
- 1pyltp安装及运行_pyltp扩展包
- 2最新ChatGPT GPT-4 自然语言理解NLU与句词分类技术详解(附ipynb与python源码及视频讲解)——开源DataWhale发布入门ChatGPT技术新手从0到1必备使用指南手册(四)_gpt nlu
- 3关于设置VMware虚拟机里的IP所在网段与主机(Windows)电脑上的Ip所在网段一致的问题_与虚机同网段
- 4Transformer_transformer神经网络
- 5放心吧!基于图灵机的AI不会超越人类
- 6QGIS常用图源(谷歌中国、mapbox、esri、天地图等)(weixin公众号【图说GIS】)_qgis地图资源
- 7CVPR2021|一个高效的金字塔切分注意力模块PSA_高效金字塔注意力分割模块(epsa)
- 8pip国内镜像源_pipjingxiangyuan
- 9三大特征提取器(RNN/CNN/Transformer)
- 10C++PrimerPlus 课后习题第四章第8题(4.8)为什么getline()接受不到数据_c++为什么getline获取不到内容
用魔法打败魔法 Prompt2Model:大模型辅助小模型
赞
踩

知乎:养生的控制人(已授权)
深度学习自然语言处理 分享
链接:https://zhuanlan.zhihu.com/p/653647768
大模型在各方面的表现都还可以,但是在很多垂直领域反而是一种浪费,因为很多时候我们并不需要它是个通才,只需要专注于特定任务。今天分享一篇文章,主要思想就是借助LLM来辅助训练一个特定任务的小模型。
论文:PROMPT2MODEL: Generating Deployable Models from Natural Language Instructions
地址:https://arxiv.org/abs/2308.12261进NLP群—>加入NLP交流群
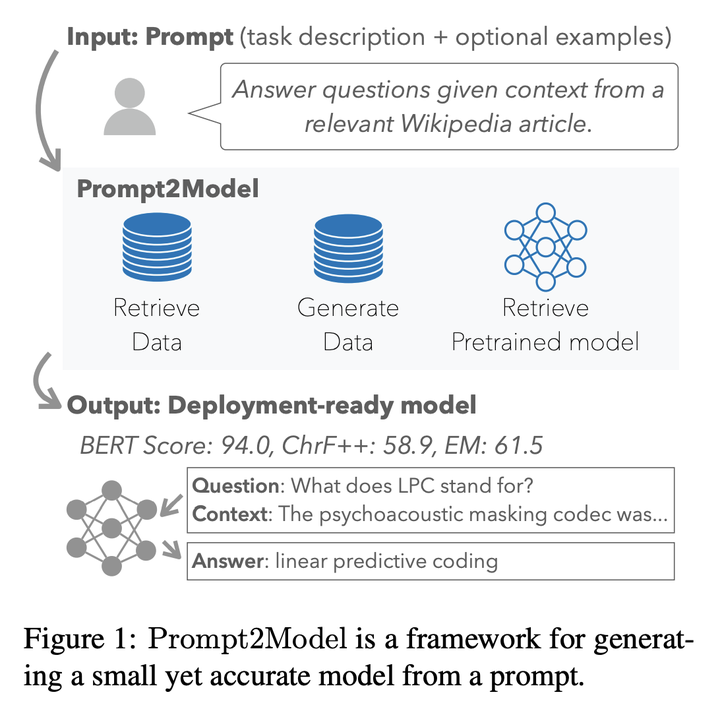
本文提出了一种名为Prompt2Model的框架,它可以接受自然语言任务描述,然后训练一个特定目的且便于部署的模型。该方法结合了检索现有数据集、预训练模型、使用LLM生成数据集,并在这些数据上进行微调。实验结果显示,与gpt-3.5-turbo相比,Prompt2Model训练的模型性能提高了20%,但模型大小减少了700倍。
Prompt2Model框架
数据集检索:根据任务相关性收集训练数据
数据集生成:利用LLM(称为“教师模型”)生成伪标签数据集,进而训练一个“学生”模型来模仿教师模型
模型检索:根据提示选择一个预训练的语言模型,进一步微调和评估
详细步骤
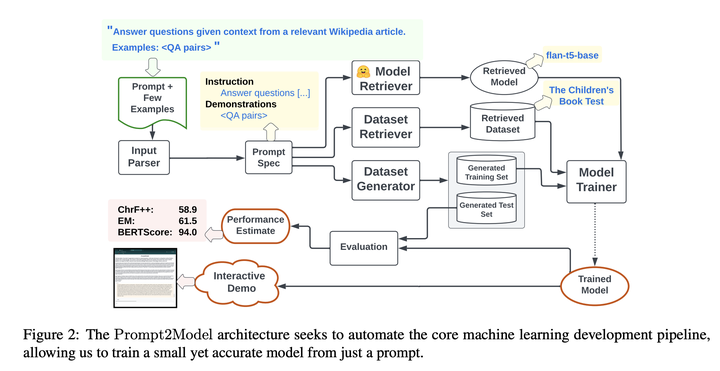
1. 提示解析
目的:将用户提供的提示分为“指令”和“示范”两部分。
方法:使用LLM(在实验中为gpt-3.5-turbo-0613)进行上下文学习,对用户提示进行分段。如果指令是非英语的,将其使用DeepL API翻译成英语。
2. 数据集检索器
目的:为给定的提示找到相关的数据集。
方法:采用Viswanathan等人(2023)引入的DataFinder系统。通过提取Hugging Face Datasets中的用户生成的数据集描述,使用DataFinder的双编码器检索器对数据集进行排序。用户可以从前k个数据集中选择最相关的数据集或指定没有合适的数据集,并指定数据集模式中的输入和输出列。
3. 数据集生成器
目的:快速、低成本地生成高质量的样本。
方法:
高多样性的少量提示:使用自动提示工程生成多样的数据集,增加用户提供的示例与随机样本,以增加多样性并避免重复。
温度退火:根据已生成的示例数量,从低到高调整采样温度,以鼓励多样性。
自洽解码:使用自洽过滤来选择伪标签,为每个独特的输入创建一个共识输出。
异步批处理:使用zeno-build并行化API请求,并使用动态批处理大小和节流机制优化API使用。
4. 模型检索器
目的:选择一个适当的预训练模型进行微调。
方法:将选择预训练模型的问题框架为搜索问题。使用用户的指令作为查询,搜索Hugging Face上的所有模型文本描述。使用gpt-3.5-turbo创建一个假设的模型描述,然后应用BM25算法计算查询-模型相似度分数。

5. 训练
目的:训练模型。
方法:将检索和生成的数据集合并,然后进行混洗,使用AdamW优化器进行训练。
6. 评估
目的:评估模型的性能。
方法:使用Exact Match、ChrF++和BERTScore三种指标自动评估模型。其中,BERTScore使用XLM-R作为编码器,支持多语言评估。
7. Web应用创建
目的:为用户提供一个与模型互动的界面。
方法:使用Gradio自动创建一个图形用户界面,然后可以轻松地在服务器上公开部署。
有意义讨论部分


进NLP群—>加入NLP交流群

