
- 1北邮考研数学:第一章_什么时候 把所有式子移到一边证明最小值大于零最大值小于零 什么时候分别证明
- 2利用 QGIS 载入和处理 S-57 电子海图数据_s57 数据处理
- 3用 TensorFlow 做个聊天机器人_tersonflow 智能问答
- 4Linux网络知识详解以及demo(Centos6、7)——OSI、TCP、UDP、IP、子网掩码/划分、网关、路由、广播、虚拟网络、网卡、交换机、DNS、ARP_linux网络协议的基本知识,包括tcp/ip、dns和dhcp
- 5如何解决收到网监大队信息系统安全等级保护限期整改通知书_网安大队 注入漏洞
- 6Aarch64架构:xavier安装torch-gpu_loongarch64安装torch
- 7macOS Monterey 12.6.6 (21G646) 正式版发布,ISO、IPSW、PKG 下载_macos 12.6.6
- 8sort函数(c/c++语言排序)_sort函数c语言
- 9高清视频录播服务器网站,高清录播服务器——DDA RSS3000
- 10HarmonyOS应用开发:资源文件的引用-$rawfile、$r
人工智能之机器翻译_人工智能机器翻译概念
赞
踩
发展历程:
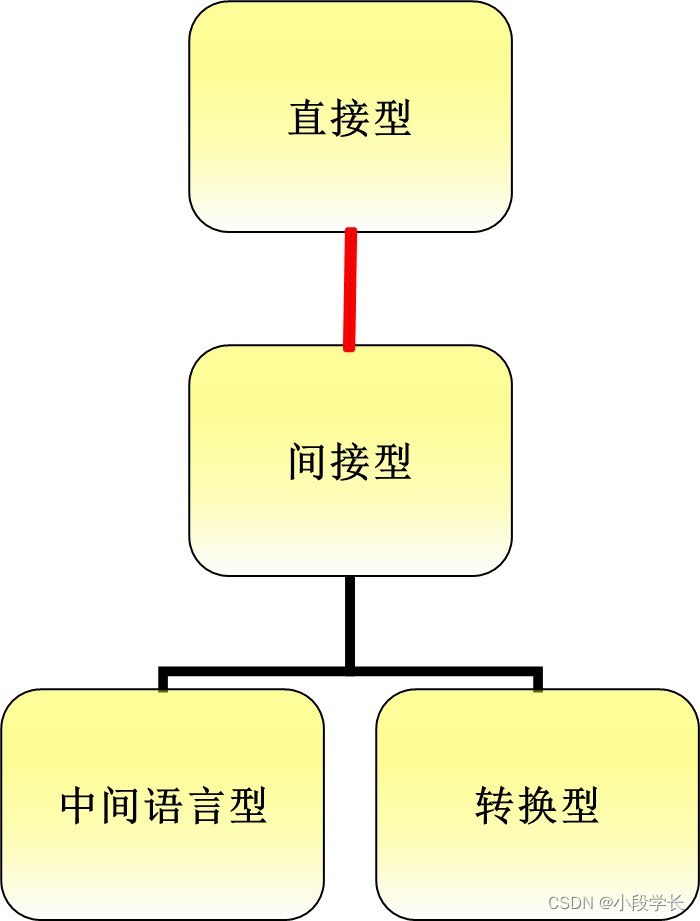
1. 直译式翻译系统(direct translation MT systems)
通过快速的分析和双语词典,将原文译出。

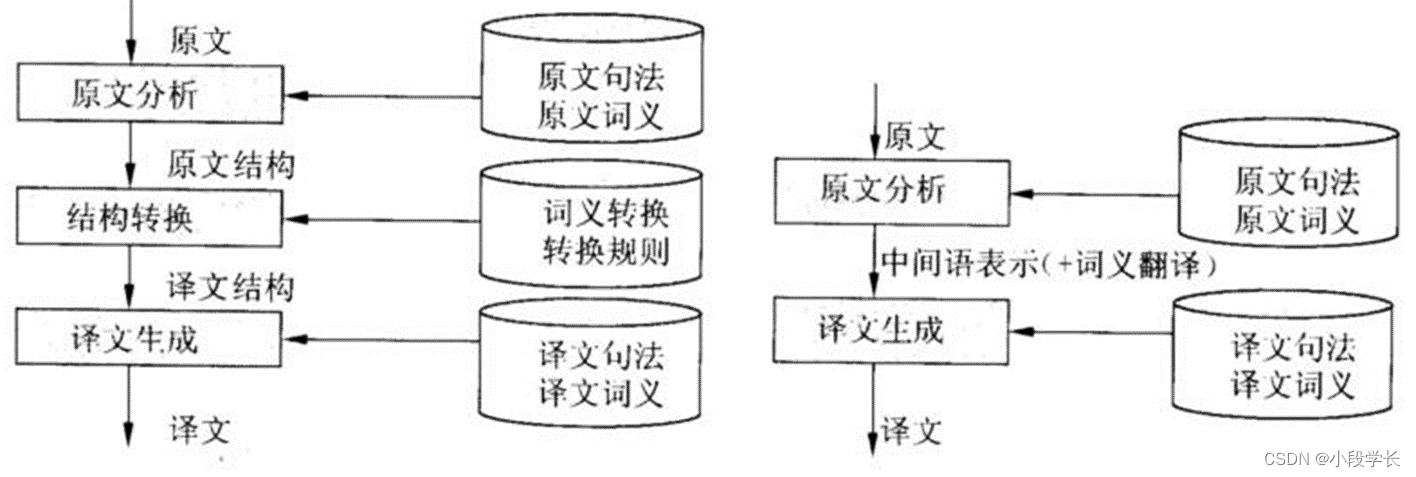
2. 规则式翻译系统(rule-based MT systems)
先分析原文内容,产生原文的句法结构,再转换成译文的句法结构,最后再生成译文。
3. 中介语式翻译系统(inter-lingual MT systems)
先生成一种中介的表达方式,而非特定语言的结构;再由中介的表达式,转换成译文。
4. 知识库式翻译系统(knowledge-based MT systems)
翻译经常需要除了词汇之外的各种知识,使用知识获取工具(knowledge acquisition),以充实知识库的内容。
5. 统计式翻译系统(Statistics-based MT systems )
1994年,IBM公司A.Berger等用统计方法和各种不同的对齐技术,给出了统计式机器翻译系统Candide。
统计机器翻译基本思想是通过对大量的平行语料进行统计分析,构建统计翻译模型,进而使用此模型进行翻译。
目前,基于统计法机器翻译系统有Google翻译、Bing翻译和百度翻译等。
统计机器翻译的首要任务是为语言的产生构造某种合理的统计模型,并在此统计模型基础上,定义要估计的模型参数,并设计参数估计算法。
早期的基于词的统计机器翻译采用的是噪声信道模型,采用最大似然准则进行无监督训练,而近年来常用的基于短语的统计机器翻译则采用区分性训练方法,一般来说需要参考语料进行有监督训练。
6. 范例式翻译系统(example-based MT systems )
将过去的翻译结果,当成范例,产生一个范例库。
7. 翻译记忆(translation memory, TM )
基本原理:用户利用已有的原文和译文,建立起一个或多个翻译记忆库,在翻译过程中,系统将自动搜索翻译记忆库中相同或相似的翻译资源(如句子、段落等),给出参考译文,使用户避免重复劳动,只专注于新内容的翻译。翻译记忆库同时在后台不断学习和自动储存新的译文,变得越来越聪明。
德国塔多思(TRADOS)公司的翻译记忆软件基于UNICODE(统一字符编码),支持55种语言,覆盖了几乎所有语言版本的 Windows95/98/NT 。
混合式翻译系统(Statistics-based MT systems )同时采用多种策略,以达成翻译的目标。
8. 神经机器翻译
神经机器翻译是模拟人脑的翻译过程,目前已经远远超过统计机器翻译,成为机器翻译的主流技术。
长短期记忆神经网络(LSTM)是一种对序列数据建模的神经网络,适合处理和预测序列数据。而且,LSTM使用“累加”的形式计算状态,这种累加形式导致导数也是累加形式,避免了梯度消失,因此在神经机器翻译中得到了广泛应用。
目前,神经机器翻译领域主要研究如何提升训练效率、编解码能力以及双语对照的大规模数据集。
网络上很多神经机器翻译的开源实现,如Groundhog (https://github.com/lisa-groundhog/GroundHog)。
欢迎大家加我微信交流讨论(请备注csdn上添加)


