
- 1用于语音识别的大语言模型finetuning_语音识别的语言模型
- 2vue3的自动引入ref,computed,reactive等,下载插件 unplugin-auto-import ,在Vite.config.ts 配置_vue3自动引入ref
- 3SpringBoot自定义注解防止表单重复提交_@repeatsubmit
- 4adb安装模式修改为speed模式、_adb speed模式
- 5AGI|一篇小白都能看懂的RAG入门介绍!_rag 关键词
- 6LLC谐振电路(一) 整流电路总结_整流电路 效率比较
- 7ArkTS开发鸿蒙OS连接mongoDB(后端node.js)2024最新教程_harmony mongo
- 8WebSocket的简单入门使用_websocket用法
- 9HBuilderx运行手机测试
- 10好用分享_Free ChatGPT Site List
读《EMOQ-TTS: EMOTION INTENSITY QUANTIZATION FOR FINE-GRAINED CONTROLLABLE EMOTIONAL TEXT-TO-SPEECH》
赞
踩
0 Abstract
虽然近年来文本到语音(TTS)的研究取得了显著进展,但仍局限于情感语音合成。为了产生情感话语,大多数作品都利用了从情感标签或参考音频中提取的情感信息。然而,由于话语层面的情绪条件,它们导致了单调的情绪表达。在本文中,我们提出了EmoQ-TTS,它通过调节具有细粒度情绪强度的音素级情绪信息来合成具有表现力的情绪言语。在这里,情感信息的强度是通过基于距离的强度量化来表示的,不需要人为标记。我们也可以通过人工调节强度标签来控制合成语音的情绪表达。实验结果表明,EmoQ-TTS在情感表现力和可控性方面具有优越性。
1 Introduction
最近,由于深度学习的发展[5,6],端到端文本到语音(TTS)系统得到了显著的改进[1,2,3,4]。虽然目前基于TTS模型的合成语音已经取得了优异的性能,但在合成具有音高、声调、语速等副语言特征(paralinguistic features)的表达性语音方面仍存在一定的局限性。特别是情感语音合成是一项具有挑战性的任务,因为情感信息受到语音各种副语言特征的影响.
对于情感语音合成,常用的方法是从参考音频[7,8]或情感标签[9,10]中提取全局情感信息。但是,这些方法的缺点是,合成语音只有一个全局信息,表达单调。为了产生类似于人类自然语言的富有表现力的情感语言,应在音素层面考虑根据情感强度进行细粒度的情感表达。已有几项研究试图通过对具有代表性的情绪嵌入进行缩放[11,12]
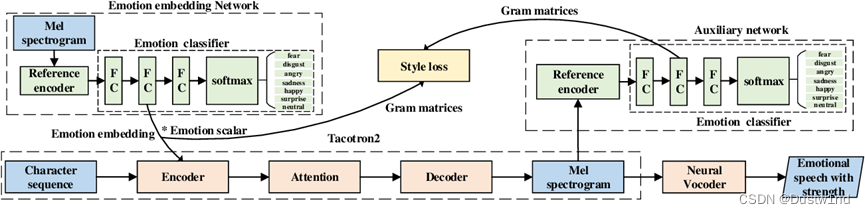
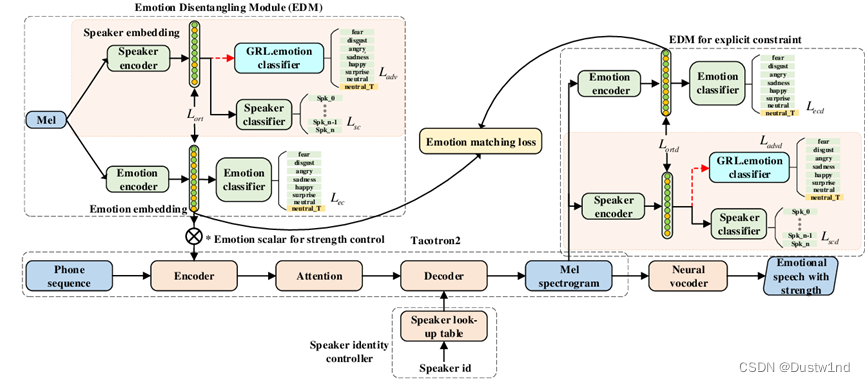
或插值[13,14]来反映细粒度的情绪表达。然而,它们也存在音频质量不稳定的问题,并且很难找到合适的缩放或插值参数。在[15]的情况下,该模型预测从学习到的排序函数[16]【文章提出了一个新的Idea, 不再是用传统的二值去标记一幅图像含不含attribute,而是用对比的关系去描述图像,对于某个attribute,一幅图像呈现的比另一幅图像多】中提取的按音素的强度标量。但是,该方法对全局标签的依赖较大,因此,基于强度标量的情绪表达控制不稳定。
为了解决上述问题,本文提出了EmoQ-TTS,它通过基于细粒度情感强度的音素级情感信息来合成表达性情感语音。为了反映适当的情绪表达,我们使用强度伪标签,并通过基于距离的强度量化,而无需人类标签。EmoQ TTS通过仅从文本中预测适当的情绪强度,更具表现力地合成语音。此外,我们可以通过手动调节强度标签来轻松控制情绪表达。实验结果表明,我们的系统成功地实现了比传统方法更好的情感表达和可控性。
2.1 Model Architecture
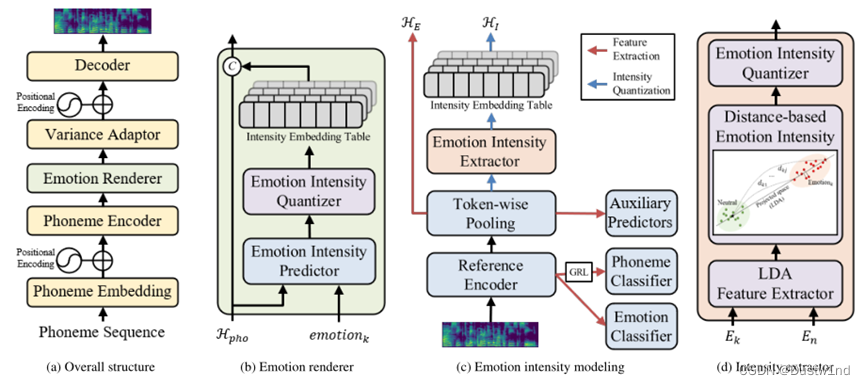
EmoQ TTS的整个架构如图1a所示。EmoQTTS基于FastSpeech2[17],它由编码器、解码器和方差适配器组成。为了合成细粒度情感语音,我们对FastSpeech2架构进行了如下修改:首先,我们引入了一个情感渲染器,根据细粒度情感强度提供音素级的情感信息。这使得所有方差信息,包括音调、能量和持续时间,都会受到细粒度情绪强度的影响。其次,将持续时间预测器移到方差适配器的末尾。这导致所有方差信息都在音素级进行处理,这在语音质量方面已被证明优于帧级方法(Fastpitch提出)。
2.2 Emotion Renderer
H-pho + Emotion_strength[x] ->【0,1】-> MSE-loss
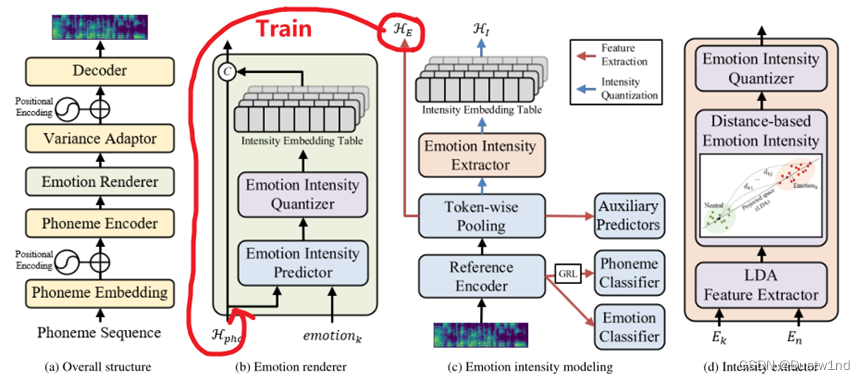
情感渲染器根据细粒度情感强度提供音素级情感信息。如图1b所示,情感渲染器由强度预测器、强度量化器和强度嵌入表组成。当提供音素隐藏序列H-pho和第k个情感类别emotion-k时,强度预测器将适合emotion-k的音素情感强度标量序列预测为0到1之间的值。强度预测器通过平均绝对误差(MAE)[19]损失进行优化,使预测强度标量序列和地面真值强度标量序列之间的差异最小化。
对于鲁棒性训练,强度标量通过情绪强度量化器定期量化为N-I大小的情绪强度伪标签集(pseudo-labels)。这里,N-I表示量化强度伪标签的总数。此外,我们还引入了一个强度嵌入表。量化强度伪标签集是每个情绪嵌入表的条目索引。最后,将音素强度嵌入序列连接到音素隐藏序列。图1b中的“C”表示串联。通过情绪强度建模,设计了地面真值强度标量和强度嵌入表。
在推理过程中,EmoQ TTS通过调节预测强度标量的量化强度嵌入来合成情感表达语音。此外,EmoQ TTS通过手动控制自定义标签的强度来控制合成语音的情感表达
3 EMOTION INTENSITY MODELING
3.1. Emotion Feature Extraction
在第一阶段,我们训练参考编码器从mel谱图中提取聚类情感嵌入。参考编码器由三个1D卷积层组成,它们为每一帧维护时间信息。为了提取有区别的情感嵌入,我们应用了情感分类器和带有梯度反转层(GRL)的音素分类器[20],如图1c所示。这些分类器在不中断音素信息的情况下,根据情感对特征向量进行聚类。这两种分类器都使用softmax层进行了优化,然后使用交叉熵损失。在音素分类器的情况下,在反向传播过程中通过梯度反转层乘以负标量来反转梯度
然后,令牌池层(Token-wise Pooling)通过在每个音素边界的范围内求平均值,将帧级序列转换为音素级序列。在这里,我们添加了两个辅助预测器,分别预测音高和能量。这些预测因子通过预测与情绪直接相关的副语言特征,使得聚类嵌入能够很好地反映情绪信息。使用均方误差(MSE)[21]损失优化辅助预测器
(((参考音频编码器除了把情绪作为标签外,把基频和能量等作为预测值反传是否也能对信息解离起到一定的效果???)))
3.2. Distance-based Emotion Intensity Quantization
在第二阶段,我们通过强度量化生成情绪强度伪标签和强度嵌入表。
如图1d所示,第k个情绪嵌入E-kj和中性嵌入项E-nj的两个簇被送入情绪强度提取器
其中j∈ {1,2,···,Nk} Nk是Ekj的总数。在这项工作中,我们对从参考编码器中提取的每个情感使用整个情感嵌入
为了提取合适的强度,我们引入了情感距离,它表示向量与中性情感质心的相对距离
两个假设
1中性情绪是其他情绪中强度最低的。
2情绪强度随着远离中性情绪而增加。
由于多维空间太不稳定,无法测量距离,情绪强度提取程序将提供的情绪嵌入到单个向量,实验选择了线性判别分析(LDA)[22]方法,这是一种对类敏感的投影方法。最优投影向量w∗ 通过最大化二元类LDA的目标函数得到
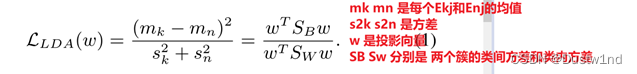
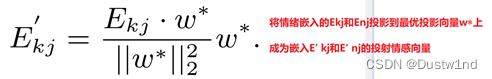

提取情感距离后,去除每种情感的异常值。通过最小-最大归一化,情感距离变为强度标量,其值介于0和1之间。这个强度标量以固定的间隔量化为NI大小的情绪强度伪标签。

- EXPERIMENTS AND RESULTS
4.1 Experimental Setup
在情感强度量化器中,对于每个情感,作为量化强度伪标签总数的NI被设置为16。在多说话人EmoQ TTS的情况下,我们在参考编码器中添加了一个带有GRL的说话人分类器,以去除情感嵌入中的说话人信息。
4.2. Model Performance
对照组:对于基线,我们使用了两种方法:TP-GST[8]和细粒度情感预测模型(FEP),前者预测文本中的全局风格嵌入,后者也预测文本中的音素级强度标量。
评价指标:MCD MOS RMSE 基于语音情感识别的外部模型计算情感分类器准确性
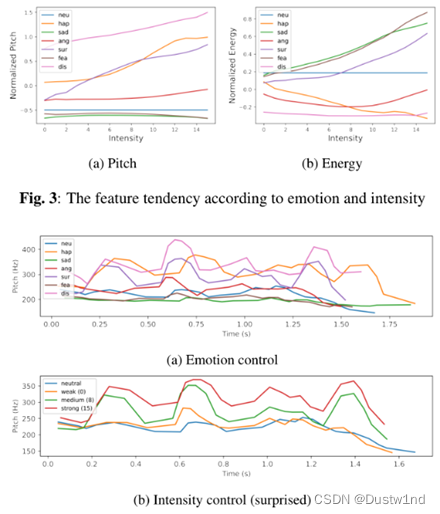
4.3. Emotion Controllability
为了展示控制情绪表达的能力,我们将音调和能量的趋势可视化
可以看出,即使在一个样本中,音高和持续时间也能根据情绪和强度很好地反映出来
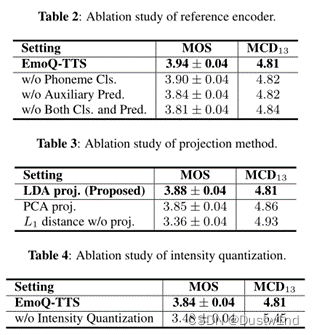
4.4 ablation Study
此部分证明了LDA模型和强度量化策略的优越性
- CONCLUSION AND FUTURE WORKS
本文提出了EmoQ-TTS,它通过预测音素方面的情感信息和细粒度的情感强度来合成富有表情的情感语音。为了在没有人为标记的情况下反映情感表达,我们提出了情感强度模型。此外,我们通过基于距离的量化强度伪标签和强度嵌入表实现了合成语音的鲁棒性。实验结果表明,EmoQ-TTS在情感表达方面具有优越性。此外,我们还证明了通过手动强度标签可以轻松控制情绪表达。

