
- 1阿里云HBase发布冷存储特性,轻松搞定冷数据处理_运用hbase技术,存储系统中的冷数据,保证系统数据的可靠性
- 2解决npm安装时没有反应的情况_npm install 没反应
- 3Gson:Java格式化Json
- 4OpenMP并行模型
- 5Flutter关于软键盘的一些问题_flutter resizetoavoidbottominset
- 6android studio manifestplaceholders,Android Gradle使用manifestPlaceholders
- 7Android Q 10 framework_android 10framework opt
- 8状态迁移法用例设计_如果使用状态迁移图法进行用例设计,需要考虑哪些种情况。
- 9【Matlab三维路径规划】蚁群算法三维路径规划【含源码 179期】_三维蚁群算法matlab
- 10nodejs里npm运行无响应解决_nodejs项目运行没有反应
Pyqt搭建YOLOV3目标检测界面(超详细+源代码)_pyqt搭建yolov3目标检测界面(超详细+源代码)
赞
踩
Pyqt搭建YOLOV3目标检测界面(超详细+源代码)
本项目github地址:https://github.com/chenanga/qt5_yolov3
大家觉得有用的话,帮忙点点star,感谢大家!
2022.5.25更新
大家有问题的话尽量在评论区问,问之前可以看一下评论区有没有类似错误的解决方法。
2021.11.23 更新
由于yolov3模型较大、且检测速度也相对会慢一点。大家如果想搭建界面,推荐大家使用yolov5。下面的代码算是一个思想或者一种搭建目标检测的方法,其他网络也大同小异,包括mmdetection等,也差不多。
如果想直接用现成yolov5的检测界面,可以参考这篇文章,Pyqt搭建YOLOV5目标检测界面
2021.11.22 更新
下面的代码片段大家可以参考着实现,如果直接拖拽到最新版的yolov3文件夹中运行可能会出错,应该我当时那个代码片段写的比较早,后续yolov3更新了,有些函数名有变动,所以直接运行会出错。我这里有当时和这个代码片段对应的yolov3的代码,但是不太知道这是哪个版本的yolov3。
所以有需要的朋友直接在公众号:万能的小陈后台回复qtv3,获取整个文件夹以及模型,配置环境后可以直接运行,配置环境教程可以参考这里 ps:ultralytics公司的yolov3和tyolov5环境是通用的。
\
实现效果如下所示,可以检测图片、视频以及摄像头实时检测。

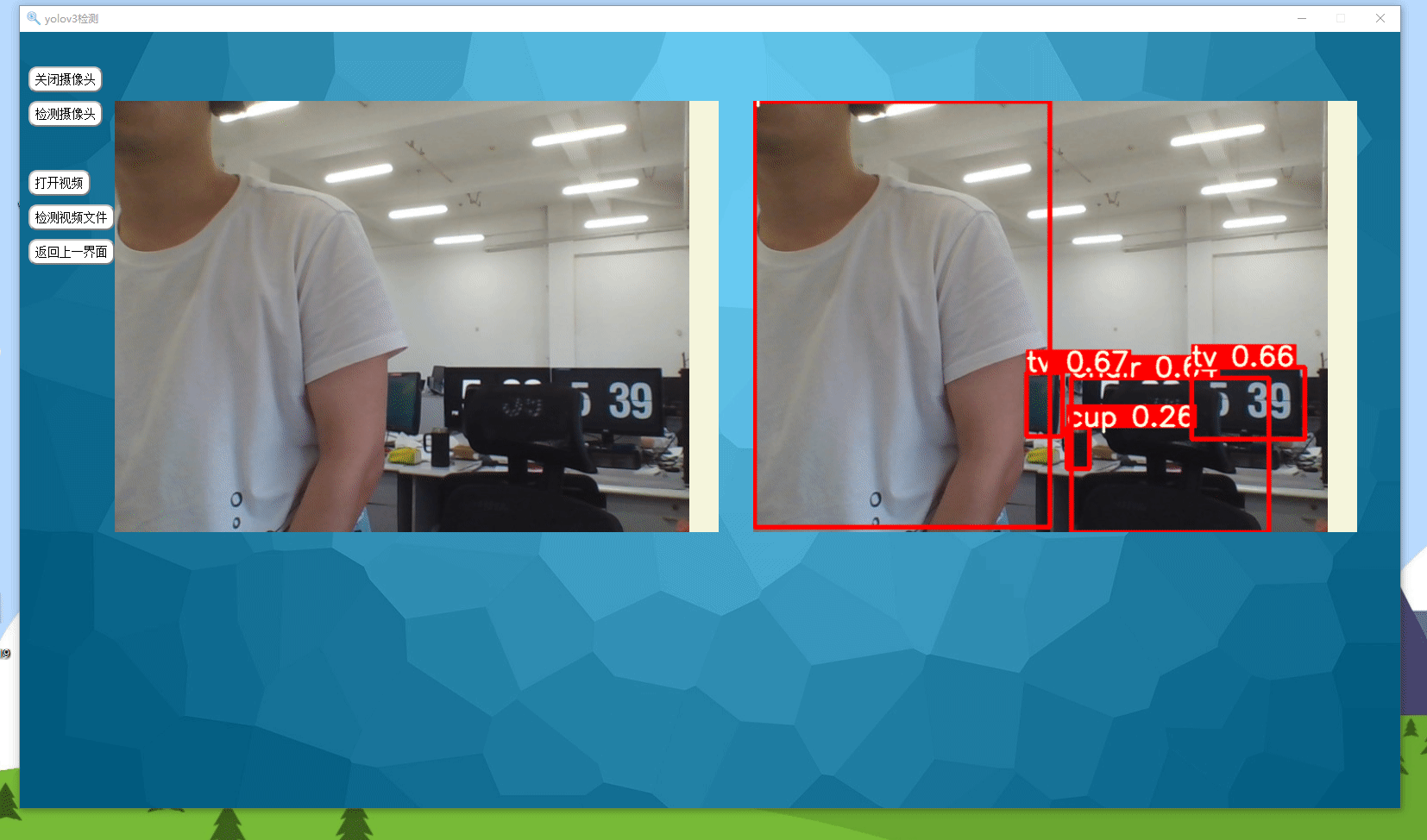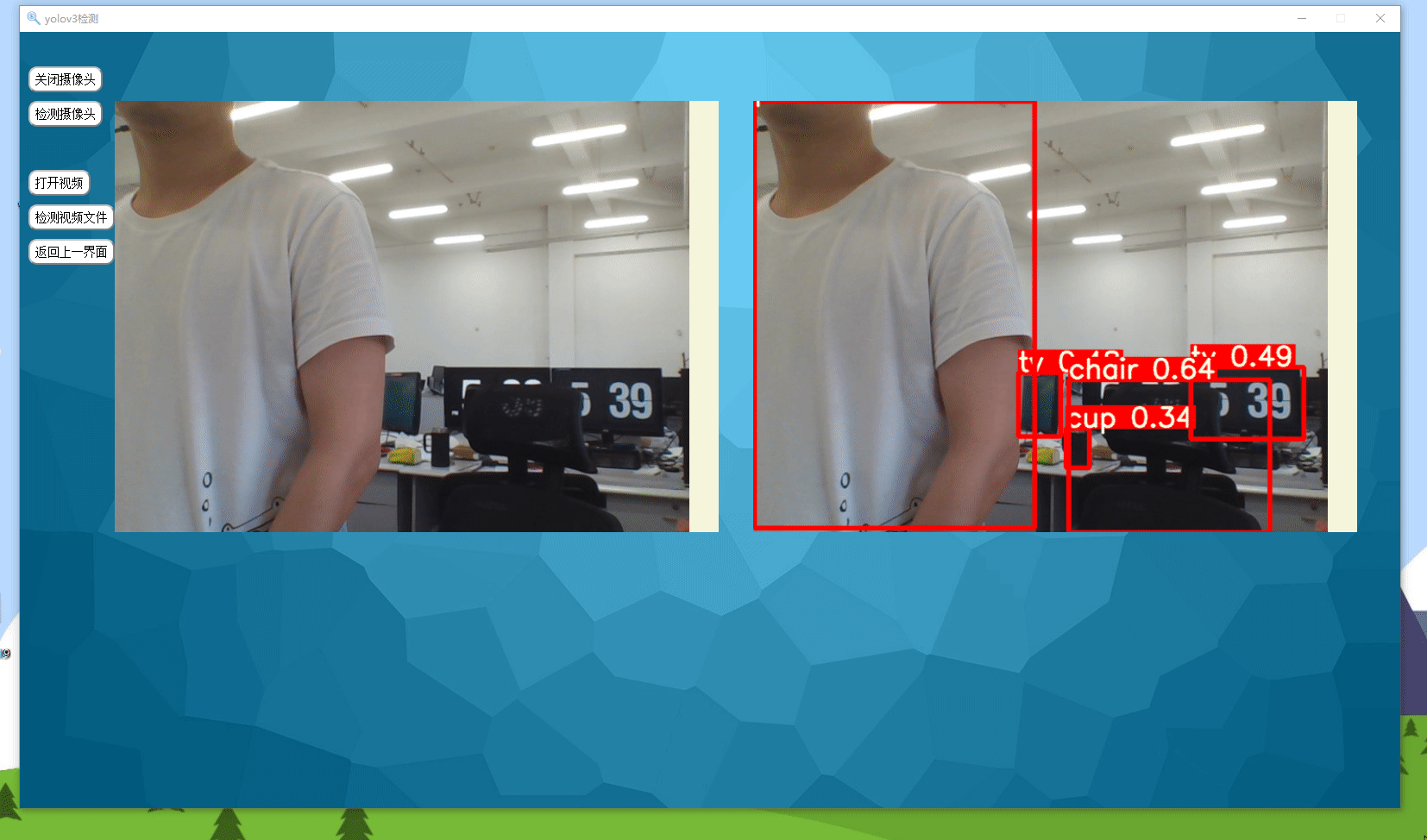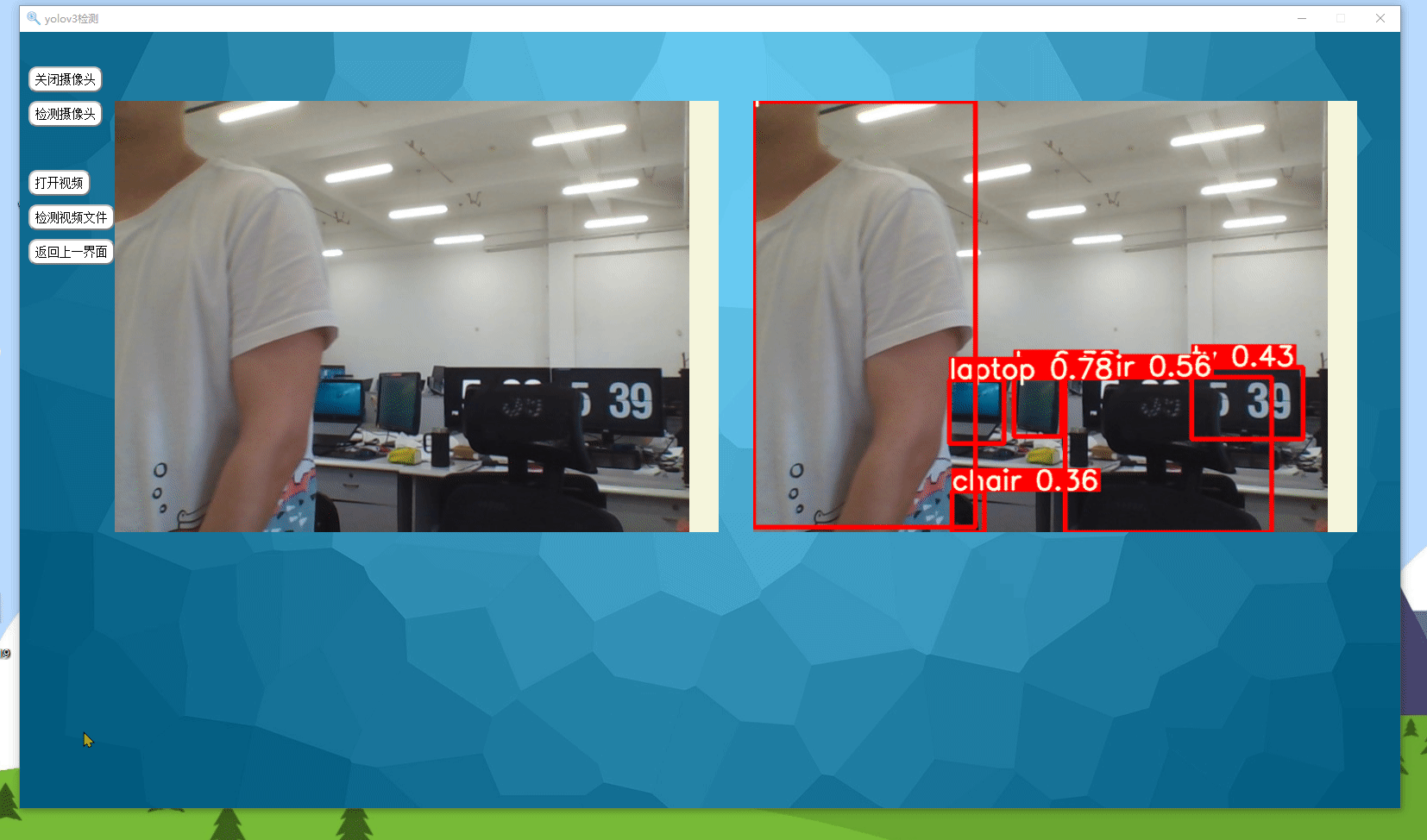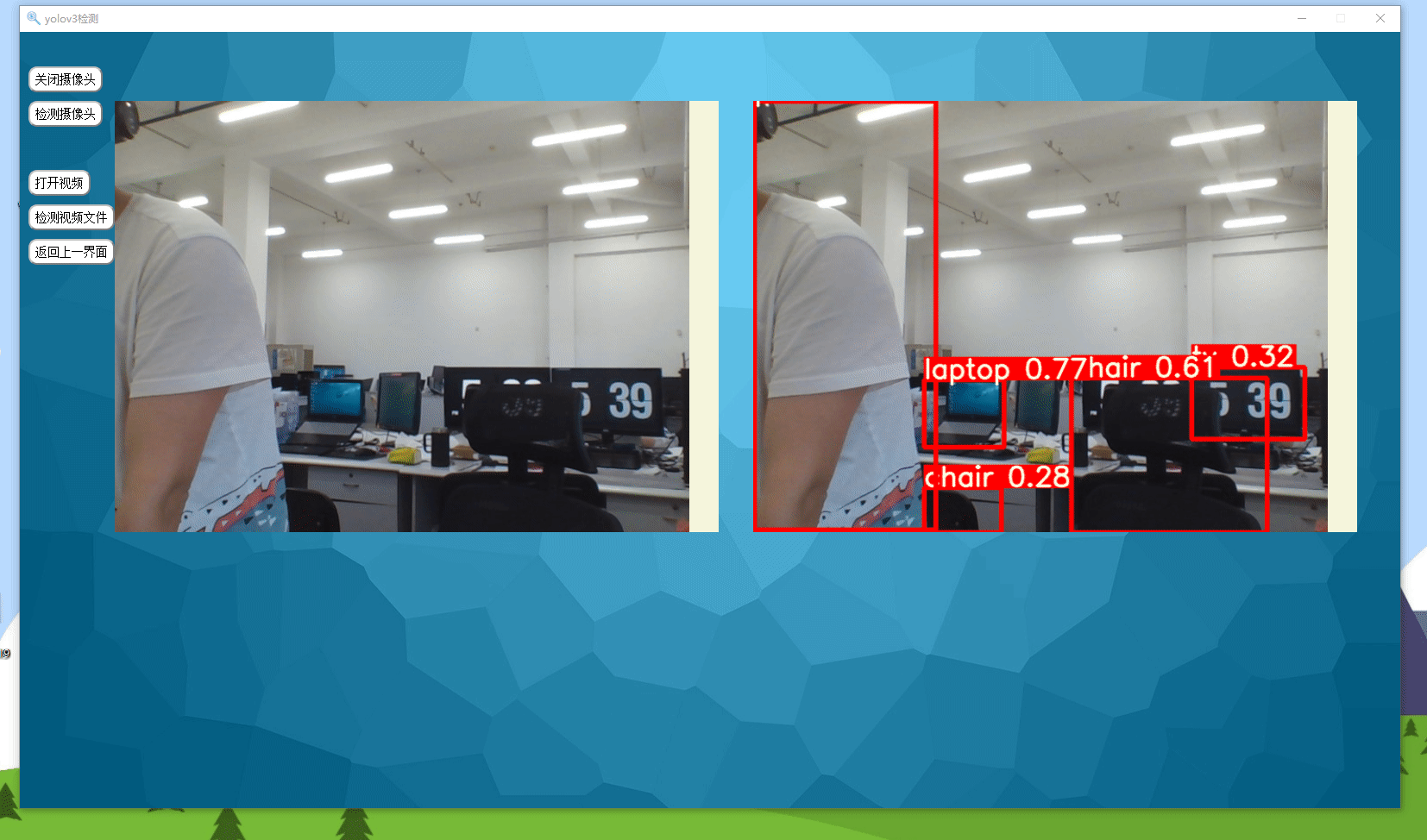
0.准备工作
0.1 环境: cuda10.1 pytorch1.8 torchvision0.9 python3.8,windows10(如果在ubuntu下使用,请自行更改路径);
0.2 yolov3采用pytorch,代码在https://github.com/ultralytics/yolov3。github打不开的点这里(我把GitHub上面的代码导入到了这个Gitee仓库里)
0.3 yolov3训练自己的数据集可以参考这些博客
YOLOV3训练自己的数据集(PyTorch版本)
如何使用Pytorch实现YOLOv3训练自己的数据集(详尽版) ,最后需要一个训练好的模型文件。
0.4 本文着重记录一下Pyqt搭建可视化界面的实现过程
1.单张图片检测
1.1 可以使用detect.py文件检测出自己训练的模型或者也可以直接使用官方的模型。(环境配置无误,能正确运行程序即可)。
1.2使用python写一个简单的QT界面,大致如下所示,三个按钮,两个label,现在先实现图片的检测,所以使用前两个按钮。
界面代码如下所示:
import sys from PyQt5.QtWidgets import * '''单张图片检测''' class picture(QWidget): def __init__(self): super(picture, self).__init__() self.resize(1600, 900) self.setWindowTitle("yolov3目标检测平台") self.label1 = QLabel(self) self.label1.setText(" 待检测图片") self.label1.setFixedSize(700, 500) self.label1.move(110, 80) self.label2 = QLabel(self) self.label2.setText(" 检测结果") self.label2.setFixedSize(700, 500) self.label2.move(850, 80) self.label3 = QLabel(self) self.label3.setText("") self.label3.move(1200, 620) self.label3.setStyleSheet("font-size:20px;") self.label3.adjustSize() btn = QPushButton(self) btn.setText("打开图片") btn.move(10, 30) btn1 = QPushButton(self) btn1.setText("检测图片") btn1.move(10, 80) btn3 = QPushButton(self) btn3.setText("摄像头和视频检测") btn3.move(10, 160) if __name__ == '__main__': app = QApplication(sys.argv) ui_p = picture() ui_p.show() sys.exit(app.exec_())

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
1.3在检测之前,我们先试着显示一张图片在界面上,可以写一个函数如def open_image(),写在picture类里面。使用一个槽函数关联按钮打开图片,如:btn.clicked.connect(self.open_image)
此时点击按钮会执行open_image()的内容。具体代码如下:
def open_image(self):
imgName, imgType = QFileDialog.getOpenFileName(self, "打开图片", "", "*.jpg;;*.png;;All Files(*)")
'''上面一行代码是弹出选择文件的对话框,第一个参数固定,第二个参数是打开后右上角显示的内容
第三个参数是对话框显示时默认打开的目录,"." 代表程序运行目录
第四个参数是限制可打开的文件类型。
返回参数 imgName为G:/xxxx/xxx.jpg,imgType为*.jpg。
此时相当于获取到了文件地址
'''
imgName_cv2=cv2.imread(imgName)
im0= cv2.cvtColor(imgName_cv2, cv2.COLOR_RGB2BGR)
#这里使用cv2把这张图片读取进来,也可以用QtGui.QPixmap方式。然后由于cv2读取的跟等下显示的RGB顺序不一样,所以需要转换一下顺序
showImage = QtGui.QImage(im0, im0.shape[1], im0.shape[0], 3 * im0.shape[1], QtGui.QImage.Format_RGB888)
self.label1.setPixmap(QtGui.QPixmap.fromImage(showImage))
#然后这个时候就可以显示一张图片了。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
点击按钮后,效果图如下所示

1.4有一种比较简单的实现图片检测程序的办法。就是前面如果你准备工作做好,你执行detect.py文件,会自动检测 data/images目录下的图片,并且在runs/detect/exp下面生成标注好的图片。可以在点击检测时候,把之前获取到的待检测图片复制一份到data/images目录下,然后执行detect.py,在runs/detect/exp里面获取标注好的图片,并且显示在界面上。(可以把detect.py的主函数封装为一个子函数,在这个里面直接调用封装好的子函数,不过这样的缺点是检测慢,因为检测之前要加载模型,会比较慢,每次检测相当于都加载了一次模型)
1.5根据以上不足,想到从detect.py文件下手,把模型加载部分单独拿出来,在第一次界面打开时候加载,之后就不需要加载。
在detect.py文件中,detect函数里面找到加载模型的部分,拿出来写成一个子函数,然后在执行detect函数时候,把model作为参数传入进去。
model = attempt_load(weights, map_location=device) # load FP32 model
- 1
写成的子函数为
def my_lodelmodel():
device = select_device()
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='weights\\yolov3.pt',
help='model.pt path(s)')
opt = parser.parse_args()
weights=opt.weights
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
return model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
至此,速度快了一些,还可以再做一些优化。
①传图像时候没必要复制一份到data/images目录,可以直接把读取的图片路径通过参数传递方式传给detect函数。
②在detect函数中直接把标注好的图像数组返回出来,这样就不必在runs/detect/exp下面找了。
至此,单张图片检测基本完成。
2. 视频、摄像头检测
2.1 在detect函数中,官方对于视频、摄像头检测是从每秒的视频中抽取30帧,对每帧进行检测。
2.2 同理,先试着使用pyqt显示视频、摄像头在界面上。
2.3 显示视频原理为:
使用QFileDialog.getOpenFileName函数打开一个视频文件,得到视频文件的地址,
使用self.cap_video=cv2.VideoCapture()打开视频,
使用flag, self.image = self.cap_video.read(),获取视频的每一帧,然后把每一帧显示(和图片显示基本一样)在label控件上面,不过注意的是要使用到定时器,self.timer_camera1 = QtCore.QTimer()。
2.4 显示实时摄像头原理为:
self.cap = cv2.VideoCapture(),参数为空时候打开摄像头。
flag, self.image = self.cap.read(),获取摄像头的每一帧,然后把每一帧显示。(也需要用到定时器)
2.5 把每一帧的检测图片传给detect函数,进行检测,并把返回值图像绘制在label控件上面。
源代码链接
关注公众号:万能的小陈,回复qtv3即可获取。
代码使用说明: 权重文件请放在 weights/yolov3.pt
如果下载有权重版本,下载后配置好环境,直接运行ui_yolov3.py即可。
如果下载无权重版本,请自行下载权重后放在weights/yolov3.pt 这里,然后在运行ui_yolov3.py即可。

注意事项
1 环境,在配置好的yolov3环境前提下,在安装PyQt5模块,至于其他的模块在运行时候,缺少什么就直接安装什么吧。(如果实在配不好环境的,可以私聊我,关注公众号:万能的小陈,回复 pyqt5 ,发给你一个现成的环境,复制到anaconda目录下就可以用,有其他问题也可在公众号私聊我。)
2 如果想把整个项目打包为可执行exe时候,有可能会在这里报错。解决方法如下:把device = select_device() 改为 device ='cuda:0'。
3 因为已经做完有一段时间了,所以当时踩的一些坑后面忘记了,后面想到再补充吧。

