
- 1MSBulid、IncrediBuild命令行接口实现自动化编译_klsp.fn
- 2uniapp 写安卓app,运行到手机端 调试_uniapp 运行到app
- 3爬取豆瓣电影Top250和数据分析_怎么爬排名前十的电影
- 4二维数组的定义和引用_二维数组的定义与使用
- 5自然语言处理之智能问答系统
- 6transfomer中Multi-Head Attention的源码实现_nn.multiheadattention 官方源码
- 7ORCLE函数学习方法
- 8键盘数字键打不出来怎么解锁?收藏好这4个简单方法!
- 92021-01-05_2021-01-05t07:00:00+08:00是什么日期格式
- 10使用阿里云微调chatglm2_model.stream_chat
EMNLP 2023 | 小米AI实验室机器翻译论文入选解读
赞
踩
近日,自然语言处理领域的国际顶级会议EMNLP 2023录用结果出炉,小米AI实验室机器翻译团队2篇论文被录用,研究方向涉及机器翻译模型蒸馏和端到端图片翻译。
EMNLP 全称为 Conference on Empirical Methods in Natural Language Processing,由国际计算语言学会(ACL)组织,每年举行一次,为自然语言处理和人工智能领域的最有影响力的国际会议之一,今年会议将于12月6日在新加坡举行。

01
▍Exploring All-In-One Knowledge Distillation Framework for Neural Machine Translation
作者:缪忠剑,张文,苏劲松,李响,栾剑,陈毅东,王斌,张民
*该工作由小米AI实验室和厦门大学苏劲松老师团队合作完成,论文类别为主会长文。
一、研究背景
近年来,研究人员提出了多种通过增大神经机器翻译模型参数规模来提升翻译质量的工作。然而,庞大的模型难以在手机等低资源移动设备上部署应用。为解决该问题,研究人员提出一系列的模型压缩技术,其中,知识蒸馏(Knowledge Distillation)被广泛采用。一般来说,常规的知识蒸馏方法使用参数量大精度高的教师模型“指导”参数量少精度低的学生模型训练,缩小和大模型的精度差距。面对算力和硬件多样化的移动设备,往往需要训练多个不同参数规模的学生模型来满足端侧推理性能要求,常规的知识蒸馏方法面临如下两点不足:
1. 分别训练多个不同参数规模的学生模型,训练成本高;
2. 多个学生模型之间缺乏交互,限制了每个学生模型的精度提升;
因此,我们提出了一种更高效的多学生模型知识蒸馏框架AIO-KD(All-In-One Knowledge Distillation),不仅可以低成本获取多个不同参数规模的学生机器翻译模型用于多种设备端侧部署,而且通过联合训练还能进一步提升学生模型质量。
二、方法介绍

左图:AIO-KD多学生模型知识蒸馏训练框架
右图:教师模型抽取子结构作为学生模型
在AIO-KD中,学生模型和教师模型共享参数,在每个训练步,我们从教师模型随机抽取多个子网络作为学生模型参与当前步的多模型联合蒸馏训练。AIO-KD的优化目标损失函数包含三部分:教师模型和学生模型的交叉熵损失函数,教师模型和学生模型之间的知识蒸馏损失函数,以及学生模型之间的互学习损失函数。除此以外,我们针对AIO-KD设计了“动态梯度截断”(dynamic gradient detaching)解决知识蒸馏损失优化目标产生的梯度对教师模型质量的负面影响,以及“两阶段互学习”(two-stage mutual learning)解决训练初期学生模型质量低无法有效进行互学习的问题。
三、实验
我们在IWSLT'14 De→En、WMT'16 En-Ro、WMT'14 En→De三个机器翻译任务上进行了实验,相比于标准的Transformer基线学生翻译模型和基于Word-KD和Selective-KD两种常用的知识蒸馏技术获得的学生翻译模型,我们提出的AIO-KD方法不仅能在一个训练任务内同时获得多个不同参数规模的学生模型且质量更优,而且一体化训练时间和成本开销也大大降低。

多个学生机器翻译模型在不同训练方法下的翻译质量对比

各模型的训练时间(GPU小时)和显存占用对比
四、展望
除了机器翻译任务,我们提出的AIO-KD也适用于其他模型架构和任务。
8月14日,在#雷军年度演讲 中,小米公开介绍了小米大模型技术助力突破方向为“轻量化”和“本地部署”,同时,演示了行业首个基于NPU芯片的小米自研大模型(MiLM-1.3B)端侧推理demo,生成效果媲美云端,生成速度达到10字/秒左右。我们认为AIO-KD可以在训练标准大模型的同时生成多个参数量小的大模型,相比传统的大小模型独立训练模式,有望产生质量更好的学生模型。

另外,在“云侧大模型+端侧小模型”协同场景下,利用业界最前沿的speculative decoding技术可实现2~3倍的大模型推理加速,同时端侧小模型生成质量保持跟云侧大模型一致,利用AIO-KD训练的大小模型可能具有更一致的输出分布,可以进一步提升推理加速比。因此,该项工作对大模型“轻量化”和“端侧部署”都有潜在价值。

02
▍In-Image Neural Machine Translation with Segmented Pixel Sequence-to-Sequence Model
作者:田炎智,李响,柳泽明,郭宇航,王斌
*该工作由小米AI实验室和北京理工大学郭宇航老师团队合作完成,论文类别为Findings长文。
一、研究背景
图片翻译是一种特定类型的机器翻译任务,其目标是将带有源语言文本的图片翻译为显示目标语言译文的图片,译图跟原图保留相同的文本布局和背景颜色。图片翻译也是小米手机系统级机器翻译产品“小爱翻译”的核心功能之一,有“拍照翻译”和“屏幕翻译”两种使用模式,有广泛的应用场景和价值,例如在国外旅游时用拍照翻译理解外语菜单和产品说明书,而不需要再低效率的手动输入外语文本获得译文。

在小米平板6 Max和MIX Fold 3新品大屏设备上的小爱翻译“实时屏幕翻译”功能效果演示
目前主流图片翻译采用级联方案,即先采用OCR识别源语言文本,再通过机器翻译获得译文,最后通过去除原图文字和嵌入译文生成最终译图。级联方法具有很好的灵活性,每个模块可以单独研发和优化,同时综合体验也能到达较好水平,但也存在诸多问题,例如,OCR错误传递对译文质量的干扰,难以处理复杂文本布局的原图,下图展示了级联和端到端图片翻译框架,在左图的级联方案中,OCR将原图中的“STADT”误识别为了“STAOT”,导致下游译文错误,而右图的端到端方案具有更好的鲁棒性,不受原图文字干扰依然能产生准确的译图。
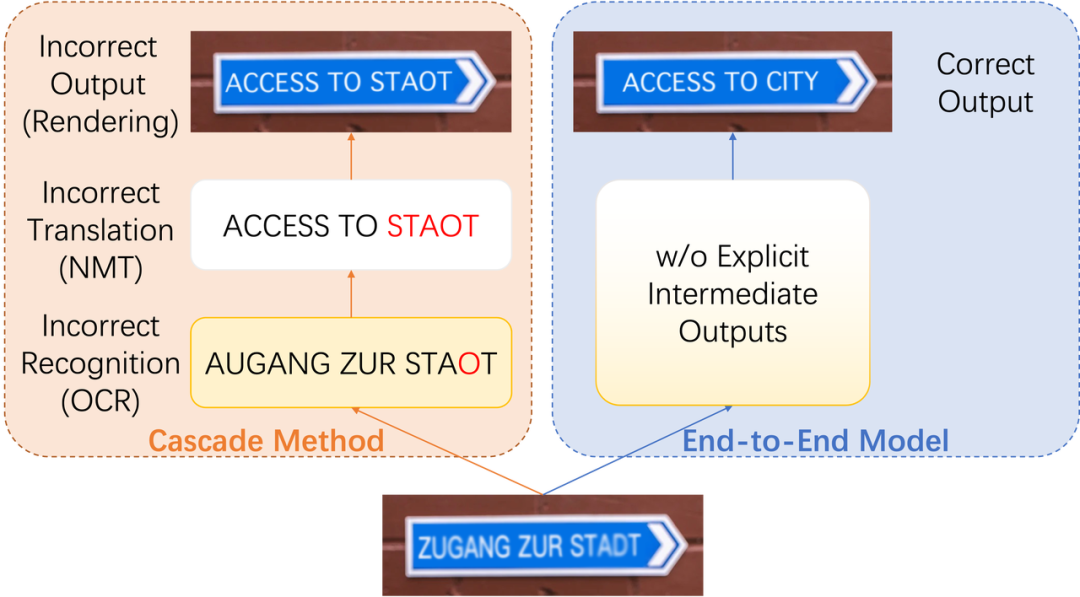
级联和端到端图片翻译框架
因此,我们提出了一种全新的端到端图片翻译模型和框架,相比既有方案,不仅生成的译文更准确,同时译图中的文字视觉效果也更清晰。
二、方法介绍
1/ 数据
目前,业界还没有公开的大规模双语图片数据集,阻碍了端到端图片翻译的研究和应用。本文使用现有的大规模WMT德英双语平行文本语料构造简单场景的图片翻译训练数据来开展研究,如下图所示,将双语文本对<x, y>中的文本以黑色字体分别嵌入到白色背景的原图和译图中。

基于平行文本语料构建图片翻译训练数据的方法
2/ 模型
我们将端到端图片翻译任务看作图像到图像的生成任务。然而,现有的图像生成模型难以生成带清晰文本的图片。对于图片翻译任务,最重要的是在保证图片布局和背景保持一致的情况下尽可能生成清晰准确的译文。不同于常用的图像生成模型,我们将带有文本的图片视为像素序列,从而将图片翻译任务转变为像素级序列到序列转换任务,在模型架构上可以采用Transformer等常用模型。

本文提出的端到端图片翻译模型架构
和“图片-像素序列”转换示意
三、实验
我们使用OCR识别译图文本,再使用BLEU和COMET评估译文质量。我们分别在领域内和领域外的机器翻译任务上进行了实验,根据下表实验结果可以看出,我们的端到端模型生成的译文质量高于传统级联方法和已有的端到端方法。

本文提出的端到端模型和级联方法的翻译质量对比

本文提出的端到端模型和早期端到端模型的翻译质量对比
四、展望
该项工作提出了一种全新的端到端图片翻译模型和训练框架,涉及的图片场景和类型离真实环境仍有较大距离,后续我们也计划结合最新的多模态大模型技术,探索更复杂更真实场景的端到端图片翻译技术,最终能够比肩甚至代替目前传统级联图片翻译方案,让小米手机用户在使用小爱翻译产品时可以获得译文更准确,视觉更逼真的体验。



