
- 1jetson nano(B01)配置pytorch和torchvision环境+tensorrtx模型转换+Deepstream部署yolov5(亲测可用)_nvdsinfer_custom_impl_yolo
- 2论文阅读《Learning to Compare: Relation Network for Few-Shot Learning》
- 3HarmonyOS开发工具安装
- 4微信小程序使用小程序客服消息云函数自动回复_微信云函数 回复客服信息不及时
- 5对标开源3D建模软件blender,基于web提供元宇宙3D建模能力的dtns.network德塔世界是否更胜一筹?
- 6OpenCV-Python系列·第二十一集:检测&跟踪人眼_python opencv 深度学习眼睛定位
- 7在Mac OS系统下安装Java_jdk17mac os运行
- 8python jieba分词_从零开始学自然语言处理(八)—— jieba 黑科技
- 9电脑如何查看是否支持虚拟化及如何开启虚拟化_如何查看物理机是否支持虚拟化
- 10〖大前端 - 基础入门三大核心之 html 篇⑧〗- 无序列表_html中无序列表标签
BERTopic
赞
踩
论文标题:
BERTopic: Neural topic modeling with a class-based TF-IDF procedure论文作者:
Maarten Grootendorst论文链接:
https://arxiv.org/pdf/2203.05794.pdfgithub:
https://github.com/MaartenGr/BERTopic
1. 原理
BERTopic 方法的步骤如下:
-
首先使用预训练模型计算 document embeddings (比如常用的 Sentence-BERT 等)
-
因为 document embeddings 维度很高,在嵌入空间中就非常稀疏,不容易进行聚类,所以需要先进行降维,比如 PCA 或者 t-SNE 等方法,这里用的是 UMAP[1]
-
基于层次和密度进行聚类,这里用的是典型的 HDBSCAN[2] 算法
-
使用 class-based TF-IDF 变体提取每个簇的主题词
静态主题建模
静态主题建模假定时间是静止的当下,不考虑文档主题分布随着时间的变化。
回顾一下 TF-IDF 算法 :
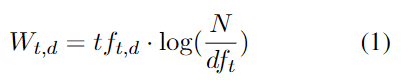
式子中,t 代表单词(term), d 代表文档(document), 这个值的意思是 t 在 d 中的词频乘以 log(语料总文档数量 比 包含t的文档的数量)。
BERTopic 使用的是相同的策略,只不过文档 d 做了一些改变:将一个 cluster (也就是一个类 class) 中的所有文档拼接起来作为新的单个文档 d. 这样 TF-IDF 公式就变成了 c-TF-IDF:
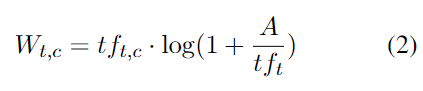
其中,c 表示 class, A 表示每个 class 的平均单词数量, 表示 class c 中 t 的频率, 表示所有 class 中 t 的频率。
就这样,簇 c 里的每个单词 t 都有了一个分数,分数越高,越能代表这个簇的主题, 显然这个候选集合是收束在簇 c 的范围里面的。
动态主题建模
和静态主题建模不同,动态主题建模考虑到了文档本身随时间的变化特征,即2022年的文档和2012年的文档主题分布是不一样的,2022年大家在讨论的主题是“三体”即将上映,而2012年大家讨论的主题是“2012世界末日”.
针对这种情况,本文引入了新的 TF-IDF 公式:
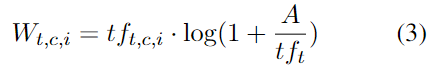
这里的 i 表示第 i 个 timestep.
平滑化
对于动态主题建模另外一个可能有用的假设是,不同 timestep 的 topic 可能是线性相关的,因此作者引入了平滑技巧(optional):
-
首先进行 L1-normalization (即除以 L1-norm), for each topic and timestep.
-
然后对 normalized vector 进行 average 平滑操作:将第 i 时刻的值与第 i-1 时刻的值进行一个平均作为新的第 i 时刻的值。
2. 效果
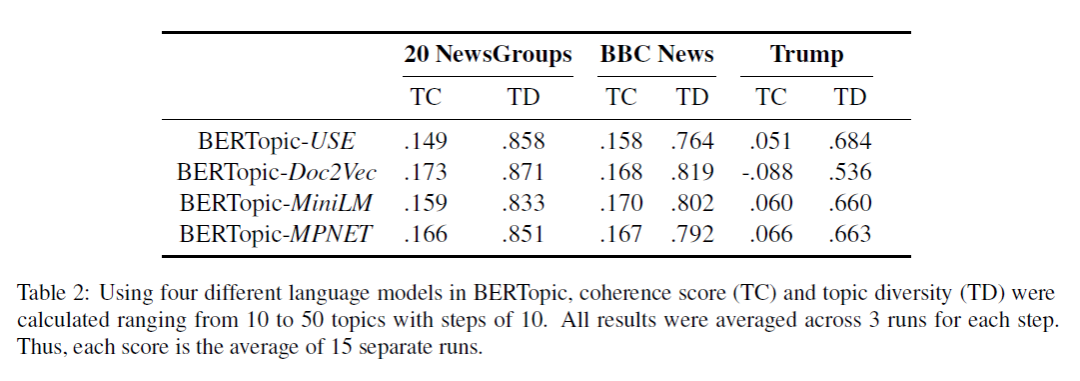
作者使用 "all-mpnetbase-v2" SBERT model 作为 embedding model, 在 20 NewsGroups、BBC News、Trump 等数据集上进行了实验,对比结果如下图:
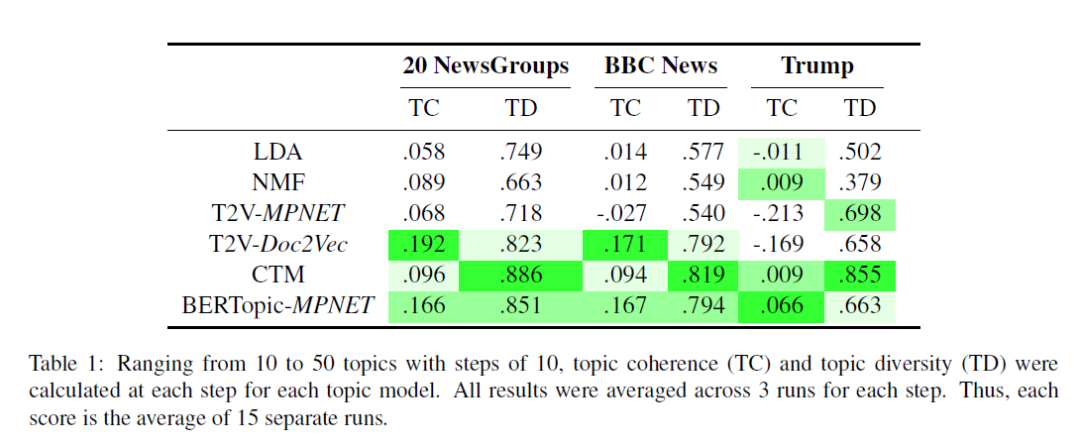
▲可见,BERTopic 有更好的综合能力
然后不同的 embedding model 对效果也会有影响:
对于动态主题建模,BERTopic 也有很好的综合效果:
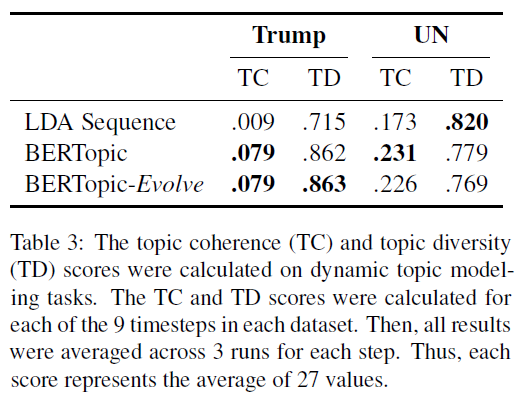
▲Evolve 表示使用了上文介绍的平滑技巧
总结下来就是:
BERTopic 优点:弥合了基于密度聚类和基于中心采样之间的 gap;适用于各种语言模型,从而可以根据需要与实际资源量灵活选择可用模型;嵌入聚类和主题生成(采词)是解耦的两个阶段;静态、动态主题建模用的是同一套框架, minimal change.
缺点:没有考虑单文档多主题;因为仅仅考虑了文档的上下文表示而主题词仍然来源于词袋,所以主题当中的单词可能高度相似从而具有一定的冗余性。
[1] Leland McInnes, John Healy, Nathaniel Saul, and Lukas Grossberger. 2018. Umap: Uniform manifold approximation and projection. The Journal of Open Source Software, 3(29):861.
[2] Leland McInnes, John Healy, and Steve Astels. 2017. hdbscan: Hierarchical density based clustering. The Journal of Open Source Software, 2(11):205.


