
- 1CentOS 7修改SSH端口_centos7 更换ssh端口 seliunx
- 2关于打包arr包含第三方资源冲突解决_打包不同的aar包,各个aar包里面有冲入字符串资源
- 3互联网摸鱼日报(2024-03-29)
- 4TCP/IP协议,TCP和UDP的区别及特点_tcp/ip协议中pct和udp区别
- 5三十八、动态规划——背包问题( 01 背包 + 完全背包 + 多重背包 + 分组背包 + 优化)_动态规划背包
- 6我通过Python做副业每个月收入30000+,这绝对是2023最赚钱的副业_python赚钱吗
- 7手把手教你学Python之波士顿房价预测_波士顿房价预测决策树python代码原理
- 8最全的java对接微信小程序客服功能实现(包含自动回复文本消息、图片消息,进入人工客服)_java实现连接微信客服的方法
- 9实验3 决策树 实操项目2:顾客购买服装的分析与预测_实验3 决策树 实操项目2:顾客购买服装的分析与预测
- 10NLP基础2-jieba中文处理_from jieba.ana
2021年数学建模国赛C题问题一详细思路和代码
赞
踩
2021年高教社杯数学建模C题问题一详细思路和代码
话不多说,先上Github代码:
谢谢友友们的支持吖,这里是21年国赛C题的分析,文末有小编精心整理的代码和源文件哦,这里小编已经再Github上开源了,想要的小伙伴可以点赞+关注+收藏哦,即可在文末评论区领取完整源代码!
1 问题分析
问题一要求我们利用近五年企业的订货量和供应商的供货量数据对供应商的供货特征进行量化分析,并以企业生产重要性为目标建立数学模型,选择出相对重要的供应商。
供货特征是供应商管理绩效的直接表现,目前业内广泛认可的指标有:质量、成本、交货、服务、技术、资产、员工与流程,合称QCDSTAP。结合本题所给的数据,我们最终选择了成本、交货和资产作为本题量化的供货特征。关于成本指标,可以利用供应商所供应的原材料采购单价来衡量;关于交货指标,在本题中,它主要反应了供应商是否按订货量交货,可以利用企业订货量与对应的供应商供货量之间差距来衡量,差额越小,说明该供应商的交货越符合规范;关于资产指标,它主要反应了供应商的经济规模,可以用供应商5年间的供货量之和来衡量。
企业生产中“降本增效”是生产中最重要的,本题基于降本增效,建立起供应商对于企业生产重要性的评估模型。供货特征中交货和资产反映了“增效”,而成本反映了“降本”,所以我们以量化的三个供货特征,通过权重计算得到每个供应商的重要性。为了确定各指标的权重,我们首先利用主成分分析对原始数据降维,并利用降维的数据对供应商进行了K-means聚类,将供应商分为两类:重要与不重要。然后,结合分类结果,利用灰色关联分析对量化的三个供货特征指标进行了分析,确定了各指标与供应商重要性的关联度。最后利用得到的关联系数,结合熵权法,确定了各指标的权重。
为了确定50家最重要的供应商,我们引入商业采购中常见的“二八法则”,即数量20%的采购物占总采购价值的80%,其余80%的采购物占总采购价值的20%。本文的采购价值,是通过的供应商的重要性来表示。最后基于供应商累计重要性为80%的切分点,确定了50家最重要的供应商。具体思路流程图如下:
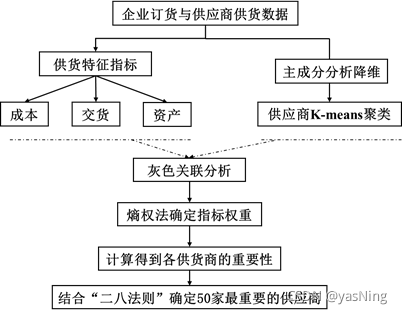
2 数据预处理与分析
本题附件一和附件二中数据量均不大,没有缺失值,但是观察分析后我们发现存在一些异常值。即:企业的订货量和供货商的供货量相差非常大,达到了几百到几千立方米。虽然题目中指出由于原材料的特殊性,供应商不能保证严格按订货量供货,实际供货量可能多于或少于订货量。但是对于相差几百甚至几千的数据,可能会严重影响到企业的生产需求,故我们对于这类数据做均衡处理。即当订货量和供货量相差大于20时,我们以订货量为基准,对供货进行均衡化调节,重新产生一个和订货量相近的数据取代替附件中供货量,以此消除相差过大带来的影响。
为了直观把握企业每周的订货量和供应商每周供应量的变化情况,我们对其数值进行了可视化,如下图
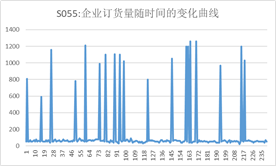
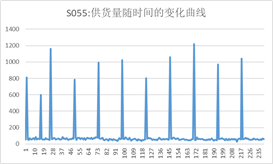
从图上来看,企业的订货量和供应商的供货量呈周期性变化,有一定的规律,后续问题也可通过此规律进行分析
3 供货特征的量化
下面具体介绍供应商的成本指标、交货指标和资产指标的量化方法。
成本指标
供货商供货时,原材料的价格体现了其供货特点,本题中共有三种原材料,其采购单价各不相同,我们利用原材料的种类可以很好的量化得到成本指标。设单位采购价格为1,得到了ABC三种原材料的价格分别为1.2、1.2和1。供货商的成本指标就取对应的所供原材料价格,实现对成本指标的量化。
交货指标
供货商供货时是否按企业订货量交货决定了交货指标的好与坏,这里我们利用企业订货量和其对应的供货商供货量的差值来量化交货指标,差值越小,则说明供货商交货越符合规范。为了描述供货商在五年之中的交货情况,我们把一个供货商五年中每一周的差值的绝对值相加,其综合越小,则供货商在五年里的交货越符合规范,下面给出交货指标的计算公式:
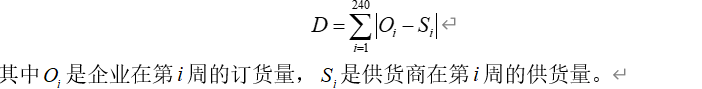
资产指标
供应商资产规模大小一定程度上反映着它的供货特点,为了合理量化供应商的资产指标,我们认为五年内供货量大的供货商,其资产应该较大,据此给出资产指标的具体计算方法:
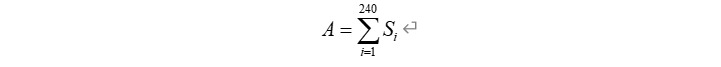
4 供货商在保障企业生产中的重要性量化模型
为了保障企业生产,我们建立了评估供货商在保障企业生产中的重要程度的模型,基于量化的供货特征计算得到了每个供货商的重要性。下面给出重要性的计算公式。

供货特征指标与供货商重要性的关联分析
分析发现,我们量化后的三个供货特征均对企业保障生产中“降本增效”的目的起着关键作用,很难说清楚哪一个指标更重要,为了弄清三个指标与供货商重要性的关联,我们首先利用K-means聚类把供货商从理论上为分为“重要”与“不重要”,即 “战略型供应商”和“考察型供应商”,因为K-means聚类算法具有将相似的个体进行区分的效果,所以从理论上来讲,我们的分类可以达到目的。在聚类之前我们对原始的240维的数据进行了主成分分析,以贡献率大于80%为基准,把数据维度降到了11维,然后再进行聚类。
然后再利用分类后的结果作为供应商是否重要的体现,利用灰色关联分析,探究三个指标对供应商是否重要的影响。下图是利用Python对402家供货商进行K-means聚类后,再利用PCA降维后(11维降到2维)可视化的结果
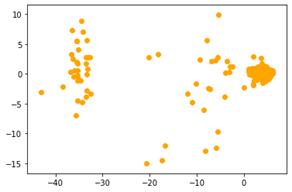
聚类后降维可视化的样本分布
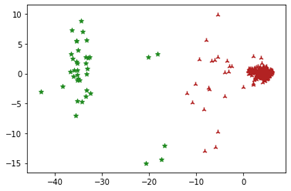
聚类结果
分析聚类结果后,我们发现两类供货商的数量基本在40和360左右波动,也反映了重要的供货商较少的理论。
把聚类后的结果与量化计算得到的三个供货特征相结合,得到了灰色关联分析之前的数据如下:
把聚类后的结果与量化计算得到的三个供货特征相结合,得到了灰色关联分析之前的数据如下
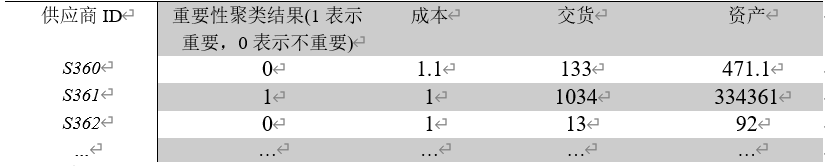
利用上表数据,结合灰色关联分析成本、交货和资产对供应商重要性的影响,得到了如下结果

从灰色关联分析结果来看,成本、交货和资产均与供应商的重要性有非常大的关联,一定程度也说明我们指标的选取的正确性
熵权法确定指标权重
灰色关联分析后,我们得到了各个指标与供应商重要性的关联系数,但是由于各
指标与供应商的关联正负性不一致,为了得到量纲与意义一致的权重,我们利用熵权法得到各指标的权重。下面是熵权法的计算流程

最后,计算求得的各指标权重为: 
5 基于二八法则确定最重要的供应商
二八法则是商业采购中普适的法则,要求数量20%的采购物占总采购价值的80%,据此,可以将供应商划分为重点供应商和普通供应商,前者数量20%,供应品价值80%。
我们已经量化计算得到了各供应商的重要性,并按重要性从高到低排列,可以利用计算结果结合二八法则,确定出最重要的供应商,再从中选取重要性最高的50家供应商。
如下图,是利用二八法则,以累计重要性占比为80%左右进行划分的曲线图
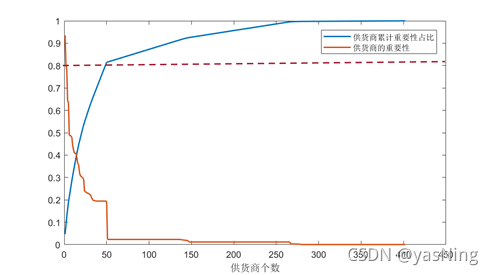
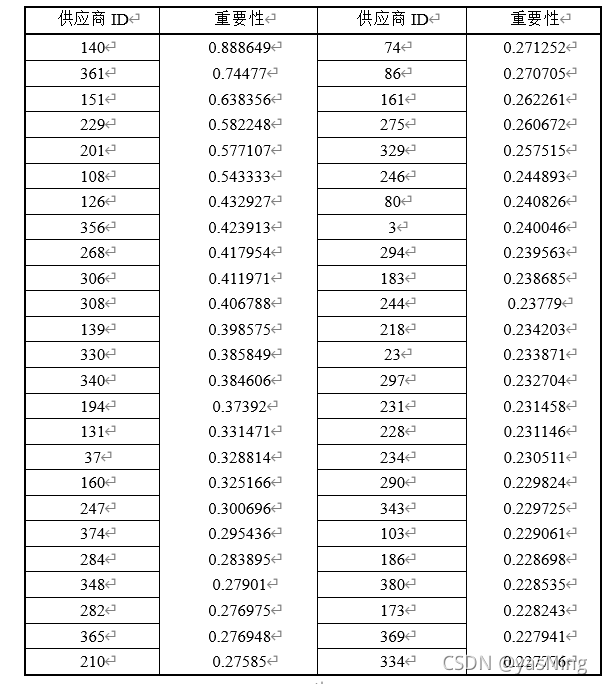
从图上来看,供货商数量在50左右时,其累计重要性占比确实接近80%,这也说明我们的评估模型得到的结果时基本符合二八法则的,按重要性从高往低依次取50个供应商作为最重要的供应商,结果如下表
Matlan代码链接:
数据预处理
%% 数据预处理
order = xlsread('..\附件1 近5年402家供应商的相关数据.xlsx', '企业的订货量(m³)', 'B2:IH403');
supply = xlsread('..\附件1 近5年402家供应商的相关数据.xlsx', '供应商的供货量(m³)', 'B2:IH403');
for i = 1:402
for j = 1:240
difference = supply(i, j) - order(i, j);
%若供货量远小于订货量,将供货量设置为订货量的临近值
if difference < -100
supply(i, j) = order(i, j) + round((rand() - 0.5) * 20);
end
end
end
xlswrite('..\附件1 近5年402家供应商的相关数据.xlsx', supply, '供应商的供货量(m³)', 'B2:IH403');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
熵权法
%% 熵权法 算权重
function [score, weights] = shangquan(x)
%实现用熵值法求各指标(列)的权重及各数据行的得分
%x为原始数据矩阵, 一行代表一个样本, 每列对应一个指标
%type指示向量,1表示正向指标,2表示负向指标
%score 返回各行(样本)得分,weights 返回各列权重
%%数据的归一化处理
X(:, 1) = guiyi(x(:, 1), 2, 0.002, 0.996); %若归一化到[0,1], 0会出问题
X(:, 2) = guiyi(x(:, 2), 2, 0.002, 0.996);
X(:, 3) = guiyi(x(:, 3), 1, 0.002, 0.996);
%%计算第j个指标下,第i个样本占该指标的比重p(i,j)
for i = 1 : 402
for j = 1 : 3
p(i, j) = X(i, j) / sum(X(:, j));
end
end
%%计算第j个指标的熵值e(j)
k = 1 / log(402);
for j = 1 : 3
e(j) = -k * sum(p(:, j) .* log(p(:, j)));
end
%计算信息熵冗余度
d = ones(1, 3) - e;
%求权值w
weights = d ./ sum(d);
%求综合得分
score = 100 * weights * X';
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
目前C题所有的代码已经在小编的github账户开放,喜欢的友友可以点赞收藏哦!有需要的小伙伴可以点击下方链接哦!
2021国赛C题代码

