
- 1测试工具分享:高效完成测试工作!
- 2智能科学与技术 毕业设计 - 选题建议 题目推荐 毕设指导 开题报告_人工智能毕业设计选题
- 3python tokenize_python – 滥用nltk的word_tokenize(已发送)的后果
- 4学C#好还是学C++好啊
- 5PyTorch: 序列到序列模型(Seq2Seq)实现机器翻译实战
- 6cvpr2013收录的文章_carl olsson, olof enqvist
- 7sklearn: TfidfVectorizer 中文处理及一些使用参数_tfidfvectorizer函数参数
- 8如何实现百度翻译接口——不用申请API接口密钥
- 9GPT-4技术报告_gpt4技术报告
- 10Android实现新闻列表
一文详解扩散模型:DDPM_怎么理解ddpm中的时间嵌入
赞
踩
作者:京东零售 刘岩
扩散模型讲解
前沿
人工智能生成内容(AI Generated Content,AIGC)近年来成为了非常前沿的一个研究方向,生成模型目前有四个流派,分别是生成对抗网络(Generative Adversarial Models,GAN),变分自编码器(Variance Auto-Encoder,VAE),标准化流模型(Normalization Flow, NF)以及这里要介绍的扩散模型(Diffusion Models,DM)。扩散模型是受到热力学中的一个分支,它的思想来源是非平衡热力学(Non-equilibrium thermodynamics)。扩散模型的算法理论基础是通过变分推断(Variational Inference)训练参数化的马尔可夫链(Markov Chain),它在许多任务上展现了超过GAN等其它生成模型的效果,例如最近非常火热的OpenAI的DALL-E 2,Stability.ai的Stable Diffusion等。这些效果惊艳的模型扩散模型的理论基础便是我们这里要介绍的提出扩散模型的文章[1]和非常重要的DDPM[2],扩散模型的实现并不复杂,但其背后的数学原理却非常丰富。在这里我会介绍这些重要的数学原理,但省去了这些公式的推导计算,如果你对这些推导感兴趣,可以学习参考文献[4,5,11]的相关内容。我在这里主要以一个相对简单的角度来讲解扩散模型,帮助你快速入门这个非常重要的生成算法。
1. 背景知识: 生成模型

目前生成模型主要有图1所示的四类。其中GAN的原理是通过判别器和生成器的互相博弈来让生成器生成足以以假乱真的图像。VAE的原理是通过一个编码器将输入图像编码成特征向量,它用来学习高斯分布的均值和方差,而解码器则可以将特征向量转化为生成图像,它侧重于学习生成能力。流模型是从一个简单的分布开始,通过一系列可逆的转换函数将分布转化成目标分布。扩散模型先通过正向过程将噪声逐渐加入到数据中,然后通过反向过程预测每一步加入的噪声,通过将噪声去掉的方式逐渐还原得到无噪声的图像,扩散模型本质上是一个马尔可夫架构,只是其中训练过程用到了深度学习的BP,但它更属于数学层面的创新。这也就是为什么很多计算机的同学看扩散模型相关的论文会如此费力。
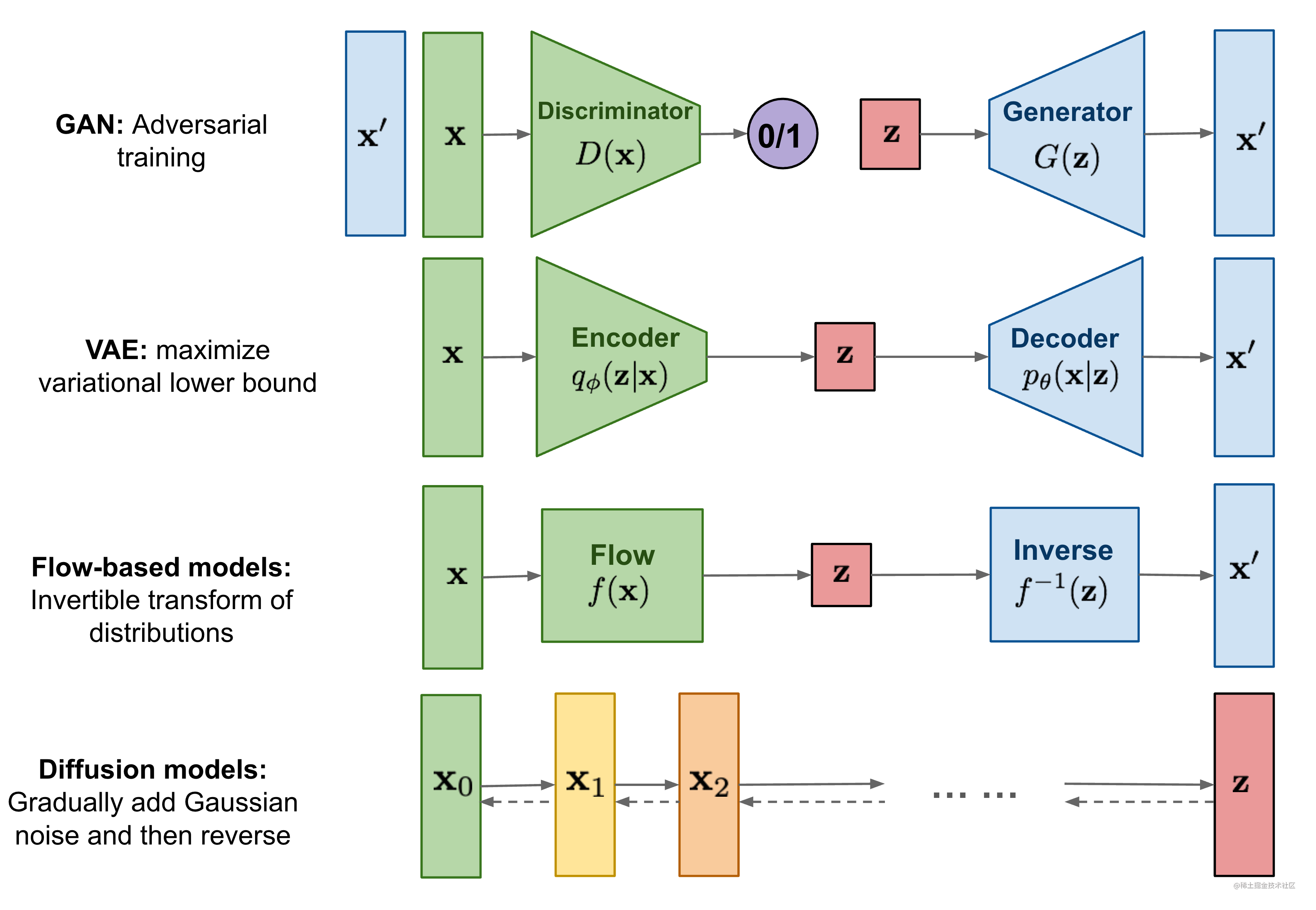
图1:生成模型的四种类型 [4]
扩散模型中最重要的思想根基是马尔可夫链,它的一个关键性质是平稳性。即如果一个概率随时间变化,那么再马尔可夫链的作用下,它会趋向于某种平稳分布,时间越长,分布越平稳。如图2所示,当你向一滴水中滴入一滴颜料时,无论你滴在什么位置,只要时间足够长,最终颜料都会均匀的分布在水溶液中。这也就是扩散模型的前向过程。
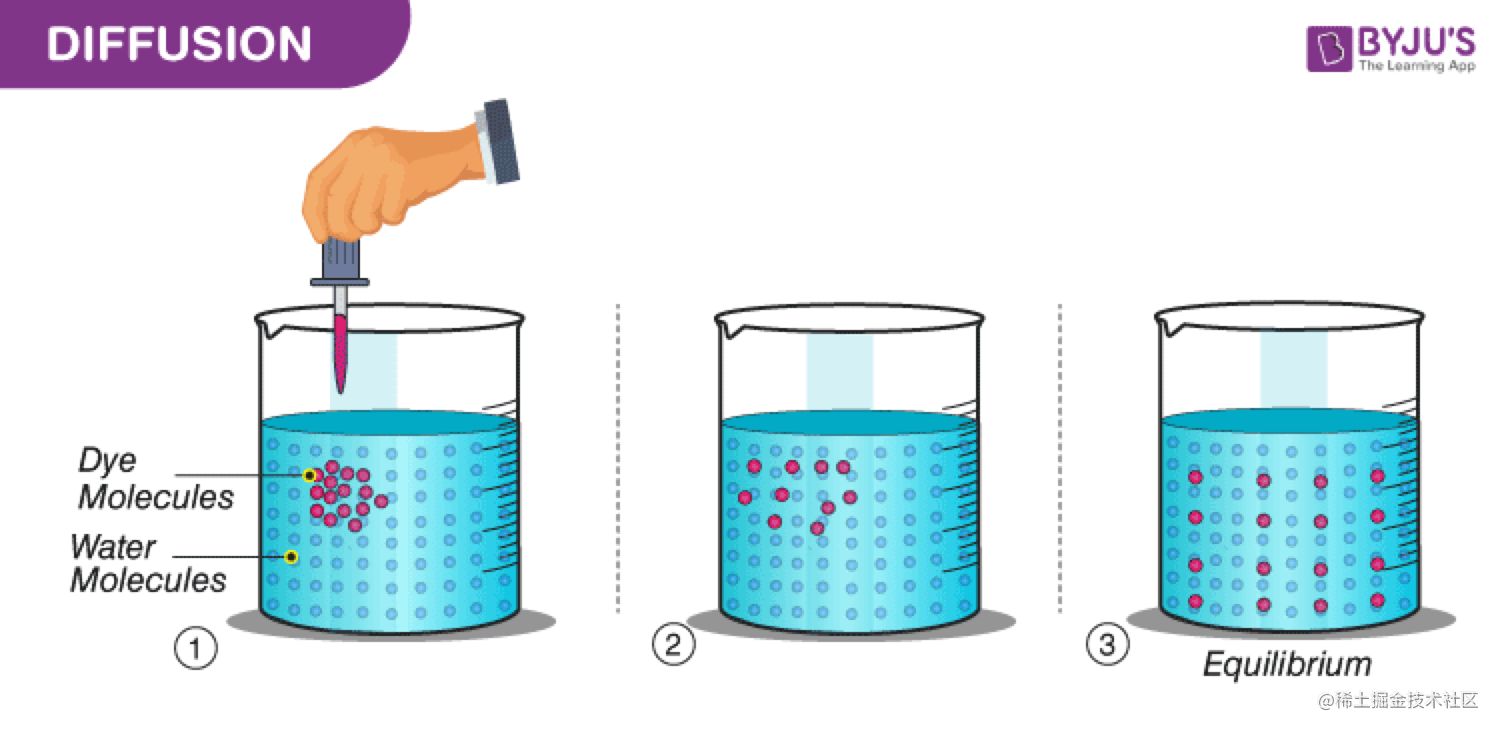
图2:颜料分子在水溶液中的扩散过程
如果我们能够在扩散的过程颜料分子的位置、移动速度、方向等移动属性。那么也可以根据正向过程的保存的移动属性从一杯被溶解了颜料的水中反推颜料的滴入位置。这边是扩散模型的反向过程。记录移动属性的快照便是我们要训练的模型。
2. 扩散模型
在这一部分我们将集中介绍扩散模型的数学原理以及推导的几个重要性质,因为推导过程涉及大量的数学知识但是对理解扩散模型本身思想并无太大帮助,所以这里我会省去推导的过程而直接给出结论。但是我也会给出推导过程的出处,对其中的推导过程比较感兴趣的请自行查看。
2.1 计算原理
扩散模型简单的讲就是通过神经网络学习从纯噪声数据逐渐对数据进行去噪的过程,它包含两个步骤,如图3:

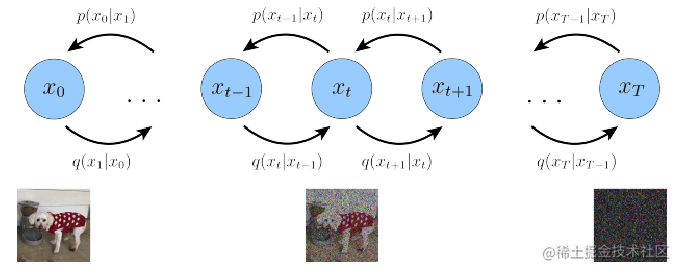
图3:DDPM的前向加噪和后向去噪过程

2.1.1 前向过程


2.1.2 后向过程

2.1.3 目标函数
那么问题来了,我们究竟使用什么样的优化目标才能比较好的预测高斯噪声的分布呢?一个比较复杂的方式是使用变分自编码器的最大化证据下界(Evidence Lower Bound, ELBO)的思想来推导,如式(6),推导详细过程见论文[11]的式(47)到式(58),这里主要用到了贝叶斯定理和琴生不等式。
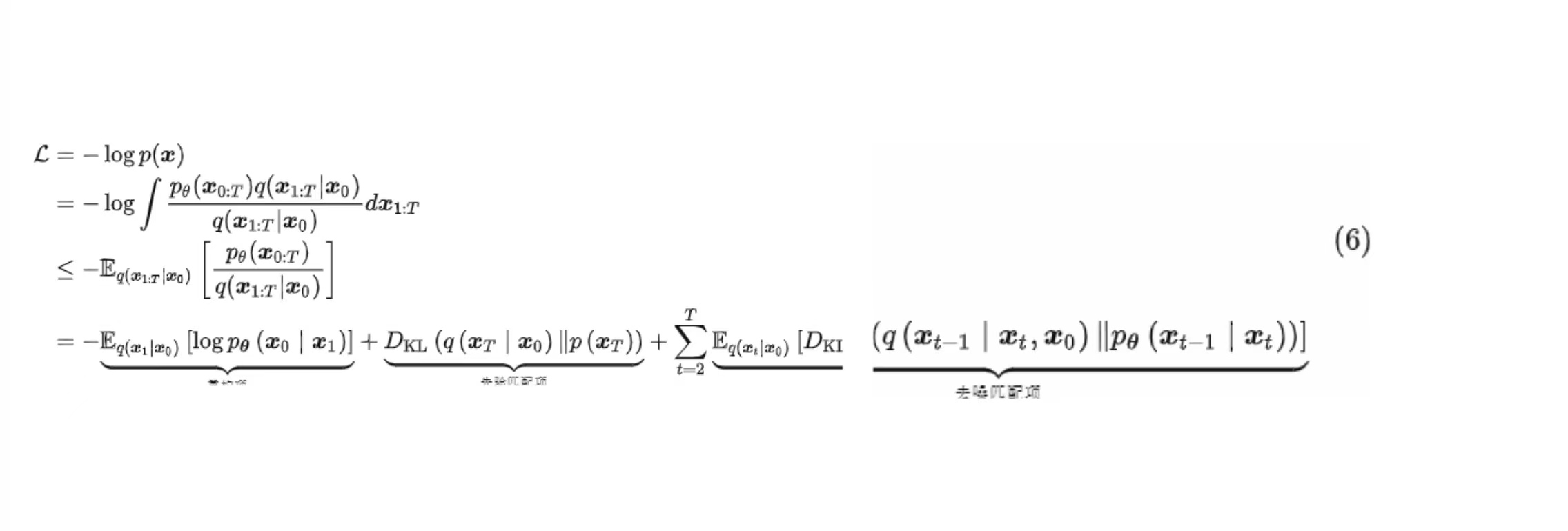
式(6)的推导细节并不重要,我们需要重点关注的是它的最终等式的三个组成部分,下面我们分别介绍它们:

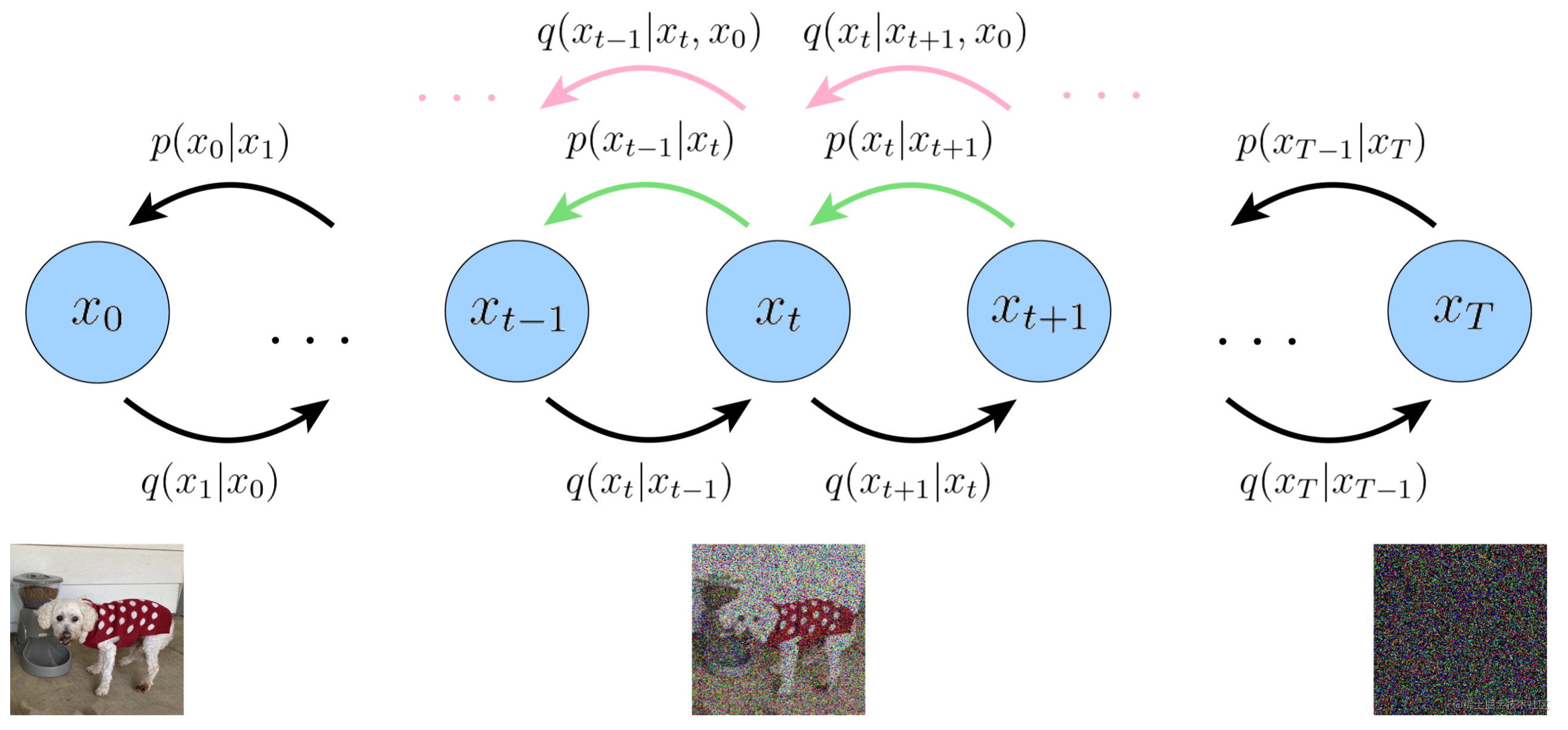
图4:扩散模型的去噪匹配项在每一步都要拟合噪音的真实后验分布和估计分布
真实后验分布可以使用贝叶斯定理进行推导,最终结果如式(8),推导过程见论文[11]的式(71)到式(84)。
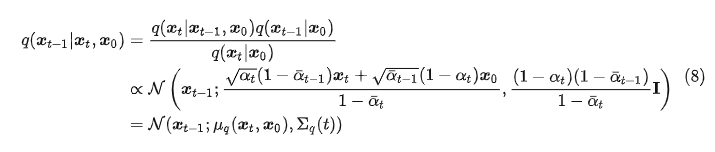

pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σq(t))




2.1.4 模型训练

虽然上面我们介绍了很多内容,并给出了大量公式,但得益于推导出的几个重要性质,扩散模型的训练并不复杂,它的训练伪代码见算法1。

2.1.5 样本生成


2.2 算法实现
2.2.1模型结构
DDPM在预测施加的噪声时,它的输入是施加噪声之后的图像,预测内容是和输入图像相同尺寸的噪声,所以它可以看做一个Img2Img的任务。DDPM选择了U-Net[9]作为噪声预测的模型结构。U-Net是一个U形的网络结构,它由编码器,解码器以及编码器和解码器之间的跨层连接(残差连接)组成。其中编码器将图像降采样成一个特征,解码器将这个特征上采样为目标噪声,跨层连接用于拼接编码器和解码器之间的特征。

图5:U-Net的网络结构
下面我们介绍DDPM的模型结构的重要组件。首先在U-Net的卷积部分,DDPM使用了宽残差网络(Wide Residual Network,WRN)[12]作为核心结构,WRN是一个比标准残差网络层数更少,但是通道数更多的网络结构。也有作者复现发现ConvNeXT作为基础结构会取得非常显著的效果提升[13,14]。这里我们可以根据训练资源灵活的调整卷积结构以及具体的层数等超参。因为我们在扩散过程的整个流程中都共享同一套参数,为了区分不同的时间片,作者借鉴了Transformer [15]的位置编码的思想,采用了正弦位置嵌入对时间 t t t进行了编码,这使得模型在预测噪声时知道它预测的是批次中分别是哪个时间片添加的噪声。在卷积层之间,DDPM添加了一个注意力层。这里我们可以使用Transformer中提出的自注意力机制或是多头自注意力机制。[13]则提出了一个线性注意力机制的模块,它的特点是消耗的时间以及占用的内存和序列长度是线性相关的,对比传统注意力机制的平方相关要高效很多。在进行归一化时,DDPM选择了组归一化(Group Normalization,GN)[16]。最后,对于U-Net中的降采样和上采样操作,DDPM分别选择了步长为2的卷积以及反卷积。
确定了这些组件,我们便可以搭建用于DDPM的U-Net的模型了。从第2.1节的介绍我们知道,模型的输入为形状为(batch_size, num_channels, height, width)的噪声图像和形状为(batch_size,1)的噪声水平,返回的是形状为(batch_size, num_channels, height, width)的预测噪声,我们搭建的用于噪声预测的模型结构如下:
- 首先在噪声图像x0上应用卷积层,并为噪声水平 t t t计算时间嵌入;
- 接下来是降采样阶段。采用的模型结构依次是两个卷积(WRNS或是ConvNeXT)+GN+Attention+降采样层;
- 在网络的最中间,依次是卷积层+Attention+卷积层;
- 接下来是上采样阶段。它首先会使用Short-cut拼接来自降采样中同样尺寸的卷积,再之后是两个卷积+GN+Attention+上采样层。
- 最后是使用WRNS或是ConvNeXT作为输出层的卷积。
U-Net类的forword函数如下面代码片段所示,完整的实现代码参照[3]。
def forward(self, x, time): x = self.init_conv(x) t = self.time_mlp(time) if exists(self.time_mlp) else None h = [] # downsample for block1, block2, attn, downsample in self.downs: x = block1(x, t) x = block2(x, t) x = attn(x) h.append(x) x = downsample(x) # bottleneck x = self.mid_block1(x, t) x = self.mid_attn(x) x = self.mid_block2(x, t) # upsample for block1, block2, attn, upsample in self.ups: x = torch.cat((x, h.pop()), dim=1) x = block1(x, t) x = block2(x, t) x = attn(x) x = upsample(x) return self.final_conv(x)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
2.2.2 前向加噪


图6:一张图依次经过0次,50次,100次,150次以及199次加噪后的效果图
根据式(14)我们知道,扩散模型的损失函数计算的是两张图像的相似性,因此我们可以选择使用回归算法的所有损失函数,以MSE为例,前向过程的核心代码如下面代码片段。
def p_losses(denoise_model, x_start, t, noise=None, loss_type="l1"):
# 1. 根据时刻t计算随机噪声分布,并对图像x_start进行加噪
x_noisy = q_sample(x_start=x_start, t=t, noise=noise)
# 2. 根据噪声图像以及时刻t,预测添加的噪声
predicted_noise = denoise_model(x_noisy, t)
# 3. 对比添加的噪声和预测的噪声的相似性
loss = F.mse_loss(noise, predicted_noise)
return loss
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2.2.3 样本生成
根据2.1.5节介绍的样本生成流程,它的核心代码片段所示,关于这段代码的讲解我通过注释添加到了代码片段中。
@torch.no_grad() def p_sample(model, x, t, t_index): betas_t = extract(betas, t, x.shape) sqrt_one_minus_alphas_cumprod_t = extract(sqrt_one_minus_alphas_cumprod, t, x.shape) sqrt_recip_alphas_t = extract(sqrt_recip_alphas, t, x.shape) # 使用式(13)计算模型的均值 model_mean = sqrt_recip_alphas_t * (x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t) if t_index == 0: return model_mean else: # 获取保存的方差 posterior_variance_t = extract(posterior_variance, t, x.shape) noise = torch.randn_like(x) # 算法2的第4行 return model_mean + torch.sqrt(posterior_variance_t) * noise # 算法2的流程,但是我们保存了所有中间样本 @torch.no_grad() def p_sample_loop(model, shape): device = next(model.parameters()).device b = shape[0] # start from pure noise (for each example in the batch) img = torch.randn(shape, device=device) imgs = [] for i in tqdm(reversed(range(0, timesteps)), desc='sampling loop time step', total=timesteps): img = p_sample(model, img, torch.full((b,), i, device=device, dtype=torch.long), i) imgs.append(img.cpu().numpy()) return imgs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
最后我们看下在人脸图像数据集下训练的模型,一批随机噪声经过逐渐去噪变成人脸图像的示例。
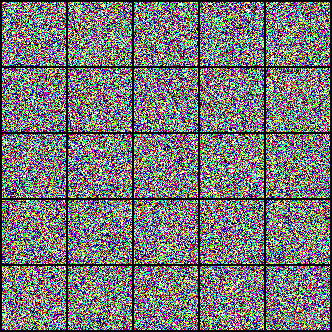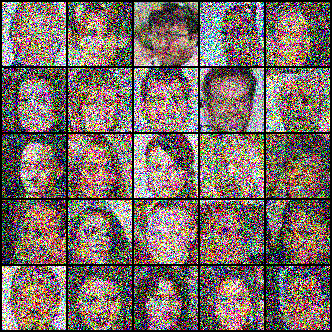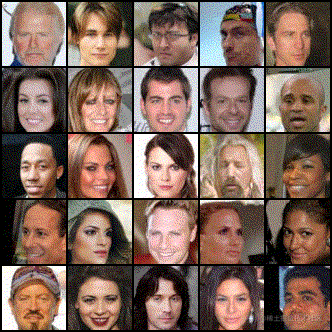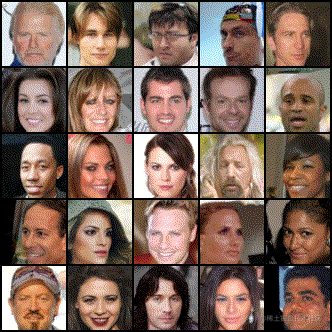
图7:扩散模型由随机噪声通过去噪逐渐生成人脸图像
3. 总结
这里我们以DDPM为例介绍了另一个派系的生成算法:扩散模型。扩散模型是一个基于马尔可夫链的数学模型,它通过预测每个时间片添加的噪声来进行模型的训练。作为近日来引发热烈讨论的ControlNet, Stable Diffusion等模型的底层算法,我们十分有必要对其有所了解。DDPM的实现并不复杂,这得益于大量数学界大佬通过大量的数学推导将整个扩散过程和反向去噪过程进行了精彩的化简,这才有了DDPM的大道至简的实现。DDPM作为一个扩散模型的基石算法,它有着很多早期算法的共同问题:
- 采样速度慢:DDPM的去噪是从时刻 T T T到时刻 1 1 1的一个完整的马尔可夫链的计算,尤其是DDPM还需要一个比较大的 T T T才能保证比较好的效果,这就导致了DDPM的采样过程注定是非常慢的;
- 生成效果差:DDPM的效果并不能说是非常好,尤其是对于高分辨率图像的生成。这一方面是因为它的计算速度限制了它扩展到更大的模型;另一方面它的设计还有一些问题,例如逐像素的计算损失并使用相同权值而忽略图像中的主体并不是非常好的策略。
- 内容不可控:我们可以看出,DDPM生成的内容完全还是取决于它的训练集。它并没有引入一些先验条件,因此并不能通过控制图像中的细节来生成我们制定的内容。
我们现在已经知道,DDPM的这些问题已大幅得到改善,现在基于扩散模型生成的图像已经达到甚至超过人类多数的画师的效果,我也会在之后逐渐给出这些优化方案的讲解。
Reference
[1] Sohl-Dickstein, Jascha, et al. “Deep unsupervised learning using nonequilibrium thermodynamics.” International Conference on Machine Learning. PMLR, 2015.
[2] Ho, Jonathan, Ajay Jain, and Pieter Abbeel. “Denoising diffusion probabilistic models.” Advances in Neural Information Processing Systems 33 (2020): 6840-6851.
[3] https://huggingface.co/blog/annotated-diffusion
[4] https://lilianweng.github.io/posts/2021-07-11-diffusion-models/#simplification
[5] https://openai.com/blog/generative-models/
[6] Nichol, Alexander Quinn, and Prafulla Dhariwal. “Improved denoising diffusion probabilistic models.” International Conference on Machine Learning. PMLR, 2021.
[7] Kingma, Diederik P., and Max Welling. “Auto-encoding variational bayes.” arXiv preprint arXiv:1312.6114 (2013).
[8] Hinton, Geoffrey E., and Ruslan R. Salakhutdinov. “Reducing the dimensionality of data with neural networks.” science 313.5786 (2006): 504-507.
[9] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]//International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015: 234-241.
[10] Long, Jonathan, Evan Shelhamer, and Trevor Darrell. “Fully convolutional networks for semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[11] Luo, Calvin. “Understanding diffusion models: A unified perspective.” arXiv preprint arXiv:2208.11970 (2022).
[12] Zagoruyko, Sergey, and Nikos Komodakis. “Wide residual networks.” arXiv preprint arXiv:1605.07146 (2016).
[13] https://github.com/lucidrains/denoising-diffusion-pytorch
[14] Liu, Zhuang, et al. “A convnet for the 2020s.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[15] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
[16] Wu, Yuxin, and Kaiming He. “Group normalization.” Proceedings of the European conference on computer vision (ECCV). 2018.

