
1.Spark概述
Spark 是一个用来实现快速而通用的集群计算的平台。
在速度方面, Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。 在处理大规模数据集时,速度是非常重要的。速度快就意味着我们可以进行交互式的数据操作, 否则我们每次操作就需要等待数分钟甚至数小时。
Spark 的一个主要特点就是能够在内存中进行计算, 因而更快。不过即使是必须在磁盘上进行的复杂计算, Spark 依然比 MapReduce 更加高效。
2.Spark生态系统
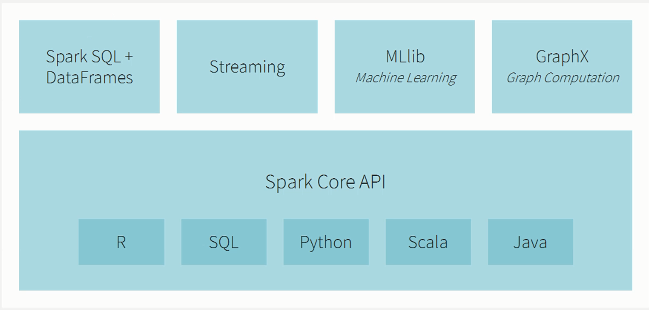
3.Spark学网站
1)databricks 网站
2)spark 官网
3)github 网站
4.Spark2.x源码下载及编译生成版本
1)Spark2.2源码下载到bigdata-pro02.kfk.com节点的/opt/softwares/目录下。
解压
tar -zxf spark-2.2.0.tgz -C /opt/modules/
2)spark2.2编译所需要的环境:Maven3.3.9和Java8
3)Spark源码编译的方式:Maven编译、SBT编译(暂无)和打包编译make-distribution.sh
a)下载Jdk8并安装
tar -zxf jdk8u11-linux-x64.tar.gz -C /opt/modules/
b)JAVA_HOME配置/etc/profile
vi /etc/profile
export JAVA_HOME=/opt/modules/jdk1.8.0_11
![]()
编辑退出之后,使之生效
source /etc/profile
c)如果遇到不能加载当前版本的问题
rpm -qa|grep jdk
rpm -e --nodeps jdk版本
which java 删除/usr/bin/java
d)下载并解压Maven
下载Maven
解压maven
tar -zxf apache-maven-3.3.9-bin.tar.gz -C /opt/modules/
配置MAVEN_HOME
vi /etc/profile
export MAVEN_HOME=/opt/modules/apache-maven-3.3.9
![]()
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=1024M -XX:ReservedCodeCacheSize=1024M"
编辑退出之后,使之生效
source /etc/profile
查看maven版本
mvn -version
e)编辑make-distribution.sh内容,可以让编译速度更快
VERSION=2.2.0
SCALA_VERSION=2.11.8
SPARK_HADOOP_VERSION=2.5.0
#支持spark on hive
SPARK_HIVE=1
4)通过make-distribution.sh源码编译spark
./dev/make-distribution.sh --name custom-spark --tgz -Phadoop-2.5 -Phive -Phive-thriftserver -Pyarn
#编译完成之后解压
tar -zxf spark-2.2.0-bin-custom-spark.tgz -C /opt/modules/
5.scala安装及环境变量设置
1)下载
2)解压
tar -zxf scala-2.11.8.tgz -C /opt/modules/
3)配置环境变量
vi /etc/profile
export SCALA_HOME=/opt/modules/scala-2.11.8
![]()
4)编辑退出之后,使之生效
source /etc/profile
6.spark2.0本地模式运行测试
1)启动spark-shell测试
./bin/spark-shell
scala> val textFile = spark.read.textFile("README.md")
textFile: org.apache.spark.sql.Dataset[String] = [value: string]
scala> textFile.count()
res0: Long = 126
scala> textFile.first()
res1: String = # Apache Spark
scala> val linesWithSpark = textFile.filter(line => line.contains("Spark"))
linesWithSpark: org.apache.spark.sql.Dataset[String] = [value: string]
scala> textFile.filter(line => line.contains("Spark")).count() // How many lines contain "Spark"?
res3: Long = 15
2)词频统计
a)创建一个本地文件stu.txt
vi /opt/datas/stu.txt
hadoop storm spark
hbase spark flume
spark dajiangtai spark
hdfs mapreduce spark
hive hdfs solr
spark flink storm
hbase storm es
solr dajiangtai scala
linux java scala
python spark mlib
kafka spark mysql
spark es scala
azkaban oozie mysql
storm storm storm
scala mysql es
spark spark spark
b)spark-shell 词频统计
./bin/spark-shell
scala> val rdd = spark.read.textFile("/opt/datas/stu.txt")
#词频统计
scala> val lines = rdd.flatmap(x => x.split(" ")).map(x => (x,1)).rdd.reduceBykey((a,b) => (a+b)).collect
#对词频进行排序
scala> val lines = rdd.flatmap(x => x.split(" ")).map(x => (x,1)).rdd.reduceBykey((a,b) => (a+b)).map(x =>(x._2,x._1)).sortBykey().map(x => (x._2,x._1)).collect
7.spark 服务web监控页面
通过web页面查看spark服务情况
bigdata-pro01.kfk.com:4040

