
热门标签
热门文章
- 1做软件测试,就得去大厂!
- 2Rasa中文聊天机器人开发指南(2):NLU篇_rasa中文文档
- 3《基于音频和文本的多模态语音情感识别的TensorFlow实现》的项目(写的很人性化的哦!)_基于tensorflow的语音情绪分析与运用的研究意义
- 4B端界面设计:页面分类设计_页面结构设计,功能划分
- 5介绍一下gpt模型的原理_gpt原理
- 6芒果YOLOv8改进10:特征融合Neck篇:改进特征融合网络 BiFPN 结构,融合更多有效特征_concat_bifpn yolov8
- 7深入解析《企业级数据架构》:HDFS、Yarn、Hive、HBase与Spark的核心应用_数据仓库 hive hdfs
- 8ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices论文学习
- 9mxnet学习笔记(二)——训练器Trainer()函数详解_gluon.trainer
- 10可视化模型:深度学习中的 Grad-CAM 指南_gcn grad-cam
当前位置: article > 正文
深入理解Transformer:BERT和GPT的神奇之旅_bert和gpt关系
作者:小小林熬夜学编程 | 2024-04-07 09:03:00
赞
踩
bert和gpt关系
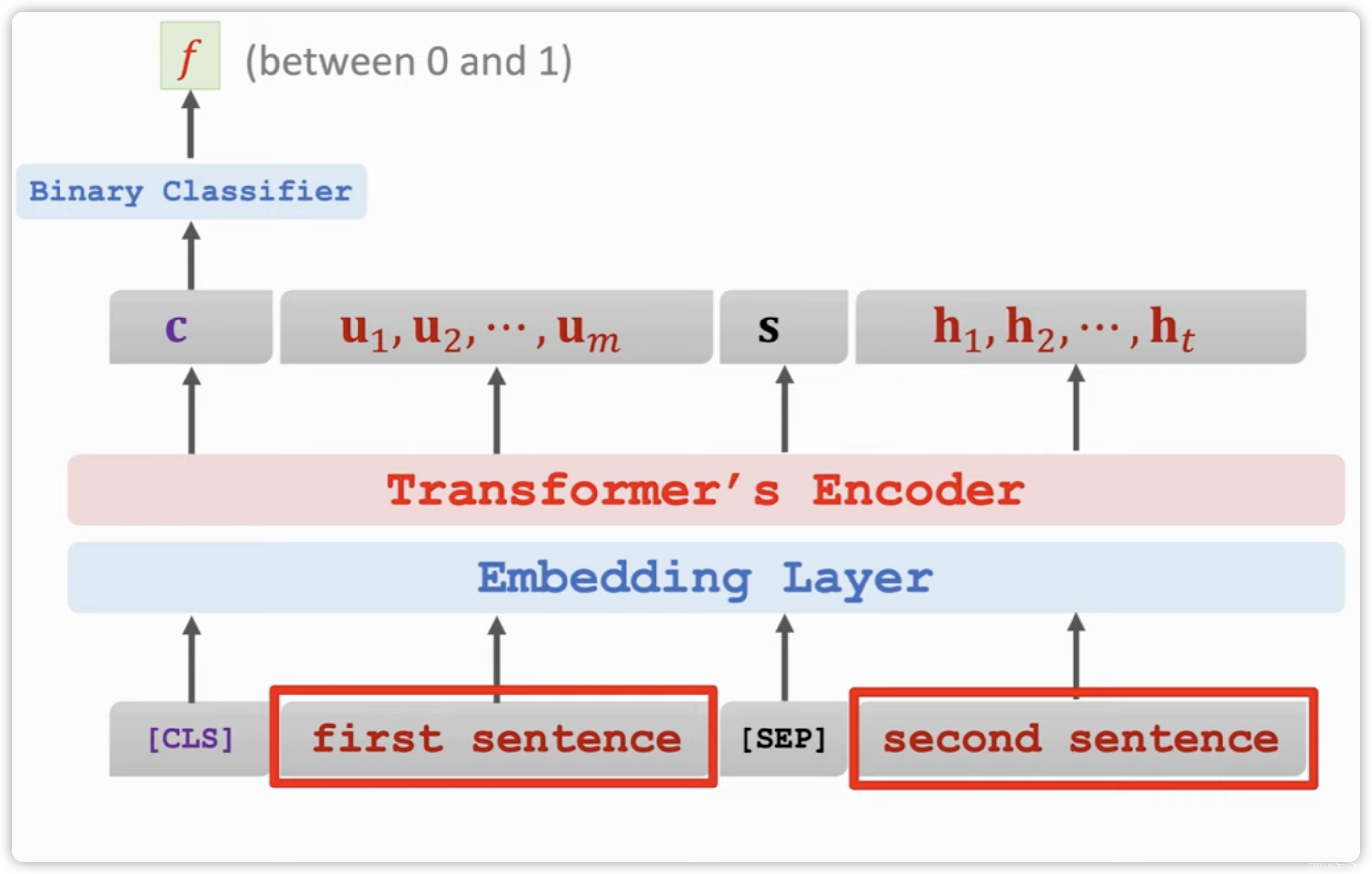
1.背景介绍
自从2017年的“Attention is all you need”一文发表以来,Transformer架构已经成为自然语言处理(NLP)领域的主流架构。Transformer的出现使得深度学习模型从传统的循环神经网络(RNN)和卷积神经网络(CNN)逐渐转向自注意力机制(Self-Attention)和并行计算,从而实现了巨大的性能提升。
在Transformer架构的基础上,Google的BERT(Bidirectional Encoder Representations from Transformers)和OpenAI的GPT(Generative Pre-trained Transformer)分别诞生了出来,并取得了显著的成功。BERT以其双向编码器的设计,在多种NLP任务中取得了卓越的性能,成为2018年的最佳论文和最佳论文奖者。GPT则以其生成模型的设计,实现了强大的语言模型,为下游NLP任务提供了强大的预训练模型。
在本文中,我们将深入探讨Transformer架构的核心概念和原理,揭示BERT和GPT的神奇之旅。我们将从背景介绍、核心概念与联系、核心算法原理和具体操作步骤以及数学模型公式详细讲解,到具体代码实例和详细解释说明,再到未来发展趋势与挑战,最后附录常见问题与解答。
2. 核心概念与联系
2.1 Transformer架构
T
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/377661
推荐阅读
相关标签

