
- 1LightPicture精致图床PHP系统源码+功能强大_图床源码
- 2uni-app 移动端登录页面
- 3常见的7种深度学习框架对比_不同深度学习框架的区别
- 42020-12-07_english bruce lin博客
- 5机器学习数学基础:常见分布与假设检验_均匀分布检验 假设检验
- 6前端Serverless:面向全栈的无服务架构实战 -- 1.Serverless综述(笔记)_前端 serverless
- 7python使用百度AipOCR来实现图像文字识别_百度ocr代码
- 8PyQt5可视化 7 饼图和柱状图实操案例 ③柱状图的实现【超详解】_pyqt 柱状图
- 9二分查找的模板_二分查找代码模板
- 10GPT指令百科全书,函4.0使用镜像地址_gpts4.0镜像
20万DBA都在关注的11个问题
赞
踩
引言
近期我们在DBASK小程序增加MySQL、PostgreSQL以及黄玮的专题栏目,欢迎大家阅读分享。
问答集萃
接下来,我们分享本期整理出的问题和诊断总结,供大家参考学习,详细的诊断分析过程可以通过标题链接跳转到小程序中查看。
问题一、impdp中断后,监听多出SYS$SYS.KUPC,无法清理
如图,serveice中多了很多KUPC:
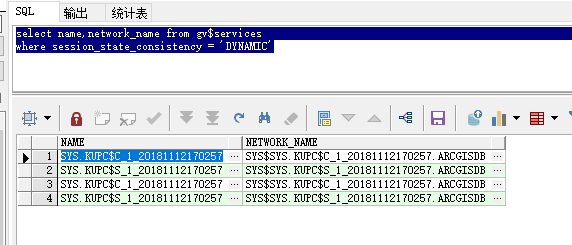
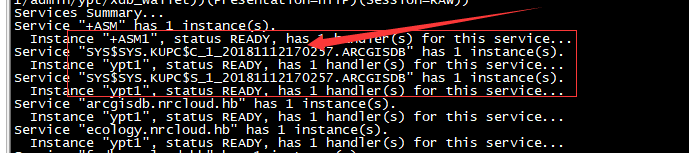
使用DELETE_SERVICE包也删除不掉
- begin
- DBMS_SERVICE.DELETE_SERVICE(service_name=>'SYS$SYS.KUPC$S_1_20181112170257');
- end;
- /
目前只在节点1出现,想请教一下怎么清理这种无效的连接服务?
诊断结论:参考How to delete SYS.KUPC$ service after kill datapump job,先要STOP_QUEUE,再DROP_QUEUE即可。
请教个问题,我的RACIP配置如下:
- 192.168.56.10 rac1
- 192.168.56.11 rac2
- 10.10.10.10 rac1-priv
- 10.10.10.11 rac2-priv
- 192.168.56.12 rac1-vip
- 192.168.56.13 rac2-vip
- 192.168.56.14 rac-scan
现在我模拟场景,RAC1主机宕机,RAC1-VIP漂移到RAC2节点。数据库的服务名是ORCL
我通过192.168.56.13去连接ORCL服务名是可以的,通过192.168.56.12去连接服务名是不可连接的,这种情况是不是正常的现像??
诊断结论:rac的vip在不发生故障的时段,连接数据库是正常。一旦发生漂移,这个vip漂到别的节点,就是不可以连接数据库的。这是正常现象。vip在这里的意义是迅速给app反馈信息,让app去连别的vip。如果没有vip,那app要等待60秒才能等到tcp超时。这个时间是不允许的 。
问题三、expdp导出含lob字段某一张大表报错ora-01555
11201,expdp,每周出现2-3次ora01555
1、undo表空间空间充足 2、undo_retention和dba_lobs中表的retention很大,远大于v$undo中maxquerylen值。
3、lob段没有坏块 请问还有其他原因吗,如何排查?
诊断结论:lob的undo不是存放在undo表空间的。他是跟lob数据所在表空间存在一起的。这个没有什么太好的办法导出,一般是建议对一个表按照rowid进行切分,划分成多个片来导出。
在aix主机的rman备份可以在x86的linux主机上恢复吗?
诊断结论:可以恢复,但是存在大小字节序问题,需要RMAN convert from platform 'AIX-Based Systems (64-bit)'的方式转换字节序,并做恢复。
问题五、sqlplus连接ASM实例connected to an idle instance
oracle11.2.0.3,rac集群资源都正常,grid环境变量也没问题,但是sqlplus / as sysasm连接ASM实例的时候显示connected to an idle instance。数据库实例可正常连接。
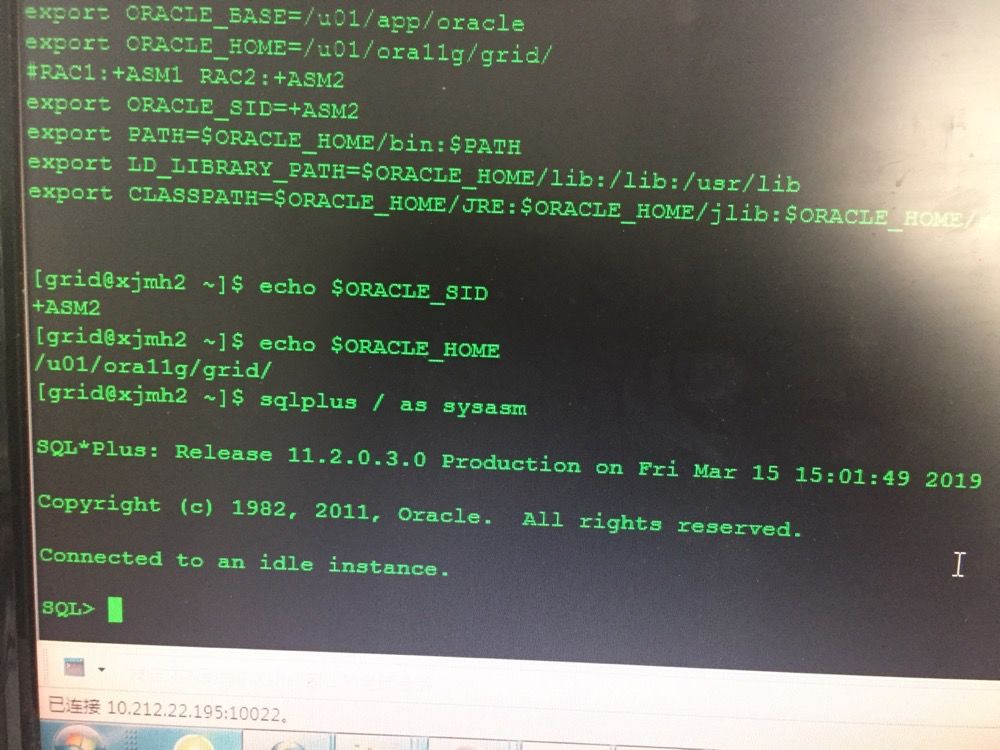
诊断结论:重置环境变量ORACLE_HOME: 去掉 /u01/ora11/grid/ 中的"/" 。
oracle的表空间碎片如何查询,到什么样的程度oracle表空间中的碎片需要整理?
诊断结论:首先要收集表的统计信息,然后通过统计信息计算出实际空间与user_extents占用的空间相比,一般碎片超过25%就可以考虑shrink或者move整理表碎片,相关SQL请查看详情。
我想咨询一下,oracle 11.2.0.4.0开了归档,没有启用追加日志模式,能做日志挖掘吗? 或者这样说:生产库的一个表数据突然不见了,用了闪回查询将数据恢复了。现在只启用了归档日志,领导需要汇报具体原因。我不知道从何下手。 求助各位专家。
诊断结论:根据我的测试,11.2.0.4没有开supplymental logging也是有会话信息的,因为_TRANSACTION_AUDITING参数默认是TRUE,redo就会包含会话信息。但是我测试结果发现会丢失部分记录信息(比如delete 10条只会miner到6条,打开supplymental logging则是完整的),所有你可以logmnr尝试下。
从多家二级医院向上级数据中心汇总数据,有的二级医院是oracle库,有的二级医院是sqlserver库,让这些二级医院导出什么格式的数据包,方便上级数据中心汇总,数据中心使用的是oracle库,谢谢
诊断结论:如果是多表可以考虑ogg,支持多种数据库的实时数据同步,也可以用java、python编写一个导出和导入的小程序或者脚本。数据格式最简单的就是纯文本,对应目标端的表结构,一行一条数据,导入oracle很方便,也有很多方法。
请问触发器中是否可以提交事务?
诊断结论:默认情况下,触发器不允许commit,随触发该触发器的事物同时提交或者回滚。在8i之后可以使用自治事物在触发器中commit,相当于事物的子事物,示例请查看详情。
有个大表,已经清理了95%.需要shrink,cascade发现影响业务。分两步回收,compat,还有shrink,这两个会影响业务吗?回收时间各多久?
诊断结论:首先lob字段不会级联shrink,需要单独处理。如果没有业务停机时间,可以考虑你说的分两步,先SHRINK SPACE COMPACT再SHRINK SPACE CASCADE,另外可以考虑不加CASCADE减少时间,然后再单独处理相关索引,至于操作时间与数据量和在线业务量有关,建议测试库测试大致操作的时间。
问题十一、rac-rac双节点DG,主备手动切换之后新主库状态为RESOLVABLE GAP
关闭主备2节点切换角色后,检查状态,发现主库的状态为RESOLVABLE GAP;有哪些情况会产生该状态?以及解决办法。
诊断结论:备库目前还有日志没有同步完,需要手工将未同步的redo日志刷新到备库,并让备库应用这些日志,如果存在归档日志未应用,需要拷贝归档日志到备库并register到备库并应用。总之,在切换之前先检查同步是否完成,主库状态为to_standby再进行switchover操作。
出处:恩墨云服务(ID:enmocs)
往期精彩
公司简介 | 招聘 | DTCC | 数据技术嘉年华 | 免费课程 | 入驻华为严选商城

zCloud | SQM | Bethune Pro2 | zData一体机 | Mydata一体机 | ZDBM 备份一体机

Oracle技术架构 | 免费课程 | 数据库排行榜 | DBASK问题集萃 | 技术通讯

升级迁移 | 性能优化 | 智能整合 | 安全保障 | 架构设计 | SQL审核 | 分布式架构 | 高可用容灾 | 运维代维
云和恩墨大讲堂 | 一个分享交流的地方
长按,识别二维码,加入万人交流社群

请备注:云和恩墨大讲

