
- 1面向专业人士的中文法律文书生成系统-大模型应用开发博客_中文法律模型
- 2headscale的部署方法和使用教程
- 3CSS初入门:过渡-Transitions_css transition
- 45.3.1 配置交换机 SSH 管理和端口安全
- 5测试常见面试题,如何有效的做自我介绍
- 6springSecurity自定义认证逻辑,重写登陆,token过滤,退出_spring security 根据用户信息 清除token
- 7clip_as_service学习过程(一)——安装客户端与服务端_clip-as-service
- 8ArraylndexOutBoundsExcepfion 异常
- 9论文阅读_AI生成检测_Ghostbuster
- 10U盘安装Win11+Ubuntu20.04双系统安装踩坑历程(双系统)_windows11 u盘安装ubuntu
opencv小程序:全景拼接_opencv vr全景拼接2:1
赞
踩
SIFT 特征检测
Scale-invariant feature transform 是以一种检测局部特征的算法,该算法通过求一幅图中的特征点(interest points,or corner points)及其有关scale 和 orientation 的描述子得到特征并进行图像特征点匹配,获得了良好效果
SIFT特征不只具有尺度不变性,即使改变旋转角度,图像亮度或拍摄视角,仍然能够得到好的检测效果。整个算法分为以下几个部分:

尺度就是高斯模糊的程度,下一层就是降采样获得下一个八度(octave)。具体建几个塔有图片大小决定(cv库决定)。。
然后跟拉普拉斯金字塔差不多吧,,就是通过高斯差分(就是不同尺度的高斯处理的图相减)获得DOG尺度空间。在这个空间内来获得尺度不变性。。拉普拉斯金字塔差(LOG)也可以找到特征的但是计算量大,就用 DOG 的最大最小值来近似等于。
- LoG近似DoG找到关键点<检测DOG尺度空间极值点>
就是在这三层上下26个点比较,如果中间那个 叉是26个邻域内的最大值或最小值就认为这个点是图像在该尺度下的一个特征点

在同一层中的相邻尺度(上下层)之间寻找,每一层的首末两个是无法比较的。为了满足尺度变化的连续性(下面有详解),我们在每一组图像的顶层继续用高斯模糊生成了 3 幅图像,高斯金字塔有每组S+3层图像。DOG金字塔每组有S+2层图像.

3. 除去不好的特征点
通过拟合三维二次函数以精确确定关键点的位置和尺度,同时去除低对比度的关键点和不稳定的边缘响应点(因为DoG算子会产生较强的边缘响应),以增强匹配稳定性、提高抗噪声能力,在这里使用近似Harris Corner检测器。
- 给特征点赋值一个128维方向参数
利用关键点邻域像素的梯度方向分布特性为每个关键点指定方向参数,使算子具备旋转不变性。至此,图像的关键点已经检测完毕,每个关键点有三个信息:位置,所处尺度、方向,由此可以确定一个SIFT特征区域。
- 关键点描述子的生成
每个块的梯度方向,梯度模值,然后用高斯窗口进行加权运算,靠近中间的关键权重就越大。最后形成一个种子点,右图 一个关键点由16个种子的组成,每个种子的有 8 个方向的信息,这种邻域方向性信息联合可以增强算法抗噪能力,同时对于含有定位误差的特征匹配也提供了较好的容错性。

对每个feature形成一个448=128维的描述子,每一维都可以表示4*4个格子中一个的scale/orientation. 将这个向量归一化之后,就进一步去除了光照的影响。
这时的SIFT 特征向量就去出了尺度变化,旋转等几何变换因素的影响
- 根据SIFT进行Match
生成了A、B两幅图的描述子,(分别是k1*128维和k2*128维),就将两图中各个scale(所有scale)的描述子进行匹配,匹配上128维即可表示两个特征点match上了。
取图像1中的某个关键点,并找出其与图像2中欧式距离最近的前两个关键点,在这两个关键点中,如果最近的距离除以次近的距离少于某个比例阈值,则接受这一对匹配点。降低这个比例阈值,SIFT匹配点数目会减少,但更加稳定。
为了排除因为图像遮挡和背景混乱而产生的无匹配关系的关键点,Lowe提出了比较最近邻距离与次近邻距离的方法,距离比率ratio小于某个阈值的认为是正确匹配。因为对于错误匹配,由于特征空间的高维性,相似的距离可能有大量其他的错误匹配,从而它的ratio值比较高。
RANSAC 算法
随机抽样一致,从一组包含“局外点”的观测数据集中,通过迭代方式估计数学模型的参数,它是一种不确定的算法——它有一定的概率得出一个合理的结果;为了提高概率必须提高迭代次数。
基本假设:
- 数据由局内点组成(可以用一些模型解释)
- 局外点不能适应模型
- 除此之外的数据属于噪声。

RANSAC并不能保证结果一定正确,为了保证算法有足够高的合理概率,我们必须小心的选择算法的参数。
iterations = 0 best_model = null best_consensus_set = null best_error = 无穷大 while ( iterations < k ) maybe_inliers = 从数据集中随机选择n个点最为局内点 maybe_model = 适合于maybe_inliers的模型参数 consensus_set = maybe_inliers for ( 每个数据集中不属于maybe_inliers的点 ) # t 是否适用于模型的阈值 if ( 如果点适合于maybe_model,且错误小于t ) 将点添加到consensus_set if ( consensus_set中的元素数目大于d ) # 判定模型是否适用于数据集的数据数目 已经找到了好的模型,现在测试该模型到底有多好 better_model = 适合于consensus_set中所有点的模型参数 this_error = better_model究竟如何适合这些点的度量 if ( this_error < best_error ) 我们发现了比以前好的模型,保存该模型直到更好的模型出现 best_model = better_model best_consensus_set = consensus_set best_error = this_error 增加迭代次数 返回 best_model, best_consensus_set, best_error

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
核心就是随机性(循环次数就是利用正确数据出现的概率)和假设性(假设随机抽取的数据就是局内点然后去计算其他点利用投票机制选出票数最多的变换)。
RANSAC 优点就是可以从包含大量局外点的数据集中估计出高精度的参数。驱动就是计算的迭代次数没有上限(就是得到的结果不一定就是最优的,正确的概率与迭代次数正比),另一个缺点就是 t,d 的设置要根据实际。并且只能估计出一个模型,两个或多个模型就不能找到其他的了。
应用于计算机视觉,例如同时求解相关问题与估计立体摄像机的基础矩阵,在图像拼接时求变换矩阵的时候(目标)。
单应性矩阵
利用两个图像中至少四个特征点能够求解一个单应性矩阵(homography matrix),然后用这个单应性矩阵能够将图像1中的某个坐标变换到图像2中对应的位置。使用opencv计算单应性矩阵的时候前提是两个图像对应区域必须是同一平面。
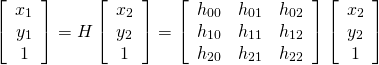
Homography 就是将一张图像上的点映射到另一张图像上对应点的3x3变换矩阵.
全景拼接小程序
kps ,得到关键点的属性
- pt 关键点的坐标,使用这个来映射
- size 关键点邻域的直径
- angle 关键点的方向,对于图像坐标系(y向下,顺时针)
- response
- octave 图像金字塔的层数
- class_id
import cv2,time # opencv 3.4.16 python 3.6 import numpy as np def get_kps_feature(image): descriptor = cv2.xfeatures2d.SIFT_create() kps,feature = descriptor.detectAndCompute(image,None) # 得到关键点和描述符 return np.float32([kp.pt for kp in kps]),feature # 特征匹配 # 两个图像有大量特征点,比较两组特征并显示相似性的特征点对,需要matcher 对象 # 有两种方式,BruteForce and KNN 暴力匹配器和K最近邻 # 暴力匹配器就是逐个比较,返回最近欧氏距离的特征(SIFT SURF 使用欧式,ORB BRISK 等用汉明距离) # 暴力匹配需要两个参数,一个距离度量,一个是否进行交叉检测的布尔值(是否要相互匹配) # KNN 就会考虑多个候选匹配的情况,返回k 个最佳匹配。 def get_H_matches_status(kpsA,kpsB,featuresA,featuresB,ratio,reprojThresh,showMatches=False): matcher = cv2.DescriptorMatcher_create('BruteForce') rawMatches = matcher.knnMatch(featuresA, featuresB, 2) # 查询描述符,训练描述符 matches = [] for m in rawMatches: # 得到的是DMatch 对象 # 两个图像描述符的索引和图像的索引,还有距离 int queryIdx;int trainIdx; int imgIdx; loat distance; if len(m) == 2 and m[0].distance < m[1].distance * ratio: # 最近和次进距离 matches.append((m[0].queryIdx, m[0].trainIdx)) # A , B 图中对应的索引 if len(matches) > 4: ptsA = np.float32([kpsA[i] for (i, _) in matches]) ptsB = np.float32([kpsB[i] for (_, i) in matches]) H, status = cv2.findHomography(ptsA, ptsB, cv2.RANSAC,reprojThresh) if showMatches: vis = drawMatches(imageB, imageA, kpsB, kpsA, matches, status) cv2.imshow('vis',vis) return matches, H, status def drawMatches(imageA, imageB, kpsA, kpsB, matches, status): (hA, wA) = imageA.shape[:2] (hB, wB) = imageB.shape[:2] vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8") vis[0:hA, 0:wA] = imageA vis[0:hB, wA:] = imageB for ((trainIdx, queryIdx), s) in zip(matches, status): if s == 1: ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1])) ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1])) cv2.line(vis, ptA, ptB, (0, 255, 0), 1) return vis if __name__ == '__main__': ratio = 0.75 # 一个是特征点匹配时的阈值,一个RANSAC 局内点的阈值 reprojThresh = 4.0 imageA = cv2.imread(r'D:\pycham\opencv3\a.jpg') # 左边的图 imageB = cv2.imread(r'D:\pycham\opencv3\b.jpg') # 要放到右边的图 kpsA, featuresA = get_kps_feature(imageA) kpsB, featuresB = get_kps_feature(imageB) matches, H,status = get_H_matches_status(kpsB,kpsA,featuresB,featuresA, ratio,reprojThresh) # 图B 拉伸 图A 贴上去,H 是图B 的点映射到 A 中的变化矩阵 result = cv2.warpPerspective(imageB, H, (imageA.shape[1] + imageB.shape[1], imageB.shape[0])) result[0:imageA.shape[0], 0:imageA.shape[1]] = imageA cv2.imshow('result',result) cv2.imshow('imageA', imageA) cv2.imshow('imageB', imageB) if cv2.waitKey(0) == 27: cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68

虽然效果一般,但还是拼上去不是。。。。。毕竟单应性矩阵只能处理一个平面,对于立体的效果就不好,就像我笔记本上映射的就没问题。。。。
问题就是中间那条线没处理掉,对于大图片就很耗时(缩小一下速度还是非常快的),然后就是改进的SURF 算法
boxfilter 盒式滤波器
与积分图类似,降低复杂度,缺点是不支持多尺度。

整个过程就是:
- 对M N 的图像求矩形模板 m,n ,如紫色矩形,从0,0 开始包住一片区域,计算矩形内像素的和,然后右移一像素。
- 右移后,与之前那个矩形相比就是少了一列,然后多了一列新的,所以计算就是一加一减。
- 到右边了,就移动到下一行开头,这一整行与第一行相比就是少了一行,多了一行新的,也是一加一减。
- 每个矩形基本只需要一加一减两次运算,所以计算更快,虽然较积分图优化很小,但也优化了不是,,
SURF 算法
sift 优点是特征稳定,对旋转,尺度变化,亮度保持不变性,对视角变化,噪声有稳定性,但是实时性不高,对边缘光滑的目标的特征提取能力弱。SURF 改进特征的提取和描述方式,用更高效的方式完成。
-
构建 Hessian 矩阵,生成兴趣点,用于特征提取。是一个多元函数的二阶偏导数构成的方阵,描述了函数的局部曲率。sift采用DOG 图像,SURF 采用黑塞矩阵行列式近似值图像。生成图像稳定的边缘点(突变点)。每一个像素点都可以生成一个 hessian 矩阵
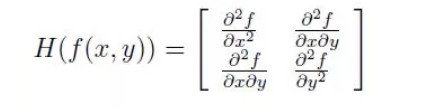
Hessian矩阵的判别式
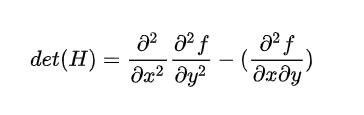
-
判别式取得局部最大值,就判断点是比周围领域其他点更亮或更暗的点,来定位关键点位置。
-
由于我们的特征的需要尺度无关系,进行Hessian 矩阵构造前需要进行高斯滤波。选用二阶标准高斯函数作为滤波器。
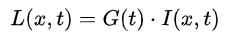
并计算得H矩阵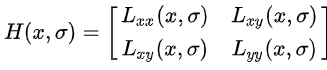
为了提高计算速度,以上的高斯滤波器使用盒式滤波器近似代替。就可以得到每个像素的判别式。其中0.9的权重是为了平衡使用盒式滤波器的误差。
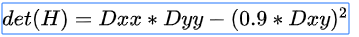
-
与sift 一样也需要构建尺度空间。但surf 不同组的图像尺寸一致,但是不同组滤波器模板尺寸加大,同一组模板尺寸一样但是模糊系数加大。
-
特征点的定位与sift 一样,也是每个像素点与三层邻域的26 个点比较,初步定位关键点,在经过一次过滤筛选出最后的特征点。
-
sift 特征点的方向采用邻域的梯度直方图,surf 中采用统计特征的的圆形邻域内的harr小波特征。以60度扇形所有点的 x,y harr小波特征总和,最后将值最大的作为特征点的主方向。

-
sift 中使用44个区域块,统计每小块内8个梯度方向共128维向量作为描述子,surf 中,在主方向上取44 的矩形区域块,每个区域统计25 个像素的水平,垂直方向的harr小波特征(方向相对于主方向来说的),这个小波特征是水平方向值之和、垂直方向值之和、水平方向绝对值之和以及垂直方向绝对值之和四个特征。所以一共有64 维向量作为描述子,这减少一半。
-
特征点匹配,与sift 一样采用两个描述子间的欧氏距离。不同的是Surf还加入了Hessian矩阵迹的判断,如果两个特征点的矩阵迹正负号相同,代表这两个特征具有相同方向上的对比度变化,如果不同,说明这两个特征点的对比度变化方向是相反的,即使欧氏距离为0,也直接予以排除。
import cv2,time import numpy as np def get_kps_feature(image,hessionThreshold): # 阈值越大,获得的关键点就越少,具体干嘛的。。 surf = cv2.xfeatures2d.SURF_create(hessionThreshold, nOctaves=4, extended=False, upright=True) # 4层金字塔,extended是否扩展描述符(false就是64维),是否要检测关键点的方向,nOctaveLayers每个层几个图片。 kps,feature = surf.detectAndCompute(image,None) return np.float32([kp.pt for kp in kps]),feature def get_H_matches_status(kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh): indexParams = dict(algorithm=0, trees=5) searchParams = dict(checks=50) flann = cv2.FlannBasedMatcher(indexParams, searchParams) rawMatches = flann.knnMatch(featuresA, featuresB, k=2) # matcher = cv2.DescriptorMatcher_create("BruteForce") # 创建一个描述符匹配器 # rawMatches = matcher.knnMatch(featuresA, featuresB, 2) matches = [] for m in rawMatches: if len(m) == 2 and m[0].distance < m[1].distance * ratio: matches.append((m[0].queryIdx, m[0].trainIdx)) if len(matches) > 4: ptsA = np.float32([kpsA[i] for (i, _) in matches]) ptsB = np.float32([kpsB[i] for (_, i) in matches]) H, status = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh) return matches, H, status else: print('匹配点不够') if __name__ == '__main__': ratio = 0.75 reprojThresh = 5.0 hessionThreshold = 500 # 这个阈值没太搞懂 imageA = cv2.imread(r'D:\pycham\opencv3\zuo.jpg') imageB = cv2.imread(r'D:\pycham\opencv3\you.jpg') kpsA, featuresA = get_kps_feature(imageA,hessionThreshold) # 查询 kpsB, featuresB = get_kps_feature(imageB,hessionThreshold) # 训练 print(kpsB.shape) matches,H,status = get_H_matches_status(kpsB,kpsA,featuresB,featuresA, ratio,reprojThresh) result = cv2.warpPerspective(imageB, H, (imageA.shape[1] + imageB.shape[1], imageB.shape[0])) direct = result.copy() direct[0:imageA.shape[0], 0:imageA.shape[1]] = imageA rows,cols = imageA.shape[:2] print(rows,cols) for col in range(0,cols): # 应该就是找左图的左右边界 if imageA[:,col].any() and result[:,col].any(): print(col) left = col break for col in range(cols - 1, 0, -1): if imageA[:, col].any() and result[:, col].any(): right = col print(col) break res = np.zeros([rows, cols, 3], np.uint8) for row in range(0, rows): for col in range(0, cols): if not imageA[row, col].any(): # 逐像素填充,,时间都花在这了。。 res[row, col] = result[row, col] # 就是把分别没有的区域用另一个填充了 elif not result[row, col].any(): res[row, col] = imageA[row, col] else: srcImgLen = float(abs(col - left)) # 分个权重实现过度 testImgLen = float(abs(col - right)) alpha = srcImgLen / (srcImgLen + testImgLen) res[row, col] = np.clip(imageA[row, col] * (1 - alpha) + result[row, col] * alpha, 0, 255) result[0:imageA.shape[0], 0:imageA.shape[1]] = res cv2.imshow('result', result) if cv2.waitKey(0) == 27: cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85

这个效果就好多了 。。。

