
- 1【Leetcode每日一题】34. 在排序数组中查找元素的第一个和最后一个位置(二分、lower_bound、upper_bound)_leetcode 二分查找 lower_bound
- 2ESP32学习笔记十九之BLE协议GAP&GATT_remove the bond device
- 3HarmonyOS使用多线程并发能力开发_鸿蒙worker线程最大激活数
- 4华为升腾网络计算机干嘛用的,华为AI芯片昇腾910是干什么的?华为升腾910与麒麟980哪个性能好?...
- 5Java毕业设计-基于Springboot框架的小区物业管理系统项目实战(附源码+论文)_基于springboot小区物业管理系统的设计与实现
- 6MobaXterm连接出现 Network error: Connection timed out 问题解决
- 7LIO-SAM代码总结_lio-sam中的gnss约束代码
- 8qemu-system-x86_64(1)-Linux手册页_qemu-system-x86_64手册
- 9(笔记5)指针与二位数组,指针数组与数组函数,指针函数_用指针实现:定义两个字符型指针p1、p2分别用指向字符数组sub1和 sub2,然后输
- 10ElasticSearch重建/创建/删除索引操作 - 第501篇_elasticsearch 删除重建索引
LLM(四)| Chinese-LLaMA-Alpaca:包含中文 LLaMA 模型和经过指令微调的 Alpaca 大型模型_llm 重复性惩罚
赞
踩

论文题目:《EFFICIENT AND EFFECTIVE TEXT ENCODING FOR CHINESE LL AMA AND ALPACA》
论文地址:https://arxiv.org/pdf/2304.08177v1.pdf
Github地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca
一、项目介绍
- 通过在原有的LLaMA词汇中增加20,000个中文符号来提高中文编码和解码的效率,并提高LLaMA的中文理解能力;
- 采用低秩适应(LoRA)的方法来有效地训练和部署中文的LLaMA和Alpaca模型,使研究人员能够在不产生过多计算成本的情况下使用这些模型;
- 评估了中文羊驼7B和13B模型在各种自然语言理解(NLU)和自然语言生成( NLG)任务中的表现,表明在中文语言任务中比原来的LLaMA对应模型有明显的改进;
- 公开了研究资源和结果,促进了NLP社区的进一步研究和合作,并鼓励将LLaMA和Alpaca模型改编为其他语言。
二、Chinese LLaMA
对于中文而言,LLaMA存在的问题:
- LLaMA tokenizer的原始词汇中只有不到一千个中文字符。尽管LLaMA tokenizer通过回退到byte来支持所有的中文字符,但这种回退策略大大增加了序列的长度,降低了中文文本的处理效率;
- byte tokens并不是专门用来表示汉字的,因为它们也被用来表示其他UTF-8令牌,这使得字节令牌很难学习汉字的语义。
为了解决这些问题,作者建议用额外的中文标记来扩展LLaMA tokenizer,并为新的tokenizer适配模型:
- 为了加强tokenizer对中文文本的支持,作者首先用SentencePiece在中文语料库上训练一个中文tokenizer,使用的词汇量为20,000。然后通过组合它们的词汇,将中文tokenizer合并到原始的LLaMA tokenizer中。最终得到了 一个合并的tokenizer,称之为中文LLaMA tokenizer,其词汇量为49,953;
- 为了适应中文LLaMA tokenizer的模型,作者将词嵌入和语言模型头的大小从形状V×H调整为V′×H,其中V=32,000代表原始词汇量,V′=49,953是中文LLaMA tokenizer的词汇量。新的行被附加到原始嵌入矩阵的末尾,以确保原始词汇中的标记的嵌入仍然不受影响。
实验表明,中文LLaMA tokenizer产生的tokens数量大约是原始LLaMA tokenizer的一半,如表1所示。正如我们所看到的,使用中文LLaMA tokenizer大大减少了编码长度,在固定的语境长度下,模型可以容纳大约两倍的信息,而且生成速度比原来的LLaMA tokenizer快两倍。

在完成上述适应步骤后,作者在标准的休闲语言建模(CLM)任务中使用中文-LLaMA tokenizer对中文-LLaMA模型进行了预训练。
三、Chinese Alpaca
在获得预训练的中文LLaMA模型后,作者按照斯坦福大学Alpaca中使用的方法,应用self-instructed微调来训练指令跟随模型。每个例子由一条指令和一个输出组成,将指令输入模型,并提示模型自动生成输出。这个过程类似于普通的语言建模任务。作者采用以下来自斯坦福大学Alpaca的提示模板,用于自我指导的微调,这也是在推理过程中使用的:

模型的loss只会技术输出部分,公式如下所示:

作者的方法和Stanford Alpaca的一个关键区别是,作者只使用了没有Input字段的例子设计的提示模板,而Stanford Alpaca为有Input字段和没有Input字段的例子分别采用了两个模板。如果例子中包含一个非空的Input字段,作者使用一个"/n "将指令和输入连接起来,形成新的指令。
PS:Alpaca模型有一个额外的填充标记,导致词汇量为49,954。
四、使用LoRA进行微调
Low-Rank Adaptation (LoRA)是一种参数高效的训练方法,它在预训练模型层旁支引入了可训练A、B矩阵,通过调整秩r来控制训练参数和模型效果,冻结大模型参数,只训练这两个A、B矩阵,这种方法大大减少了可训练参数的数量,LoRA形式如下图所示:
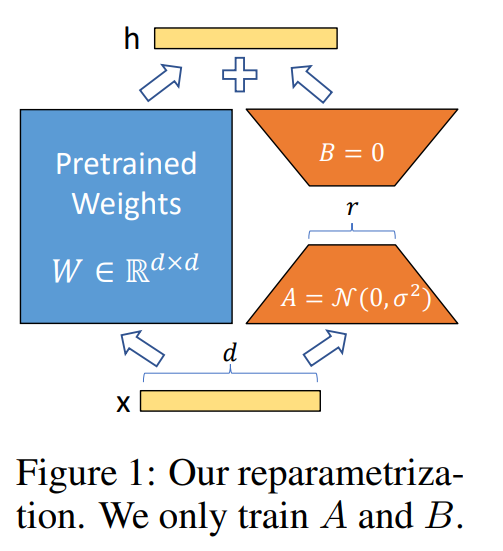
LoRA的一般公式如下,其中r是预先确定的秩,d是隐藏的大小,A和B是分解的可训练矩阵:
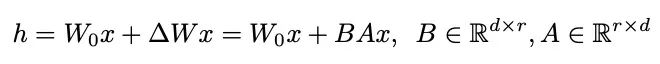
为控制预算,作者在chinese-LalaMA/Alpaca模型的实验中都讲应用LoRA,包括预训练和微调阶段。作者主要将LoRA引入注意力模块的权重中,实验效果请参考下一节和表2。
五、实验设置
5.1、用于预训练和微调的实验设置
7B版本
预训练:作者用原始的LLaMA权重初始化中文-LLaMA模型,收集中文BERT-wwm、MacBERT、LERT等模型使用的语料(大概20GB)进行预训练。预训练过程包括两个阶段:
- 第一阶段:冻结transformer编码器的参数,只训练embeddings来适应新增加的中文词向量,同时尽量减少对原始模型的干扰;
- 第二阶段:将LoRA权重(适配器)添加到注意力机制中,并训练embeddings、LM头和新增加的LoRA参数;
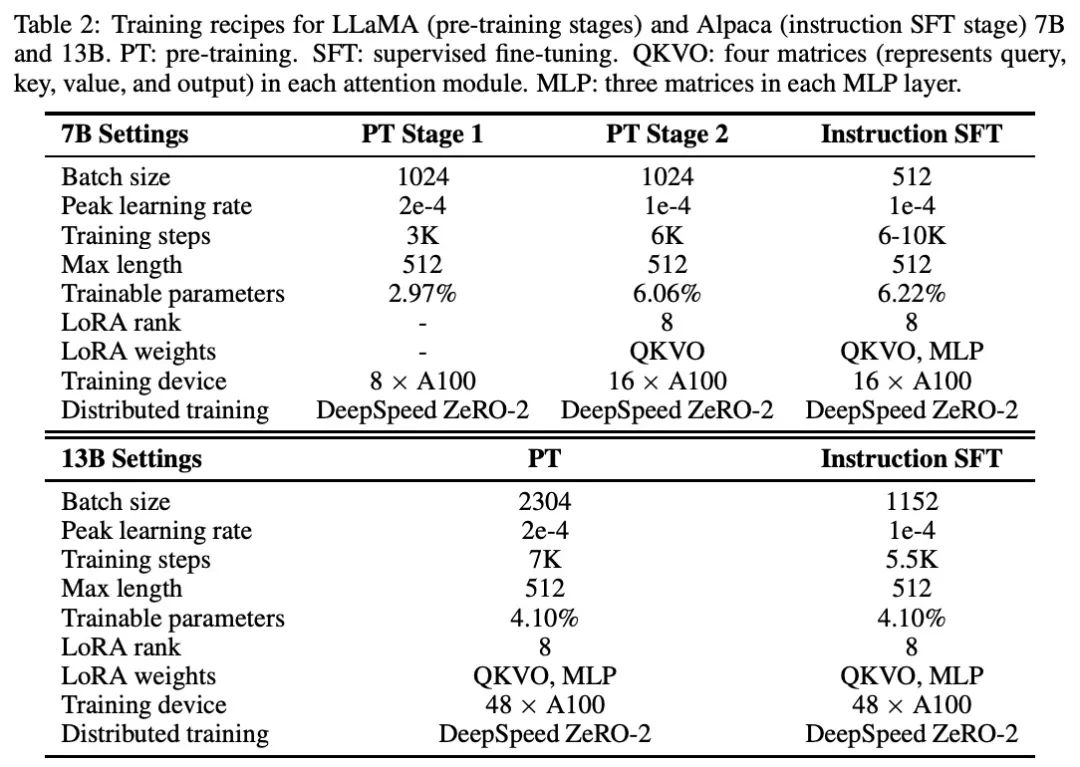
指令微调:在得到预训练的模型后,作者在MLP层添加LoRA适配器来增加可训练参数的数量。微调数据包括翻译、pCLUE3 , Stanford Alpaca,以及爬虫的SFT数据。对于抓取的数据,作者采用从ChatGPT(gpt-3.5-turboAPI)中自动获取数据的self-instruction方法。超参数可以参考表2,微调数据的详细信息可以在表3中查阅。
13B版本
预训练:13B模型的预训练过程与7B模型的预训练过程基本相同,作者跳过了预训练的第1阶段,直接将LoRA应用于注意力和MLPs的训练,同时将嵌入和LM头设置为可训练。
指令微调:LoRA设置和可训练参数与预训练阶段保持一致。作者在13B模型的微调中使用了额外的100万个爬行的self-instruction的数据,使得13B模型的总数据量为3M,超参数可以参考表2。
5.2、解码的设置
LLMs的解码过程在决定生成文本的质量和多样性方面起着关键作用。在实验中,作者设置的解码超参数如下表所示:
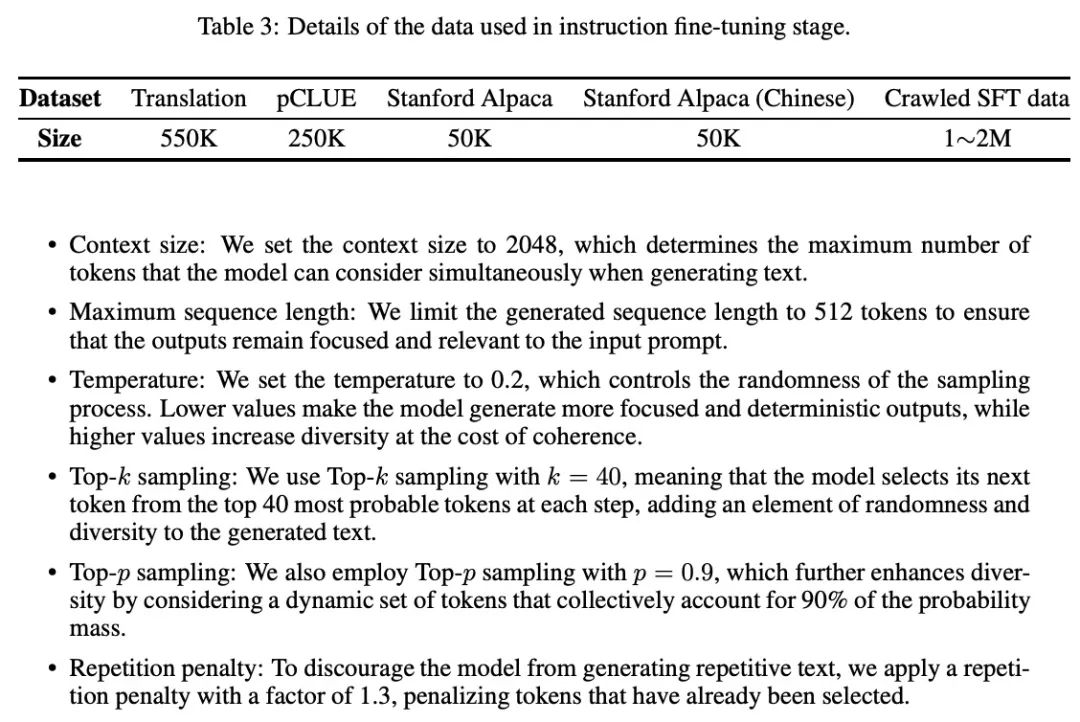
- 上下文大小:上下文大小设置为2048,这决定了模型在生成文本时可以同时考虑的最大数量的标记;
-
最大的序列长度:生成的序列长度限制在512个标记,以确保输出结果保持重点,并与输入提示相关;
-
温度:温度设置为0.2,控制采样过程的随机性。较低的值使模型产生更集中和确定的输出,而较高的值则以一致性为代价增加多样性;
-
Top-k抽样:使用k=40的Top-k抽样,这意味着模型在每一步从最有可能的40个标记中选择其下一个标记,为生成的文本添加随机性和多样性元素;
-
Top-p抽样:采用了p=0.9的Top-p抽样,通过考虑集体占概率质量90%的动态标记集,进一步提高了分歧度;
-
重复性惩罚:为了阻止模型生成重复的文本,应用了一个系数为1.3的重复惩罚,惩罚那些已经被选中的标记。
PS:这些值对于每个应用场景来说可能都不是最佳的。作者没有对每个任务的这些超参数进行进一步的调整,以保持一个平衡的观点。
5.3、在CPU上部署
在个人电脑上部署大型语言模型,特别是在CPU上部署,由于其巨大的计算需求,历来都是一个挑战。然而,在许多社区努力的帮助下,如llama.cpp,用户可以有效地将LLM量化为4bit形式,大大减少内存使用和计算需求,使LLM更容易部署在个人电脑上,这也使得与模型的互动更加快速,并有利于本地数据处理。量化LLM并将其部署在个人电脑上,有几个好处。首先,它帮助用户保护数据隐私,确保敏感信息留在他们的本地环境中,而不是被传输到外部服务器。其次,它通过使计算资源有限的用户更容易接触到LLMs,实现了对它们的民主化访问。最后,它促进了利用本地LLM部署的新应用和研究方向的发展。总的来说,使用llama.cpp(或类似的)在个人电脑上部署LLM的能力,为在各种领域中更多地利用LLM和关注隐私铺平了道路。
在下面的章节中,作者将使用4bitRTN量化的中文羊驼进行评估,从用户的角度来看,这比面向研究的观点更现实。通常来说,4bit量化的模型一般比FP16或FP32模型的表现要差。
5.4、评价和任务设置
评估文本生成任务的性能可能具有挑战性,因为它们的形式有很大的不同,这与自然语言理解任务(如文本分类和提取式机器阅读理解)不同。继以前利用GPT-4作为评分方法的工作之后,作者也采用GPT-4为每个样本提供一个总分(10分制),这比人工评估更有效。然而,GPT-4可能并不总是提供准确的分数,所以作者对其评分进行人工检查,必要时进行调整。人工检查确保了评分的一致性,并反映了被评估模型的真实性能。作者使用以下提示模板对系统的输出进行评分:

通过采用GPT-4作为评分方法,结合人工检查,作者建立了一个可靠的评估框架,有效地衡量了中文羊驼模型在一系列自然语言理解和生成任务中的表现。评估集由160个样本组成,涵盖10个不同的任务,包括问题回答、推理、文学、娱乐、翻译、多轮对话、编码和伦理等。一项具体任务的总分是通过将该任务中所有样本的分数相加,并将总分归一化为100分来计算的。这种方法确保了评价集反映了模型在各种任务中的能力,为其性能提供了一个平衡而有力的衡量。
六、实验结果分析
在这一节中,作者介绍并分析了4bit量化的中文Alpaca-7B和Alpaca-13B模型进行实验的结果,如表4所示。
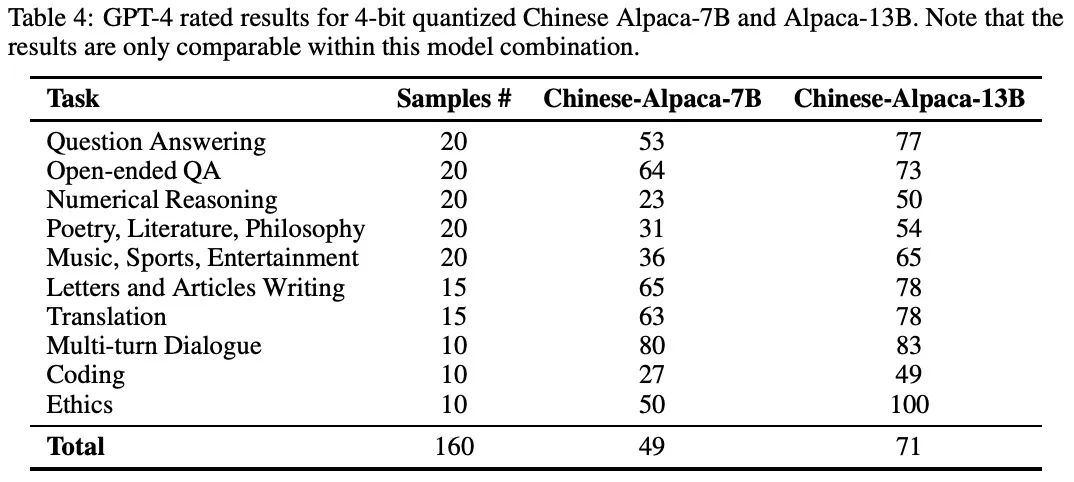
基于GPT-4在10个不同的NLP任务中的评分结果,共包括160个样本。值得注意的是,所提出的分数只可以相互比较,而不能与其他模型比较,这就需要对系统重新评分。
中文的Alpaca-7B和Alpaca-13B模型的性能都显示出比原来的LLaMA模型有明显的提高。中文的Alpaca-13B模型的性能一直优于7B变体,突出了增加模型容量的好处。
对于问题回答任务,中文的Alpaca-13B获得了77分,而7B模型为53分。在开放式问答中也可以看到类似的改进,13B和7B模型的得分分别为73和64。数字推理显示出更大的改进,13B模型的得分是50,而7B模型的得分是23。
在诗歌、文学、哲学、音乐、体育和娱乐等领域,13B模型的表现继续优于7B模型,其得分分别为54和65,而7B模型为31和36。在涉及信件和文章、翻译和多轮对话的任务中,性能差距仍然很大,13B模型一直取得较高的分数。有趣的是,即使作者没有使用任何多轮对话数据来调整系统,中文羊驼仍然有能力跟踪对话历史,并以连续的方式遵循用户指令。
编码任务表现出明显的改进,中文的Alpaca-13B模型得到49分,而7B模型得到27分。最显著的性能差异可以在伦理学任务中观察到,13B模型获得了100分的满分,而7B模型的得分是50分,这表明在拒绝任何不道德的用户输入方面表现出色。
总之,实验结果表明,中文的Alpaca-7B和Alpaca-13B模型都比原来的LLaMA模型有明显的改进,其中13B模型在所有任务中的表现一直优于7B模型。这强调了作者的方法在提高LLaMA和Alpaca模型的中文理解和生成能力方面的有效性。


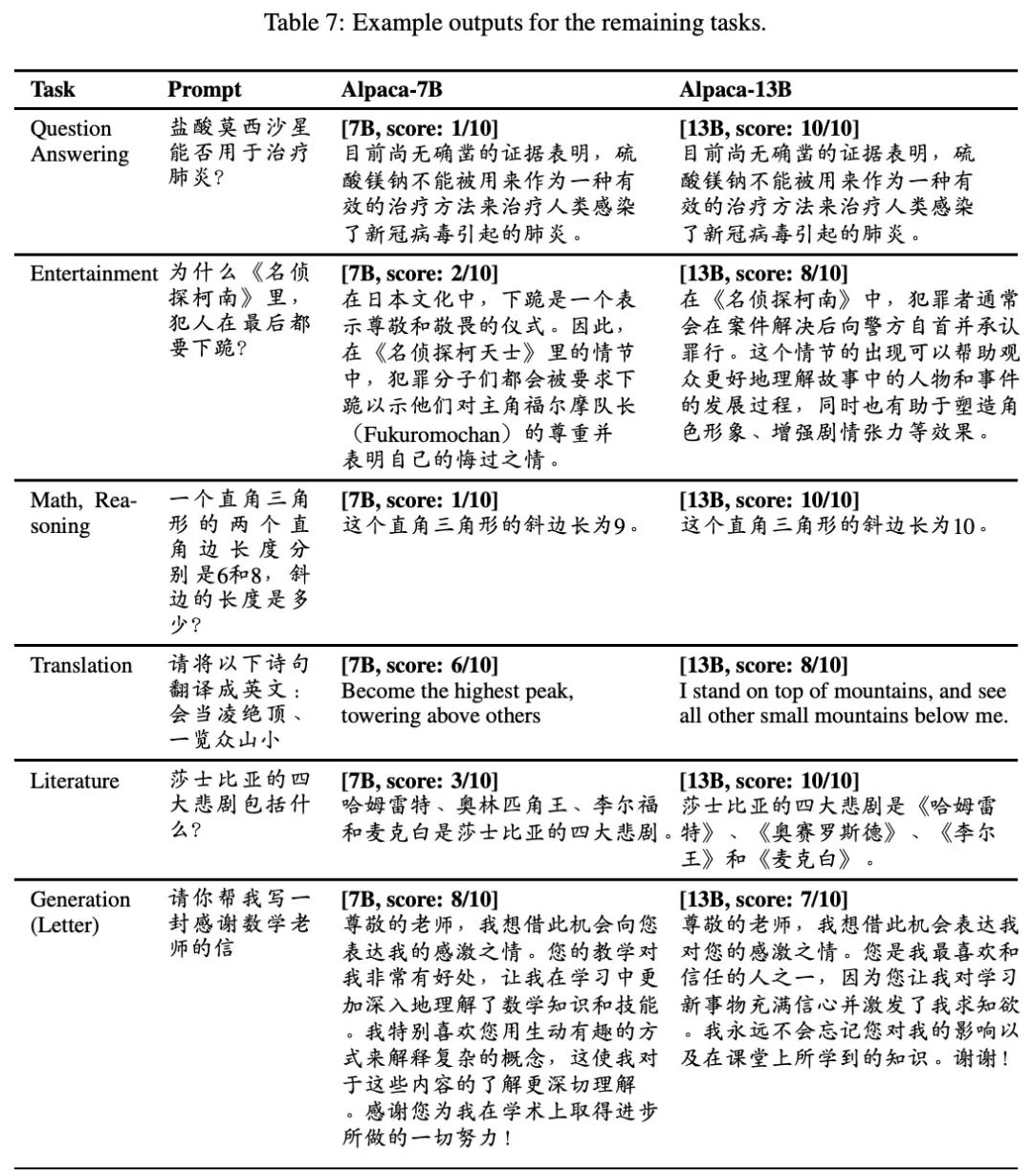
七、结论
在这份技术报告中,作者提出了一种方法来提高LLaMA模型的中文理解和生成能力。认识到原来的LLaMA中文词汇的局限性,通过加入2万个额外的中文符号来扩展它,极大地提高了它对中文的编码效率。在中文LLaMA的基础上,用指令数据进行了监督性的微调,从而开发出了中文羊驼模型,它表现出了更好的指令跟随能力。
为了有效地评估模型,在10种不同的任务类型中注释了160个样本,并使用GPT-4进行评估。实验表明,所提出的模型在中文理解和生成任务中明显优于原LLaMA,与7B变体相比,13B变体一直取得更大的改进。
展望未来,作者计划探索从人类反馈中强化学习(RLHF)或从人工智能指导的反馈中再强化学习(RLAIF),以进一步使模型的输出与人类的偏好一致。此外,作者打算采用更先进和有效的量化方法,如GPTQ等。此外,作者还打算研究LoRA的替代方法,以便更有效地对大型语言模型进行预训练和微调,最终提高它们在中文NLP社区各种任务中的性能和适用性。
限制条件
虽然这个项目成功地加强了对LLaMA和Alpaca模型的中文理解和生成能力,但必须承认有几个局限性:
- 有害的和不可预知的内容:结果表明,13B版本比7B版本有更好的能力来拒绝不道德的查询。然而,这些模型仍然可能产生有害的或与人类偏好和价值观不一致的内容。这个问题可能来自于训练数据中存在的偏见,或者模型在某些情况下无法辨别适当的输出;
- 训练不充分:由于计算能力和数据可用性的限制,模型的训练可能不足以达到最佳性能。因此,模型的中文理解能力仍有改进的余地;
- 缺少稳健性:在某些情况下,模型可能会表现出脆性,在面对对抗性输入或罕见的语 言现象时产生不一致或无意义的输出;
- 可扩展性和效率:尽管应用了LoRA和4bit量化,使模型更容易被更多的人接受, 但当与原来的LLaMA相结合时,模型的大尺寸和复杂性会导致部署上的困难,特别是对于计算资源有限的用户。这个问题可能会阻碍这些模型在各种应用中的可及性和广泛采用。
参考文献:
[1] https://arxiv.org/pdf/2304.08177v1.pdf

