
- 1模块化的RAG和RAG流程:第一部分_rag 文档规范
- 2RestTemplate使用笔记_postforobject传多个参数
- 3文心大模型通用信息抽取技术ERNIE-UIE在金融监管科技中的应用
- 4一文读懂“语言模型”
- 5Apache Doris (Incubating) 原理与实践
- 6Hive_Hive ROLLUP, GROUPING SETS, CUBE 聚合函数 与 GROUPING 函数_hive rolling up
- 7bootstrap日期插件datepicker_如何下载bootstrap的插件
- 8【JS每N日一练】【自动化】gitcode创建子项目并导入git
- 9新论文石锤Transformer:别只看注意力,没有残差和MLP,它啥都不是
- 10NLP新宠——Prompt范式_sd prompt 范本
自然语言处理从零到入门 文本挖掘
赞
踩
文本挖掘 – Text mining
网络上存在大量的数字化文本,通过文本挖掘我们可以获得很多有价值的信息。
本文将告诉大家什么是文本挖掘,以及他的处理步骤和常用的处理方法。
一、什么是文本挖掘?
每到春节期间,买火车票和机票离开一线城市的人暴增——这是数据
再匹配这些人的身份证信息,发现这些人都是从一线城市回到自己的老家——这是信息
回老家跟家人团聚,一起过春节是中国的习俗——这是知识
上面的例子是显而易见的,但是在实际业务中,有很多不是那么显而易见的信息,比如:
- 每周末流量会有规律性的上升或者下降,这是为什么?
- 国庆长假,使用 iPad 购物比例比平时要高,这时为什么?
- …
而文本挖掘的意义就是从数据中寻找有价值的信息,来发现或者解决一些实际问题。
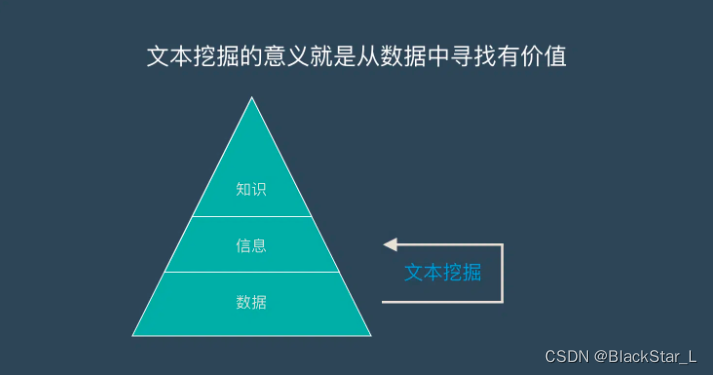
维基百科:
文本挖掘,也称为文本数据挖掘,大致相当于文本分析,是从文本中获取高质量信息的过程。高质量信息通常是通过统计模式学习等手段设计模式和趋势而得出的。文本挖掘通常涉及构造输入文本的过程(通常解析,添加一些派生的语言特征和删除其他特征,然后插入到数据库中),在结构化数据中导出模式,最后评估和解释输出。文本挖掘中的“高质量”通常是指相关性,新颖性和兴趣的某种组合。典型的文本挖掘任务包括文本分类,文本聚类,概念/实体提取,粒度分类法的生成,情感分析,文档摘要和实体关系建模(即,命名实体之间的学习关系)。
文本分析涉及信息检索,词汇分析以研究词频分布,模式识别,标记 / 注释,信息提取,数据挖掘技术,包括链接和关联分析,可视化和预测分析。最重要的目标是通过应用自然语言处理(NLP)和分析方法将文本转换为数据进行分析。 典型的应用是扫描以自然语言编写的一组文档,并为文档集建模以用于预测分类目的,或者用提取的信息填充数据库或搜索索引。
二、文本挖掘的5个步骤
文本挖掘大致分为以下5个重要的步骤。
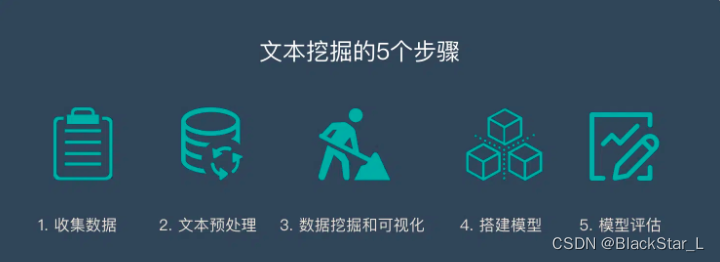
文本挖掘的5个步骤:
- 数据收集
- 文本预处理
- 数据挖掘和可视化
- 搭建模型
- 模型评估
三、7种文本挖掘的方法

- 关键词提取: 对长文本的内容进行分析,输出能够反映文本关键信息的关键词。
- 文本摘要: 许多文本挖掘应用程序需要总结文本文档,以便对大型文档或某一主题的文档集合做出简要概述。
- 聚类: 聚类是未标注文本中获取隐藏数据结构的技术,常见的有 K均值聚类和层次聚类。更多见 无监督学习
- 文本分类: 文本分类使用监督学习的方法,以对未知数据的分类进行预测的机器学习方法。
- 文本主题模型 LDA: LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。
- 观点抽取: 对文本(主要针对评论)进行分析,抽取出核心观点,并判断极性(正负面),主要用于电商、美食、酒店、汽车等评论进行分析。
- 情感分析: 对文本进行情感倾向判断,将文本情感分为正向、负向、中性。用于口碑分析、话题监控、舆情分析。
参考
文本挖掘 (维基百科)
NLP(1)— 初识文本挖掘 (jianshu)
文本数据分析:文本挖掘还是自然语言处理?(csdn)
用 Python 做文本挖掘的流程 (zhihu)
Python英文文本预处理:步骤、使用工具及示例 (csdn)
以虎嗅网4W+文章的文本挖掘为例,展现数据分析的一整套流程 (jiqizhixin)
文本挖掘 – Text mining (easyai)

