
- 1大数据Hadoop之——部署hadoop+hive+Mysql环境(window11)_hadoop mysql
- 2【修改huggingface transformers默认缓存文件夹】_transformers_cache
- 3大数据在推荐系统中的作用_推荐系统与大数据安全
- 4android 检测无用资源,一个自动清理Android项目无用资源的工具类及源码
- 5【深度学习】-Imdb数据集情感分析之模型对比(4)- CNN-LSTM 集成模型_cnn-lstm做情感分析的时候需要保证cnn的输出和bilstm的输出维度一致吗
- 6Wireshark 抓包工具与长ping工具pinginfoview使用,安装包_wireshark端口抓包命令
- 7Neo4基础语法学习_neo4j语法教程
- 8注意力机制(Attention)原理详解_attention层
- 9毕业设计 基于单片机的智能盲人头盔系统 - 导盲杖 stm32
- 10基于ZooKeeper的Kafka分布式集群搭建与集群启动停止Shell脚本
caffe模型文件解析_干货|手把手教你在NCS2上部署yolov3-tiny检测模型
赞
踩
如果说深度学习模型性能的不断提升得益于英伟达GPU的不断发展,那么模型的边缘部署可能就需要借助英特尔的边缘计算来解决。伴随交通、医疗、零售等行业中深度学习应用的发展,数据处理和智能分析逐渐从云端走向边缘。本人与大家分享一下英特尔的边缘计算方案,并实战部署yolov3-tiny模型。
OpenVINO与NCS简介
早在2016年,英特尔收购了Movidius,并在2018年推出了两代神经计算棒(分别称为NCS和NCS2,统称NCS设备)。除了硬件,英特尔推出了OpenVINO深度学习部署工具包,并且在2018年下半年更新了5个版本,早期称为dldt[1],其中包括模型优化器和推理引擎以及面向OpenCV和OpenVX的优化计算机视觉库。

图1: NCS和NCS2
NCS基于Mygrid2VPU,NCS2[2]是基于Mygrid X VPU,英特尔®Movidius™Myriad™X VPU是最新一代的英特尔®VPUs。它包括16个强大的处理内核(称为SHAVE内核)和专用的深度神经网络硬件加速器,用于高性能视觉和AI推理应用。
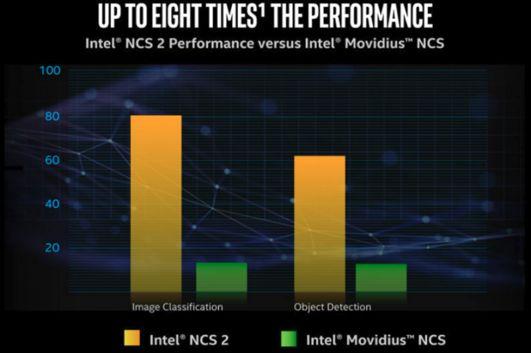
图2: NCS和NCS2性能比较
要在NCS设备上跑神经网络,可以使用Movidius SDK(ncsdkv1和ncsdkv2),ncsdkv2与ncsdkv1不兼容,ncsdkv1现在基本已经被弃用,并且ncsdkv1和ncsdkv2仅支持一代计算棒NCS,不支持NCS2,只有OpenVINO同时支持NCS和NCS2。OpenVINO实际上包含了Movidius SDK,相对于Movidius SDK一是增加了对深度学习功能的支持,其中包含一个深度学习的部署工具套件,里面包括了模型优化器和推理引擎;另外增加了对OpenCV、OpenVX等这些在传统计算机视觉领域用的比较普遍的函数库的支持,而且这些函数库都在英特尔的CPU上做了优化。与Movidius SDK相比,原来只是做编码、解码的加速,现在不仅能做编解码的加速,也能做视频处理工作,把Movidius SDK结合在一起,在整个流水线里面所用到的所有工具打在一起放到OpenVINO里面,让开发者只用一个工具把所有的需求都能满足[3]。
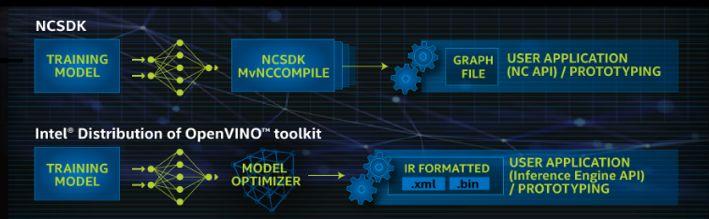
图3: NCSDK和OpenVINO工具包工作流程对比
OpenVINO和Movidius SDK的主要区别如下:
1. 环境变量:相对于Movidius SDK强制的修改bashrc添加Movidius SDK的工具到环境变量中,OpenVINO的做法更加人性化,单独将次操作写入setupvars.sh脚本,让用户自行选择是否以及何时添加环境变量
2. 支持框架:相对于Movidius SDK仅支持Caffe和TensorFlow,OpenVINO还支持MxNet、Kaldi和ONNX等模型的转换
3. API方面:Movidius SDK提供C和Python接口,OpenVINO提供C++和Python接口
4. 模型优化器:OpenVINO模型优化器可以自动执行与设备无关的优化,例如将BatchNorm和Scale融合到卷积中,在Movidius SDK转换前需自行融合后再转换模型。Movidius SDK提供三种工具来测试并转换模型,OpenVINO仅包含模型优化器mo.py用于转换IR中间过程文件(xml描述网络结构,bin包含权重和偏差二进制等数据),分析网络性能可以在运行程序的时候指定参数
5. 多NCS设备情况:Movidius SDK提供所有NCS列表,用程序员决定在特定的设备上进行推理,OpenVINO工具包根据设备负载向NCS设备分发推理任务,因此无需关心特定的NCS设备或者管理NCS设备
OpenVINO相对于Movidius SDK更加成熟完善,不足之处是目前除了树莓派[4]还无法在ARM上使用。如果你还没有使用过Movidius SDK,强烈建议你直接安装OpenVINO,如果你现在正在使用Movidius SDK,也推荐你更换为OpenVINO[6]。OpenVINO结合NCS或NCS2,在边缘设备部署深度学习模型妥妥的。
OpenVINO不仅有Windows版本,还有Linux、LinuxforFPGA、Raspberry版本。如果说ncsdk专门为NCS设备而生,OpenVINO则是Intel的产业布局中的重要一环,支持Intel CPU、NCS、NCS2、Movidius VPU、Intel GPU、FPGA等,借助于IR中间过程文件,可以在上述硬件上部署模型或者在跨两个处理器上部署异构模型(拆分模型)。
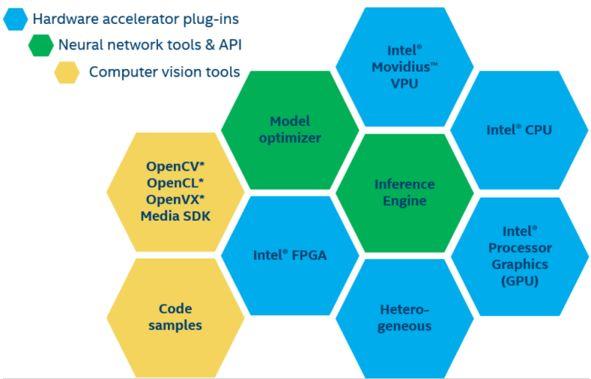
图4: OpenVINO工具包支持的硬件
啰啰嗦嗦介绍了这么多,关于模型优化器和推理引擎更加详细的介绍,请参考Developer Guide[7][8]。下面开始撸起袖子动手干起来。
Linux下安装OpenVINO
首先介绍下笔者使用的平台和软硬件信息:
处理器:Intel® Core™ i7-7700 CPU @ 3.60GHz × 8
操作系统:Ubuntu16.04 LTS x86_64
NCS设备:NCS、NCS2
OpenVINO:2018 R5 Linux版本[5]
安装过程这里不一一赘述[9],下面说说一下需要注意的地方:
1. 如果已安装早期版本的OpenVINO,需要重新转换模型,不同版本编译出来的过程文件有差异,加载的模型的时候很可能会失败
2. 建议使用root账户避免Intel Media SDK权限问题,当然可以使用常规用户运行安装脚本,可以运行GUI安装向导或者命令行指令,笔者使用的是常规账户安装
3. 由于我们最后要使用NCS设备,注意在Select Components to install页面查看VPU相关选项是否打开
4. 如果使用root权限运行安装,OpenVINO安装在`/opt/intel/`目录,否则会在`/home/user/intel/`目录
5. 安装成功后会自动安装上OpenCV4.0.1,因此如果后续使用出现OpenCV版本冲突需要注意
6. 配置临时环境变量在终端执行source ~/intel/computer_vision_sdk/bin/setupvars.sh,关闭终端失效。 也可以将上面语句添加到~/.bashrc文件末尾永久设置环境变量,因为OpenCV版本的问题建议配置临时环境变量
7. 配置模型优化器,可以一次为所有的框架配置也可以单独配置一个框架,仅在开发平台配置即可,目标平台无需配置
8. 配置NCS设备的USB udev rules ,建议使用安装页面中推荐的手动安装方式,注意如果在目标平台打开NCS设备失败,首先使用lsusb命令检查是否能找到NCS设备,没有厂商信息,只有设备编号,NCS的设备编号是‘03e7:2150’,NCS2的设备编号是‘03e7:2485’
9. 编译并运行例子程序验证安装是否成功,有些程序可能在NCS设备上运行失败,比如smart_classroom_demo,NCS设备上不支持批处理模式
yolov3-tiny模型优化
关于yolov3-tiny模型的原理和训练可以参考SIGAI的其他文章,这里不做介绍。下图表示了基于OpenVINO的深度学习部署流程,下面我们一步步来实现基于OpenVINO+NCS设备的yolov3-tiny演示程序。
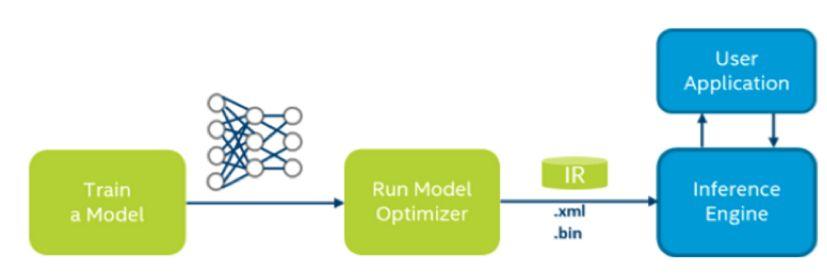
图5: OpenVINO部署工作流程
笔者手头yolov3-tiny模型是darknet模型,输入图像尺寸是416*416,在VOC2007和VOC2012的train和val四个数据集进行训练,VOC2007的test数据集作为验证集。OpenVINO不支持darknet模型转换,因此首先需要将darknet模型转换为OpenVINO支持的模型,这里转换为caffe模型[10],也可以转换为tensorflow模型[11],当然也可以在tensorflow下直接训练[12]。从darknet转换caffe模型[10],这里提几个转换要点:
1. 针对maxpool中size=2、stride=1的情况,由于darknet和caffe中计算输出尺寸公式不同,可以在caffe模型设置stride=1,kernel=3,pad=1,但是不建议这样进行转换,会有较大的精度损失。因此建议将这样的maxpool层size设置为3,并重新训练模型,转caffe时设置pad为darknet中pad/2
2. 训练时需要注意resize的方法,darknet默认的方法是letterbox,一般常规的resize方法是不等比例,训练和测试时使用的resize方法不一致,精度会降低很多

图6: 两种resize模式(左图原图,中间不等比例resize,右图letterbox方式)
3. route层转换为concat层、shortcut层转换为eltwise层
4. 由于NCS设备和CPU不支持upsample层,因此将upsample层转换为deconvolution层,注意替换的过程,使用的是constant filler,value设置为1
5. yolo层不进行转换,有两种做法一是将yolo前面一层作为输出,yolo层在CPU上进行运算,二是可以将yolo层作为自定义层,本方案中采用第一种
6. 转换过程或多或少会有精度损失,因此转换完成后建议在caffe上重新测试精度,确定转换过程没有问题
完成caffe模型的转换,需要使用OpenVINO模型优化器将caffe模型转换为的OpenVINO中间过程IR文件,转换参数参考[13]注意以下两点:
1. OpenVINO输入网络的数据设置为U8,输入网络数据需要除以255进行归一化
2. OpenVINO在CPU下支持模型格式是FP32,NCS设备上支持的格式是FP16
python3 mo_caffe.py --input_proto yolov3-tiny.prototxt --input_model yolov3-tiny.caffemodel --data_type FP16 --output_dir FP16 --model_name yolov3-tiny --scale_value data[255.0]
至此完成模型的准备工作,还差最后一步。
yolov3-tiny模型部署
在OpenVINO的例子程序中有yolov3的演示程序,是基于tensorflow转换得到的yolov3模型,可以参考该例子程序以及集成推理引擎步骤进行修改。
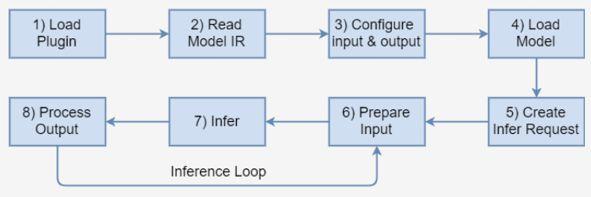
图7: 应用程序中集成OpenVINO推理引擎的步骤
修改过程有几个需要注意的地方:
1. 训练模型时使用的resize模式是letterbox,OpenVINO支持的resize方式(bilinear、area)并不支持letterbox,因此需要在CPU上完成resize过程
2. 注意输入网络图像的三通道顺序,yolov3-tiny输入网络的顺序是RGB
3. 输入网络配置为U8,NCHW模式,官网介绍中输入网络支持FP32,因此归一化也可以在CPU上进行
4. 输出网络配置为FP32,NCHW模式,由于CPU模式不支持FP16,因此这里为了统一CPU和NCS设备上代码,统一使用FP32

图8: 左图caffe下测试结果,右图NCS2测试结果
yolov3-tiny性能测试
既然转换模型成功,部署也成功了,当然需要评测一下速度和精度了。废话不多说,直接看下文。
精度测评,评价指标mAP
测试集VOC2007_test,共4952张图像,mAP计算过程与darknet一致:

表1 精度测评模型
* 上述在letterbox缩放方式下测试结果,当使用不等比例缩放时CPU上mAP下降到39.14%
* 从上表可以看出精度并没有太大变化
速度测评,评价指标FPS
有几个要点需要说明:
1. USB3.0接口,最好使用有源的USB Hub
2. OpenVINO支持同步模式和异步模式,所谓的同步模式就是传输一张图像等待网络输出,异步模式就是传输下一张图像并等待当前图像返回结果,这样节省部分传输等待时间,以下速度测试在异步模式下测试
3. 帧率是指全流程的速度,包含读取图像解码时间、图像缩放时间、YOLO层运算以及从YOLO层输出转换得到检测结果,也就是图7中中6-8步骤的时间
4. 缩放函数使用OpenCV,使用darknet中的浮点计算方法帧率降低一半

表2 速度测评模型
目前OpenVINO还在开发中,本文资料针对R5版本适用,好了啰嗦这么多希望对大家有所帮助。暂时还不方便公开代码,请见谅,给大家推荐一个公开的通过tensorflow转换到OpenVINO的程序[14]。
参考资料
1. OpenVINO源码:
https://github.com/opencv/dldt
2. NCS2:
https://ncsforum.movidius.com/discussion/1302/intel-neural-compute-stick-2-information
3. OpenVINO与Movidius SDK的区别:
https://www.xianjichina.com/news/details_80102.html
4. Raspberry版本下载:
https://software.intel.com/en-us/articles/OpenVINO-Install-RaspberryPI
5. OpenVINO下载:
https://software.intel.com/en-us/openvino-toolkit/choose-download/free-download-linux
6. 从sdk过渡到OpenVINO:
https://software.intel.com/en-us/articles/transitioning-from-intel-movidius-neural-compute-sdk-to-openvino-toolkit
7. 模型优化器Developer Guide:
https://software.intel.com/en-us/articles/OpenVINO-ModelOptimizer
8. 推理引擎Developer Guide:
https://software.intel.com/en-us/articles/OpenVINO-InferEngine
9. Linux安装OpenVINO:
https://software.intel.com/en-us/articles/OpenVINO-Install-Linux
10. darknet转caffe:https://github.com/marvis/pytorch-caffe-darknet-convert
11. darknet转tensorflow:
https://github.com/mystic123/tensorflow-yolo-v3.git
12. tensorflow下训练yolov3-tiny:
https://github.com/YunYang1994/tensorflow-yolov3
13. OpenVINO转换caffe模型参考:
https://software.intel.com/en-us/articles/OpenVINO-Using-Caffe
14. OpenVINO+tensorflow+yolov3/yolov3-tiny:
https://github.com/PINTO0309/OpenVINO-YoloV3

