
第二篇 基于自然语言处理的漏洞检测方法综述_基于nlp的智能合约漏洞检测
赞
踩
杨伊等 来源:计算机研究与发展
目录
据2021年CVE漏洞趋势安全报告,当前漏洞类型占比最大的5类漏洞分别是代码执行、拒绝服务、溢出、跨站脚本以及信息获取。基于自然语言处理技术实现漏洞检测的研究工作按照数据类型的不同进行分类,可分为官方文档、代码、代码注释以及漏洞相关信息。
注: 四大信息安全高水平会议:USENIX Security,IEEE S&P, ACM CCS,NDSS。
1 相关技术
1.1 自然语言处理
在利用自然语言处理技术辅助漏洞检测研究的时候,通常是NLP解析器使用标准NLP技术对预处理文本中的每一条语句进行分解,依次利用依存语法解析、词嵌入、命名实体识别、词性标注、语义消歧等操作对语句进行处理。
- 依存语法解析(dependency parser):主要是通过分析单词等语言单位之间的词法关系来揭示句子的句法结构,包括主谓关系、动宾关系等。依存句法解析的结果通常表示为有根解析树。
- 词嵌入(word embedding):将文本(单词或短语)从词汇表映射到实数的高维向量,把一个维数为所有词的数量的高维空间映射到一个低维度连续向量空间中,从而消除维数灾难的问题,每个单词或词组被映射为实数域上的向量。
- 命名实体识别(named entity recognition):识别文本中具有特定意义的实体以及可以用名称标识的事物,主要包括人名、地名、机构名以及专有名词等。
- 词性标注(part-speech tagging,POS):基于上下文将文本中的单词标记为对应于特定词性(名词、动词、形容词等)的过程。
- 词义消歧(word sence disambiguation,WSD):根据上下文确定对象语义的过程。
以上各步骤构成了自然语言处理的预训练内容。当前预训练语言模型被划分为词嵌入模型(Word3Vec,GloVe,ElMo)和多用途的NLP模型(Transformer和BERT)。
词嵌入模型:通过随机值初始化词表示,并通过应用连续词袋或跳过词将词上下文的联合概率分布用作其输入模型,然后在神经网络的训练过程中利用这种分布,其中单词向量会不断更新以使联合概率最大化。训练的结果确保相关词被赋予其相似上下文的近似向量,而不相关的词被映射到不同的向量中,而词与词之间的语义差异通常通过向量之间的余弦距离进行测量。ElMo模型能够根据上下文推断每个词对应的词向量,解决多义词问题。
预训练模型Transformer的核心就是注意力机制,该模型完全依靠注意力机制绘制输入和输出之间的全局依赖关系,其本质上是一种 Encoder-Decoder 的结构,以 3 种不 同 的 方 式 使 用 多 头 注 意 力 机 制。
基于transfomer模型Encoder结构的模型BERT,预训练部分与Word2Vec和ELMo相似。BERT预训练模型可以使一个词在不同的语境下生成不同的词向量。
1.2 漏洞检测与分析
漏洞:网络和安全的根源,是信息系统的硬件、软件、操作系统、网络协议、数据库等在设计上、实现上出现的可以被攻击者利用的错误、缺陷和疏漏。
漏洞攻击:
漏洞检测:对信息系统所用软硬件进行研究,找出存在的可能威胁信息系统安全的薄弱环节。
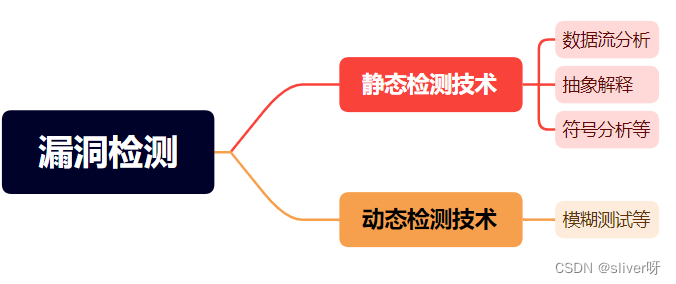
静态检测技术:在不执行应用程序源代码的情况下,从语法和语义上理解程序的行为,直接分析被检测程序的特征,寻找可能导致错误的异常,包括潜在的安全违规、运行时错误以及逻辑不一致等情况。基于源代码的静态检测技术主要有数据流分析、抽象解释和符号分析。
- 数据流分析:目的是分析变量沿着程序执行路径的流动过程,即获取相关程序运行时行为的信息的过程,不会使用语义运算符。在基于数据流的源代码漏洞分析中,通常包含代码建模、程序代码模型、根据规则进行漏洞分析以及检测结果的分析。在数据流分析时,根据程序路径的分析精度分为流不敏感分析、流敏感分析和路径敏感分析。它们的主要区别在于当根据程序路径的深度进行分类时,分为过程内分析(只考虑函数内的代码)和过程间分析(考虑函数之间的数据流)。
- 抽象解释:对计算机程序的部分进行执行,然后获取有关它的语义信息,目的是找出程序在运行时的语义错误,比如除零或者变量溢出。
- 符号分析:指的是使用符号值而不是实际数据作为输入,将实际变量的值表示为符号表达式,得到每个路径抽象的输出结果。
模糊测试:本质是向程序中插入异常的、随机的输入来触发程序中不可预见的代码执行路径或漏洞。分为基于路径覆盖率的模糊测试方法和导向型模糊测试方法。
- 基于覆盖率的模糊测试方法:目的在于生成输入以及遍历应用程序的不同路径,从而在一些路径上触发错误,即最大化覆盖路径从而触发可能包含错误的路径。当前主流的基于路径覆盖率的漏洞检测工具包括AFL、libFuzzer、AFLFast、VUzzer等。
- 导向型模糊测试方法:在潜在漏洞位置已知的情况下,寻找可以触发漏洞的POC,即有针对性地生成一组输入。当前常见地导向型模糊测试方法包括AFLGo、SemFuzz、Hawkeye等。

