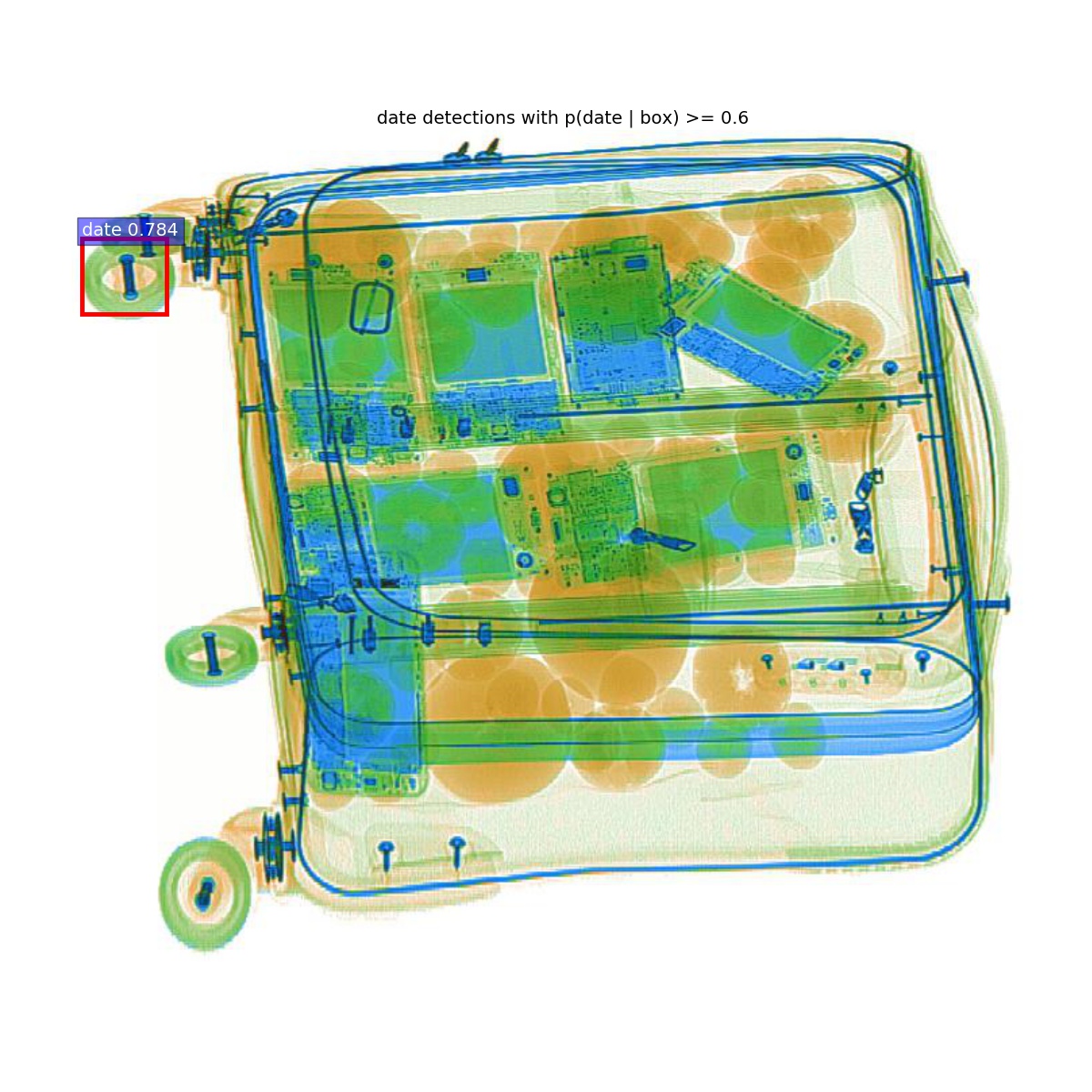

在行李箱中的水果没有被识别出来,但是行李箱的一个轮子却被识别成了枣子。
结论:
在水果试验中,水果的背景太过于单一,导致网络把白色背景信息记录到模型中,在测试的时候如果有类似背景的待测物品就很容易错分。
对于训练样本的背景选取规律还不清楚。
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

